PDFmdx Version 3.7.4
Neuerungen PDFmdx Editor Version 3.7.4:
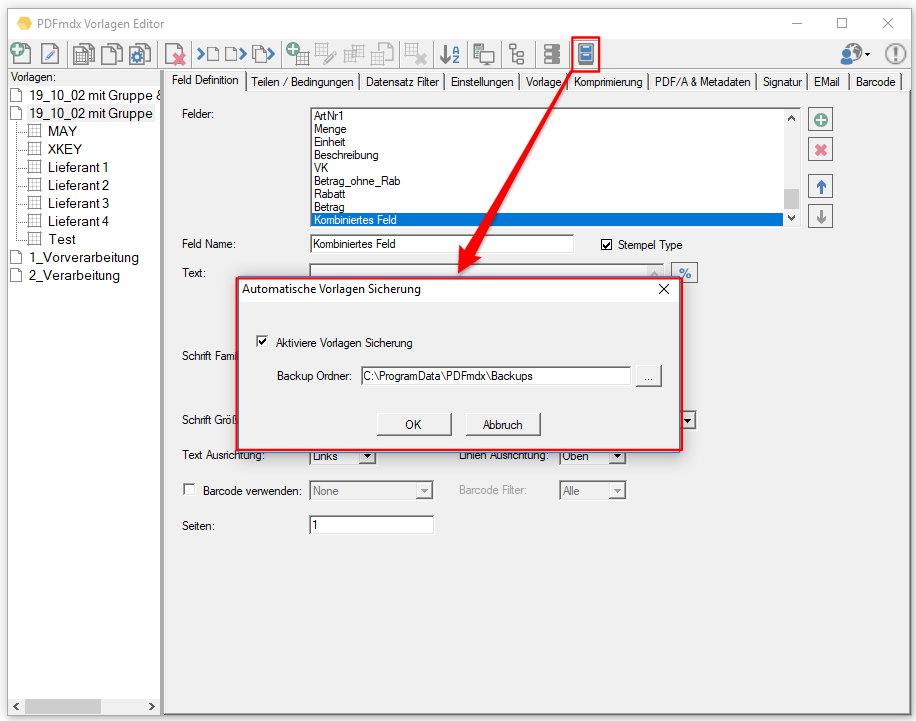
- Automatische Sicherung der Vorlagen beim Start: Aktivieren der Funktion, Pfadangabe für die Sicherungen, Sicherungen werden mit Datum und Zeit gekennzeichnet und rotierend ersetzt.
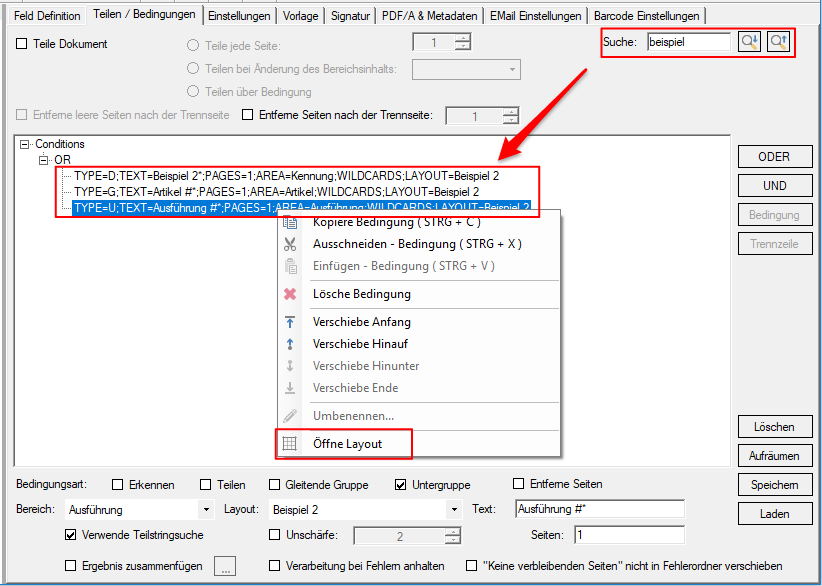
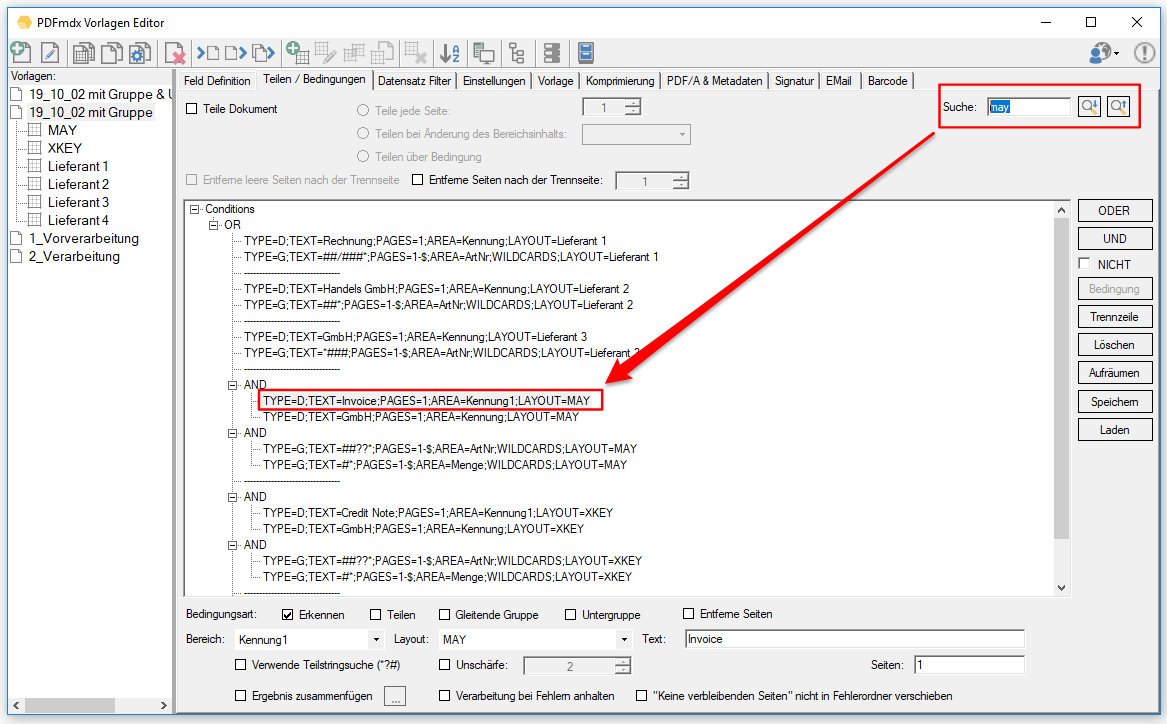
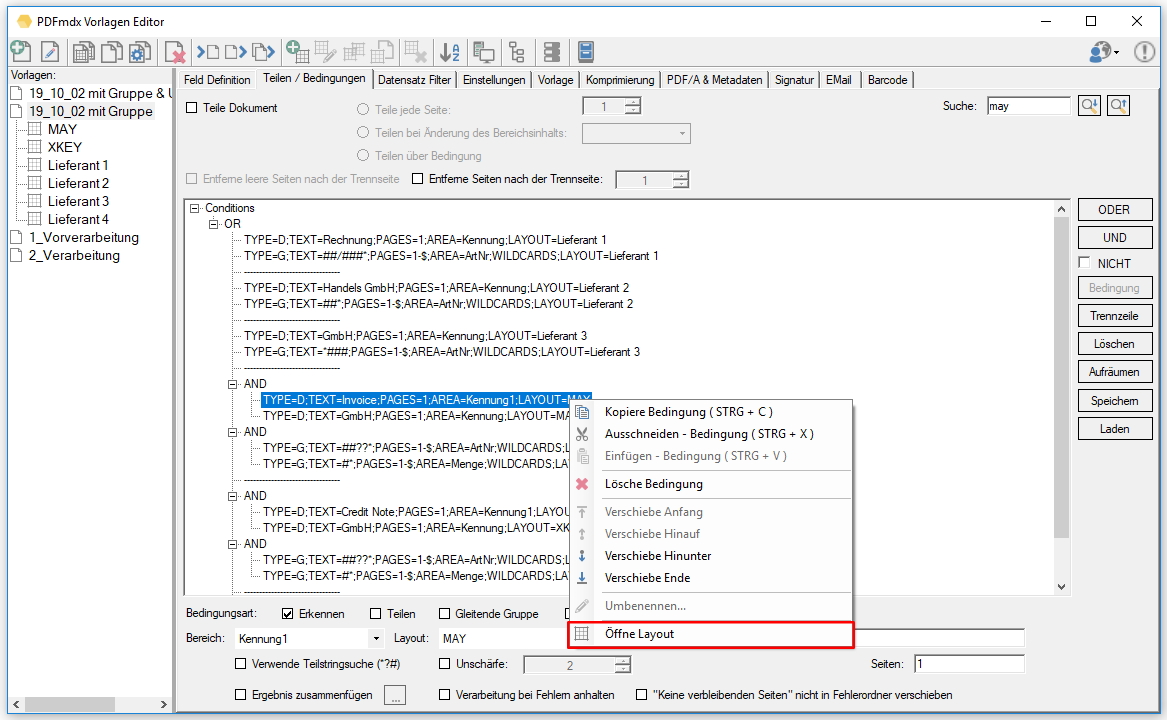
- Suchfunktion für Bedingungen: Vorwärts / Rückwärts Suche, Volltextsuche in den Bedingungen, Auswahl der gefundenen Bedingung, Über das Kontextmenü kann das mit der Bedingung verknüpfte Layout direkt aufgerufen und geöffnet werden.
- Kommentar / Trennzeilen im Bedingungseditor können gelöscht / hinauf / hinunter verschoben werden.

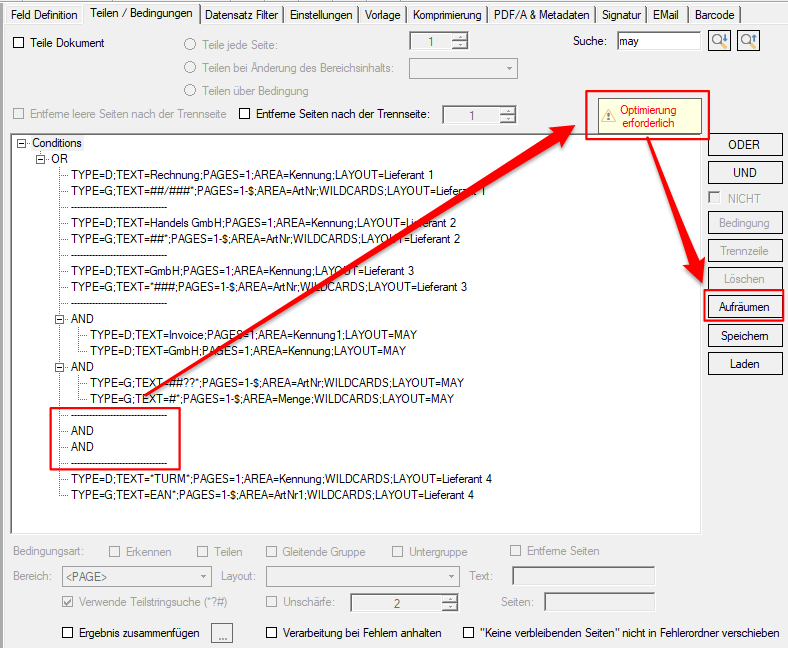
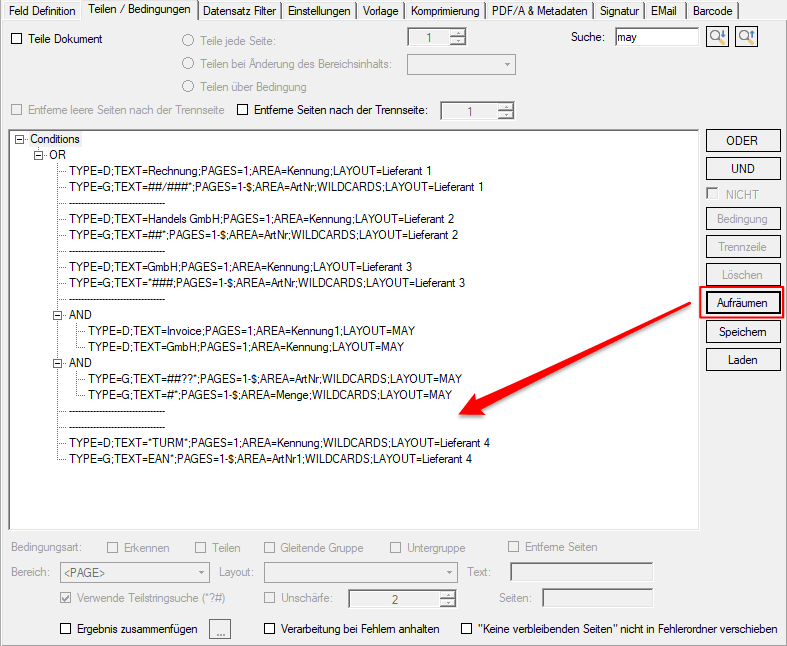
- Warnung bei leeren Bedingungs-Knoten: Leere Bedingungs-Knoten können bei der Verarbeitung zu unvorhersehbaren Ergebnissen führen. Diese werden jetzt im Bedingungseditor erkannt. Es wird eine Warnung angezeigt um eine Bereinigung durchzuführen.
