Neuerungen PDFmdx Vorlagen Editor:
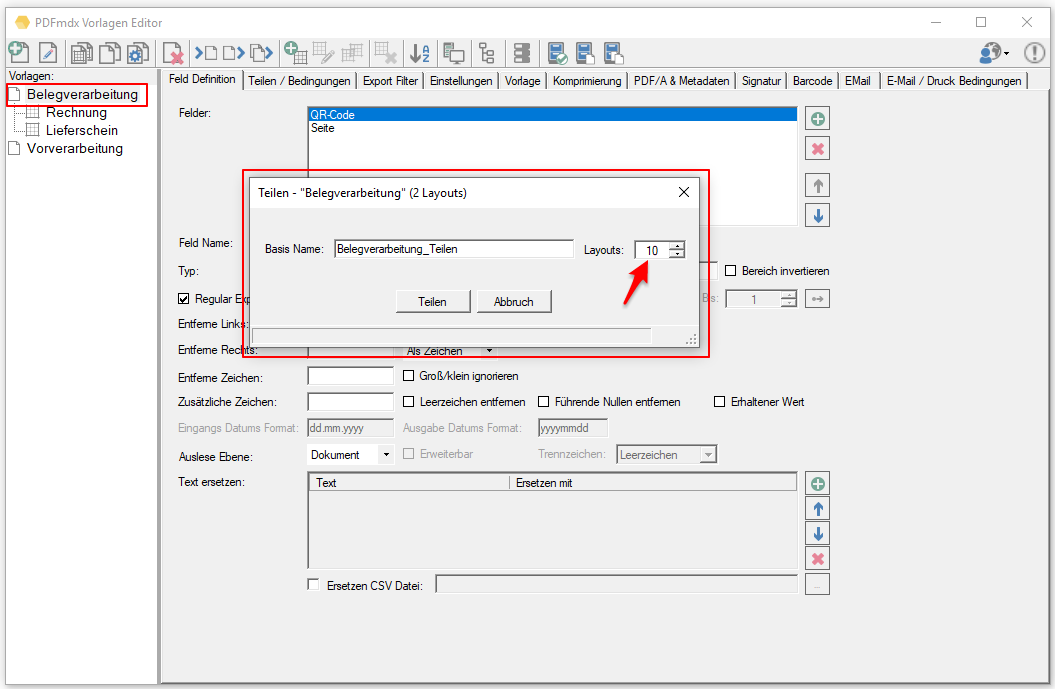
- Vorlagen teilen: Vorlagen können mit der Zeit auch sehr viele Layouts und Bedingungen enthalten. Enthält z.b. in einer Vorlage mehrere hundert Layouts so wird die Bearbeitung dieser langsam und unübersichtlich. Dafür bietet es sich an mehrere Vorlagen zu verwenden und die Layouts aufzuteilen. Für die Verarbeitung macht es keinen Unterschied. Um bestehende Vorlagen aufzuteilen gibt es dafür jetzt eine eigene Funktion. Dabei wird die Anzahl der Layouts pro Vorlage angegeben. Der PDFmdx Editor erzeugt daraus dann automatisch Vorlagenkopien und teilt die Layouts und die damit zusammenhängenden Bedingungen auf. Danach enthält jede Vorlage nur mehr die angegebene Anzahl an Layouts.
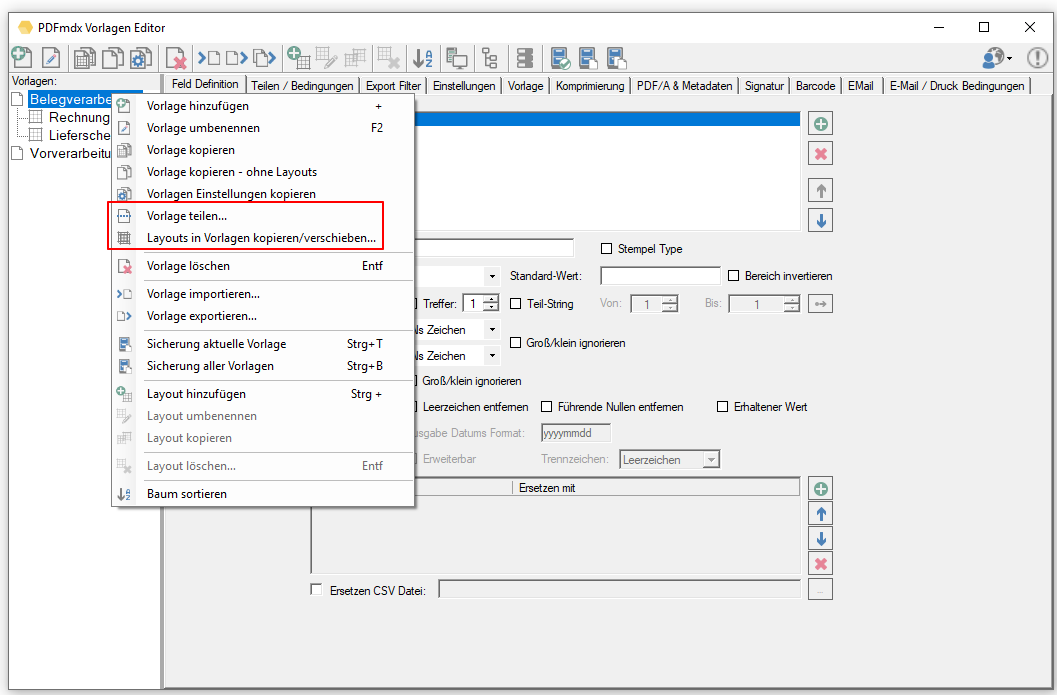
- Layouts kopieren/verschieben: Zusammen mit der Funktion „Vorlagen teilen“ wurde auch die Funktion um Layouts in eine oder mehrere andere Vorlagen zu kopieren bzw. auch zu verschieben erweitert und neu implementiert. Bisher war es nur möglich ein Layout in eine andere Vorlage zu kopieren. Jetzt können in einer Vorlage die Layouts (ein oder mehrere) und die Ziel-Vorlagen (ein oder mehrere) ausgewählt werden. Ebenso ist es möglich die ausgewählten Layouts zu verschieben und nicht nur zu kopieren. Die Felder und deren Position in den Layouts bleiben erhalten bzw. werden in der Zielvorlage hinzugefügt.

