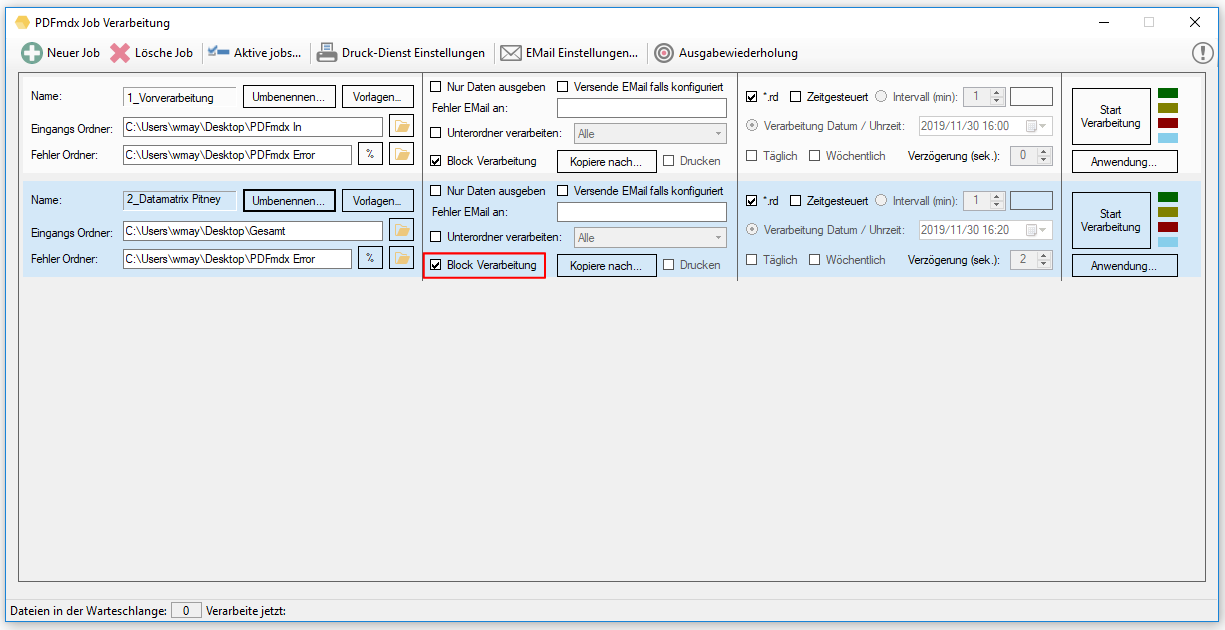
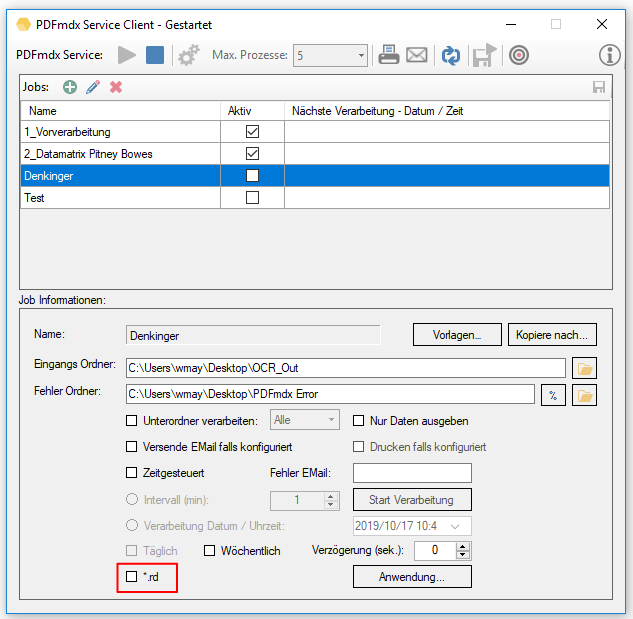
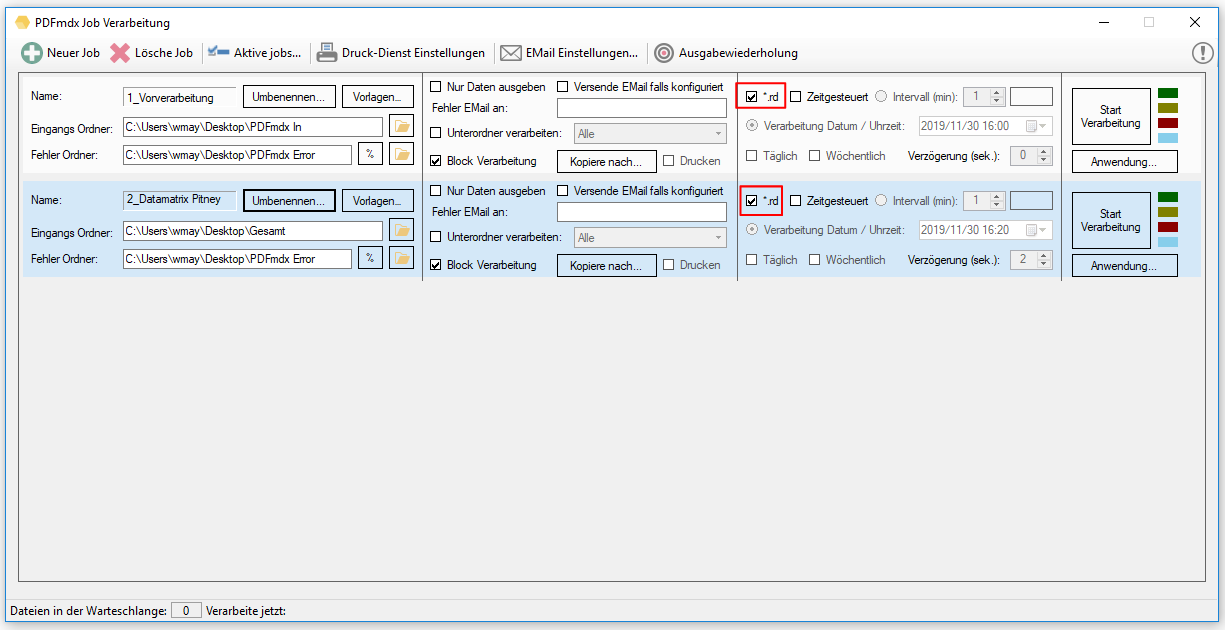
