Innovations PDFmdx Version 2.8.1:
Template synchronization:
The PDFmdx template editor can now match the locally created templates and layouts via a web service connection to one or more PDFmdx servers. This allows templates to be developed and tested locally, to be replicated to the processing servers later. Communication is via SOAP via http / https. This considerably simplifies and accelerates the matching and distribution of new and updated templates.


Textstamp with rotation angle:
To apply a text not only horizontally, but at any angle, there is now the additional “angle” parameter.

Anchor Field Search – New Features:
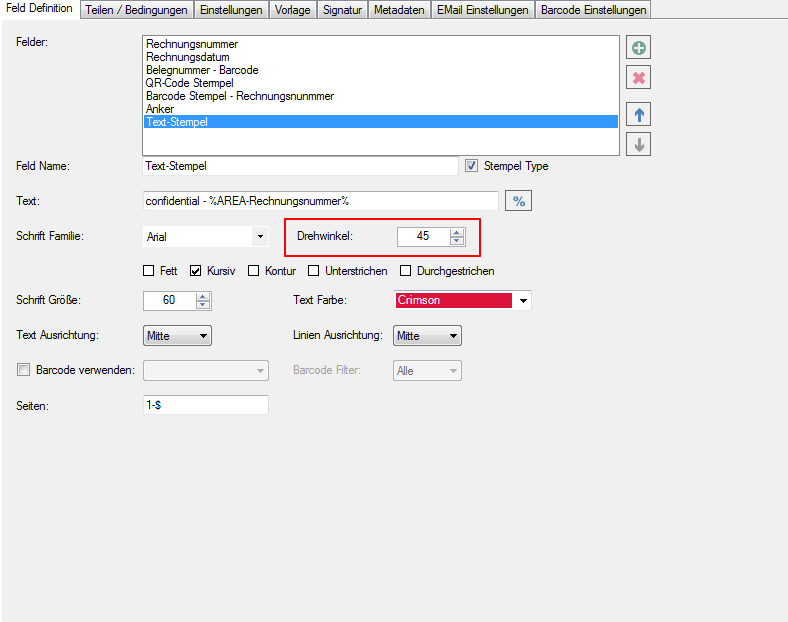
So far, the string for the positioning of the anchor field on the entire page has been searched (from top) and the first reference was assumed as the position for the anchor field. However, it may occur that the term is not the first but the next occurrence is the search position, and there is no other unique way to position the field over a search string. Therefore the function was extended.
By default, the anchor field search is now performed from the field position of the template. The next matching string is taken as the position for the anchor fields. A new addition is the ‘hit’ option. If it is activated and a number is specified, the page is scanned from top to bottom and left to right for the anchor text. The number indicates the number of hits as an anchor field position. So eg. the 2nd hit can be found on a page as an anchor field position.
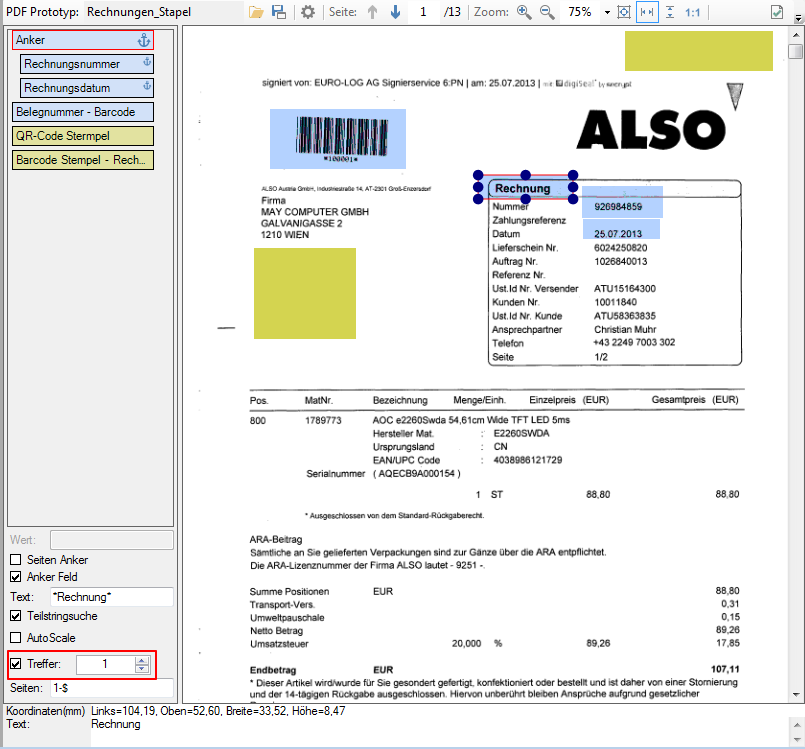
AutoScale-function:
Especially in the case of scanned documents it can happen that the contents of the documents on the page vary not only in their positioning horizontally or vertically, but documents can also have different scaling and sizes. Z.B. For example a scanned expression with different scales was created. Although the relative position and size of the fields to be read is the same between the documents, the absolute values are different. The layout for the reading of the fields is created using a typical document and so far only considered the absolute distances and sizes of the fields. A document that appears about 10% smaller on the A4 page could not be processed, because the fields compared to the created layout both of the position so synonymous of the size does not fit. For this, we have now implemented an AutoScale function, which is able to automatically compensate for such different scaling to a certain extent.