- NICHT für Bedingungen: Um die Logik einer Bedingung umdrehen zu können.

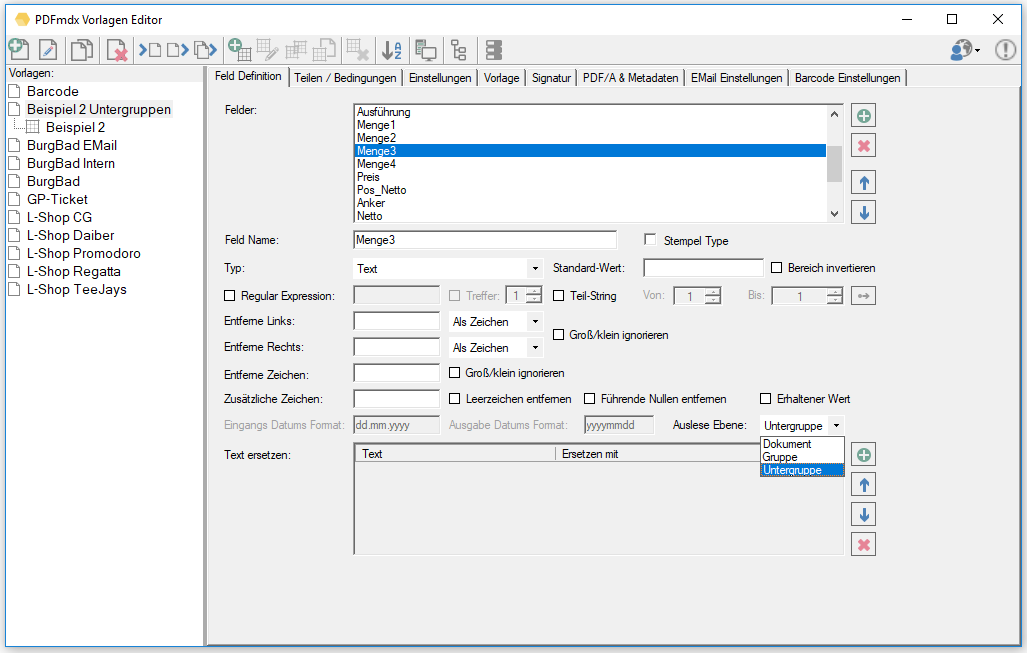
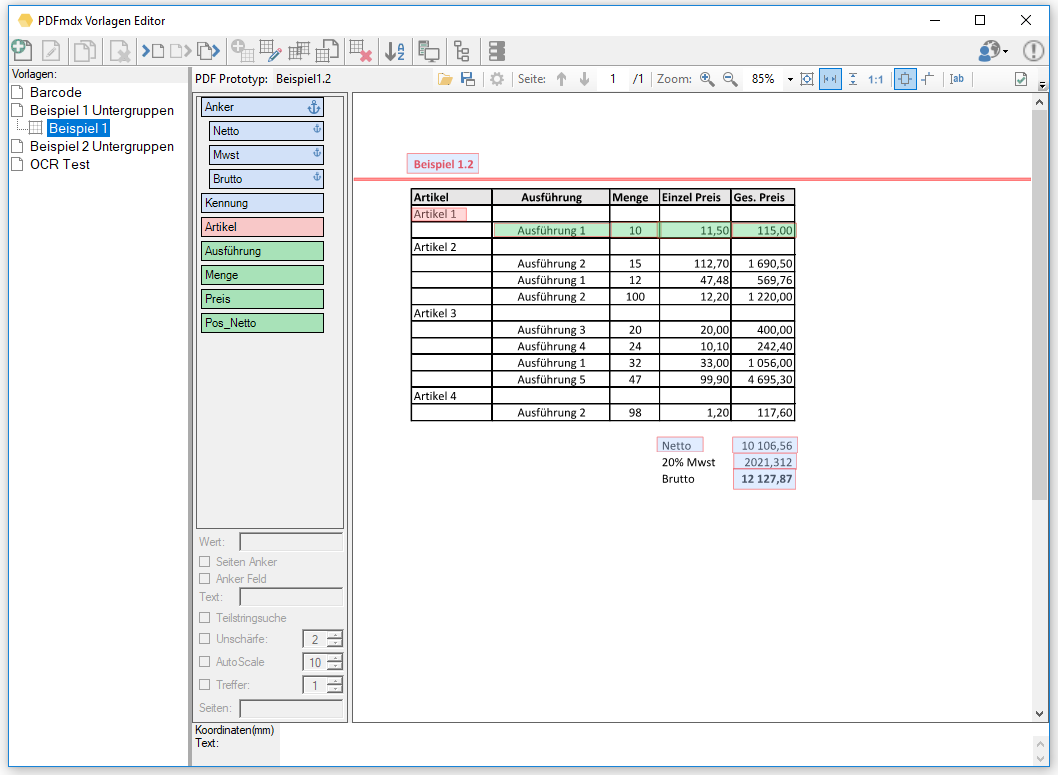
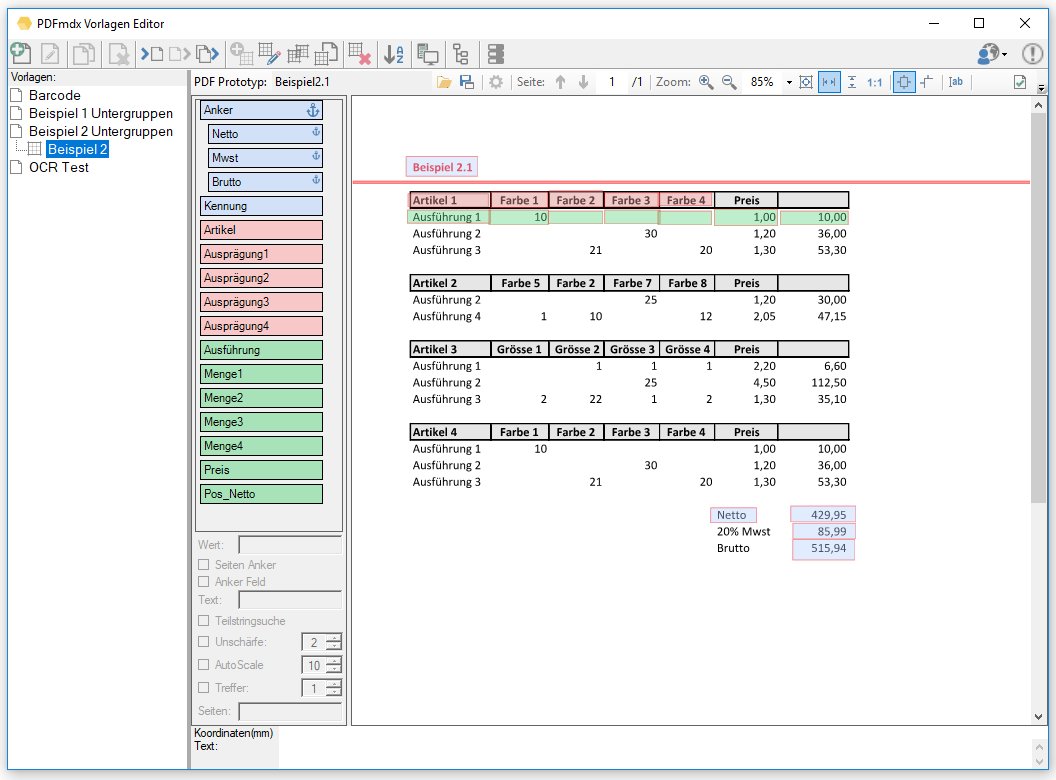
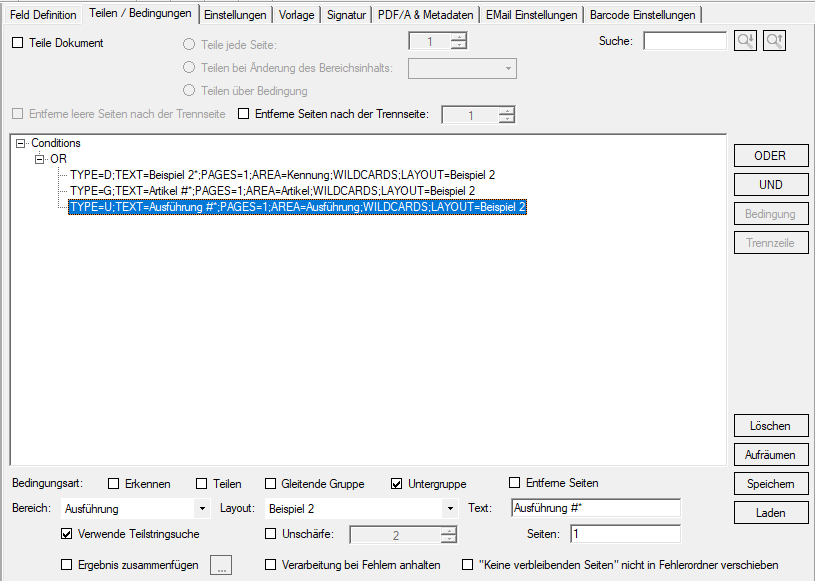
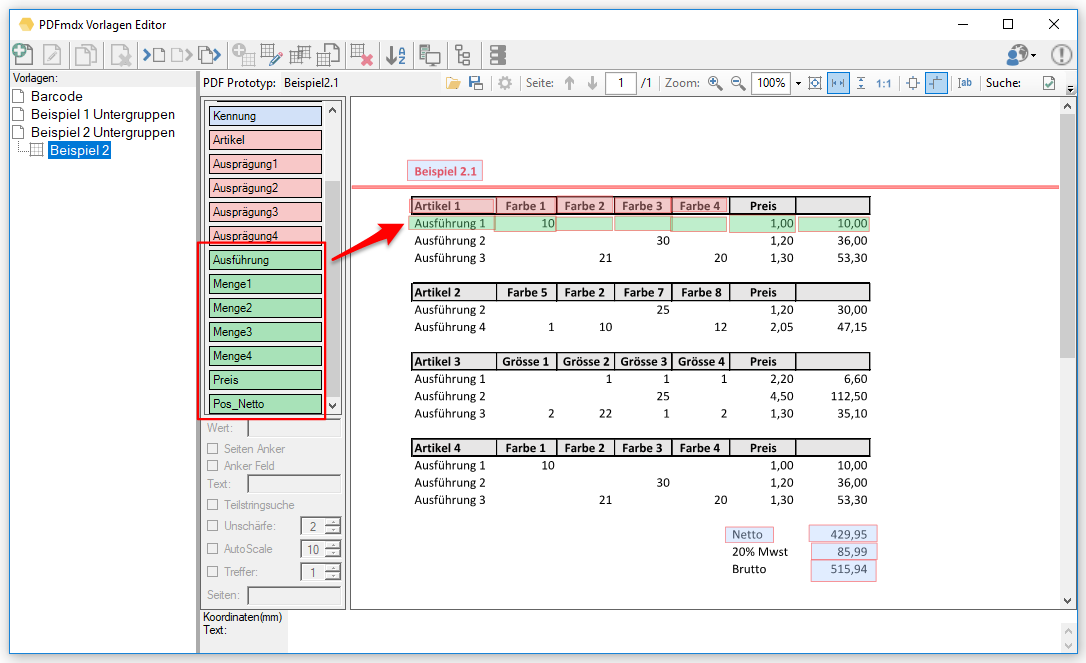
- Erweiterbare Felder: Bei Feldern einer gleitenden Gruppe kann es vorkommen dass nicht jeder Datensatz die gleiche Anzahl an Zeilen aufweist und daher ein in seiner vertikalen Größe fix definiertes Feld entweder zu viele oder nicht alle Zeilen erfasst. Mit dieser Option kann das Feld vertikal kleiner definiert werden und es werden alle folgenden Zeilen bis zum nächsten Datensatz in einem Feld erfasst. Das Zeichen das am Ende jeder Zeile für das Zusammenführen eingefügt wird ist konfigurierbar (Leerzeichen, Strichpunkt, Beistrich).

- Feldposition angleichen und optimale Größe anpassen: Für die Erfassung von Datensätzen einer gleitenden Gruppe / Untergruppe ist es wichtig dass die Felder sich alle auf einer vertikal annähernd gleichen Position befinden und dass die Felder vertikal die richtige Größe aufweisen. Optimal ist die Größe dann wenn das Feld vertikal gerade noch den Textbereich erfasst um den Text auslesen zu können, sollte jedoch nicht größer oder kleiner sein. Manuell kann es bei engen Zeilen manchmal nicht einfach sein die Größe richtig zu setzen. Dafür gibt es jetzt eine Automatik-Funktion. Mit dieser Funktion werden die Felder automatisch vertikal ausgerichtet und auf die optimale Größe gesetzt.