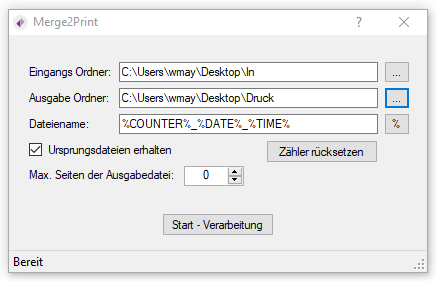
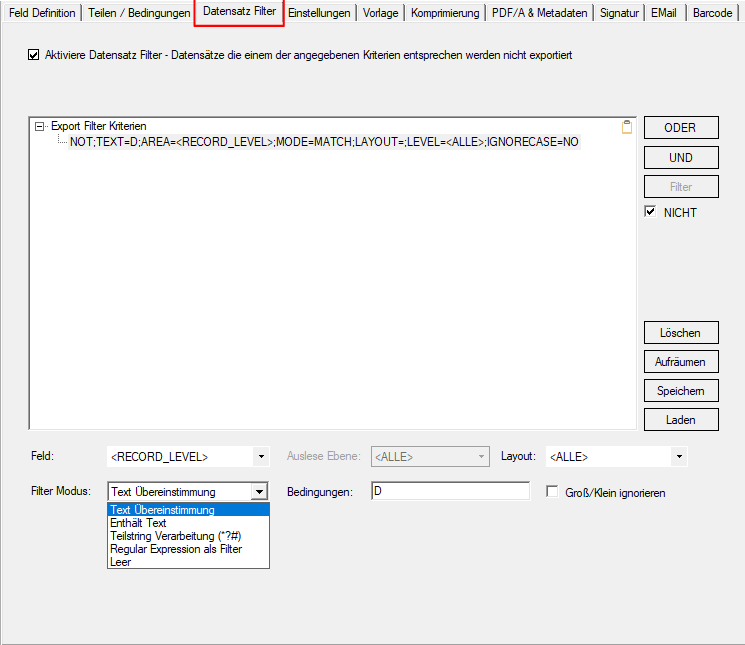
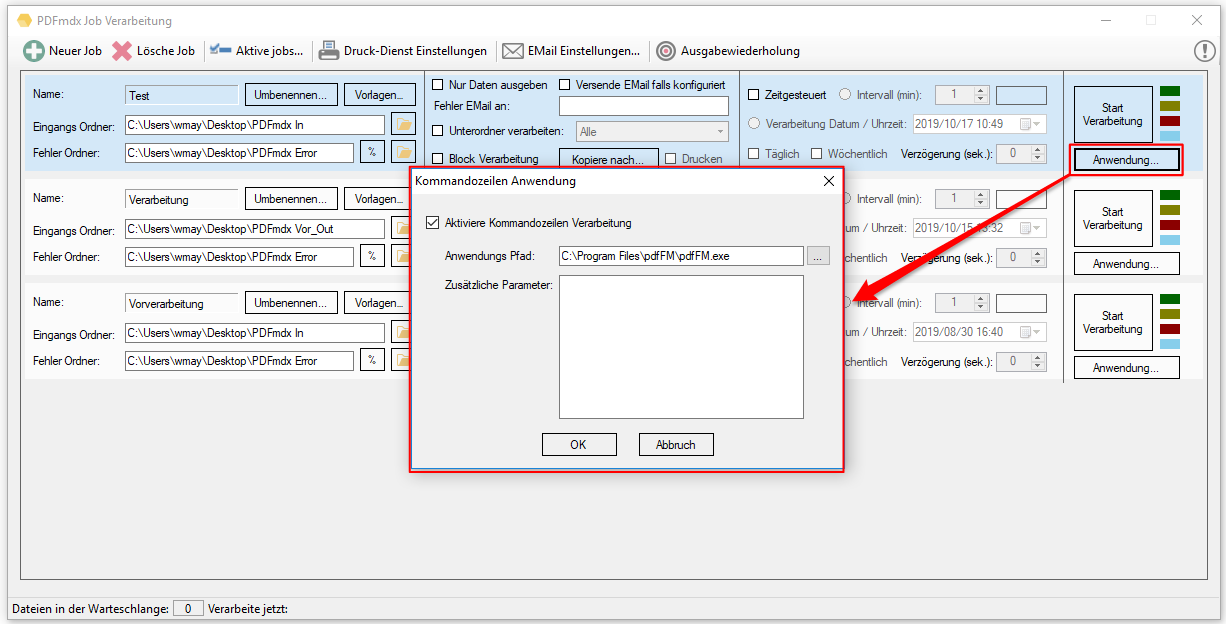
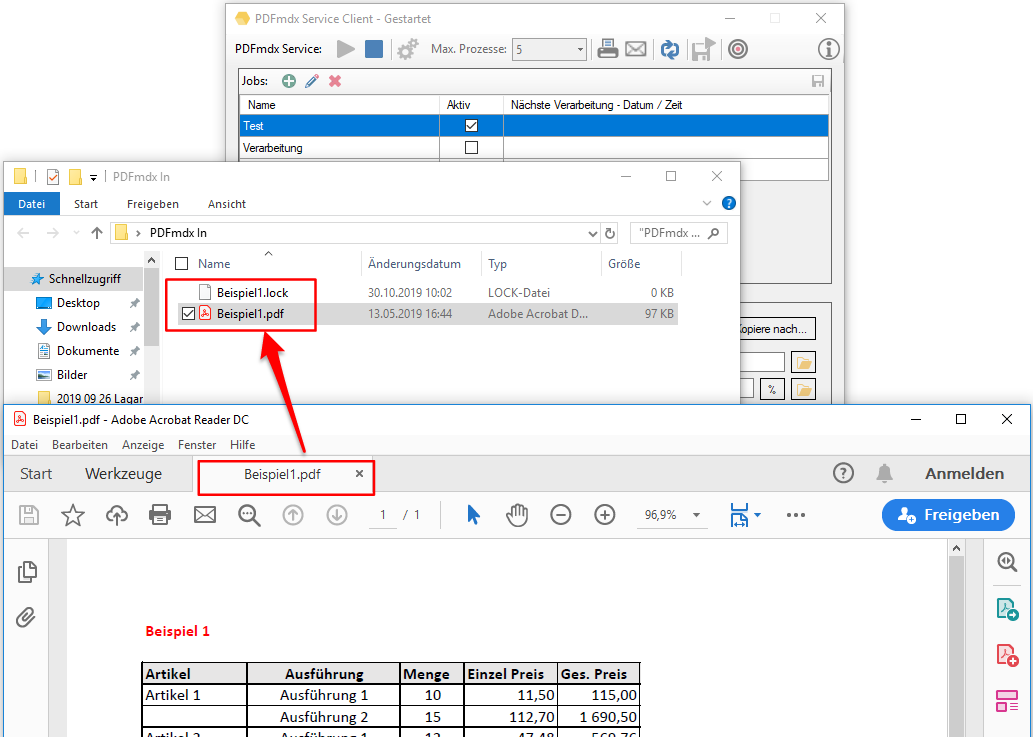
