Funktionen – AutoOCR Ordnerverarbeitung / Überwachung:
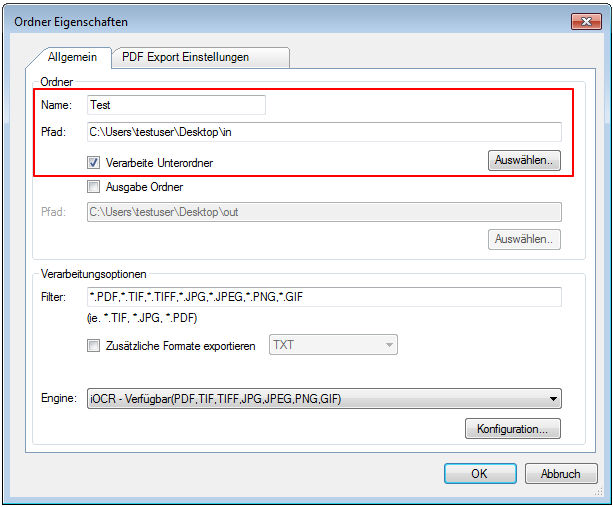
1.) Verarbeiten von Eingangsordnern / Strukturen: Dabei wird ein Eingangsordner bzw. eine ganze Ordner-Struktur verarbeitet. Die erzeugten PDF Dateien werden in der gleichen Ordnerstruktur mit den gleichen Namen wie die Ursprungsdatei abgelegt. Ein Spezialfall sind jedoch PDF Dateien da es PDF Dateien gibt die keine OCR Verarbeitung benötigen und Andere die eine solche erfordern. Es kann auch vorkommen dass nur bestimmte Seiten einer PDF Datei eine OCR Verarbeitung benötigen.
Um die PDF´s nicht nochmals zu verarbeiten werden die von AutoOCR bereits verarbeiteten Dateien in der Datenstruktur durch ein „Label“ gekennzeichnet.
Beim Start des AutoOCR-Dienstes wird die Ordnerstruktur komplett gescannt um noch nicht verarbeitete Dateien zu identifizieren. Dabei muss jede PDF Datei auf dieses „Label“ hin überprüft werden. Zu beachten ist dass bei umfangreichen Datenbeständen dieser Vorgang entsprechend lange dauert da jede PDF Datei geöffnet und überprüft werden muss.
2.) Datum / Zeit der Ursprungsdatei erhalten: Mit dieser Option kann das Datum und die Uhrzeit der Erstellung, der Änderung und des Letzter Zugriffs von der Ursprungsdatei auf die durch den OCR Vorgang erzeugte PDF Datei übertragen werden. Das PDF-Dokument wird somit ohne Änderung dieser Attribute ersetzt.

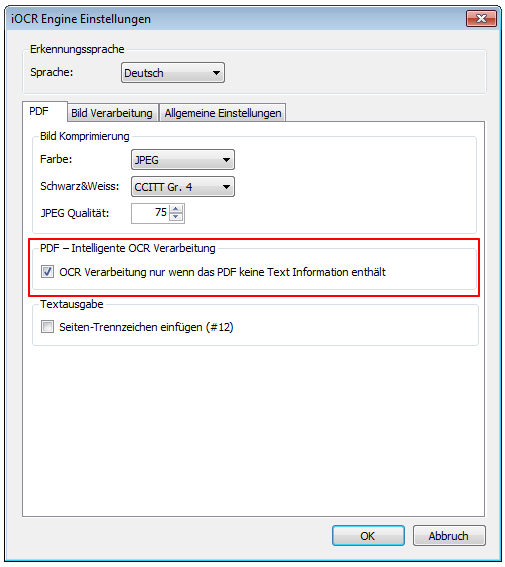
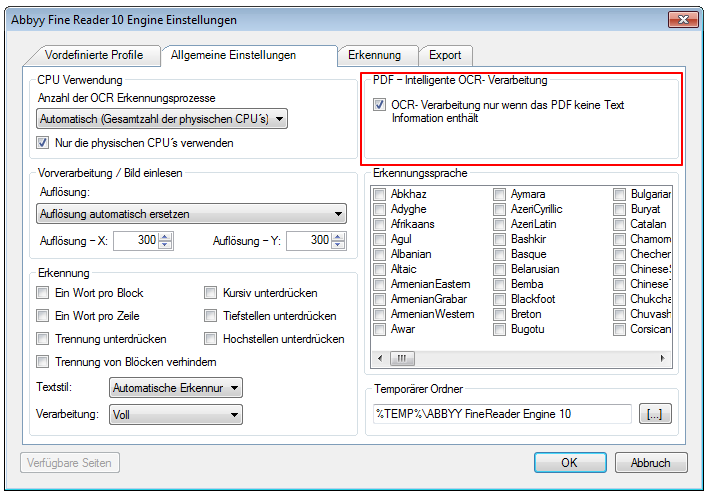
3.) Intelligente OCR Verarbeitung von PDF Dateien: PDF´s können reine Bilddateien ohne Text, „normale“ PDF Dateien die bereits Text enthalten oder aber auch gemischte Dokumente sein. Dabei sind einzelne Seiten gescannte Bilddateien ohne Text und die restlichen Seiten normale PDF Inhalte mit Text. Ohne spezielle Funktionalität würde immer das gesamt PDF Dokument und damit alle Seiten unabhängig vom Inhalt einer OCR Verarbeitung unterzogen werden. Das kostet Zeit, Ressourcen und vergrößert die PDF Dateien unnötig. Deswegen sollte die „intelligente OCR Verarbeitung“ aktiviert werden. Dabei werden nur jene Dokumente und Seiten OCR verarbeitet bei denen es notwendig ist. „Normale“ PDF Dateien werden dabei gar nicht verarbeitet sondern nur mit einem „Label“ – siehe 1.) versehen.