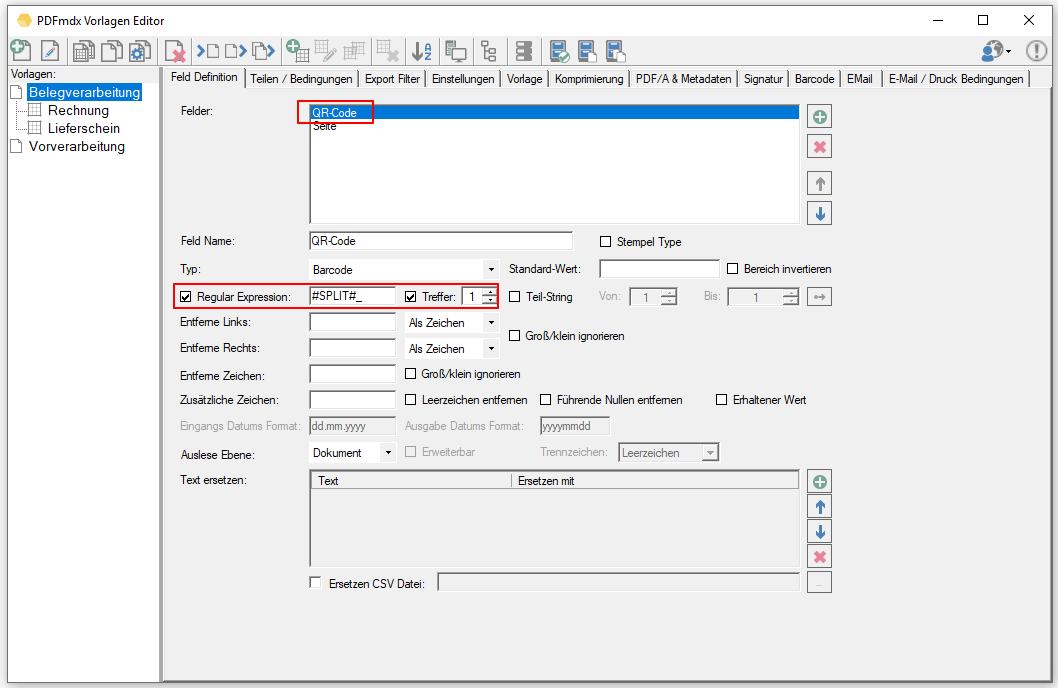
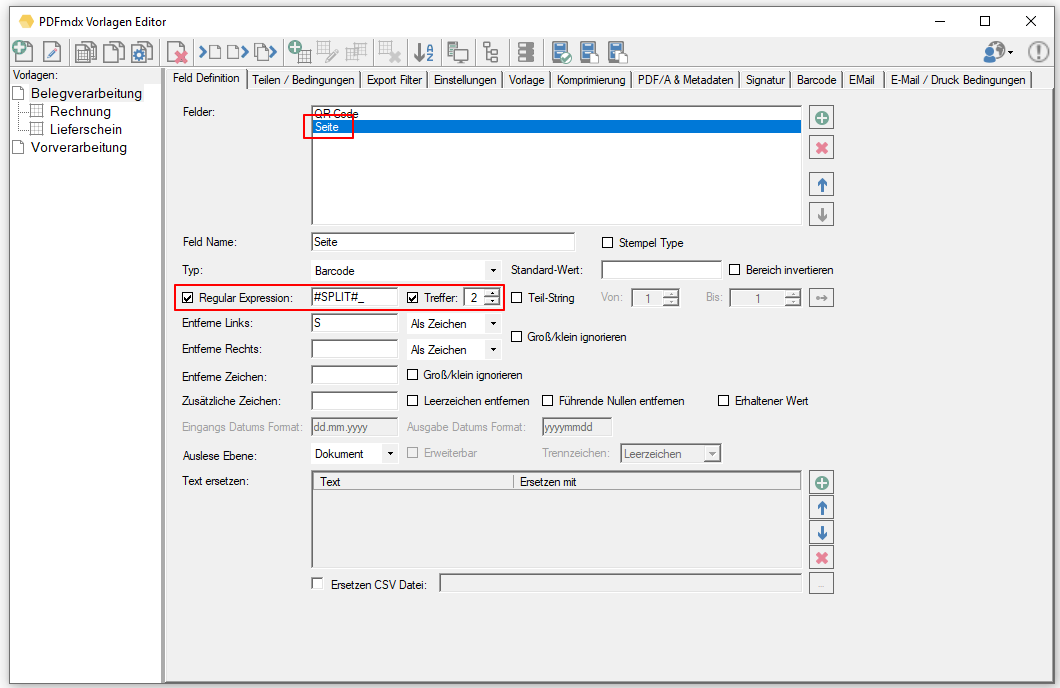
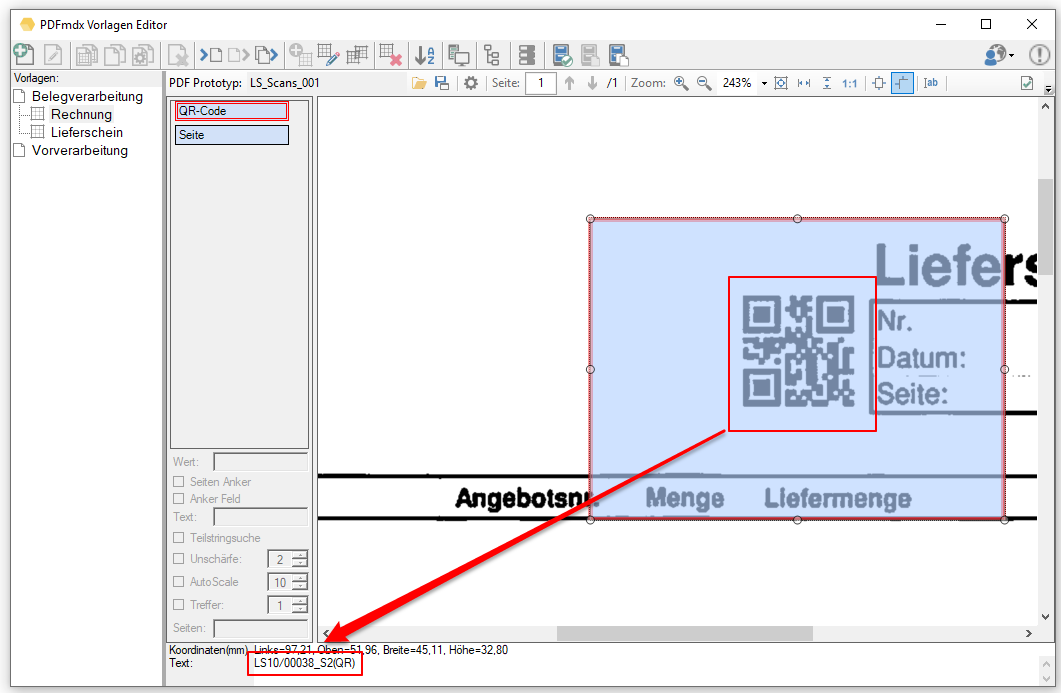
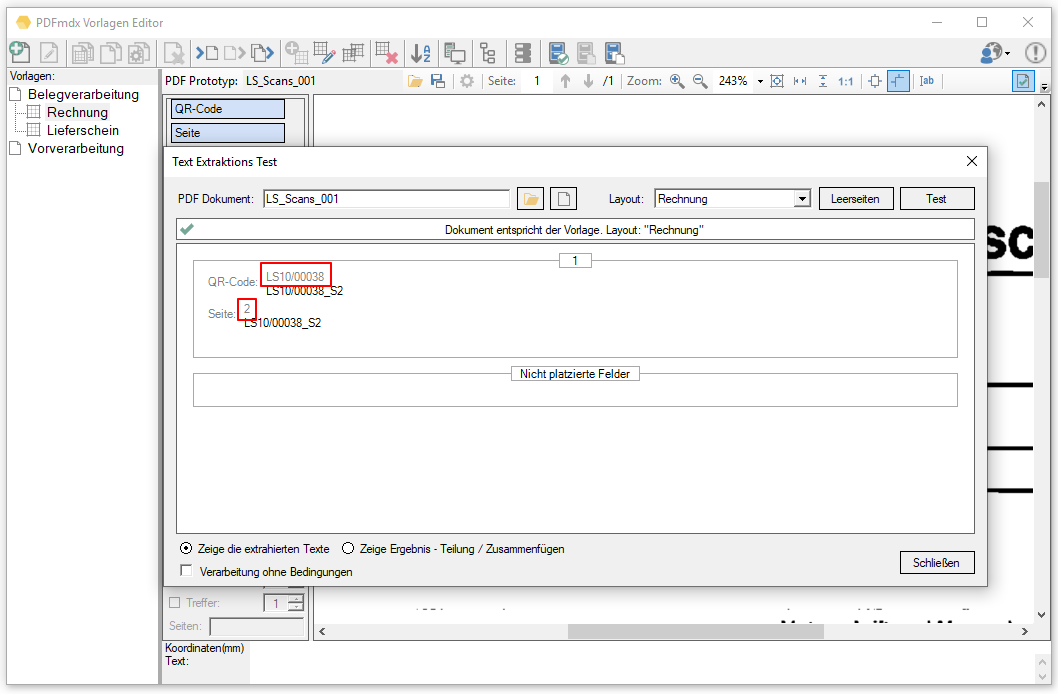
- Teilbereiche von Feldern auslesen: Beim Auslesen von Feldinhalten gibt es jetzt eine neue Funktion um gezielt und einfach einen bestimmten Teil eines Textes zu erhalten. z.b Falls ein einziges Feld alle Informationen zusammengefasst und über Trennzeichen z.b. „/“ getrennt enthält. z.b. „XKEY GmbH\Gerstlgasse30\1210\Wien“. Mit Hilfe der neu implementierten Regex Funktion kann über die Angabe von „#SPLIT#\“ plus der Position im String konfiguriert werden welcher Teil ausgelesen und für die Belegung