In addition to document fields, PDFmdx can also read position data. Position data is lists or tables with rows and columns. These are typically found on invoices to cite several items in the document. We use the term “sliding group / subgroup. One or more columns (= fields) in on or more rows, on one or more pages, are searched and read in a vertically defined area.
From the PDFmdx version 3.5.0 there is a 2-stage structure where in addition to the groups a subgroup level is also possible. One or more subgroup datasets can be recognized and read out for a group dataset. There are documents with 2-stage position data, eg. in the case of textiles or clothing where an item (number, description) can also have a “sub-level” with sizes or color specifications. The item itself is simply listed and in the level below there are the quantities / prices for individual characteristics.
Two-level readout of position data:
- “Document/Group/Subgroup” fields define the detection level.
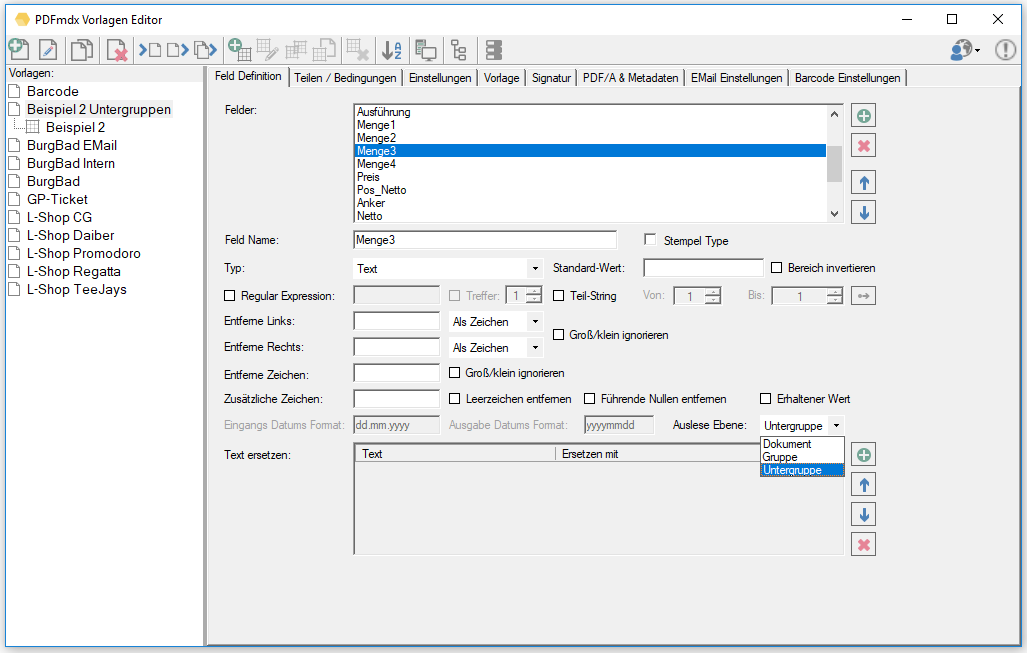
- An area defined by 2 red horizontal boundary lines will be scanned on all pages of the document for the group (red boxes) and subgroup (green boxes) records.