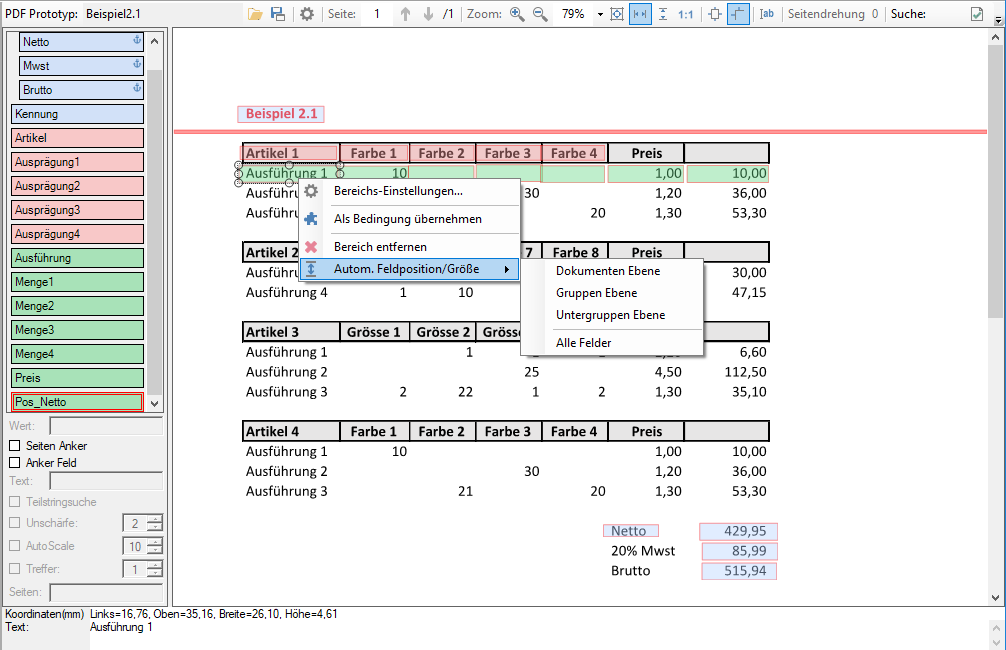
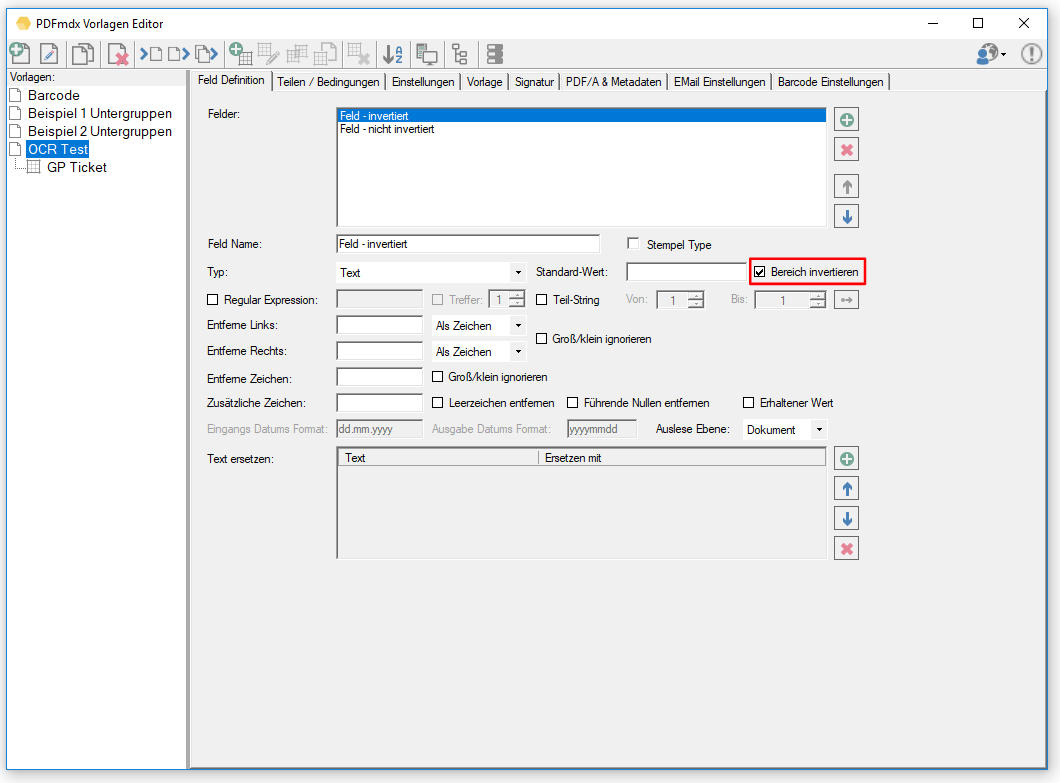
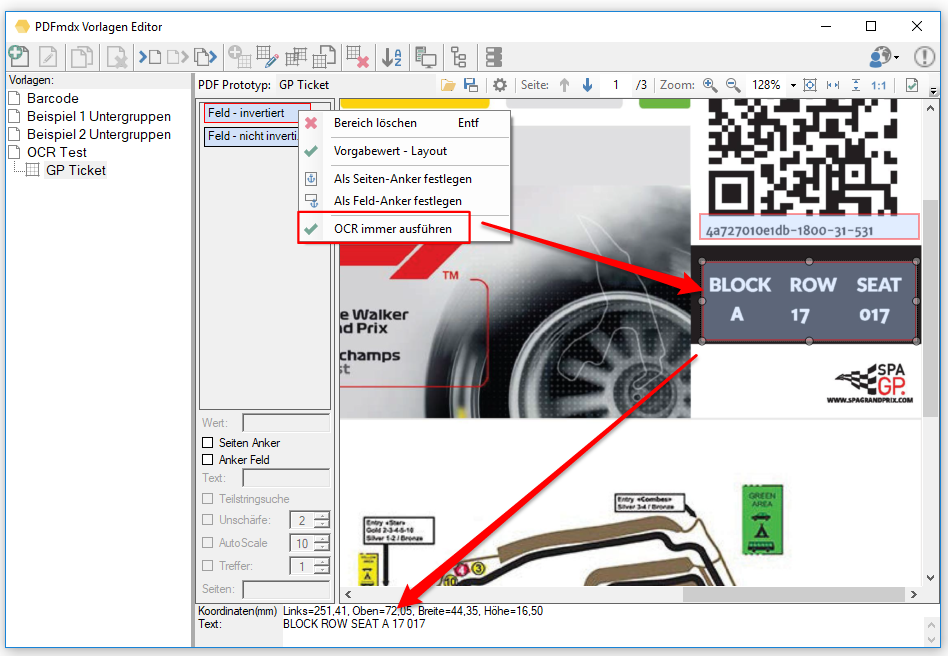
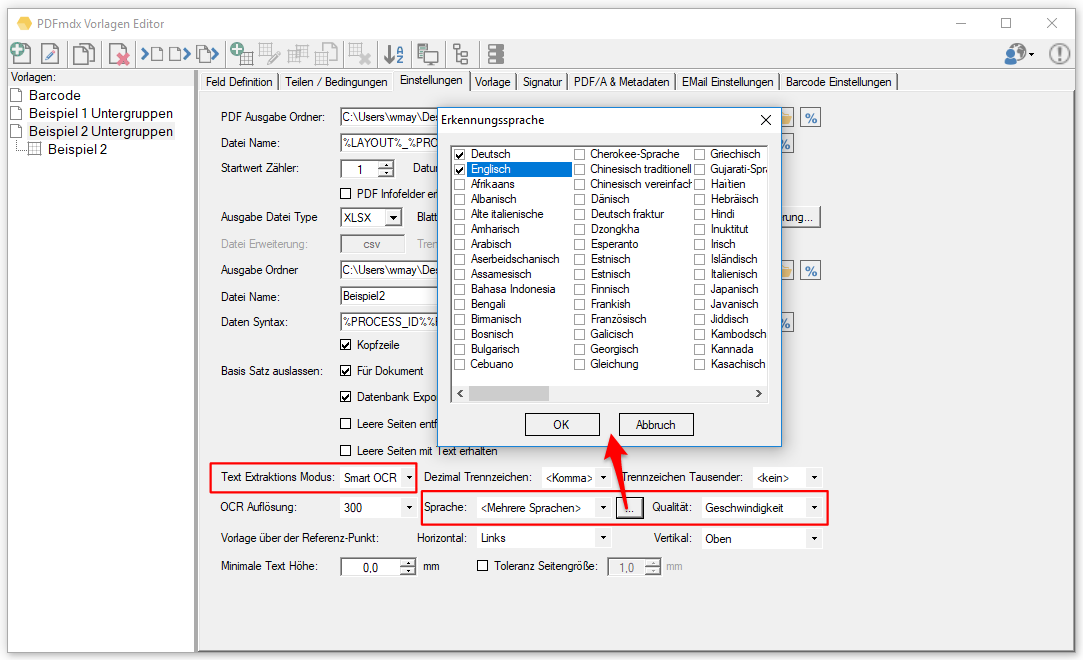
- Bereich vor der OCR Erkennung invertieren: OCR funktioniert nur bei dunkler Schrift auf hellem Hintergrund. Bei heller Schrift auf einem dunklen Hintergrund muss vor der OCR Erkennung der Bereich invertiert werden. Dafür gibt es jetzt eine eigene Bildverarbeitungsfunktion die für ein Feld aktiviert werden kann und vor der integrierten OCR Erkennung ausgeführt wird.
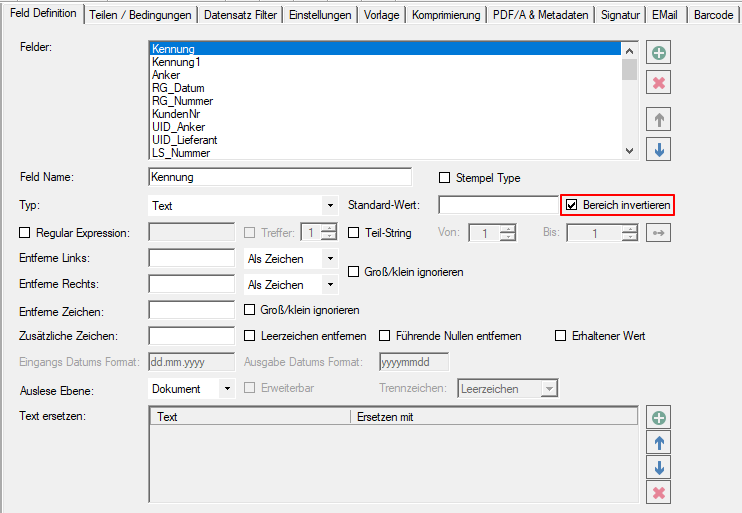
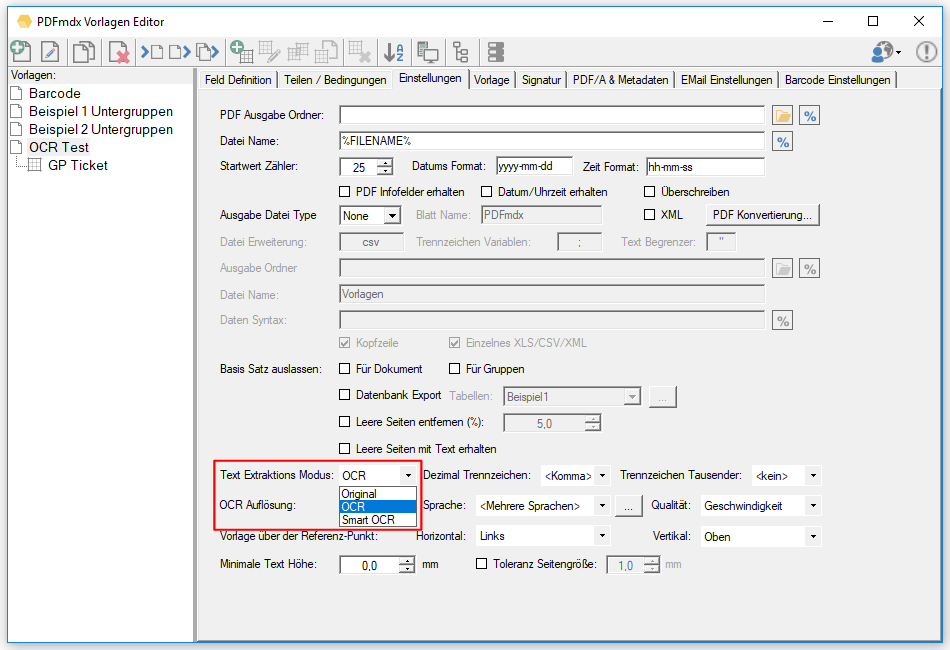
- OCR immer ausführen: Nicht immer hat eine PDF in der Textebene den korrekten Text hinterlegt. z.b. wenn im Gesamtdokument invertierte Bereiche mit weißem Text auf schwarzem Hintergrund vorhanden sind. Ist die „SmartOCR“ Verarbeitung aktiviert so wird ein Bereichs-OCR nur ausgeführt falls kein Text in dem Bereich vorhanden ist. Für einzelne Bereiche kann jetzt festgelegt werden dass trotz bestehendem Text die OCR immer ausgeführt wird z.b. um vorher eine Invertierung des Bereichs durchzuführen um so ein brauchbares Ergebnis zu bekommen.