der Variablen verwendet werden soll. So kann z.b. die PLZ = 1210 durch die Angabe von „#SPLIT#\“ + „3“ ausgelesen und ermittelt werden.
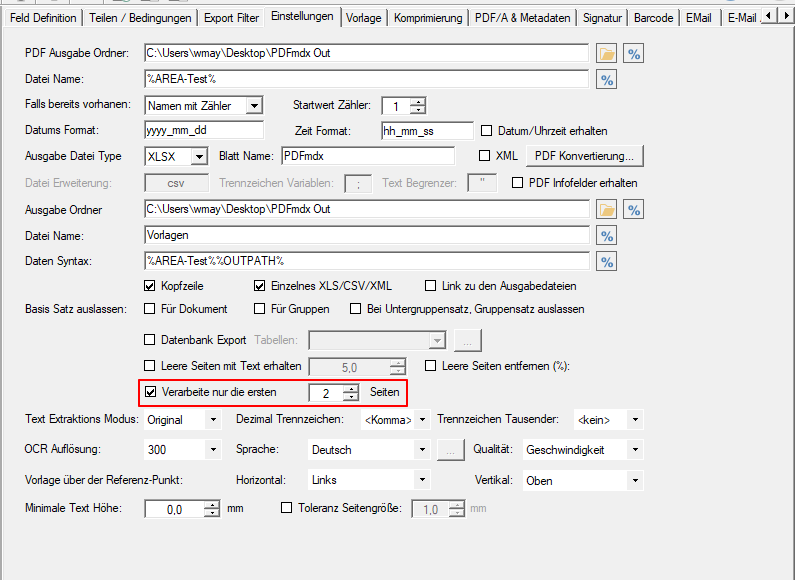
- Seitenlimit für Verarbeitung konfigurierbar: Oft befindet sich die für die Verarbeitung erforderliche Information nur auf der ersten bzw. auf den ersten Seiten. Um die Verarbeitung sehr umfangreicher PDF Dokumente welche auch einige hundert Seiten umfassen können zu beschleunigen, kann bei der Vorlage jetzt auch ein Seitenlimit (z.B.: 2) gesetzt werden. Damit wird festgelegt dass nur die angegebenen Seiten und nicht immer alle Seiten des Dokuments einlesen und verarbeitet werden.
