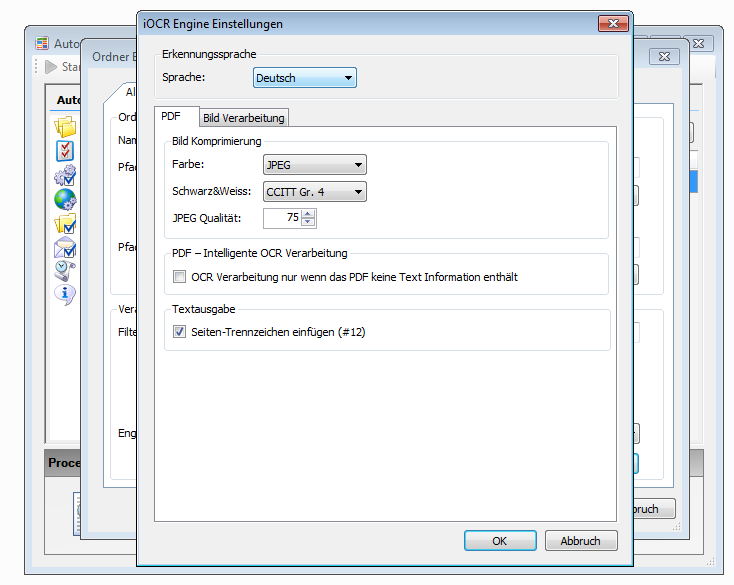
GenOCR Version 1.2.0 / iOCR5 / vsOCR5 – basierend auf Google OCR tesseract 5.0
Unserer Standard OCR Engine – iOCR / vsOCR wurde aktualisiert und basiert jetzt auf der aktuellen Google / tesseract OCR Version 5.0.
Info über zusätzliche Sprachen für iOCR5 / vsOCR5 – siehe >>>
