SmartTransformer – FileConverterPro integrated with Alfresco ECM
SmartTransformer is an integration of FileConverterPro (FCpro) with Alfresco ECM / DMS. The SmartTransformer consists of an Alfresco extension, an own, lean server that knows the context of the Alfresco documents and handles the processing and updating as well as the FileConverterPro.
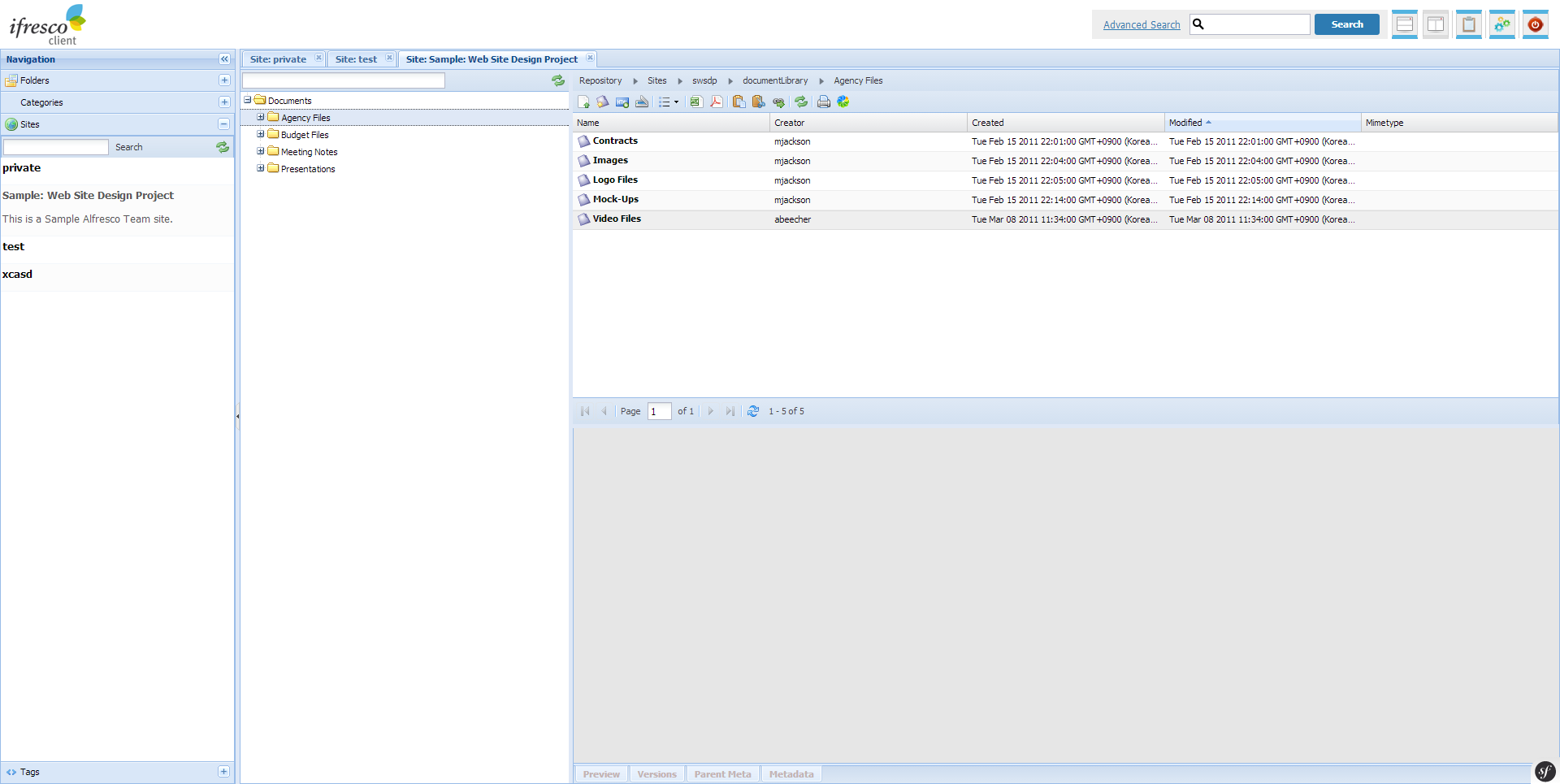
High-quality previews and better alfresco performance:
Why does viewing previews affect Alfresco performance? Alfresco automatically generates document thumbnails and previews from Office documents. This mechanism leads to complaints among the users, especially in larger environments. On the other hand, Alfresco becomes unstable and slow because it is busy with conversions or even waiting for stuck conversion jobs. On the other hand, the users are dissatisfied with the quality of the previews – the presentation mostly does not correspond to the one in MS-Office or its expression.
The Smart Transformer tackles the problem at its roots and store any office conversion to an independent, robust and scalable transformation of service that converts Office documents with MS Office libraries. The previews are as if the user had saved the document in Microsoft Office as PDF.
There is avoidance of multiple conversions, through intelligent caching in the SmartTransformer. In the same process, it is also a real relief to the Alfresco server (repository) by outsourcing all transformation tasks (text extraction, preview, thumbnail generation) to a standalone service / server. No CPU is loaded on the Alfresco server. Thus it is reliable and robust: conversion jobs are managed by the SmartTransformer of a database.