- Bedingungs-Editor
-
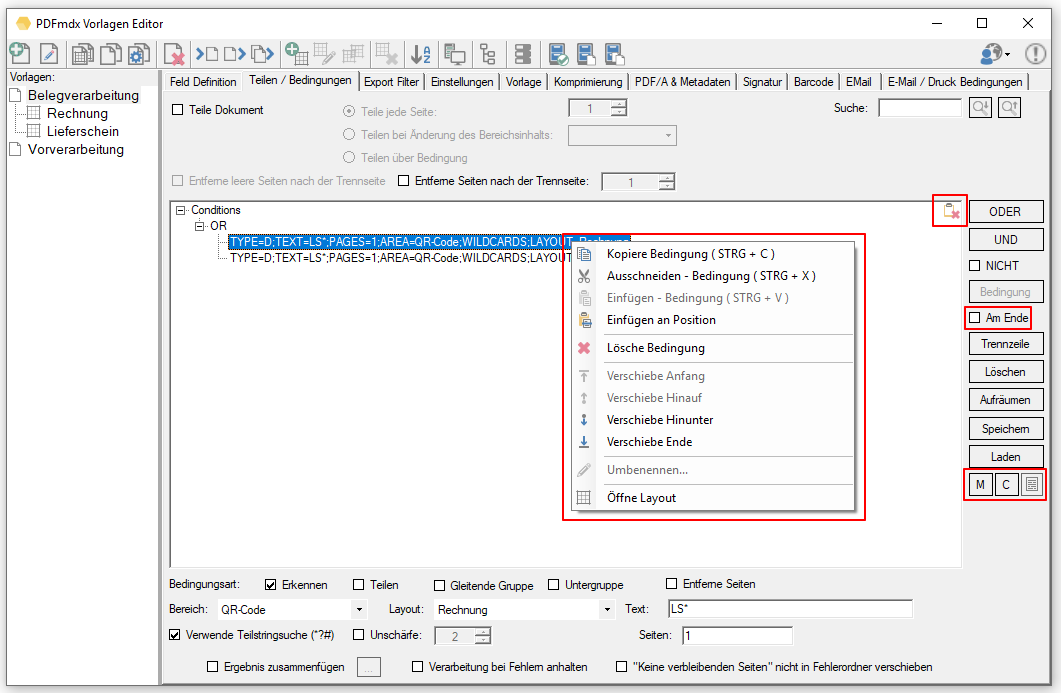
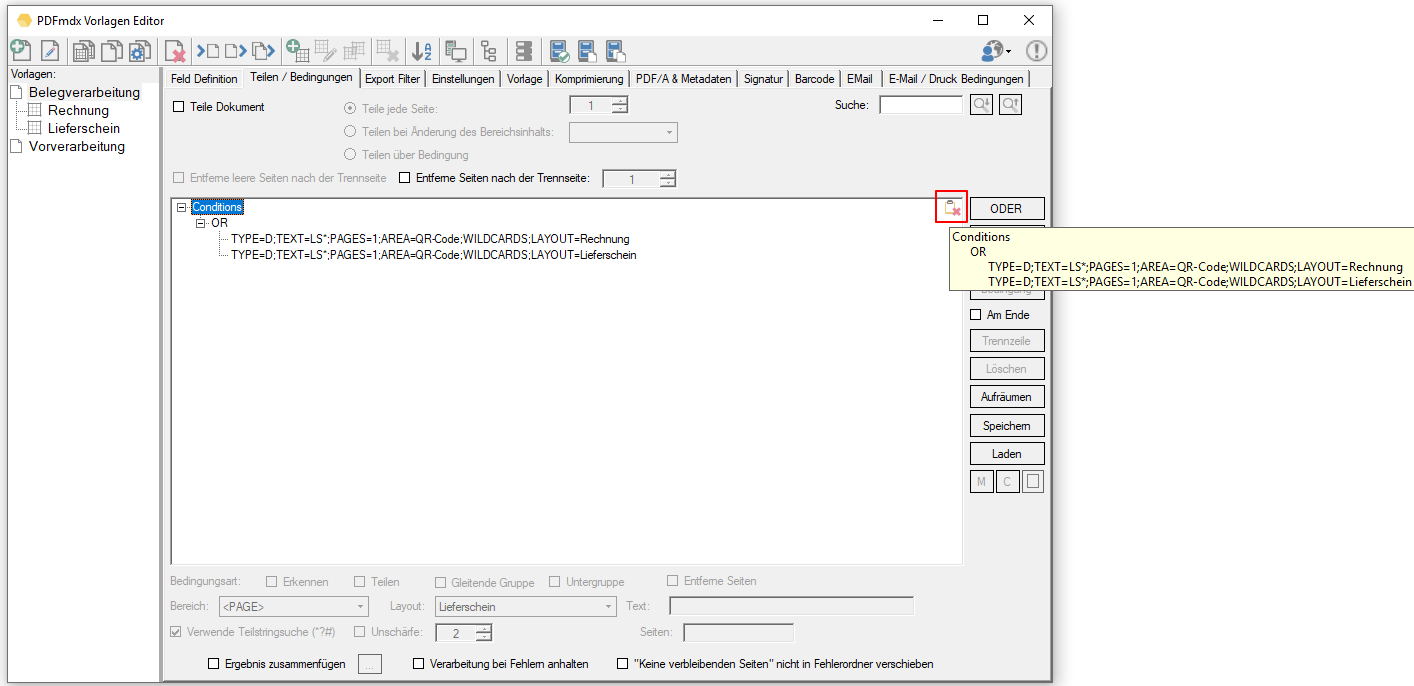
- Einzelne Bedingungen, Teilstrukturen aber auch der ganze Bedingungsbaum kann über das Clipboard von einer Vorlage in eine Andere kopiert werden.