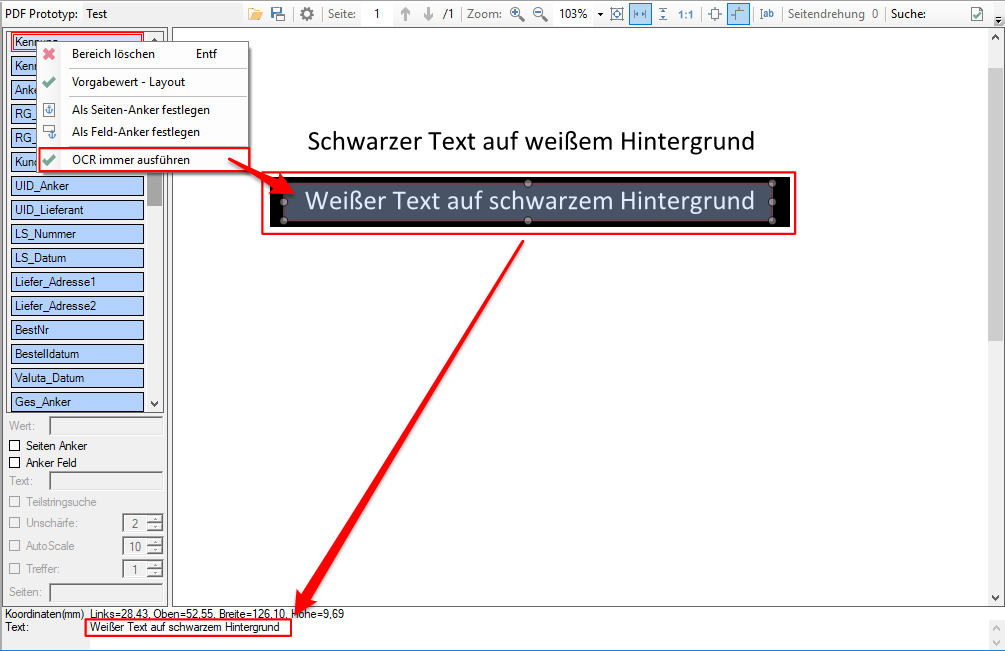
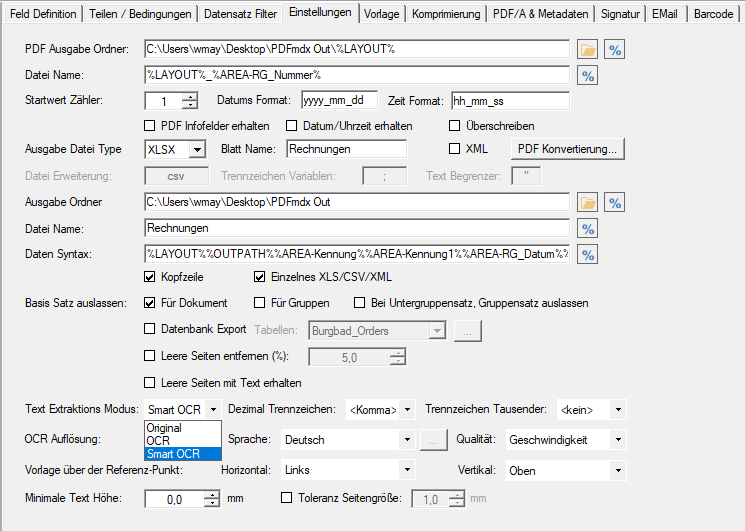
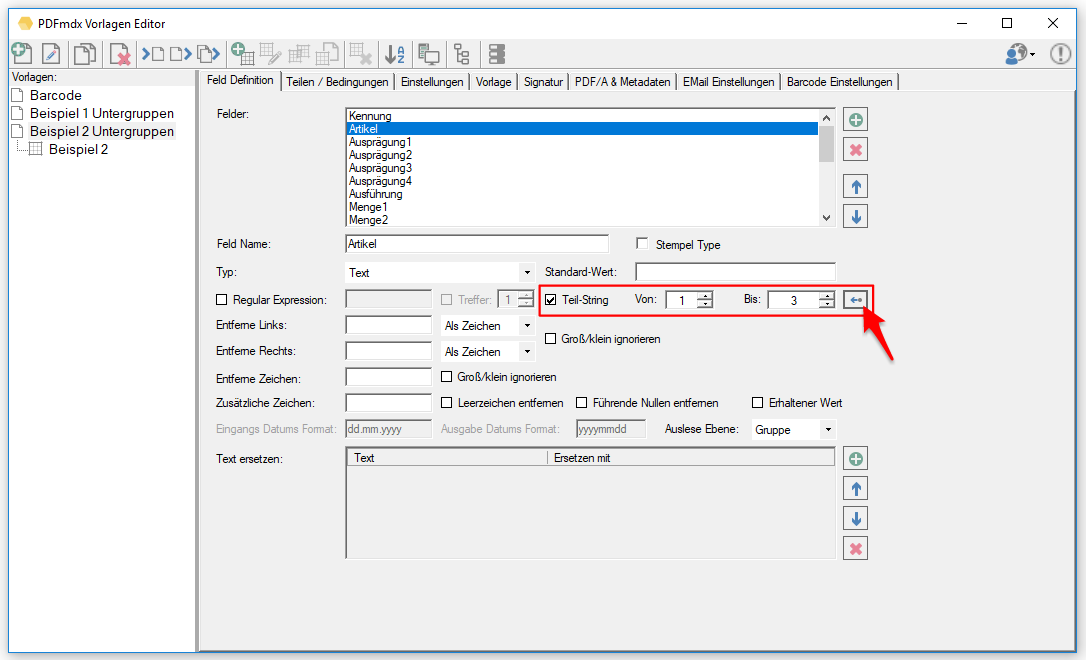
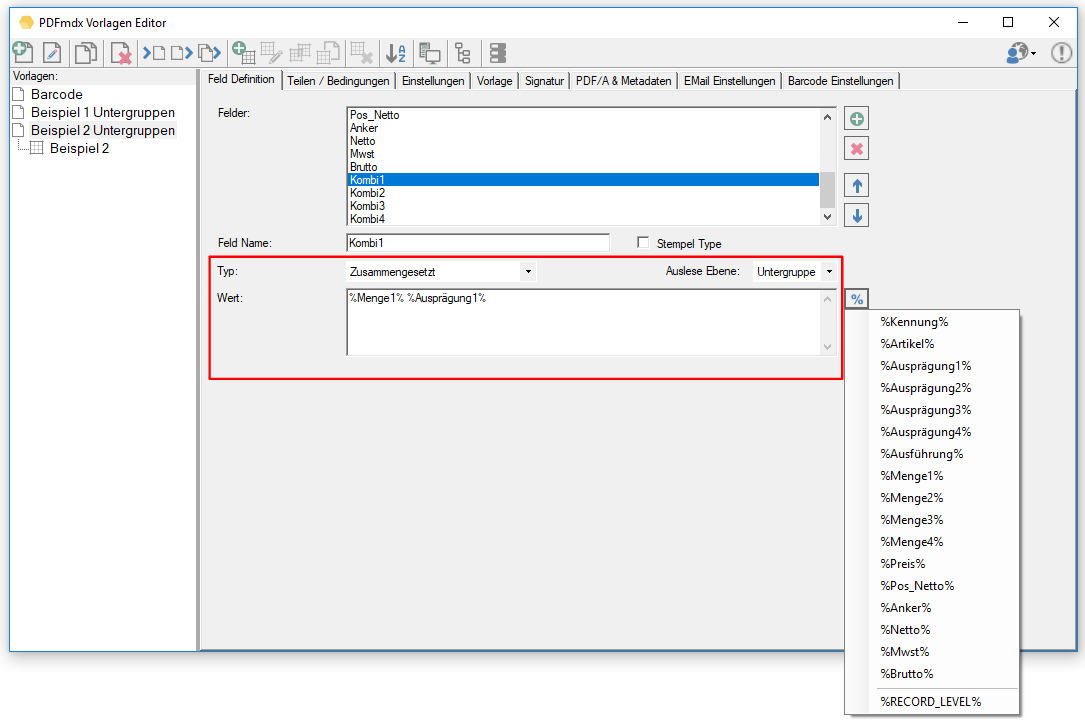
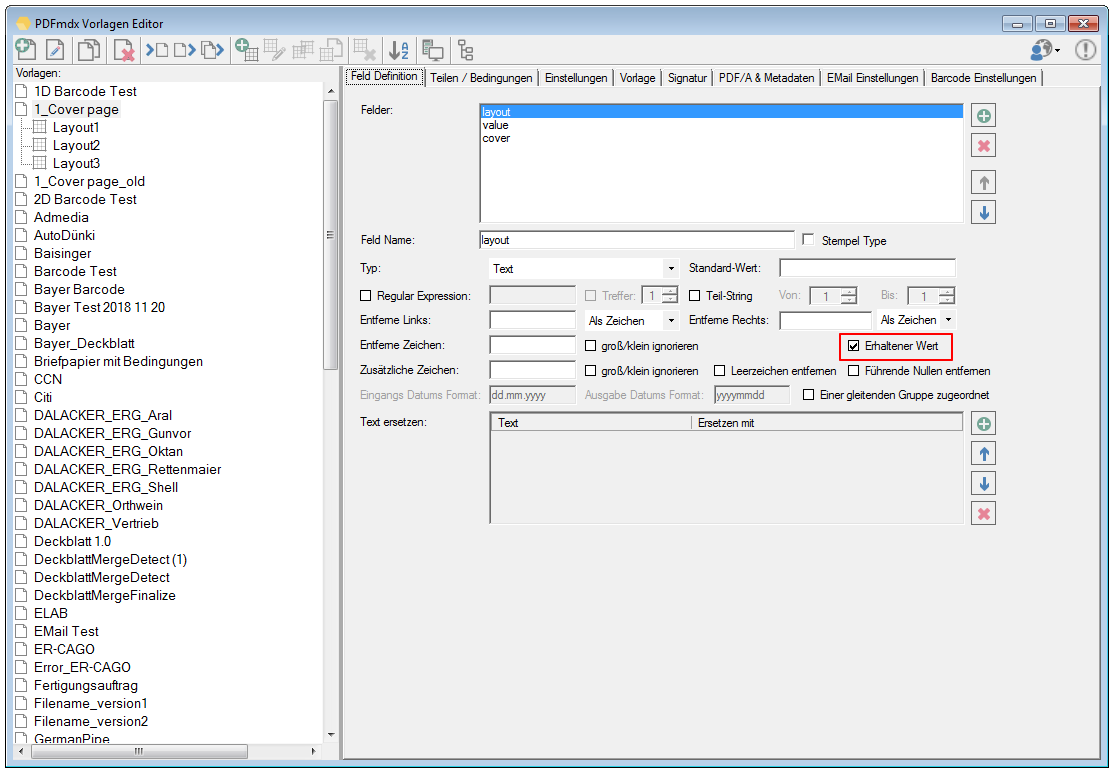
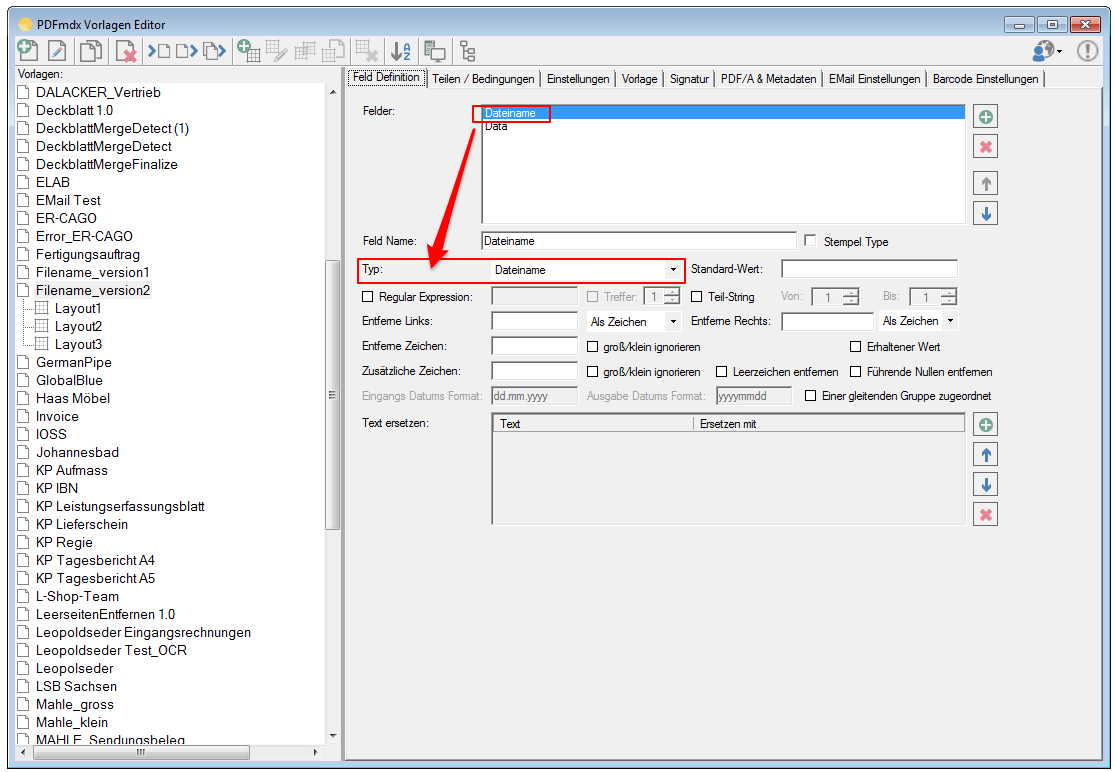
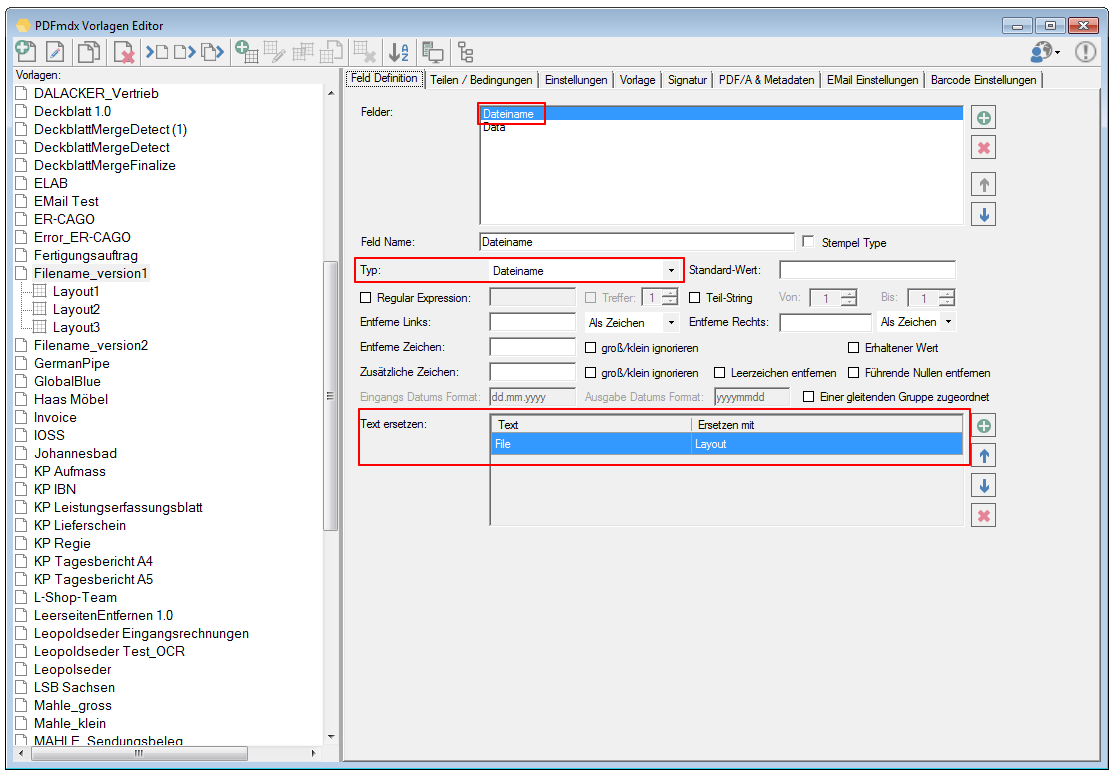
- Zusammengesetzte Felder: Es können jetzt auch Felder angelegt werden die aus anderen Feldern und Texten zusammengesetzt sind. Diese Felder können für die Ausgabe verwendet werden.