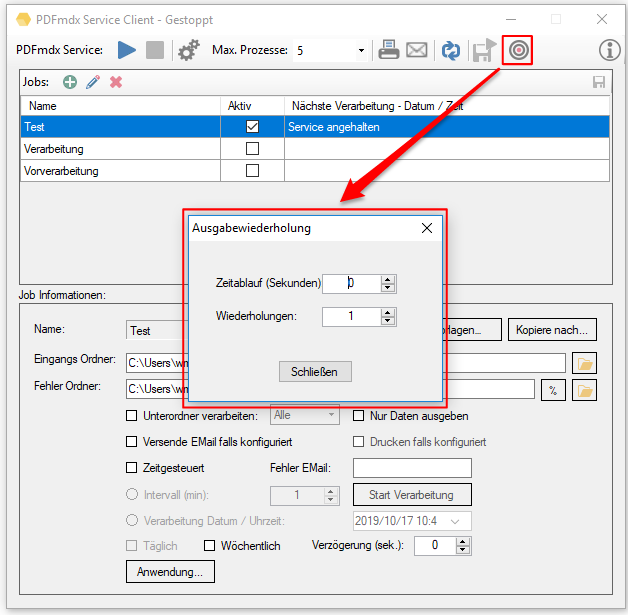
PDF2PDFA-CL Version 1.1.7
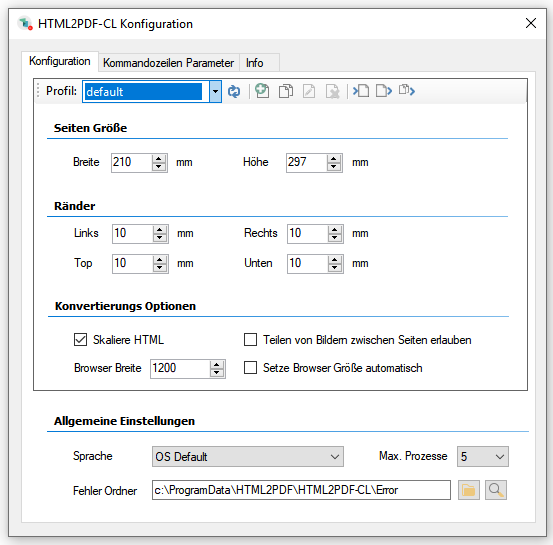