- Trennzeilen können kopiert / ausgeschnitten und an einer beliebigen Stelle in der Struktur wieder eingefügt werden.
- (M)emory Funktion um eine bestehende Bedingung als Vorüberlegung für alle neu hinzugefügten Bedingungen zu verwenden. M – setzt die aktuell ausgewählte Bedingung als Default, C – Löscht diese Vorbelegung wieder. Diese Voreinstellung ist Vorlagen spezifisch und wird mit dieser auch gespeichert und wiederhergestellt.
- Checkbox um festzulegen ob eine neu anzulegende Bedingung am Beginn oder am Ende der aktuellen Ebene in der Baumstruktur eingefügt wird. Bisher wurden eine neue Bedingung immer am Anfang einer Knotenebene eingefügt wodurch es bei großen Baumstrukturen notwendig war die Bedingung immer nachträglich nach unten zu verschieben um wieder an den Ausgangspunkt zu kommen.

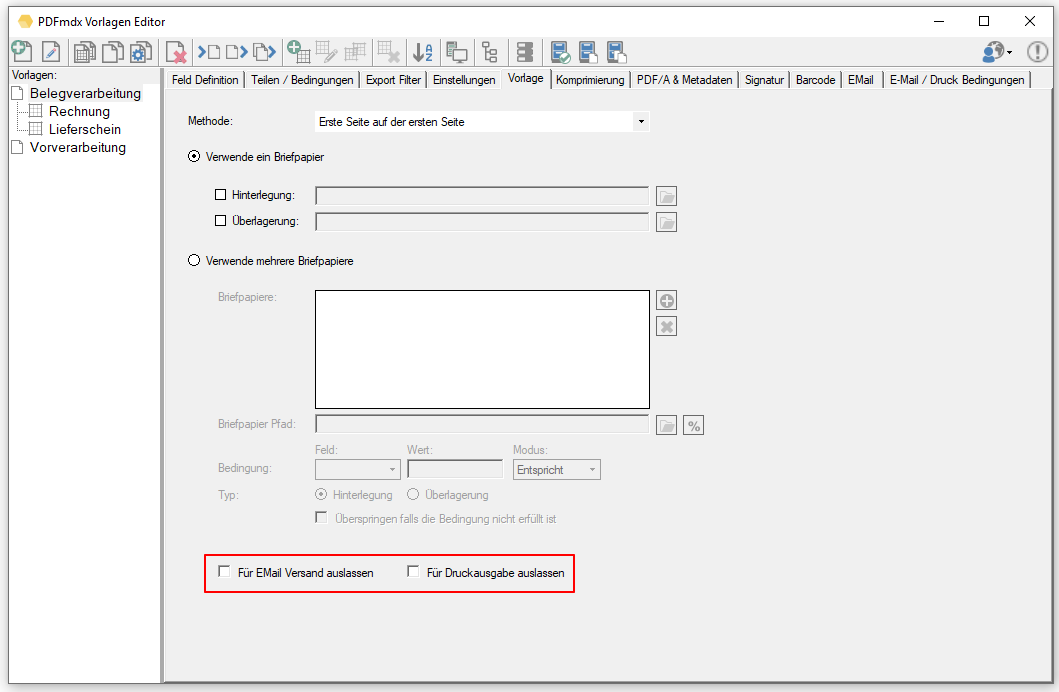
- Briefpapier beim Ausdruck / EMail Versand nicht anwenden: Werden Dokumente sowohl auf Drucker ausgegeben bzw. auch als EMail verschickt so kann es erforderlich sein das Briefpapier für die Druckausgabe nicht anzuwenden da sich im Drucker bereits Briefpapier befindet, das EMail aber mit Briefpapier verschickt werden soll. Mit dieser Option kann das gezielt gesteuert werden.
