PDF2Printer – Version 2.0.22 – Print pages / areas, extended PCF control file
Innovations PDF2Printer Version 2.0.22:
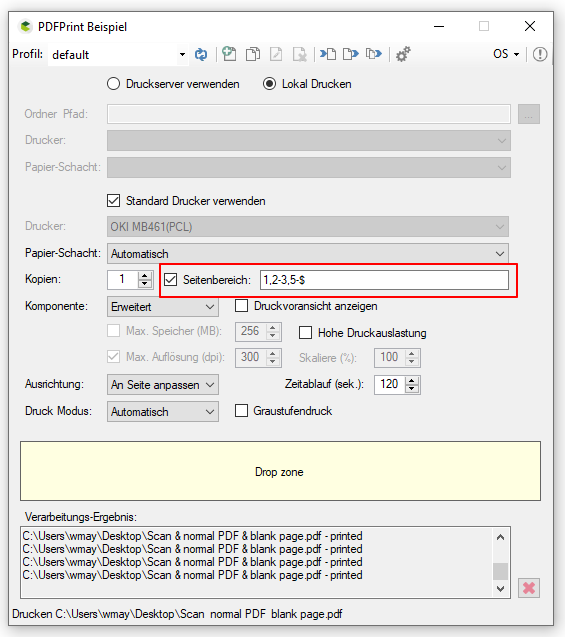
Print specific pages / ranges of pages:
- Page ranges – from / to – with the minus sign: e.g. 6-8
- Individual pages – separated by a comma: e.g. 1,4,6-8
- All pages from a certain page to the end of the document – with the dollar sign: e.g. 1,4,6-8,10- $
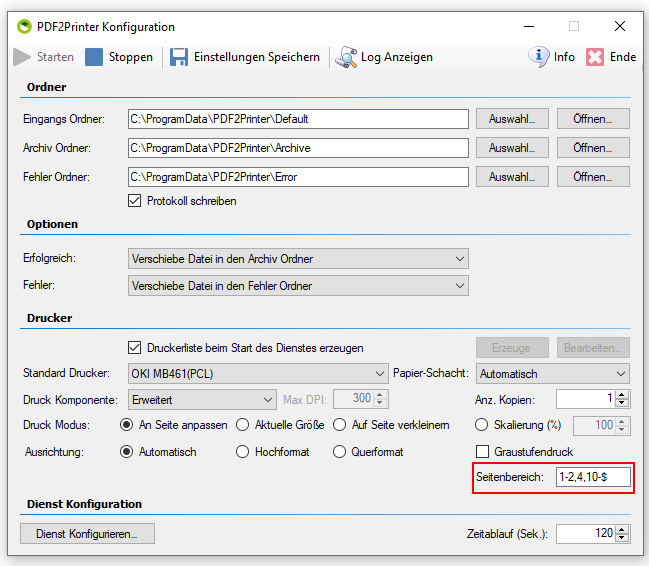
Extended PCF control file:
An essential function of PDF2Printer is the possibility of controlling the printing process via a PCF- Print Control Format File. The PCF control file has now been expanded to include the new functions of the PDFPrint .NET component.
PDF2Printer can monitor an input folder. PDF files that end up in it are printed out immediately with the configured standard settings. Any subfolders can be created in the monitored folder into which PDF files are copied. The printout of these PDF files can only be triggered via a * .PCF file.
A PCF file can contain the names of one or more PDF files to be printed. The PDF to be printed must already exist in the subfolder before the PCF file is created there or copied into it. The PCF file can contain one or more lines, one line per PDF. Printed PDF files will be deleted. Once all files have been printed and the subfolder is empty, the subfolder and the PCF file are also automatically deleted.
Syntax of the PCF lines:
<PDF file name> \ t <Printer name> \ t <Paper tray type>: <Paper tray name> \ t <Copies> \ t <Grayscale> \ t <Page range>
![]()
- \ t = TAB Character as a separator between the parameters.
- & lt; PDF file name & gt; = Name of the PDF file to be printed, without path, the PDF must be in the same subfolder as the PCF file.
- & lt; Printer Name & gt; and & lt; Tray_Type & gt;: & lt; Tray_Name & gt; = Can be found in the “printers.pnames” file. This file is automatically created by the PDF2Printer application when the service is started in the monitored folder and contains the list of all available printers / paper feed trays. Please note that the system account under which a Windows service runs by default does not have access to network printers. Therefore a user account should be used. You should log in with this user account, perform the PDF2Printer configuration and test the printer under this user account. This user should then also be used for the PDF2Printer service. This ensures that the PDF2Printer service has the same printers available as when configuring via the user interface.
- & lt; Copies & gt; = Number of copies for the printout
- & lt; Grayscale & gt; = true / false – Whether to print in color or in grayscale.
- & lt; Pages area & gt; = Individual pages separated by a comma, from / to with the minus sign, or up to the end of the file with the $ sign: e.g. 1,3-4,10 – $ </ li>
Download – PDF2Printer – Service to automatically print PDFs >>>