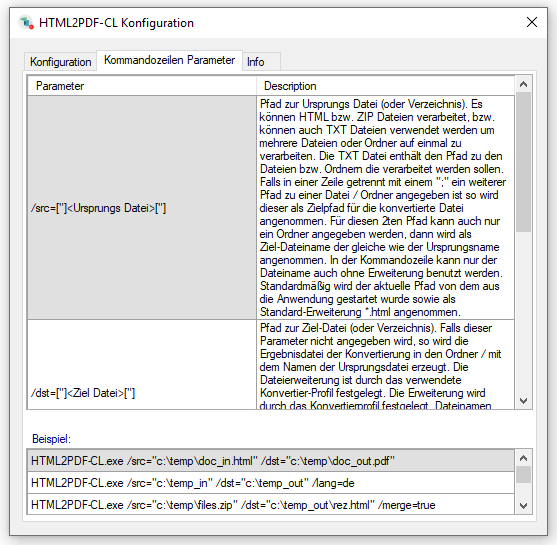
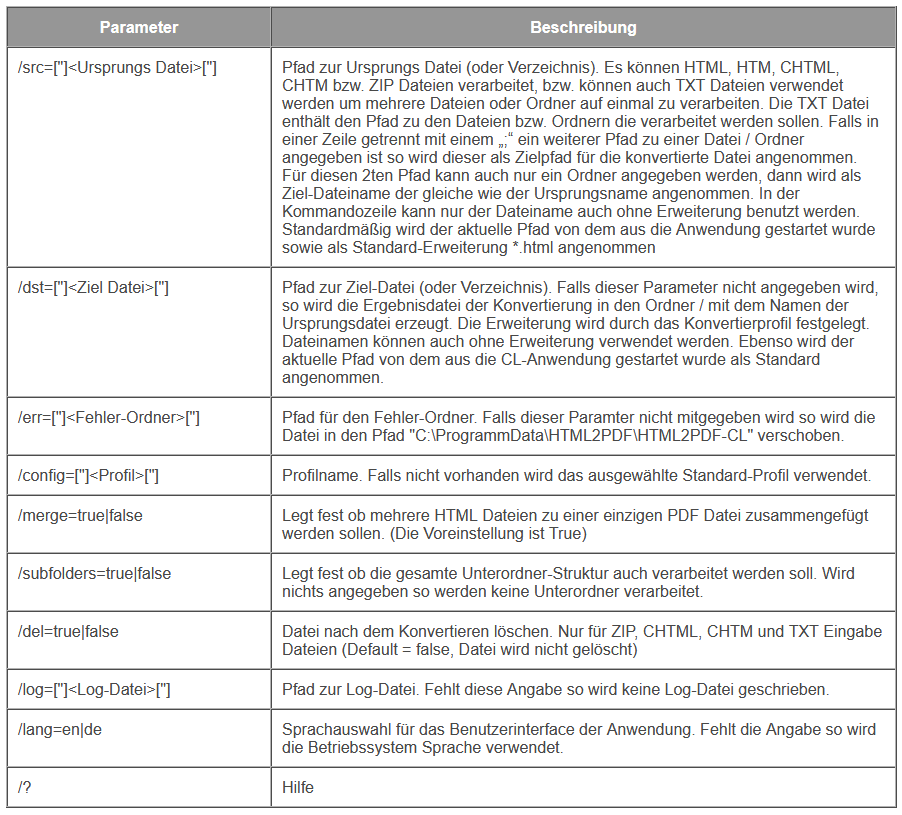
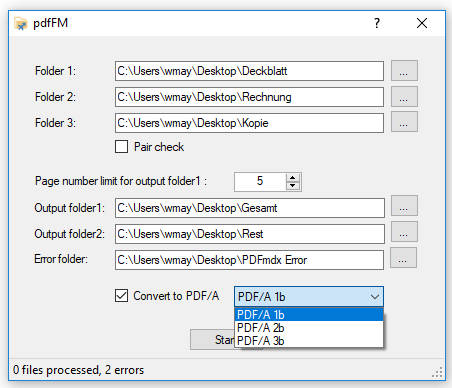
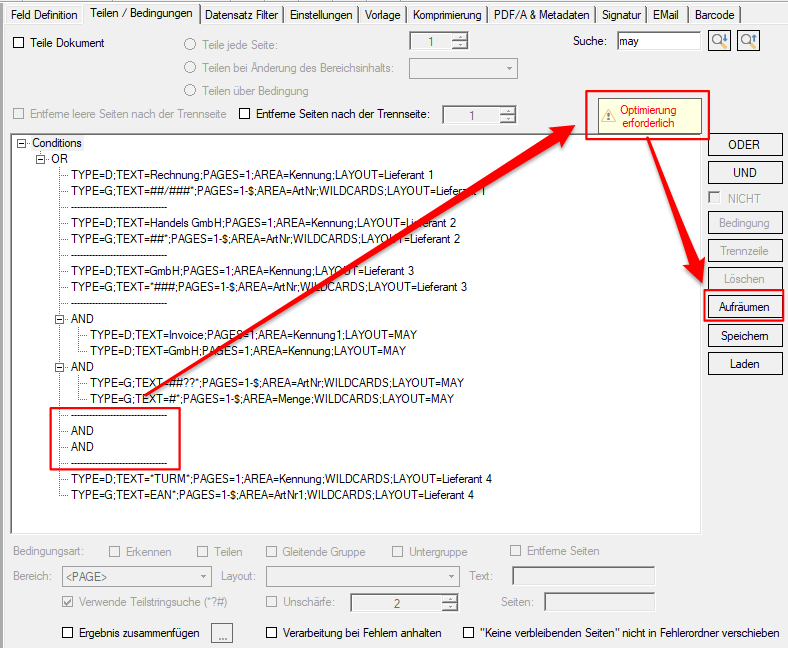