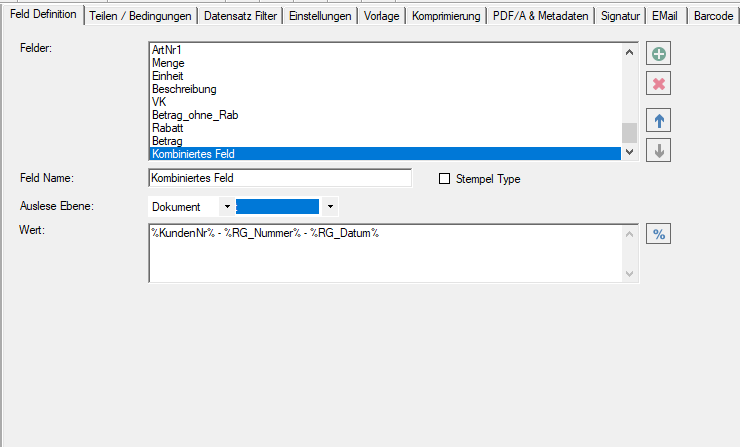
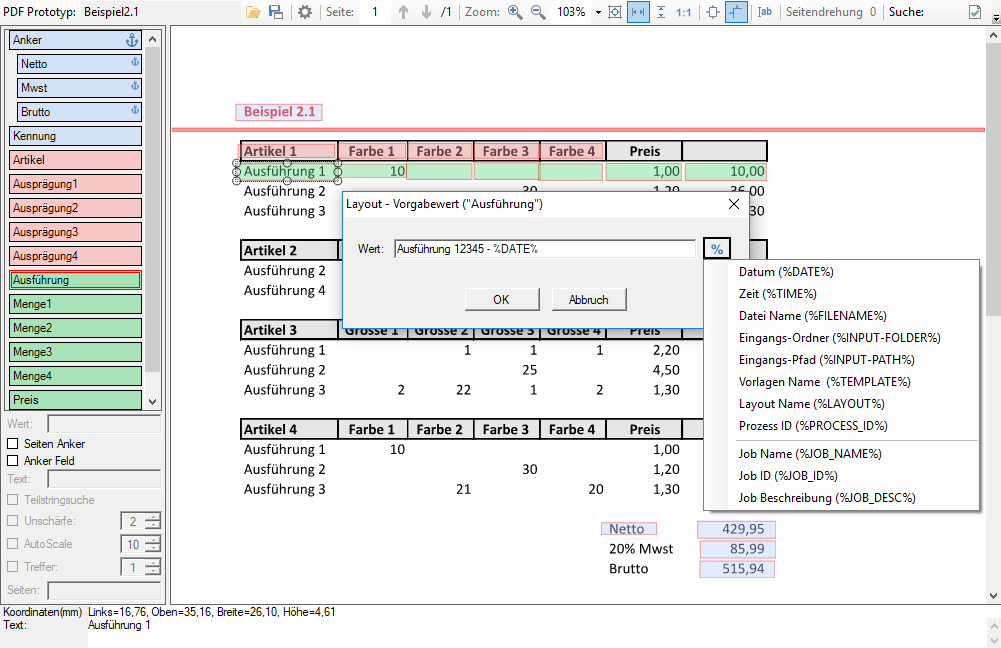
- Vorgabewerte für Felder können auf Basis des Layouts und nicht nur global vergeben werden.

- Numerische Felder können auch negative Werte annehmen.
- Vorlage ohne die in der Vorlage enthaltenen Layouts als neue Vorlage anlegen.
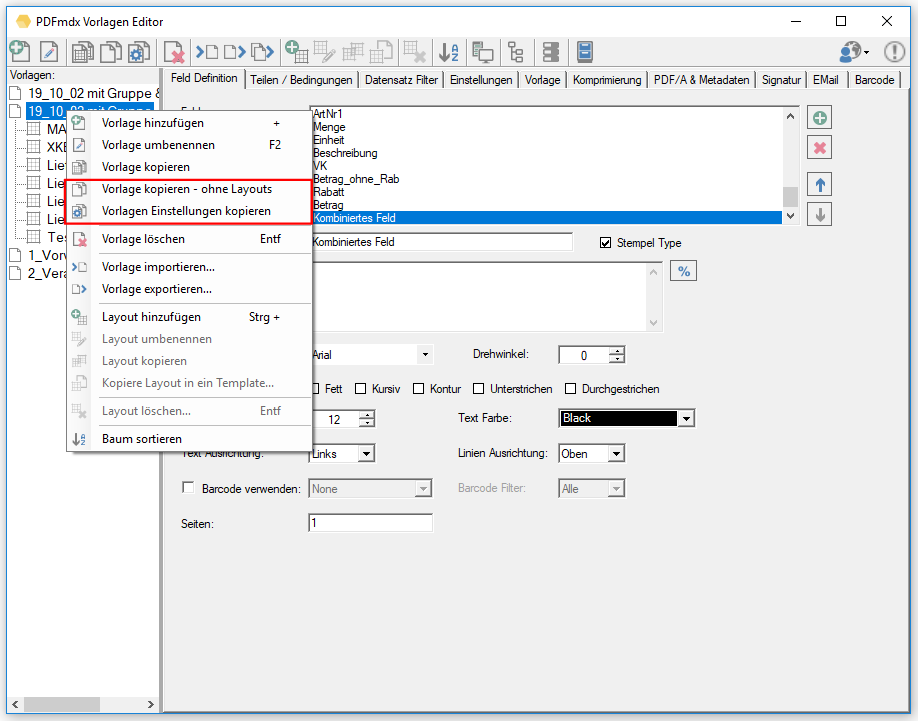
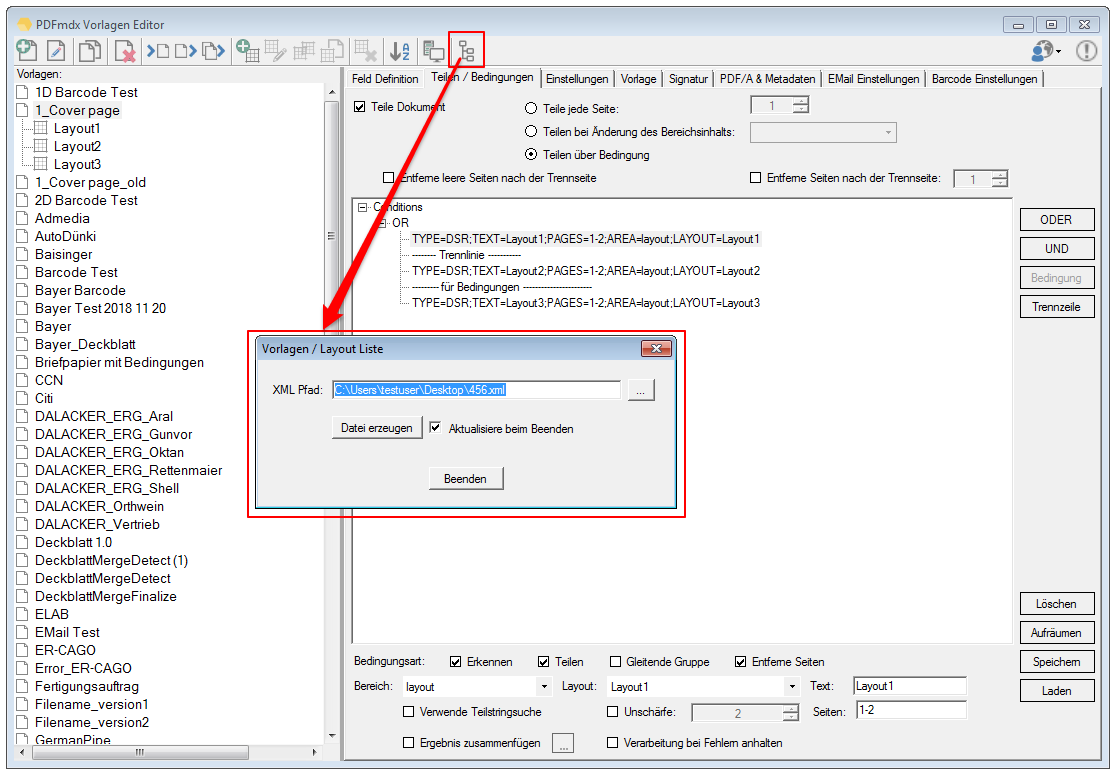
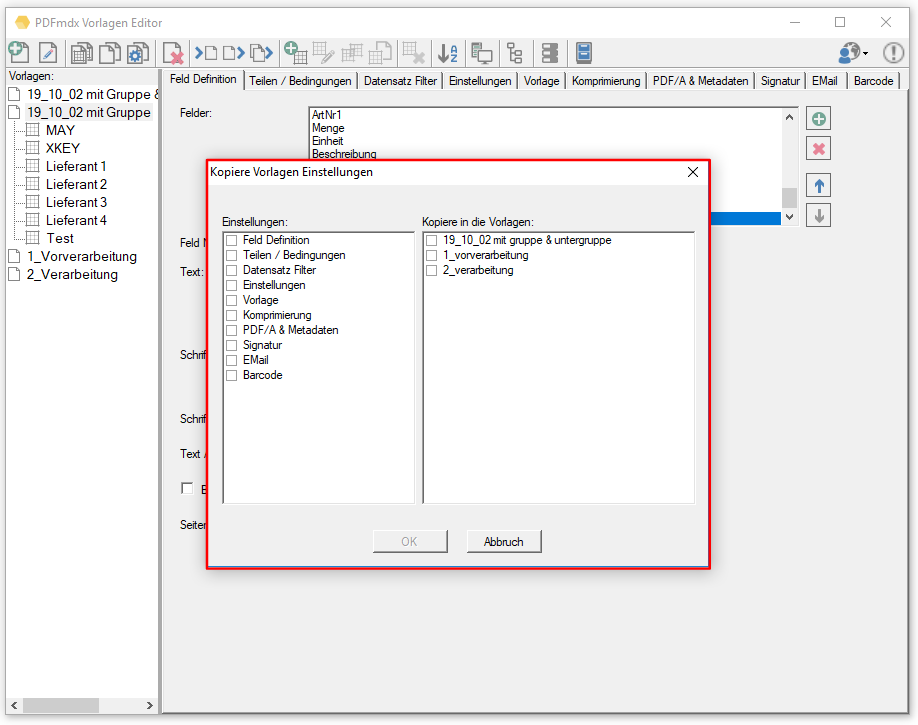
- Einstellungen einer Vorlage auf andere Vorlagen zu übertragen: Auswahl der Einstellungs-Tabs der Ausgangs-Vorlage sowie Auswahl der Zielvorlagen.