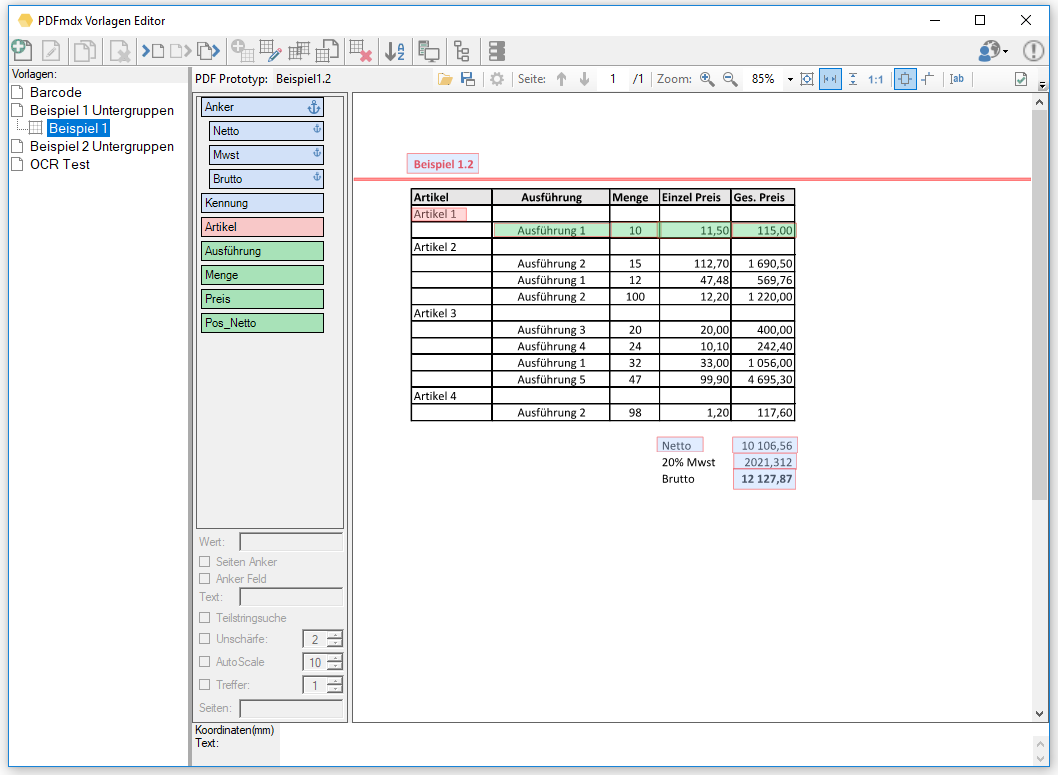
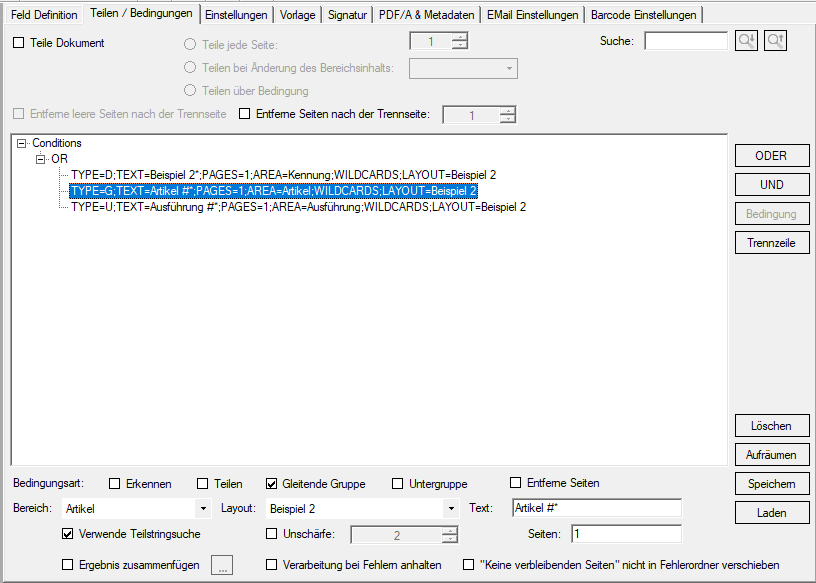
- The specified conditions are used to identify and read out the group (G) and subgroup (U) data records.