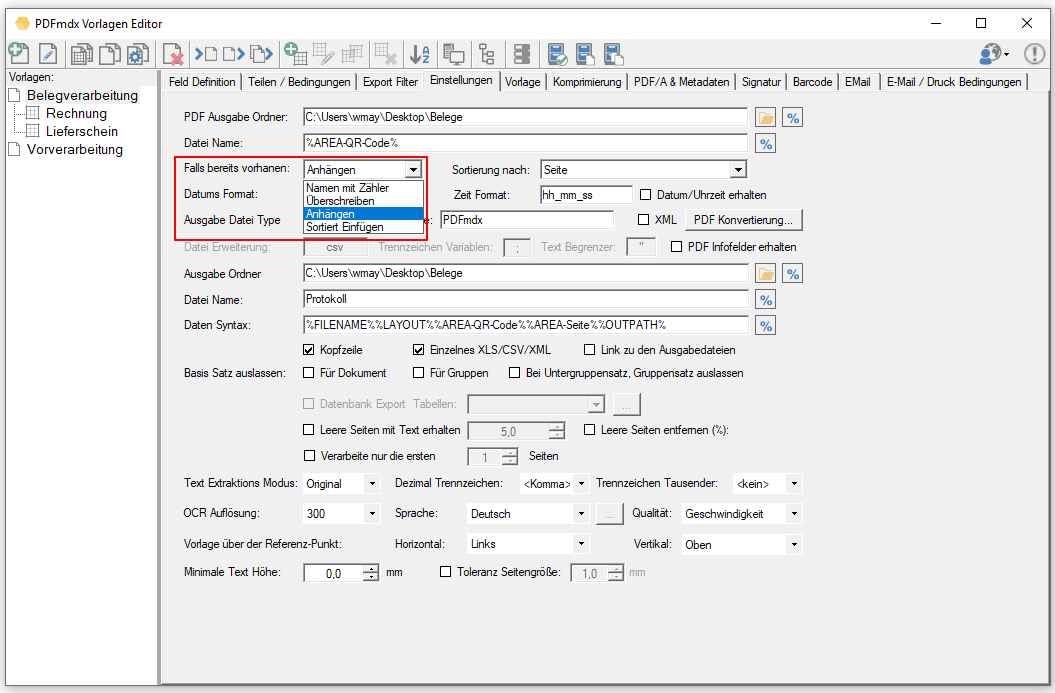
- Einzeldokumente sortiert zusammenfügen: Um beim Erfassen von Belegen vorher nicht auf eine bestimmte Reihenfolge/Sortierung achten zu müssen, bzw. um Einzelbelege über einen ausgelesenen Feldinhalt sortiert zu einem Gesamtdokument zusammenzufügen, wurden 2 neue Funktionen – „Anhängen“ sowie „Sortiert einfügen“ bei der Ausgabekonfiguration implementiert.
- „Anhängen“ – Wird bei der Ausgabe ein PDF mit dem gleichen Namen gefunden so wird die neue Datei an die bestehende Datei hinten angefügt.
- „Sortiert einfügen“ – Bei der Konfiguration muss ein Feld ausgewählt werden nach dem die Sortierung erfolgen soll. Dabei wird ein PDF Lesezeichen mit dem Text des ausgewählten Sortierfeldes erzeugt. Wird bei einer nachfolgenden Ausgabe eine Datei mit dem gleichen Namen gefunden so wird das neue Dokument an Hand des Sortierfelds an der richtigen Stelle im PDF eingefügt oder angehängt. Bei „Leer“ bzw. gleichem Inhalt wird hinten angehängt.
- PDF Display Rotation wird berücksichtigt: PDF Dateien können über einen „Display Roatation“ Parameter (0,90,180,270) enthalten. Z.B.: Kann bei Dokumenten die gedreht eingescannt wurden über den „Display Rotation“ Parameter die Darstellung entsprechend korrigiert werden um die Seiten immer im Hochformat anzuzeigen. Der Parameter dient aber nur für die Anzeige am Bildschirm, intern ist die PDF Datenstruktur jedoch weiterhin rotiert (z.b. am Kopf stehend). Die aktuelle Version von PDFmdx erkennt die PDF „Display Rotation“ und berücksichtigt diese, so dass die Darstellung auch der Verarbeitung entspricht und die Felder von den richtigen Positionen ausgelesen werden.
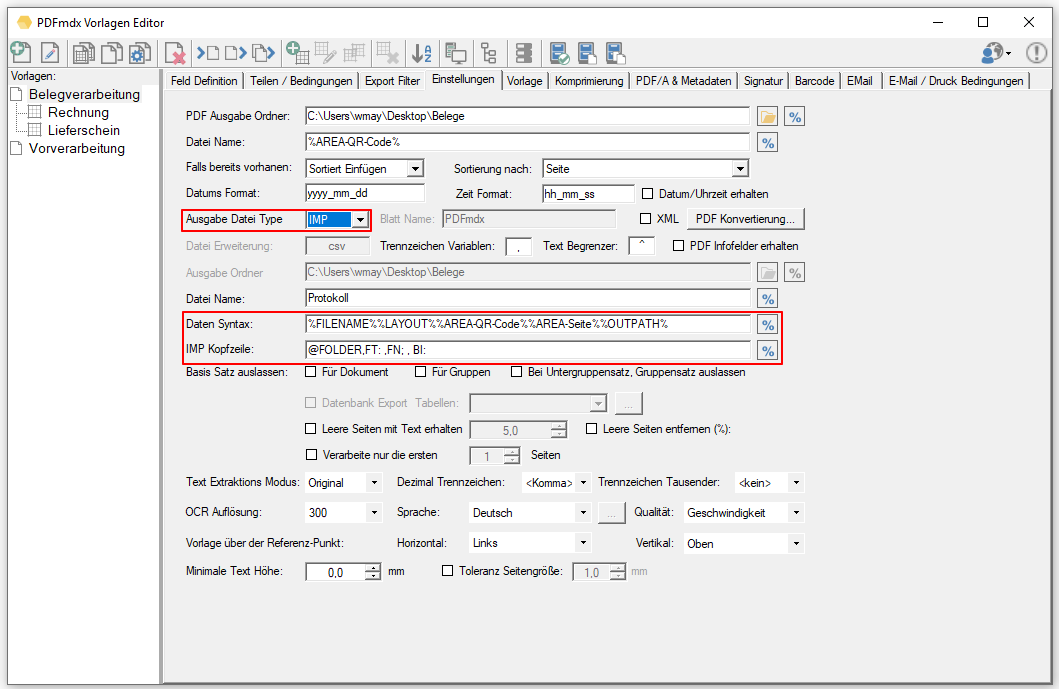
- EasyArchiv (IMP) Export Format: Das EasyArchiv IMP Metadaten Ausgabeformat ist eine Art CSV Format. Es enthält eine individuell zu konfigurierende Kopfzeile sowie Folgezeilen mit den PDFmdx Metadaten. Als Feldbegrenzung ist das „^“ und als Feldtrennzeichen der „,“ (Beistrich) vorgegeben. Für die Folgezeilen stehen wie bei allen anderen Formaten die Felder / Variablen zur Auswahl zur Verfügung.