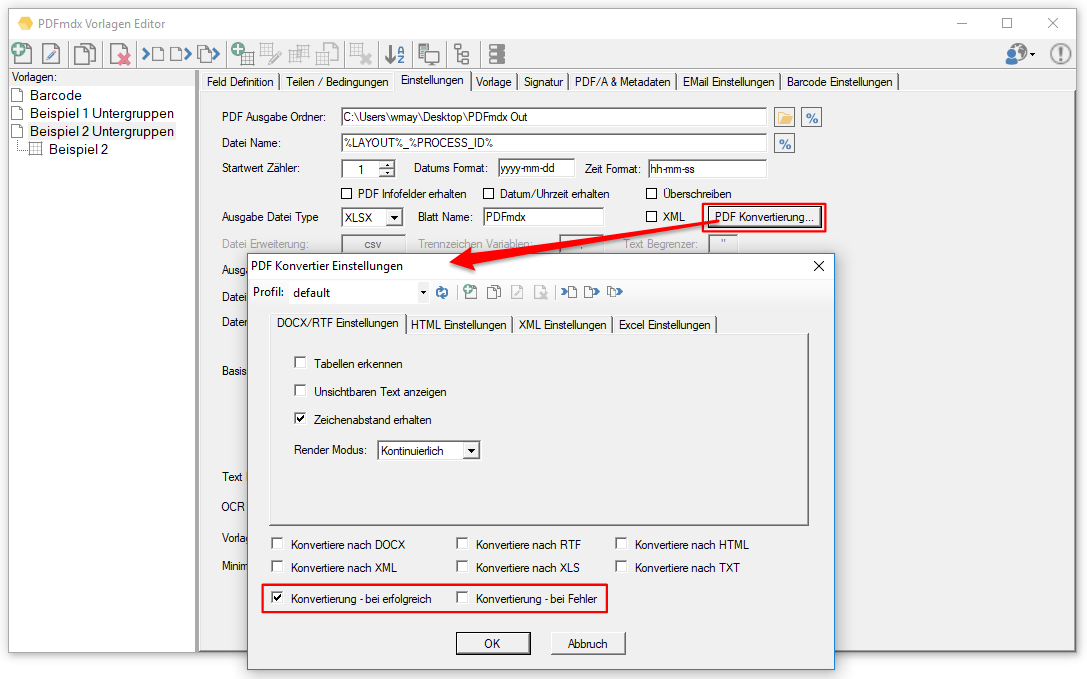
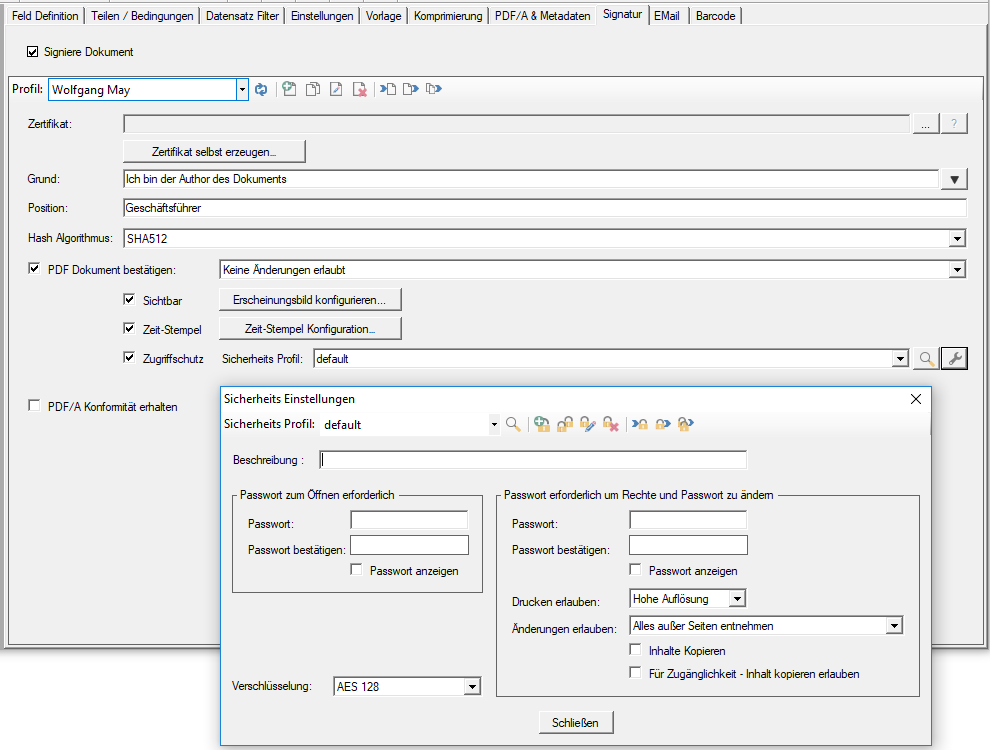
- PDFSign Komponente wurde integriert um die erzeugten PDF schützen und signieren zu können.
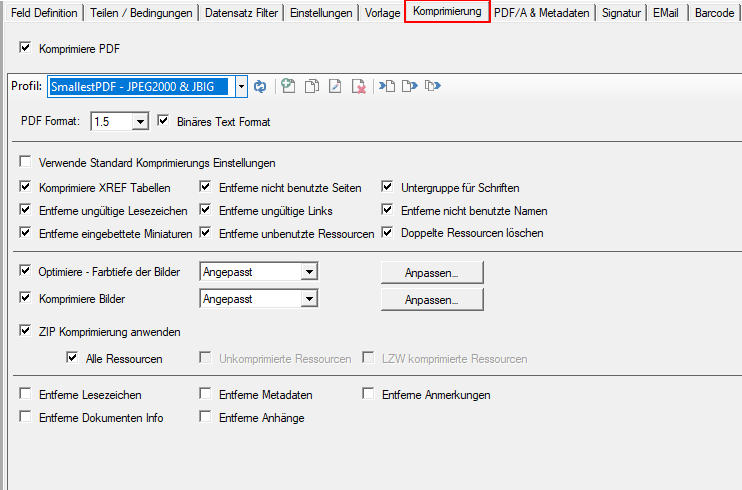
- PDFCompressor Komponente wurde integriert um optimierte und möglichst kompakte PDF Dateien zu erzeugen.
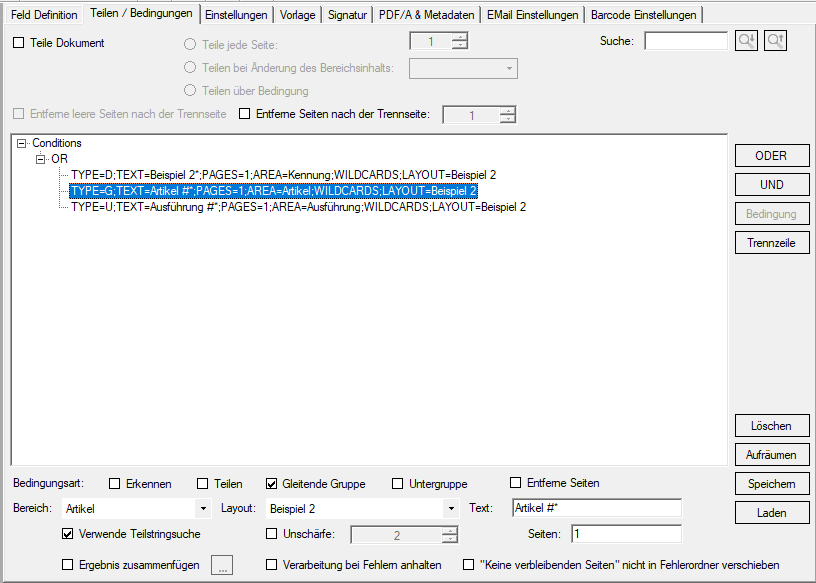
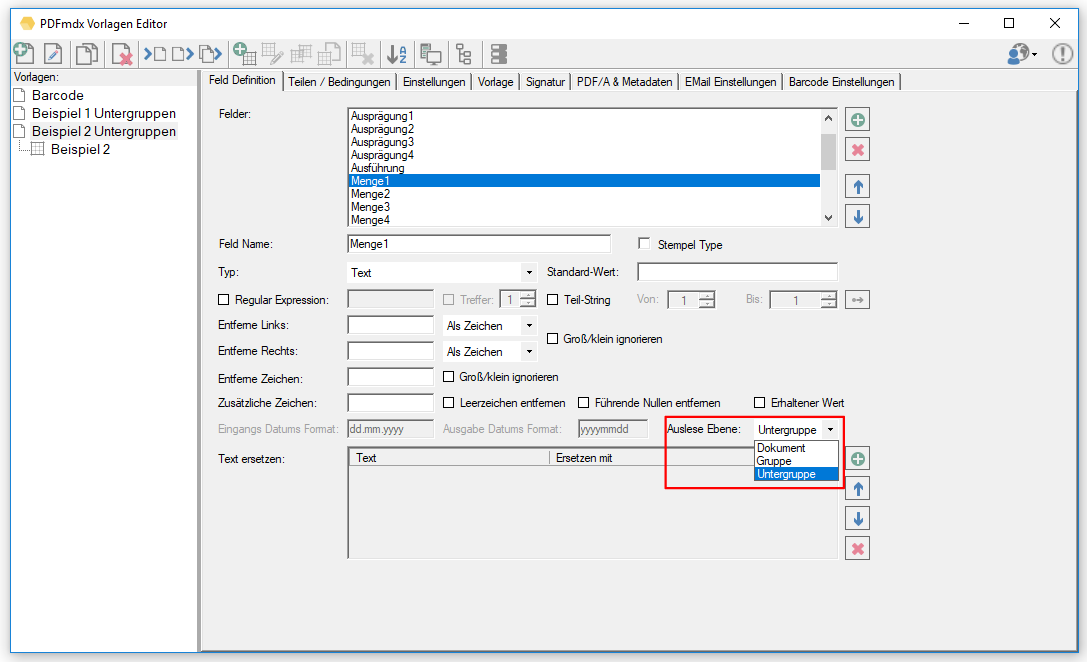
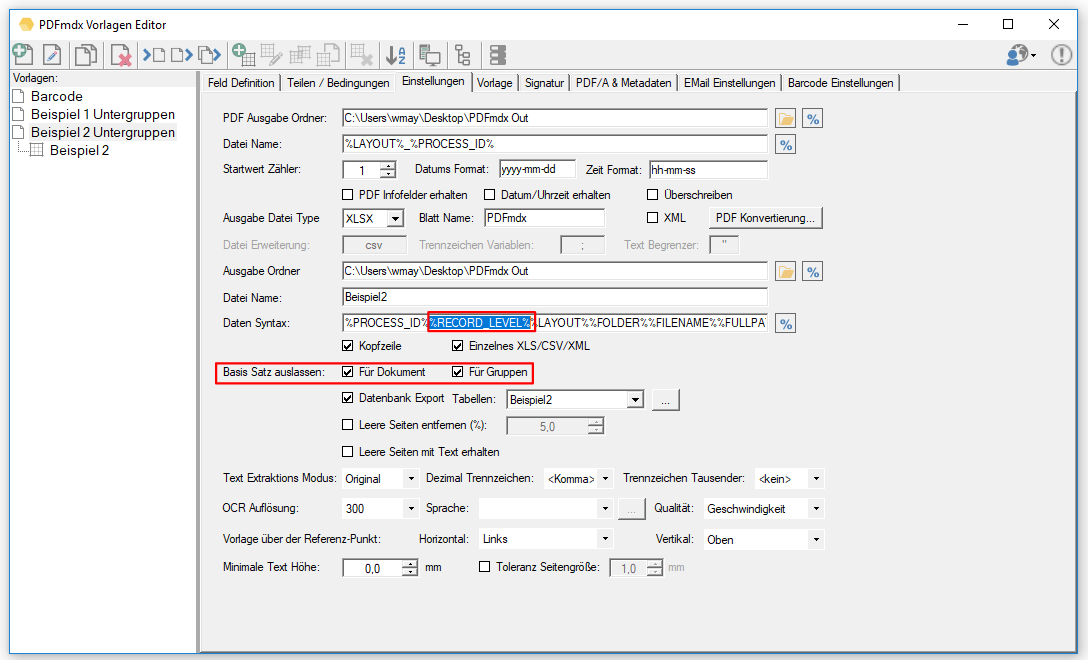
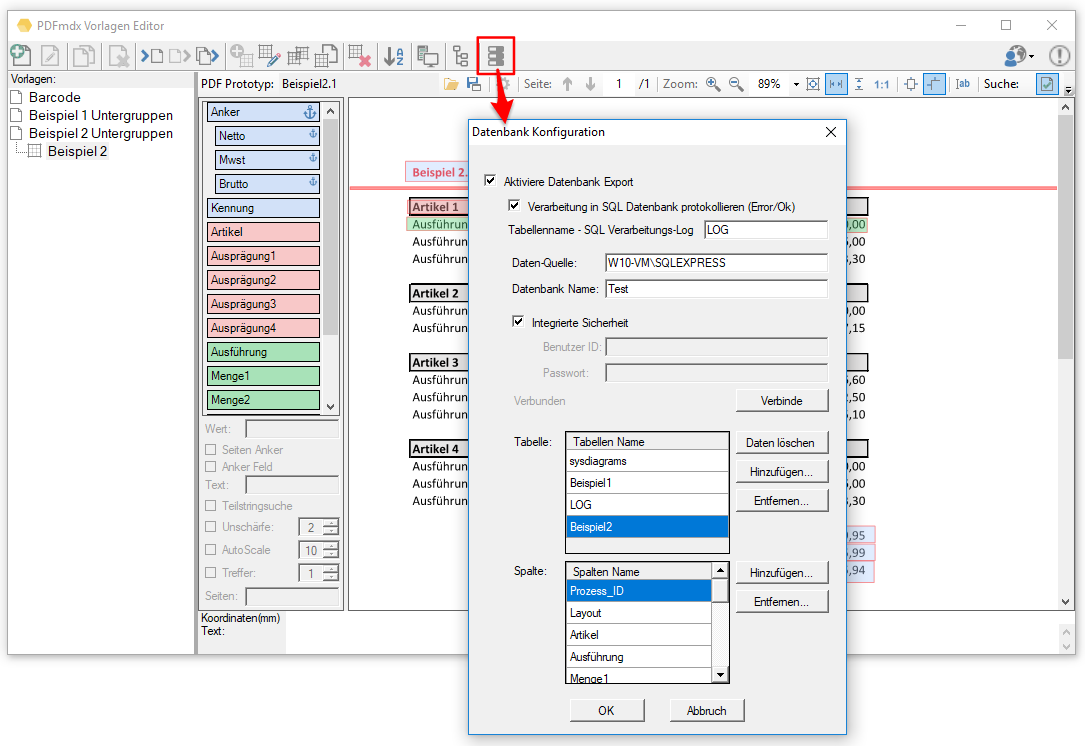
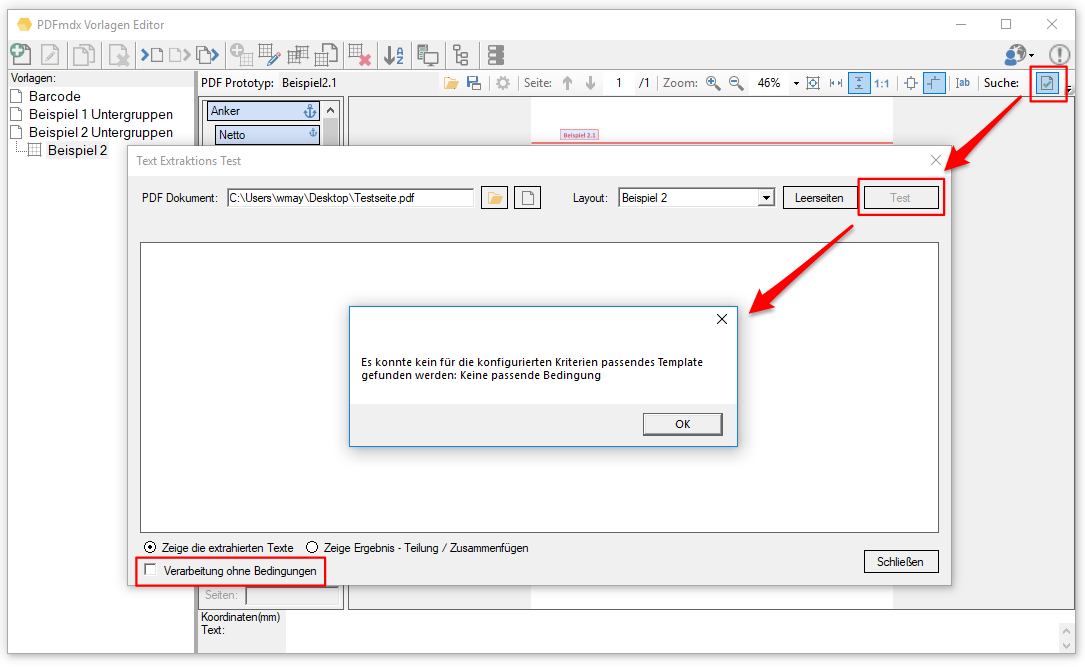
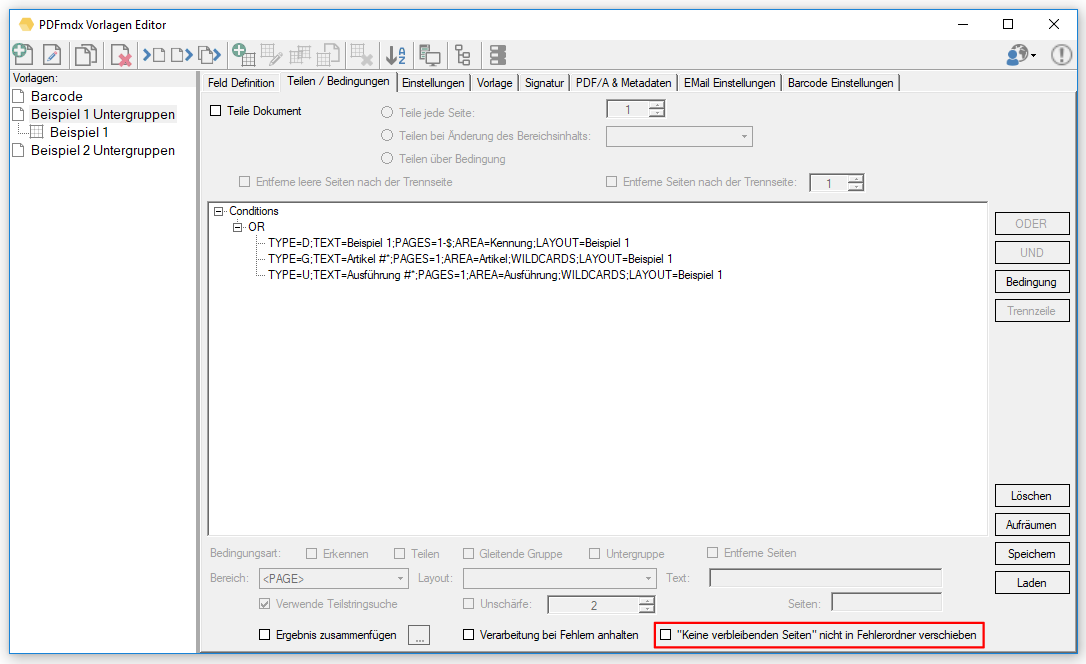
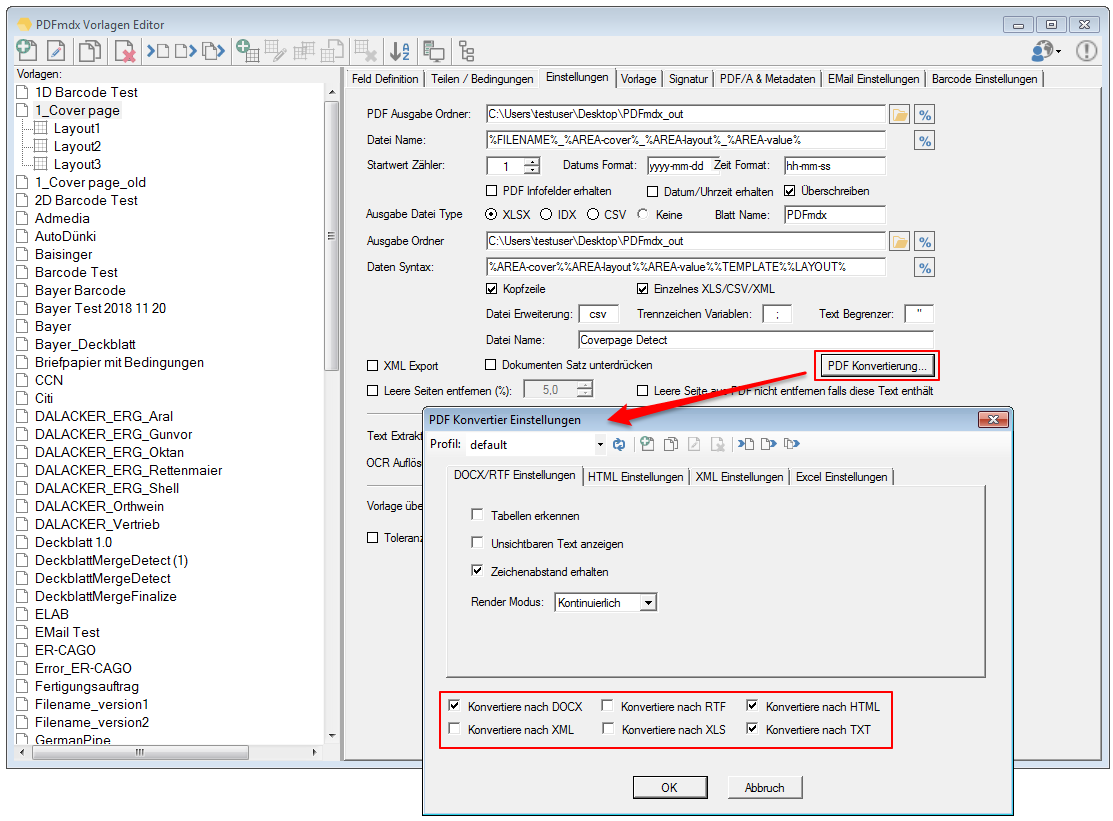
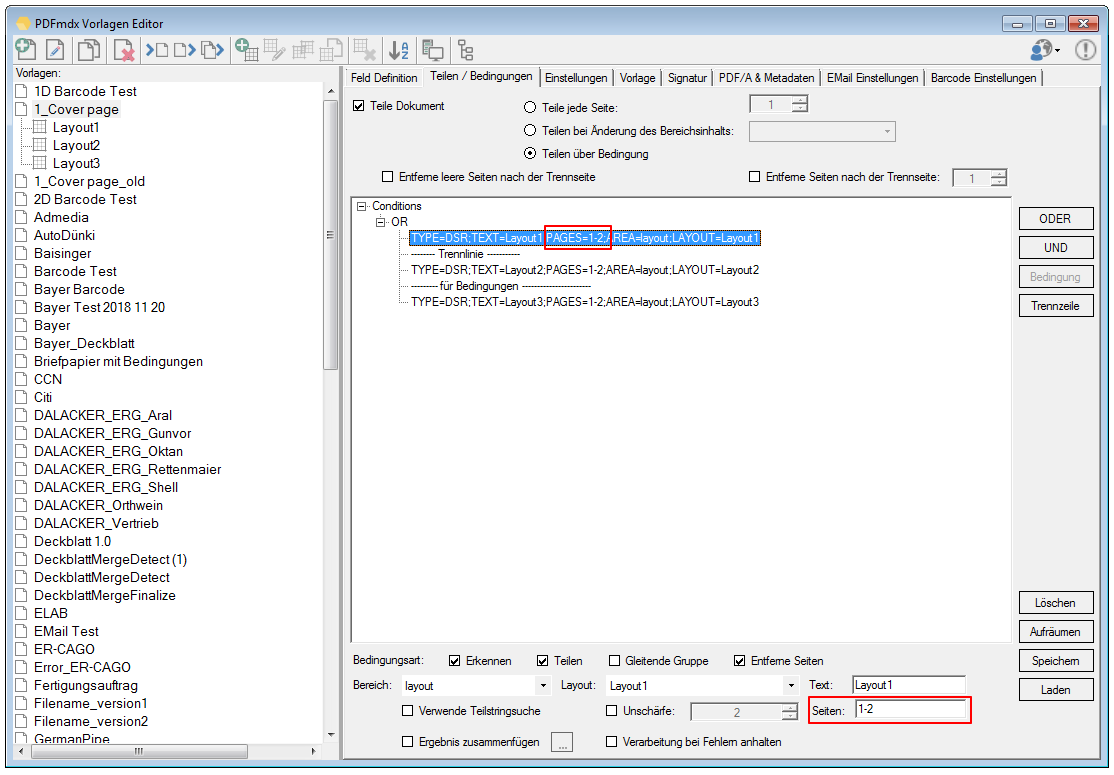
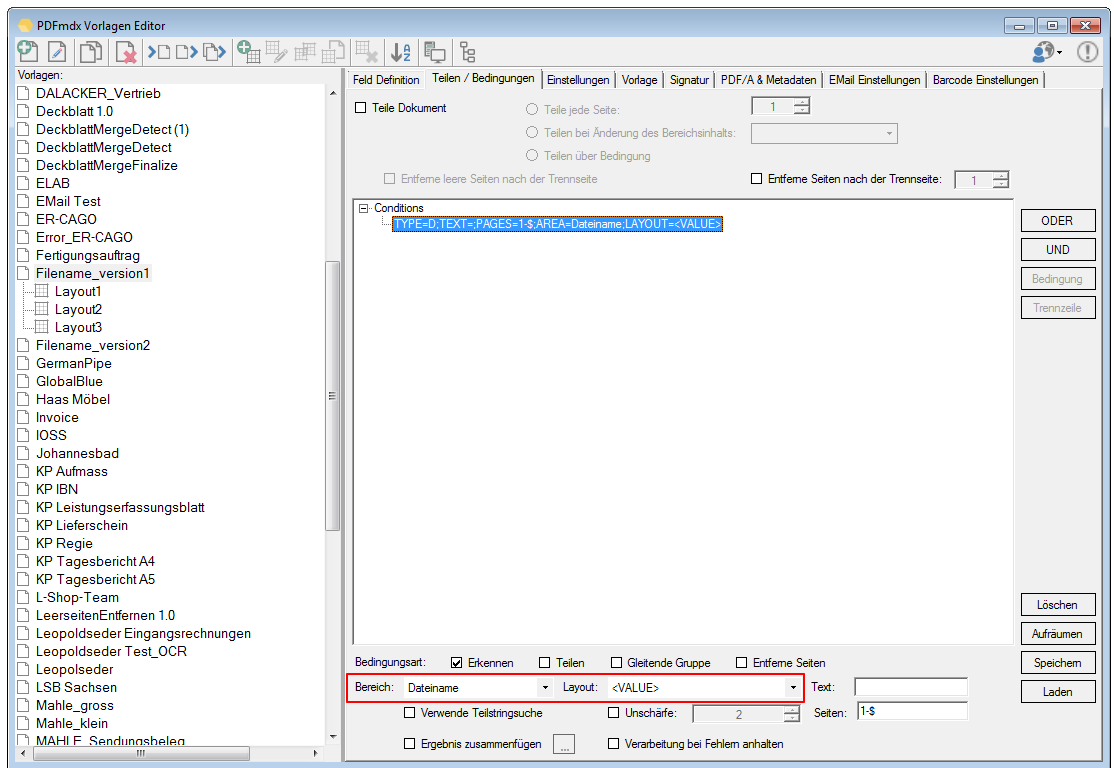
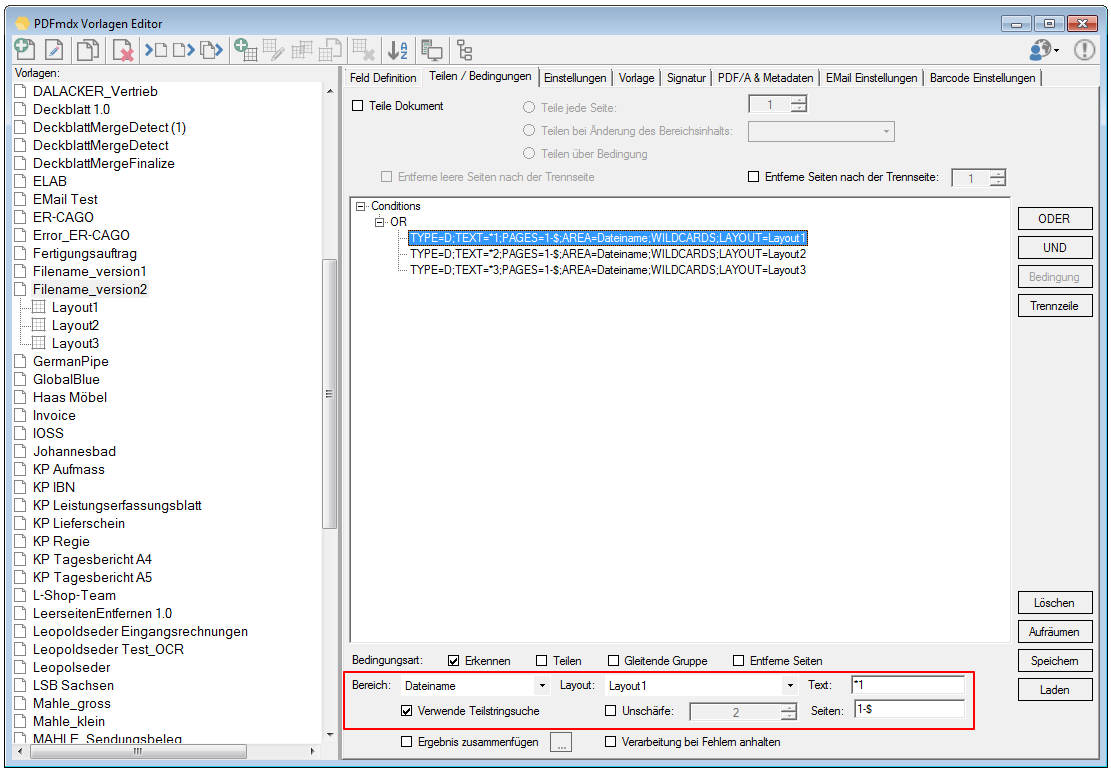
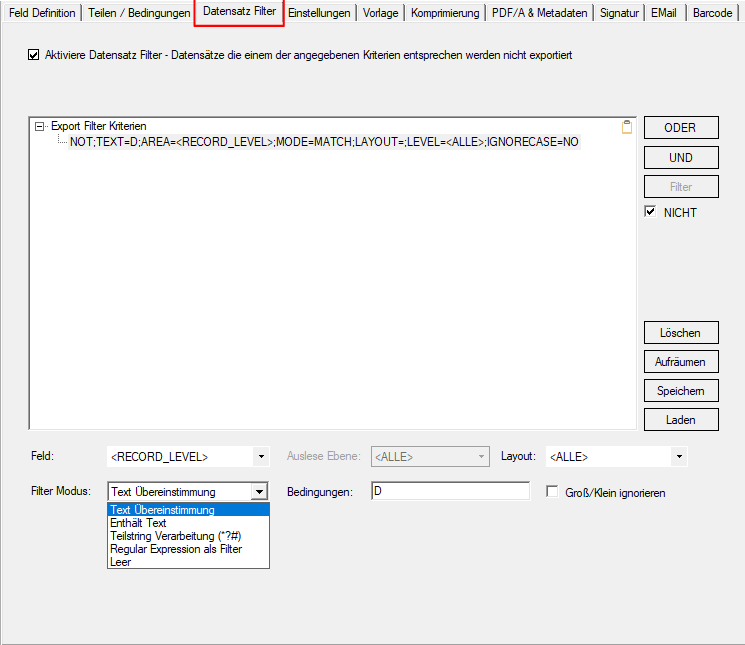
