Innovations – FCpro version 1.0.86:
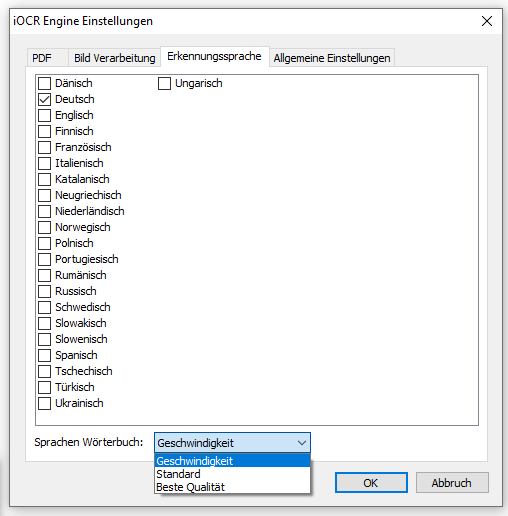
- FCpro’s iOCR Standard OCR component is now based on the new Tesseract OCR version 4.0. This makes it now possible to recognize documents with multiple languages. Multiple languages should only be activated if required, as each additionally activated language increases processing time accordingly.
- Option to select OCR accuracy/speed – There are 3 different recognition profiles available for OCR detection – “Speed / Standard / Accuracy”. By default, the “Speed” profile is preset, which in this selection corresponds to the OCR recognition accuracy of that of the previous version. “Standard” and “Accuracy” bring improvements in OCR recognition quality to the previous versions, but take longer to process than the “Speed” profile. However, different settings can be preconfigured and easily and quickly switched using the FCpro processing profiles.
- The new version of iOCR will be installed as “vsOCR4” in version 1.1.4 via the FCpro setup. This results in a new FCpro installation requirement. iOCR now also requires the “MS Visual C ++ 2015” instead of the “MS Visual C ++ 2005” runtime. The presence is automatically checked during installation and installed if necessary.
![]()
- Configurable parameter for splitting OCR documents with multiple pages: During OCR processing, the iOCR component loads the document to be processed completely in the main memory. In this case, e.g. a 500 pages Black&White, 300dpi document needs about 1.2GB of main memory. However, FCpro can also run several processes in parallel, which can quickly run out of resources depending on the configuration and size of the documents being processed. In order to be able to better control the required resources and their distribution to several parallel processes, it is possible to specify via a parameter from which number of pages for OCR processing a document automatically splits, processes the sub-documents seperately and finally reassembles it into a complete document.
FCpro determines a default value based on the available resources using the following formula:
Number of pages for OCR Split = Number of Cores/CPU * 5 + (GByte RAM/2)*5
This results in e.g. with 2 cores/CPU and 4GB RAM = 2*5 + 2*5 = 20 as default value, which can be changed individually.

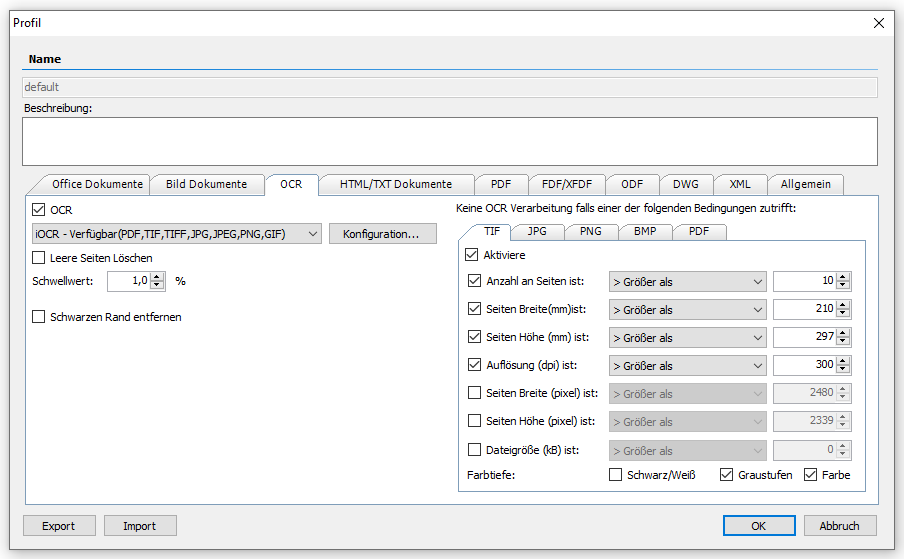
- Advanced options for conditional OCR processing: The OCR conditions can now be set individually for each file extension. In addition, the file size (in kB) and the color depth (Black&White, grayscale, color) can be used as criteria. For multi-page file formats (PDF, TIFF) the criteria are checked based on the parameters of the first page.
Download – FileConverterPro (FCpro) (from 1.0.86 ~600MB ) >>>