Beispiel einer IMP Kopfzeile: @FOLDER,FT:B2B_Netz,FN:Partner,FN:B2BMessageID,FN:MailMessageID,FN:RefNr,FN:Sender,FN:B2BSystem,BI:2001
FT: = Dokument Typ, FN: = Feldnamen. Diese Zeile muss entsprechend dem Archiv in das importiert werden soll individuell konfiguriert werden.
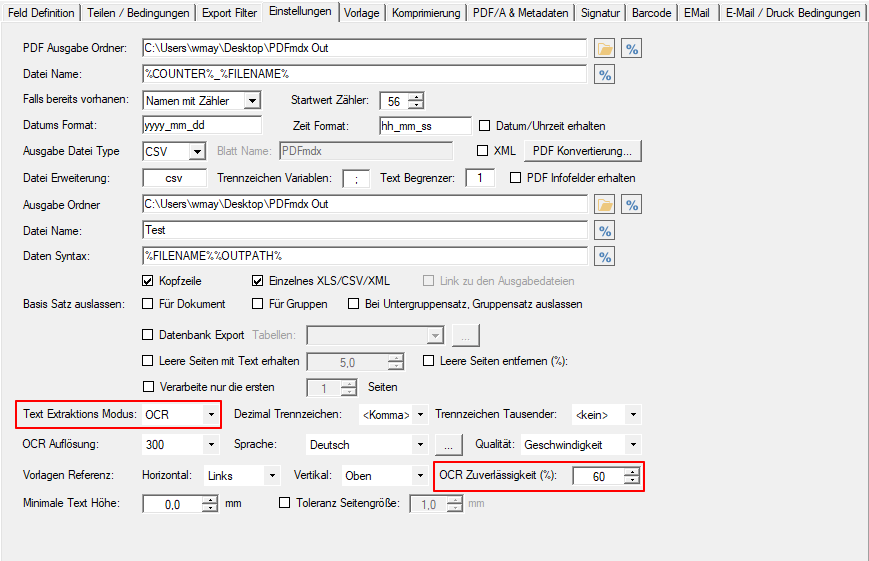
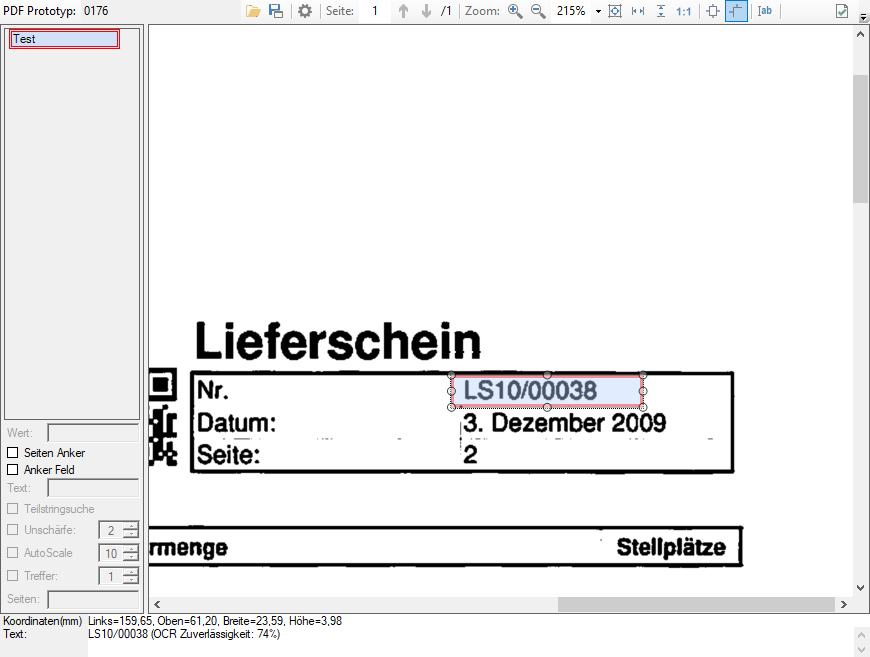
- OCR Zuverlässigkeit beim Bereichs OCR: Für die positionierten Felder gibt es bei PDFmdx auch die Möglichkeit den Text aus dem Bild über eine OCR Funktion zu ermitteln. Bisher war intern die OCR Zuverlässigkeit fix mit 60% vorgegeben. Jetzt ist dieser Schwellwert konfigurierbar und wird auch bei der Voransicht für die Textausgabe in der Fußzeile des PDFmdx Editors, als Information ausgegeben.
Neuerungen PDFmdx Verarbeitung:
- Job Trigger Funktion: Der Start der Verarbeitung einer oder mehrere Jobs kann durch das Ende der Verarbeitung eines anderen Jobs angestoßen werden. Alle Jobs die über einen Trigger gestartet werden müssen in der Jobliste deaktiviert sein ansonsten wird die Verarbeitung über die Ordner Überwachung ausgelöst und nicht über den Trigger. Bei diesen Jobs wird der Start der Verarbeitung nur mehr über den Trigger eines anderen Jobs ausgelöst. Durch einen Trigger kann auch die sortierte Verarbeitung sichergestellt werden. Dabei wird der nächste Verarbeitungsschritt erst gestartet nachdem alle Dateien eines vorangegangenen Jobs fertig verarbeitet wurden.