The SmartTransformer solves bottlenecks in the Alfresco architecture:
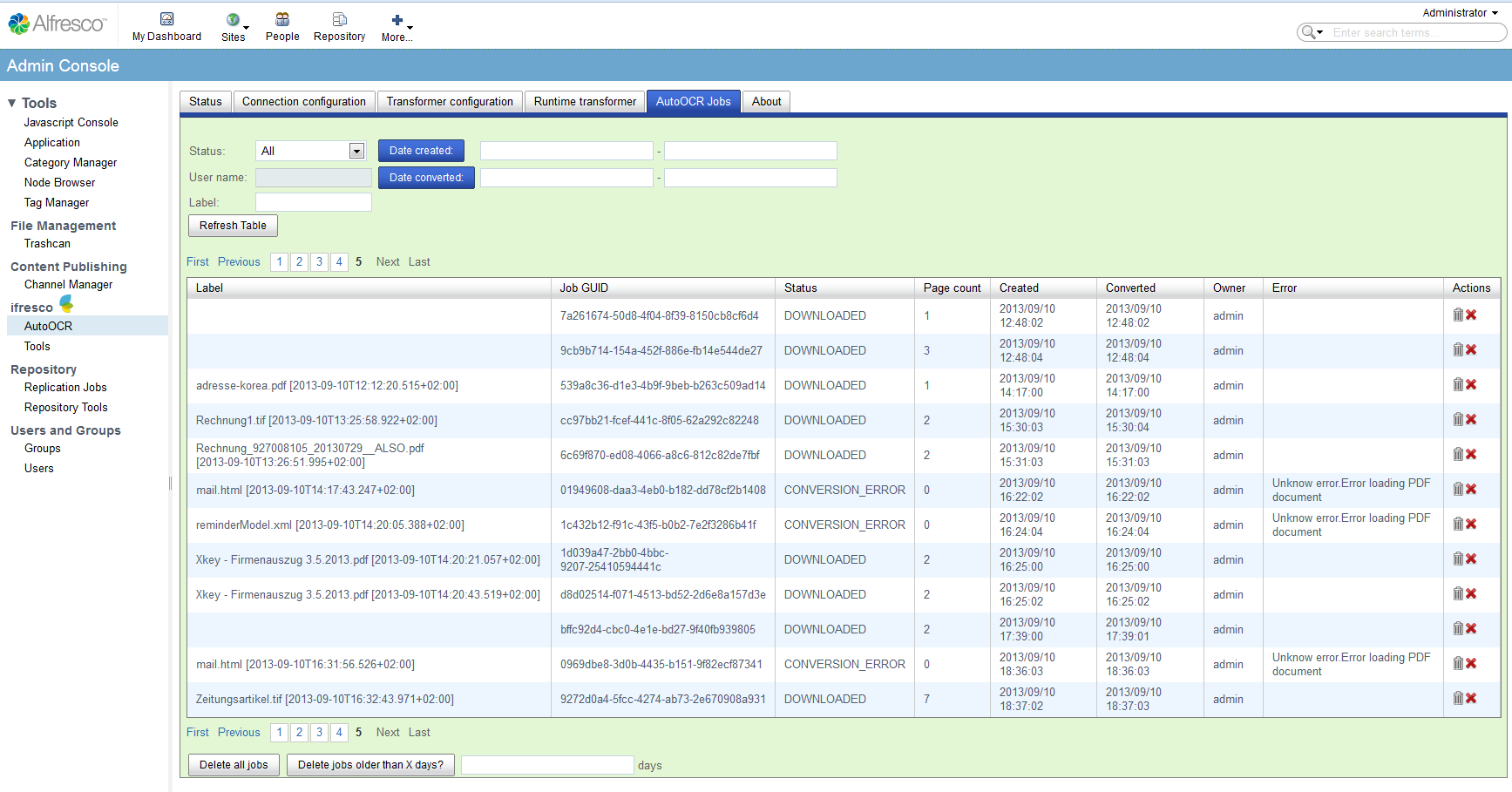
- Transformation tasks that can be performed by FCPro are simulated in Alfresco by placeholder documents and are instead entered as a “job” in a persistent job queue and transferred to the FCPro. As soon as FCPro has completed the transformation, the placeholder is replaced by the real transformation. From the point of view of Alfresco no load is created by the transformation since the result is immediately returned by the placeholder. The job queue also reboots and possible problem documents can be easily identified. In the Alfresco standard, transformations are implemented by Java threads, which can lead to scaling problems on a regular basis.
- Multiple transformations of the same binary object as the Alfresco Transformer are avoided because they are recognized by the SmartTransformer. In the same way, jobs are automatically deleted during fast updates on an Alfresco document, if they have not yet started, or the jobs are replaced by new ones.
- Unlike the Alfresco standard implementation, the transformation is already proactive when creating or modifying a document, not just when Alfresco Share is accessed. In this case, identically configurable sets are created with only one transformation (thumbnail, preview, gallery-view, …) so that the Office document has to be opened only once.
In Alfresco, a JavaScript Api is also available for the SmartTransformer.
The SmartTransformer was developed by our Alfresco development partner ECM4u.
Inquiries about the product can be directed directly to:
ecm4u GmbH
Heiko Robert [heiko.robert@ecm4u.de]
http://www.ecm4u.de
Hölderlinplatz 2b
70193 Stuttgart
t: +49 (711) 912775-72
m: +49 (176) 347475-72
f: +49 (711) 912775-80