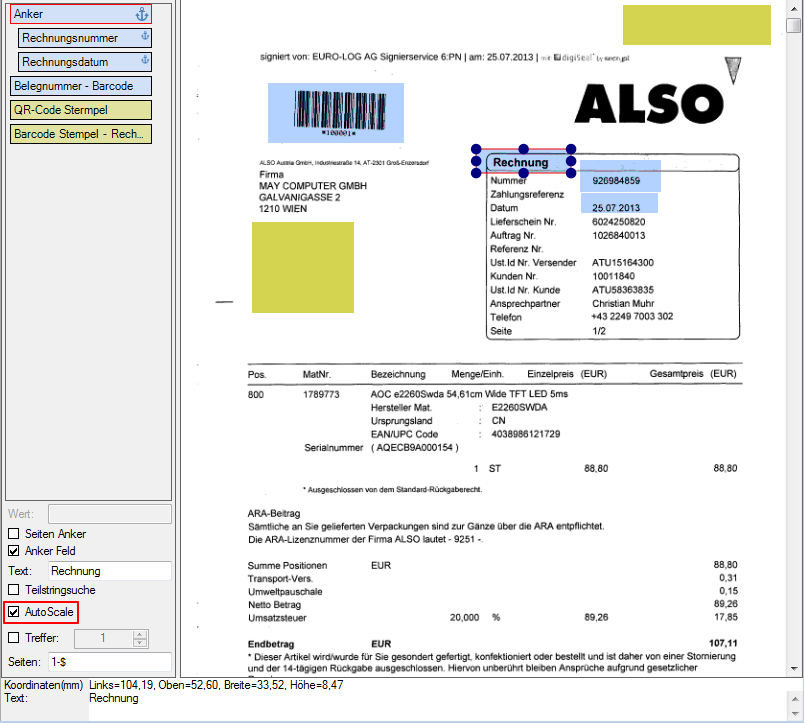
What is to be considered:
- The layout should be created from the “largest” version
- An anchor field must be used that can be found without partial string search. E.g. Via the string “Invoice” but not via “* Invoice *”
- The “AutoScale” option must be activated.
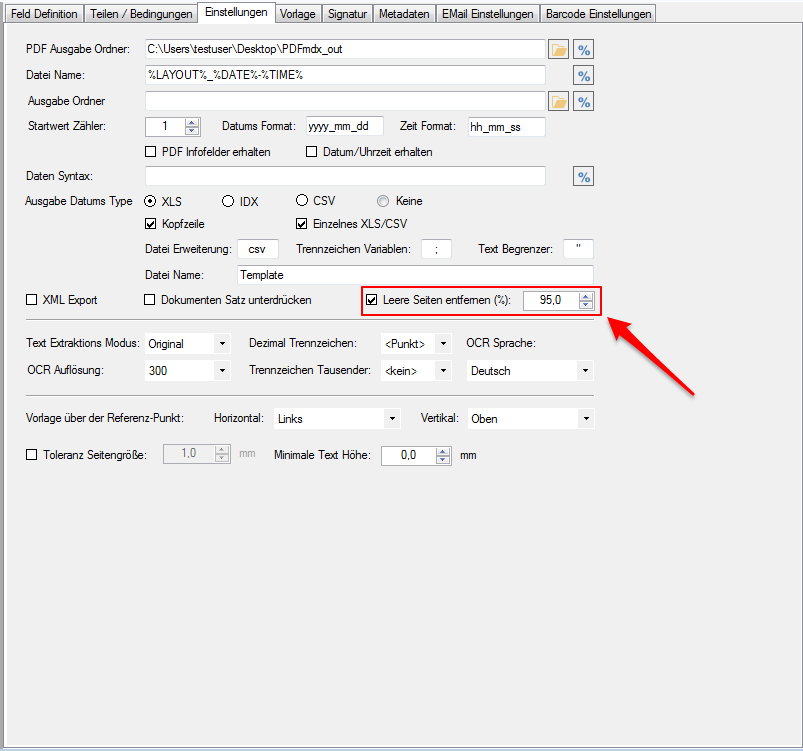
Detect and remove blank pages:
When scanning documents, duplicate scans may contain blank pages (partially unprinted backs) in the document. Scanners do not always have a function to automatically remove them during the scanning process. For the further processing and archiving, empty pages are disturbing and should be able to be removed. With the current PDFmdx version 2.8.1 there is now a function to automatically detect and remove blank pages. The criterion for detecting a blank page is a threshold value which is set to 95% by default. We recommend a value between 95 and 98%. The value specifies the percentage of the “white pixels” on a page. A page is identified as “empty” as soon as the proportion of white pixels is greater than or equal to the set value, e.g. 95%. Blank pages are removed before all other PDFmdx processors are started.