- Export Datensatz Filter: Über Bedingungen kann der Datensatzexport gefiltert werden. Datensätze die einer der definierten Bedingungen entsprechen werden gefiltert und nicht ausgegeben. Gefilterte Datensätze werden in der Testfunktion „rot“ markiert angezeigt. Bedingungen können auf Basis von Textstrings, Teilstrings, Regular Expression oder „Leer“ über Felder, Layouts und Auslese Ebene (Dokument, Gruppe, Untergruppe) sowie UND / ODER bzw. NICHT Verknüpfungen aufgebaut werden.
Neuerungen PDFmdx Prozessor Version 3.7.4:
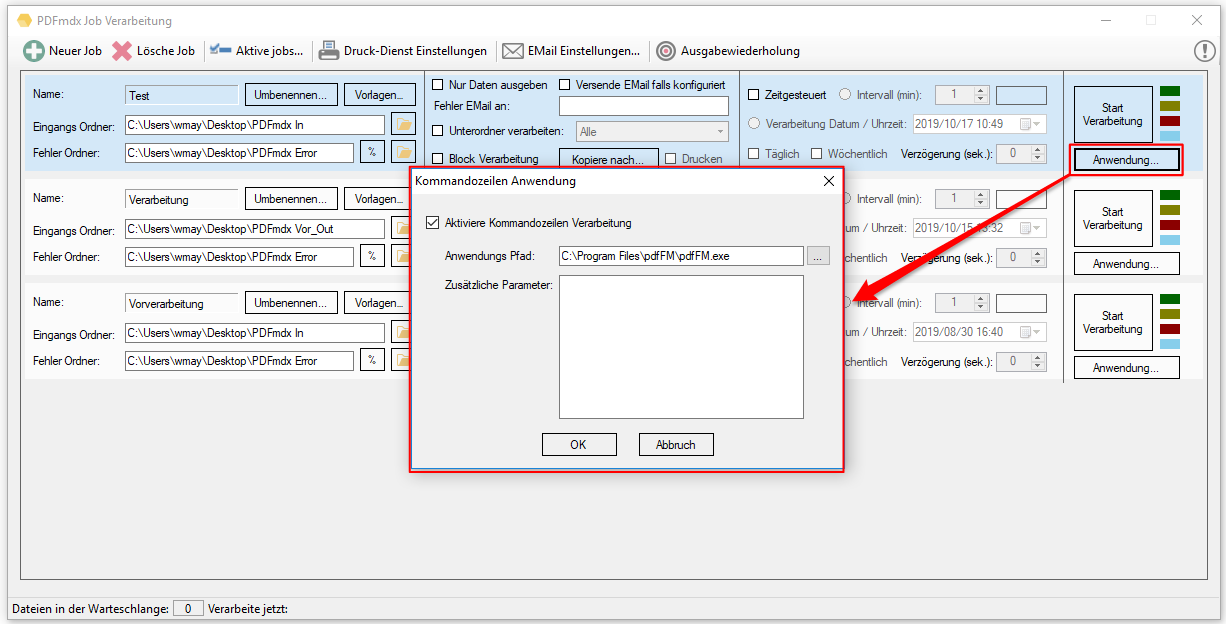
- Kommandozeilen Anwendung aufrufen: Nach der Verarbeitung aller Dokumente aus dem Eingangsbereich eines Jobs kann eine Kommandozeilen Anwendung aufgerufen werden. Z.B.: pdfFM um Dateien aus mehreren Ordnern mit gleichem Namen zu einer Gesamt PDF zusammenzufügen. Erfolgt die Verarbeitung über den PDFmdx Windows Service so darf die Kommandozeilen Anwendung keinen Dialog anzeigen und muss „silent“ ausgeführt werden.