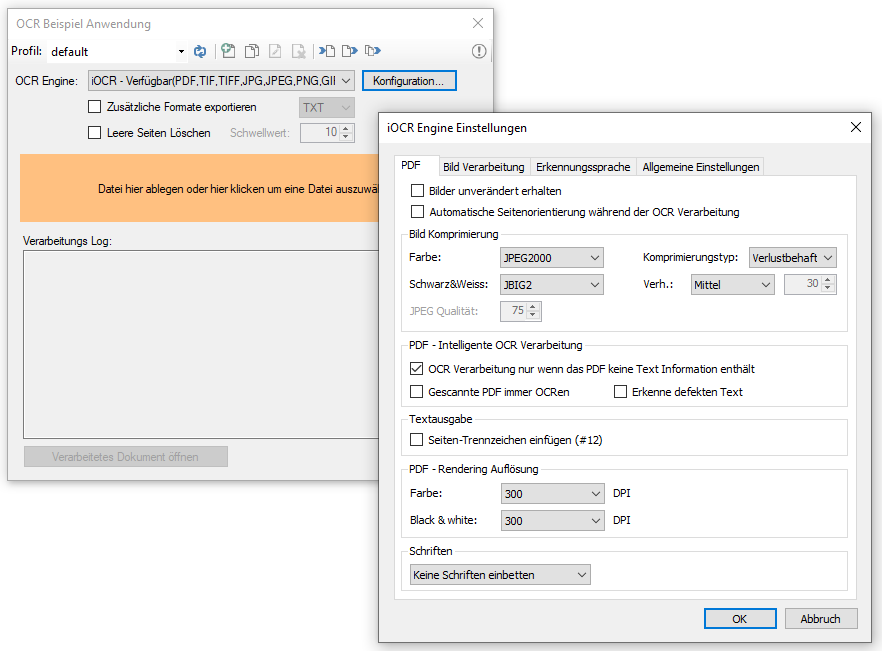
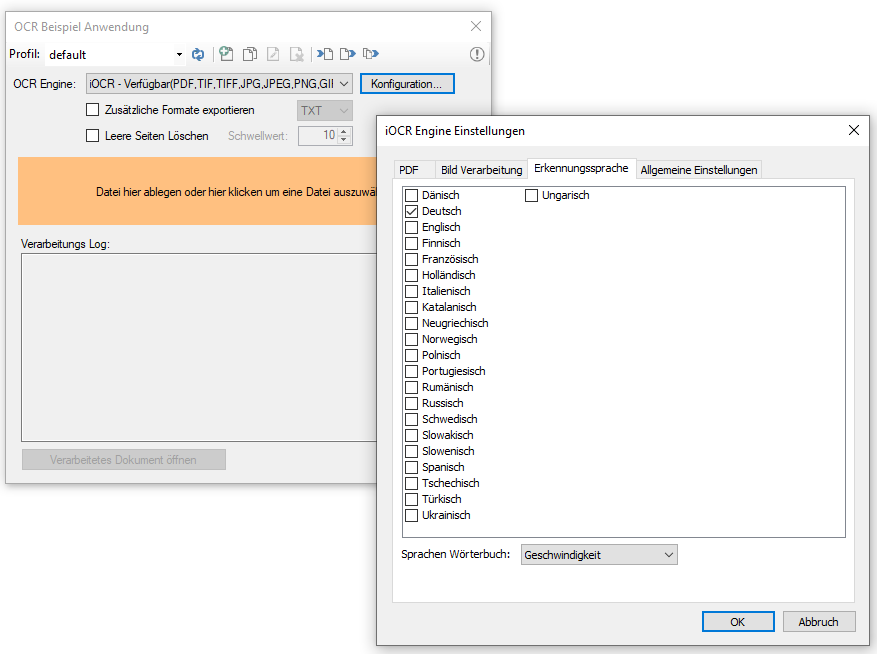
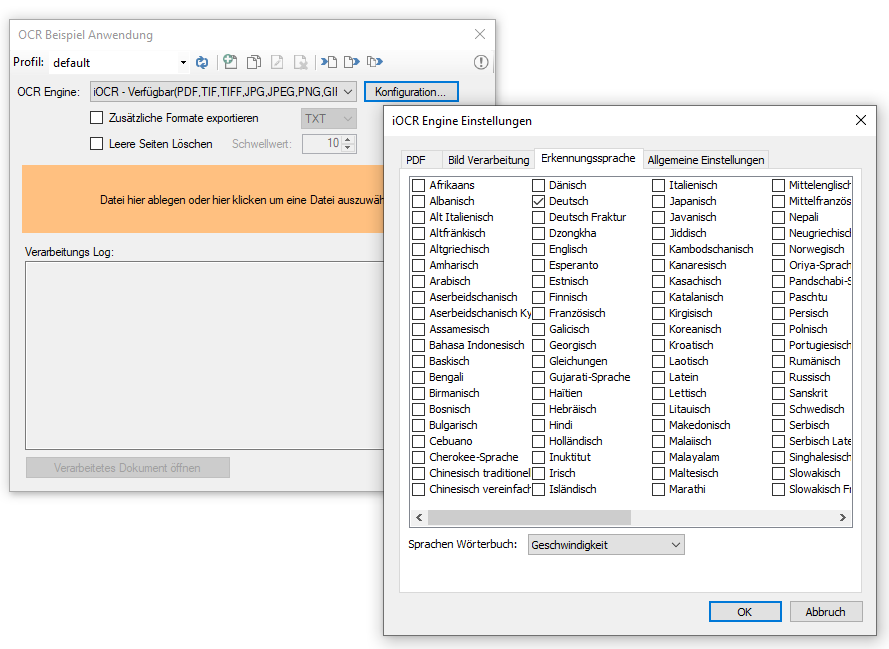
Download – GenOCR – OCR Testanwendung für iOCR (ca. 680MB) >>>
Download – iOCR5 (vsOCR5) Setup – Basis Sprachen (ca. 400MB) >>>
Download – iOCR5 (vsOCR5) Setup – zusätzliche Sprachen (ca. 1200MB) >>>