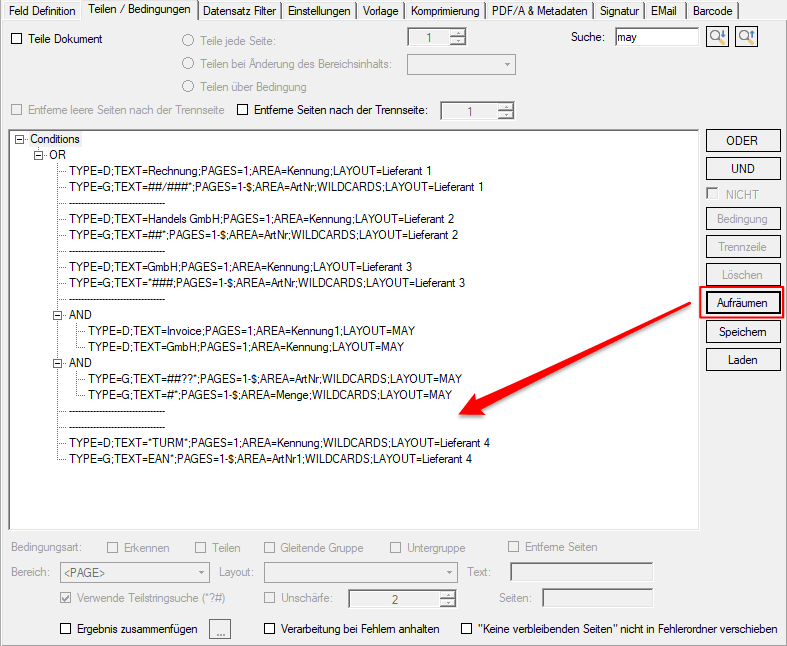
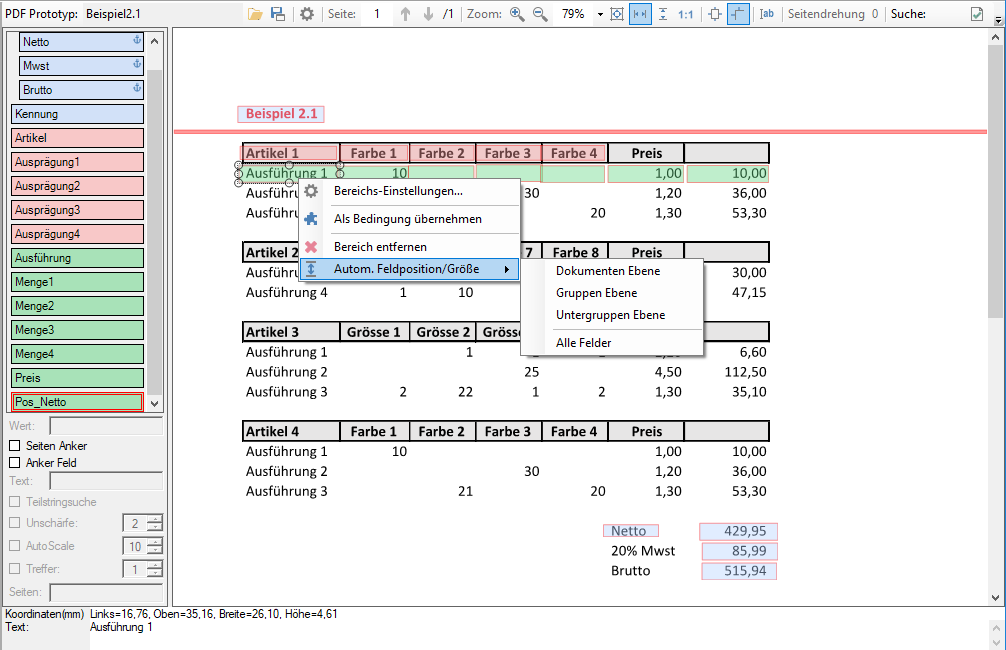
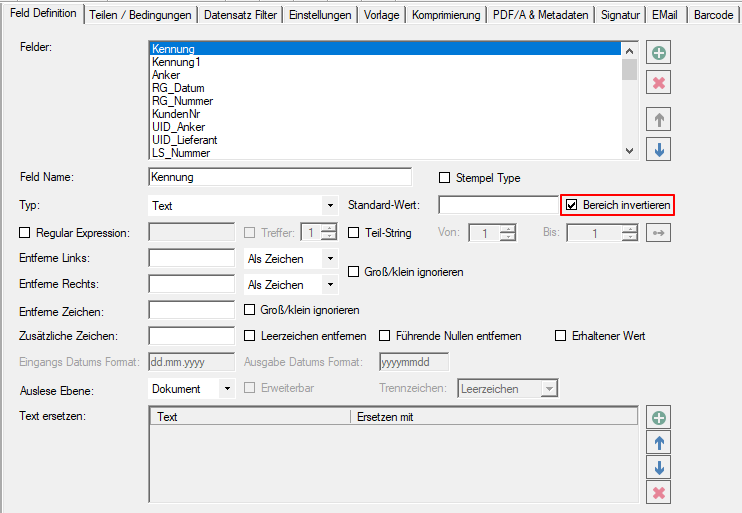
