PDF documents can be generated in different ways. PDFs are able to summarize various contents and sources in one document. Pages can be constructed from “normal” PDF content consisting of text, images, and vector graphics, and typically already have textual content that can be used for full text indexing and search. However, a PDF document can also contain scanned pages in black and white or color. Such pages or documents must undergo OCR recognition to insert the textual information for indexing and searching.
So there are certain PDF documents which either should not be subjected to any OCR processing, or only individual pages or all of them have to be processed because they were generated by a scan process.
Normally, all these types of PDF documents occur in business processes and the user can not distinguish whether or not a document needs to become OCR – viewed from the outside via the Adobe Reader or on the printer, this can not be immediately recognized and distinguished.
If you would generally process every PDF document / page in the same way, regardless of how they are structured and whether an OCR processing makes sense or not, there would be some disadvantages:
Each PDF page is “rasterized” again, regardless of the structure and content, ie converted into an image and then processed OCR. This is like printing the document, scanning it again and then subjecting it to OCR processing. This gives you a picture from a “normal” PDF page with underlying text recognized by the OCR engine.
- the quality is not the same as before
- the documents become bigger
- special PDF properties are lost (bookmarks, links, etc.)
- Processing time and resources are consumed
- OCR page licenses are consumed unnecessarily
A PDF OCR processing should therefore be “intelligent”, so that in the process and by the user does not have to decide with difficulty whether a PDF document must be subjected to OCR processing or not. Even more difficult is when a single PDF document consists of mixed normal and scanned parts.
That’s why we’ve integrated intelligent OCR processing into AutoOCR, which works in the same way with both the Abbyy and the iOCR OCR engine. This can be controlled per input folder or for the web service interface via the OCR profile and is available for both PDF> PDF and PDF> TXT processing.

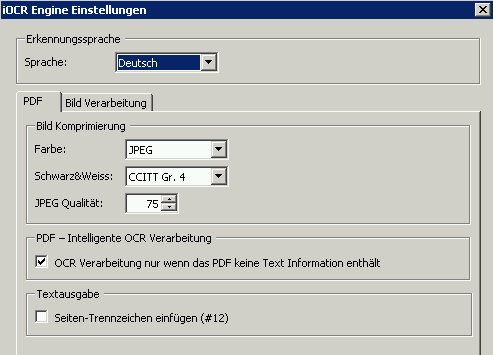
Highlights – Intelligent PDF OCR processing:
- works for both PDF> PDF and PDF> TXT processing
- for the Abbyy OCR and iOCR engine
- at the folder as well as for the web service processing
- the PDF document as well as every single page are analyzed and only those pages OCR are processed that do not contain any text – these are usually scanned pages that have not yet been processed by OCR.
- existing normal PDF documents and pages are taken over unchanged and not processed
- OCRed documents and pages are not processed again.
- in the case of PDF> TXT processing, the text is extracted from the normal PDF pages and OCR is only performed on pages without text.
- PDF functions and bookmarks are retained and are included in the target document.
- Saves processing time and Abbyy OCR page licenses
- the files are not enlarged
- the quality of the PDF pages is preserved.
The “intelligent PDF OCR processing” can be found in addition to AutoOCR in all other of our software products that support OCR processing z.b. ifresco Profiler, FileConverter, DropOCR, PDFMerge, etc.