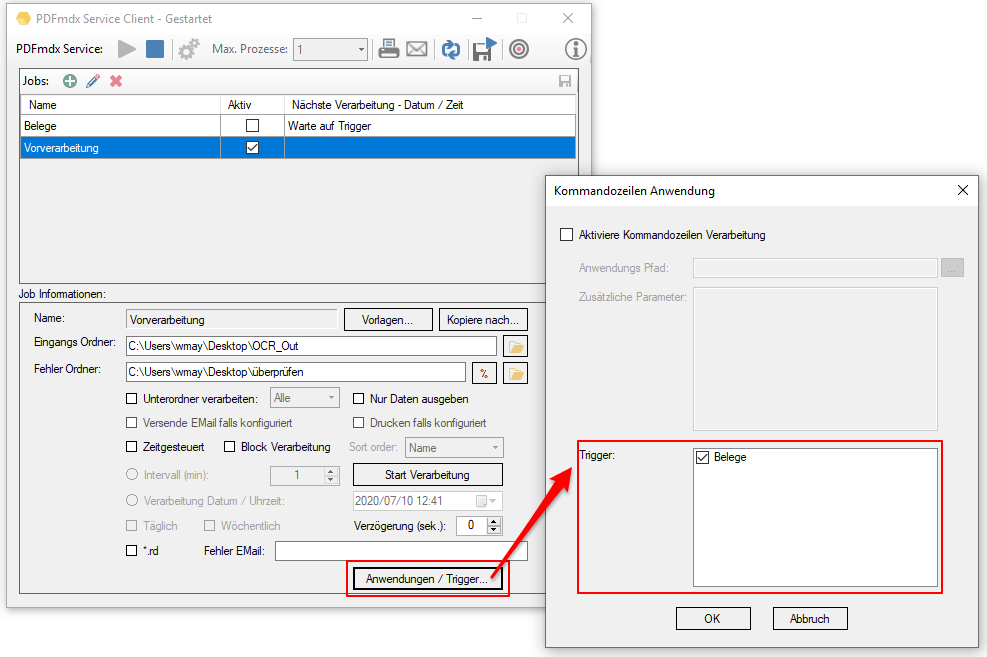
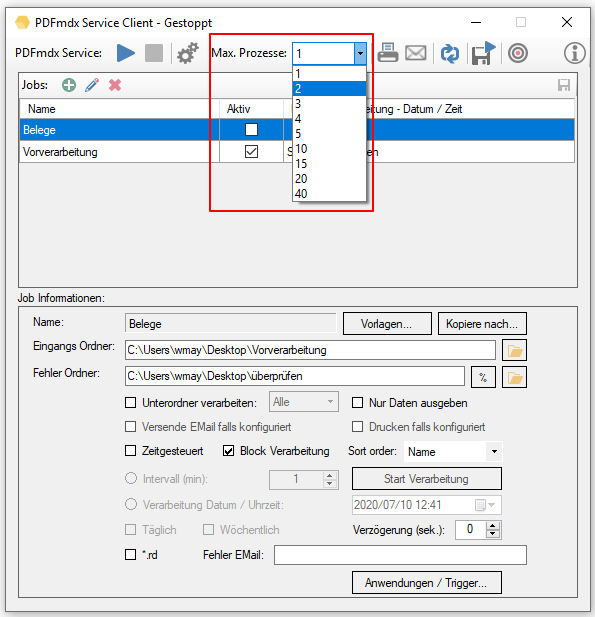
- Sortierte Verarbeitung von Eingangsdateien: Dateien in überwachten Ordnern können jetzt auch sortiert (auf / absteigend) nach Name, Größe, Erstellungs- und Änderungs-Datum verarbeitet werden. Dazu muss die Option „Blockverarbeitung“ aktiviert sein. Der Start einer sortierten Verarbeitung erfordert einen definierten Zeitpunkt. Er kann über den Intervalltimer, zu einem eingestellten Zeitpunkt, durch eine *.rd Datei, durch den Trigger eines anderen Jobs oder durch Drücken von „Start Verarbeitung“ ausgelöst werden.

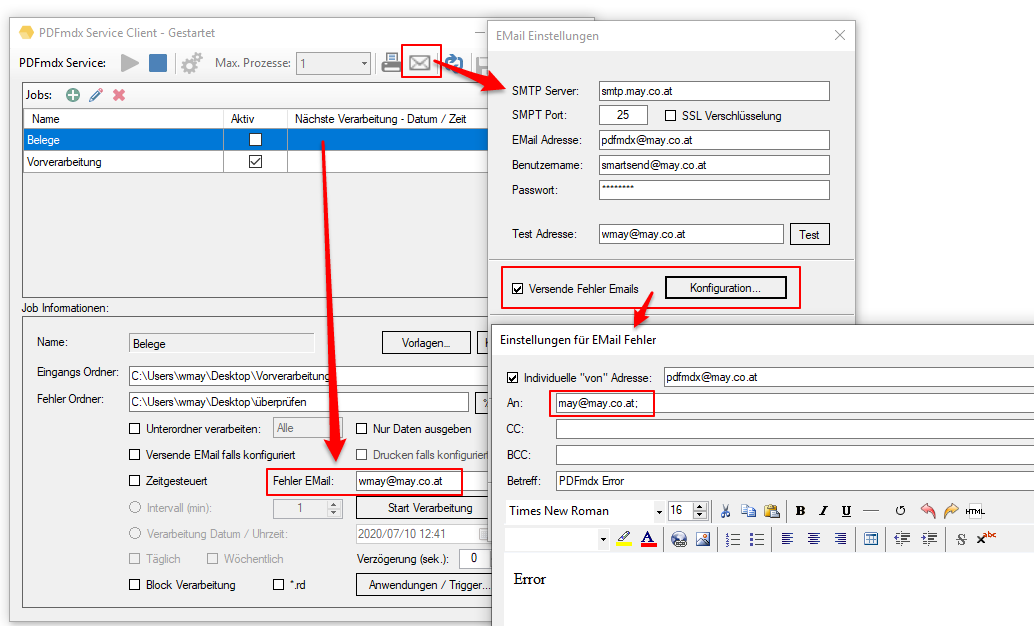
- Fehler EMail Adresse pro Job: Pro Job kann eine individuelle Fehler EMail Adresse festgelegt werden. Diese übersteuert die generell im PDFmdx Prozessor festgelegte, für alle Jobs geltende Fehler EMail Adresse.
- Parallele Verarbeitung: Erfolgt auf Basis der Jobs, nicht jedoch um innerhalb eines Jobs mehrere Dokumente parallel zu verarbeiten.