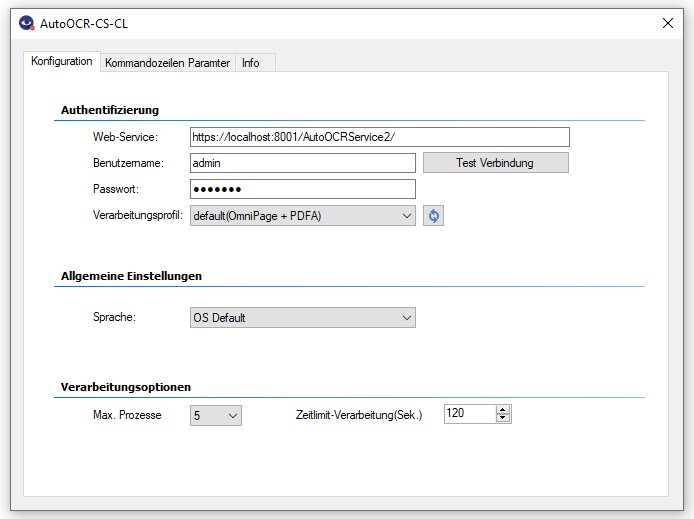
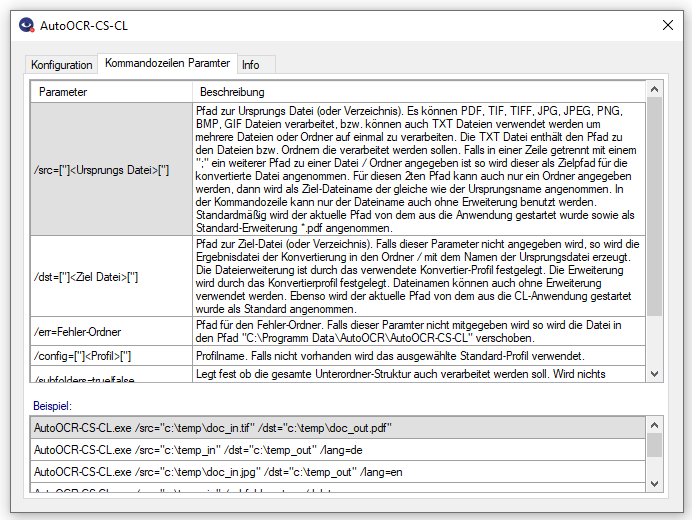
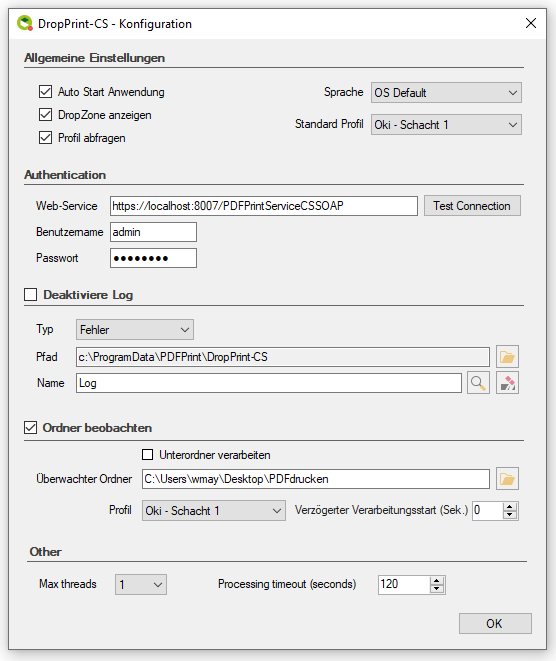
PDFmdx – Reading position data via a sliding group – Product video
PDFmdx can read information from PDF documents via defined areas and assign them to a field. However, there is also information in a document that occurs several times. For example, position data of invoices – quantity, article number, price etc. These are usually executed as tables in fixed columns and a variable number of rows.
PDFmdx is also able to read position data from PDF documents with the help of “sliding groups”. Fields are assigned to a “sliding group” and positioned on the template document. Criteria define conditions to identify a row as a “sliding group” record. Two delimiters determine in which vertical area of the pages such data records are searched for.
The following video also shows the use of “anchor fields” to find and read information which is “moving” on a page and has no fixed position, e.g. the final amount of an invoice.