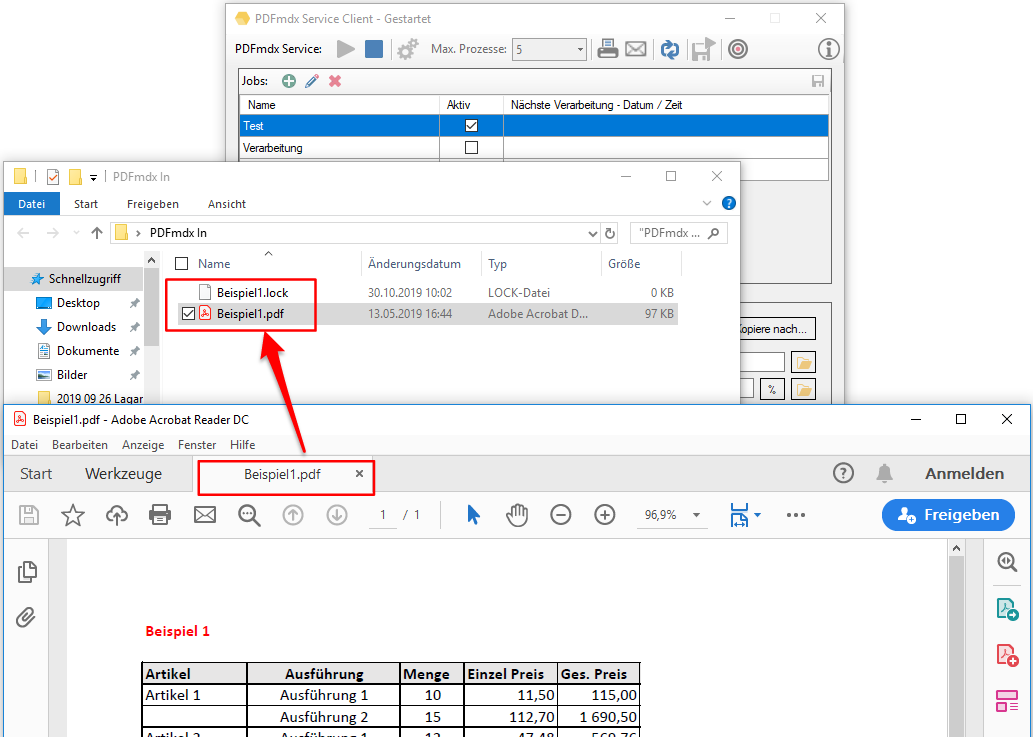
- Gesperrte Dateien werden erkannt und nicht verarbeitet: Falls eine zu verarbeitende Datei gesperrt ist kann sie weder verarbeitet als auch nicht in einen Fehler Ordner verschoben werden. Solche Dateien werden über eine *.lock Datei gekennzeichnet und nicht weiter verarbeitet. Um eine solche Datei später wieder zu verarbeiten muss nur die *.lock Datei gelöscht werden.
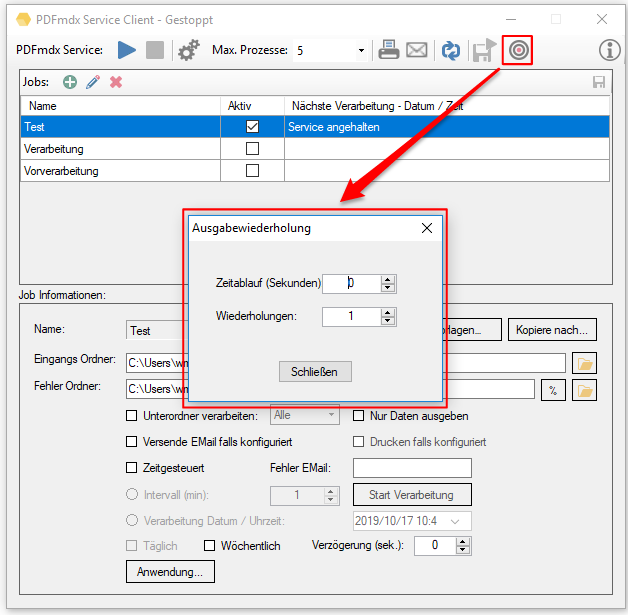
- Ausgabe – Wiederholung: ist ein Gerät bei der Ausgabe (Share / Netzwerklaufwerk) nicht sofort verfügbar bzw. reagiert zu langsam so ist jetzt die Wartezeit sowie die Anzahl der Wiederholungen einstellbar bevor die Verarbeitung diesen Umstand als Fehler erkennt und die Verarbeitung unterbricht.