4.) Ordnerüberwachung – Datei-System Events / Blockverarbeitung: Ist es gefordert dass die während der laufenden Verarbeitung neu hinzukommende Dateien sofort erkannt und verarbeitet werden so muss die Option „Datei-System Events“ ausgewählt werden. Wurde „Blockverarbeitung“ ausgewählt so werden neu hinzukommende Dateien nicht automatisch erkannt. Die „Blockverarbeitung“ ist speziell für die Erstverarbeitung großer Mengen an Dokumenten vorgesehen. Nach der Erstverarbeitung sollte dann auf „Datei-System-Events“ umgeschaltet werden damit neu hinzukommende Dateien unmittelbar verarbeitet werden. Wird der AutoOCR-Dienst gestoppt und wieder gestartet so wird zuerst immer die komplette Ordnerstruktur nach noch nicht verarbeiteten Dateien durchsucht.
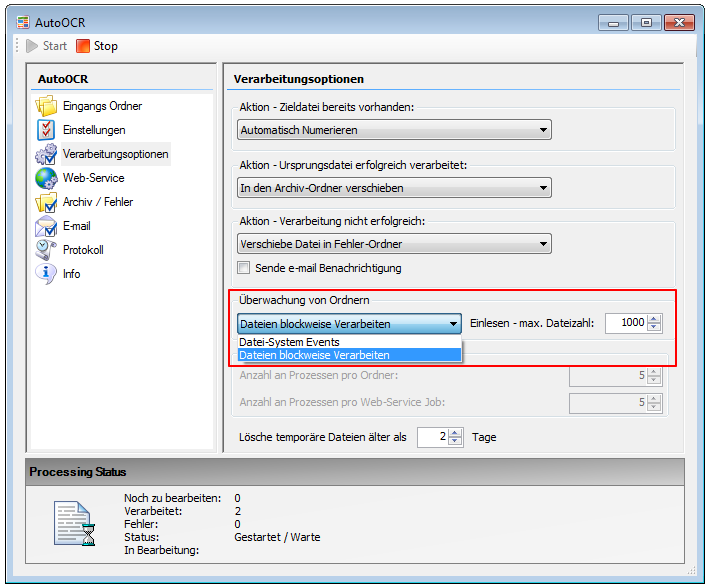
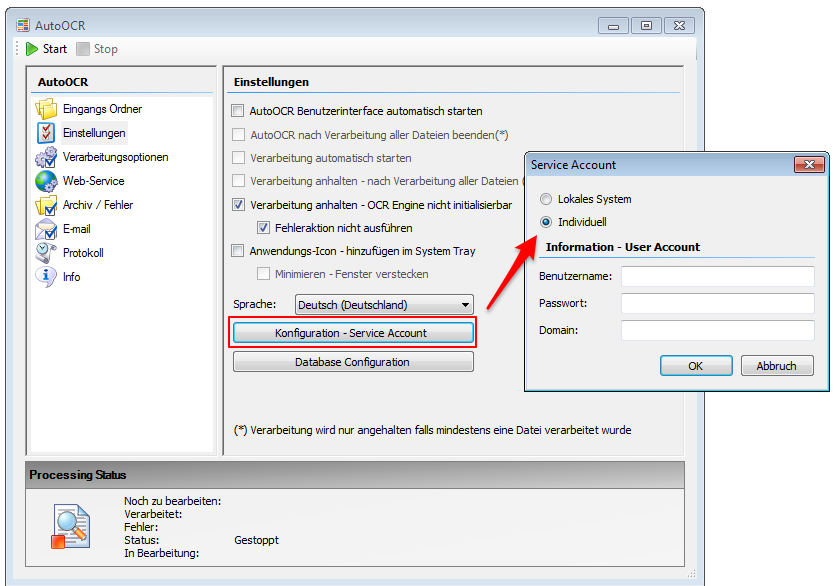
5.) Verarbeiten von Dateien / Ordnern von Netzwerk-Shares: Nach der Installation läuft der AutoOCR-Dienst standardmäßig als „Lokaler System Account“. Müssen Dateien und Ordner von Netzwerk-Shares verarbeitet werden so muss ein „User-Account“ angelegt und für den AutoOCR-Dienst verwendet werden der auch über die entsprechenden Rechte verfügt um auf die verwendeten Netzwerk-Shares zugreifen zu dürfen.