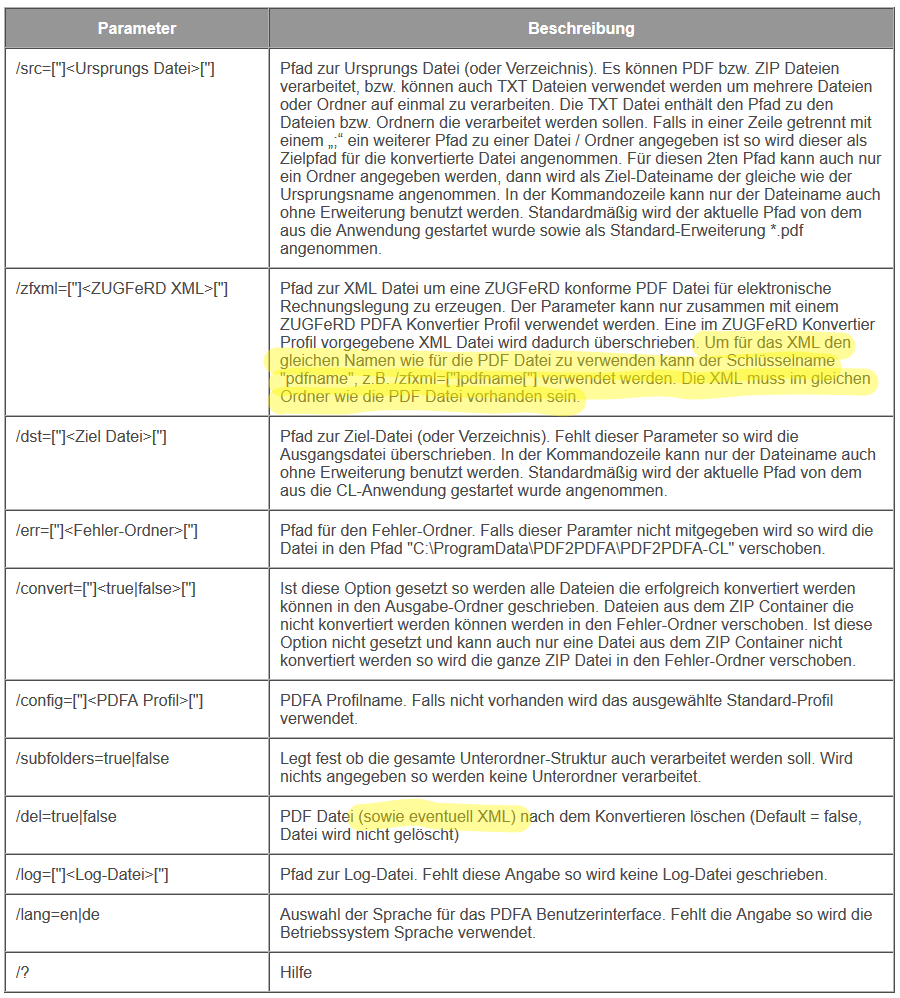
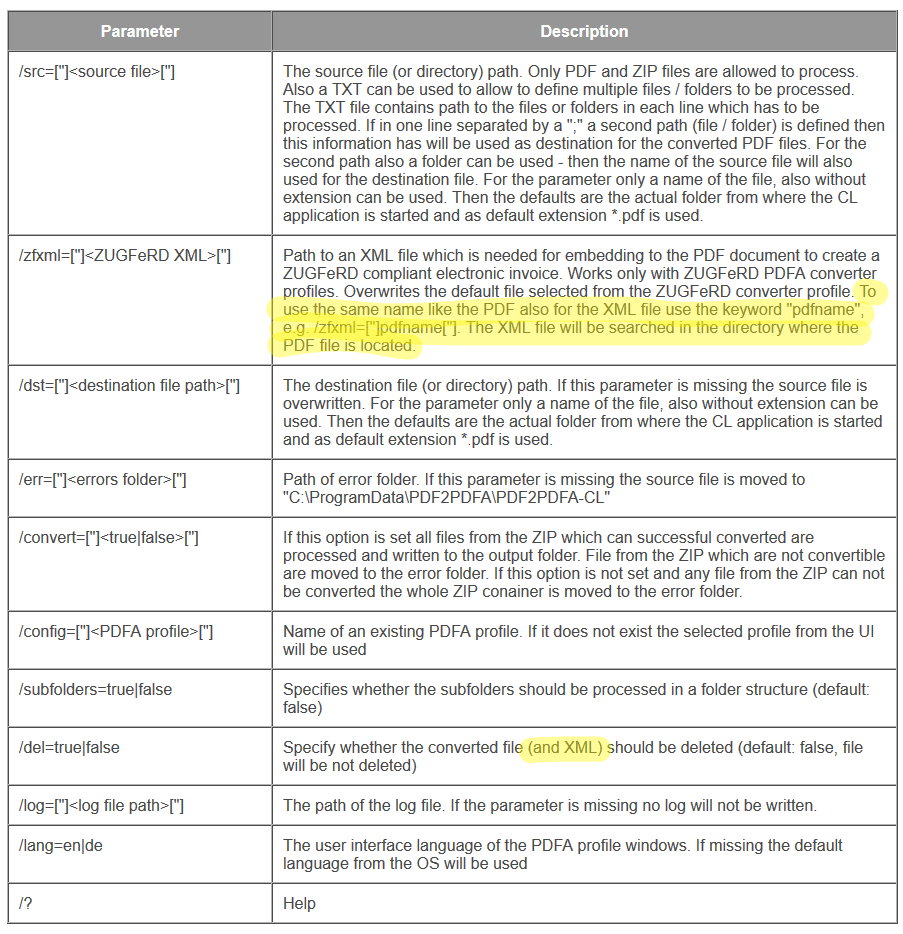
With the PDF2PDFA-CL Version 1.1.7 there is an extended command line parameter for the ZUGFeRD processing /zfxml=pdfname. This searches for an XML with the same name in the folder of the PDF file and uses it to create the ZUGFeRD PDF.
Download – PDF2PDFA-CL – PDF/A – commandline converter >>>
Download – Readme / Help – PDF2PDFA-CL >>>