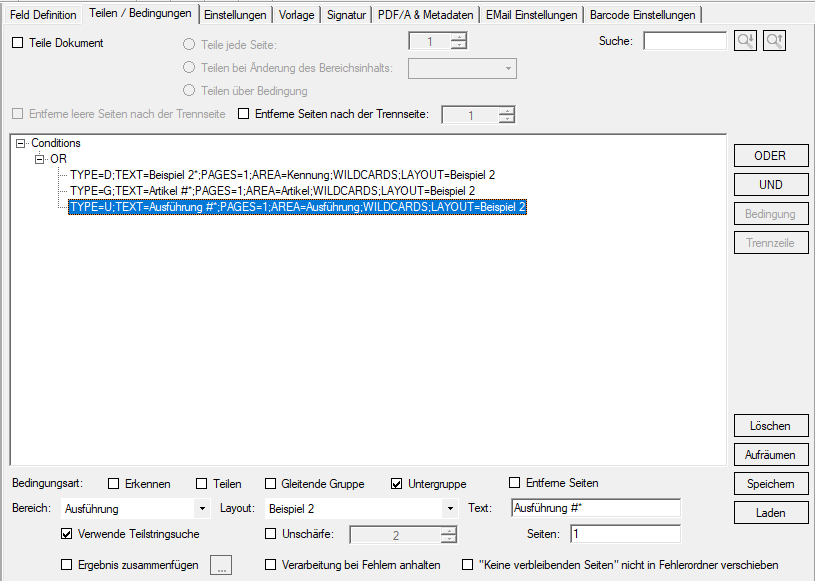
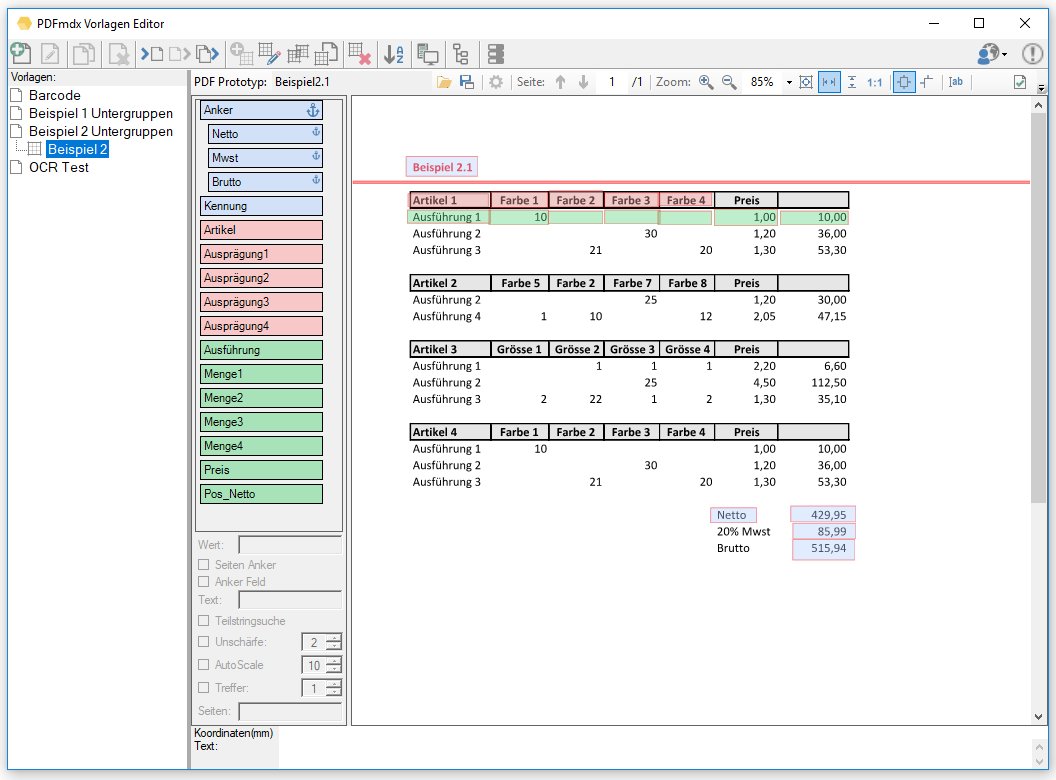
- Along with the lowest-level records, the information of the group and document fields is also available.
For tests and as a starting point for your own tests, we have created two example templates with PDF test files. The *.pmdx templates only need to be imported into the PDFmdx Editor via drag&drop and the output path may need to be adjusted. For processing, it is then necessary to create a job with input and error folders in the PDFmdx processor and to select the two test templates for the job.
Download – PDFmdx – Templates and examples for two-level reading of position data >>>
Download – PDFmdx Template Editor & Processor >>>