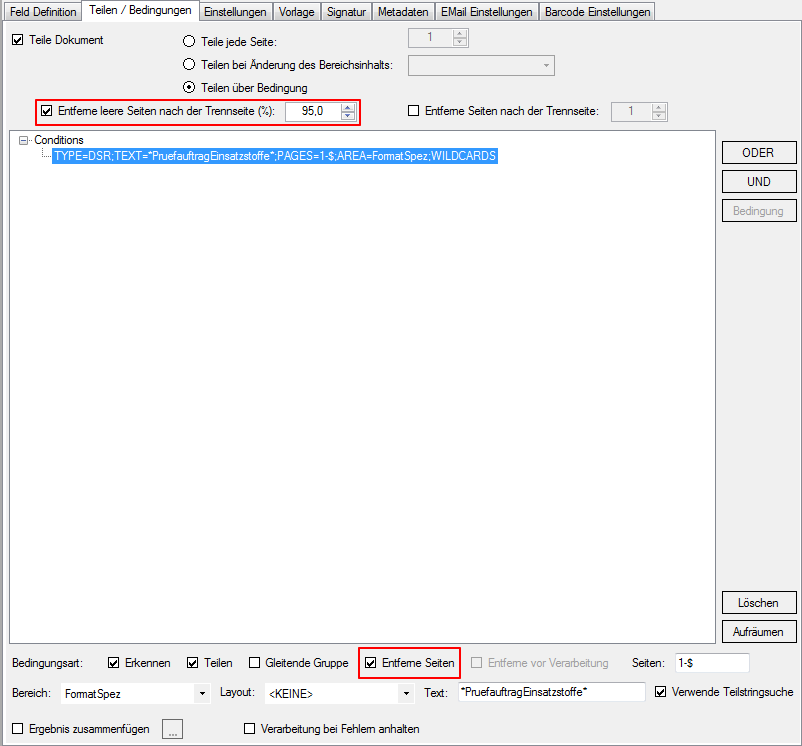
Remove sides / blank pages after the separation pages:
If a document is split, the found separator page can also be deleted. New addition is now also a function to delete the following pages of the separation page. In this case, either a certain number of subsequent pages to be removed can be defined, or the function for automatic page identification / removal with threshold values can be used.

Regular Expression Parameters to selectively extract numbers from a field:
RegEx expression “\ d +” can be used to return numbers of a field. If no parameter is specified, we automatically return the “first of the longest of the found numbers”. (E.g., the read-out field content is “page 15/110”, “110” is returned). Together with the “Hits” parameter, a number of a specific position can be extracted from the string. With parameter = 1, the first number found in the string “15” is returned with 2 the second “110” and so on.
RegEx can also be used in combination with the additional string formulations:
Up to now, only the RegEx processing or alternatively the other string processing functions could be used. Now it is also possible to combine these two functions – RegEx can therefore be used together with the functions – partial string, remove – left / right / space / leading zeros as well as the function characters and type selection. The RegEx processing is executed first, regardless of the type of the field.
%TIME% Variable – Now in 24 hour format
Update to SQL Compact Version 4.x – The version is now already included in the setup and does not have to be reloaded and installed as usual with version 3.5.