Neuerungen AutoOCR & AutoOCR-light 2.0.41:
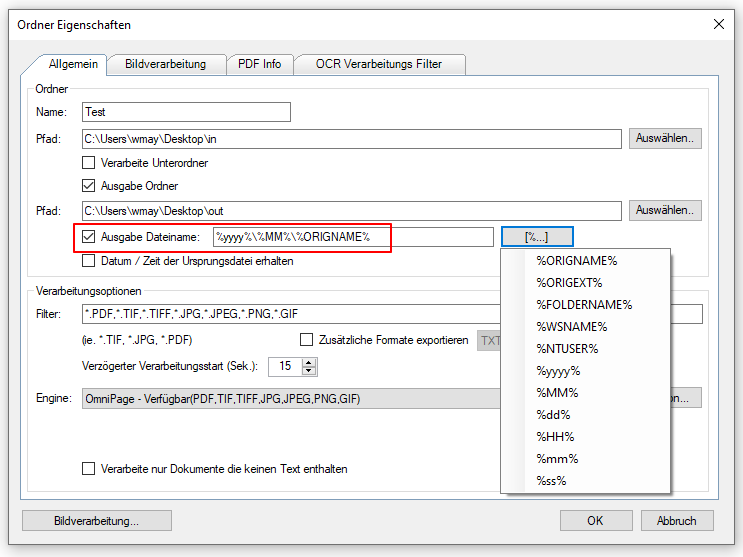
- Ziel-Dateiname /-Ordner über Variablen: Für den Ausgabedateiname und für den Ausgabeordner können jetzt auch einige Variablen verwendet werden. Die Konfiguration erfolgt in Feld für Ausgabe Dateinamen. Durch Verwendung von „\“ kann in dem Feld auch eine Ordnerstruktur angegeben werden, die unter dem ausgewählten Ausgabe Startordner angelegt wird.
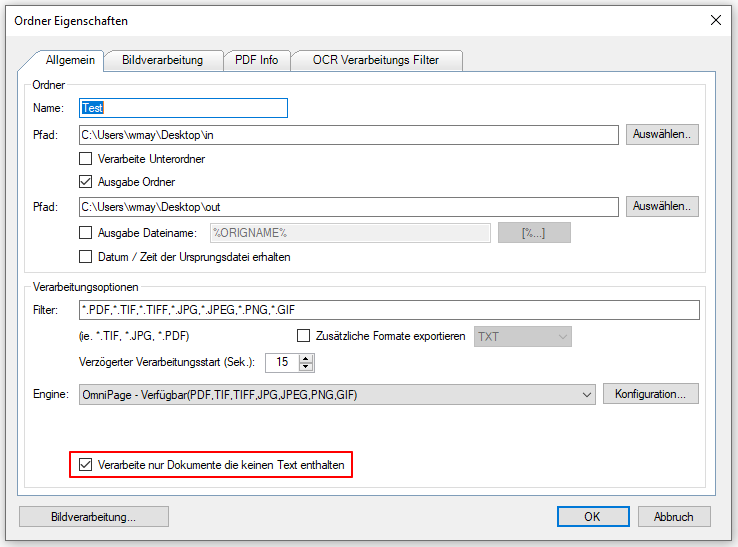
- Ausscheiden von PDF die bereits Text enthalten: Durch die „intelligente“ OCR Verarbeitung kann zwar erkannt werden ob ein PDF eine OCR Verarbeitung erfordert oder nicht, dabei werden aber immer alle PDF aus den überwachten Eingangsordnern verarbeitet und im Zielordner ausgegeben. Will man aber nur PDF´s ausgeben die wirklich eine OCR Verarbeitung erfordern, so war diese Unterscheidung bisher nicht möglich. Durch diese neue Option werden nur jene PDF im Ausgabefolder ausgegeben die wirklich OCR verarbeitet wurden. Alle anderen PDF´s werden je nach Konfiguration aus dem Eingangsfolder z.B,: gleich direkt in den Archivfolder verschoben und landen daher nicht im Ausgabefolder.
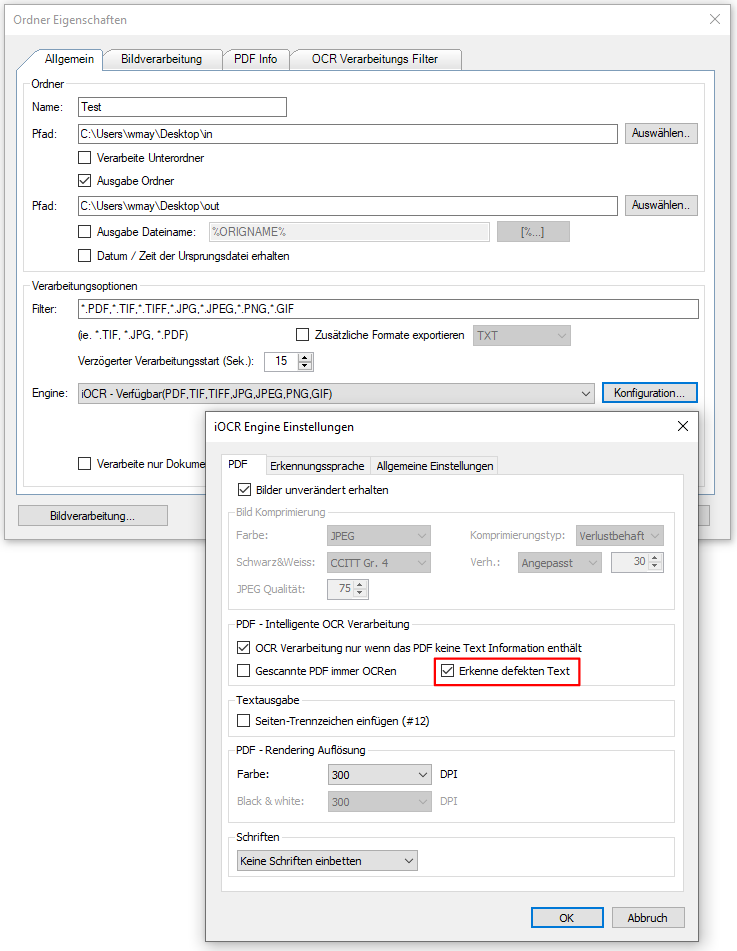
- Defekten Text im PDF erkennen und korrigieren: Es kommt vor dass PDF zwar Text enthalten, dieser jedoch „defekt“ ist. Das Problem liegt in einer fehlerhaften Erstellung des PDF. Dabei werden Texte / Schriften falsch oder unvollständig codiert. Oft tritt das Problem auch auf falls ein bestehende PDF, aus einem Anzeigeprogramm, nochmals über eine PDF Druckertreiber ausdruckt wird um daraus wieder ein PDF zu generieren.
In diesem Fall kann man zwar den Text im PDF markieren und kopieren, der extrahierte Text ist jedoch nicht brauchbar und enthält nur Sonderzeichen und Hieroglyphen. Solche PDF´s können nicht sinnvoll weiterverarbeitet werden. Es können keine Informationen aus dem PDF gewonnen werden, das PDF kann nicht durchsucht werden und über Volltextsuche oder Suchmaschinen wird das Dokument nicht gefunden. Von außen kann das nicht erkannt werden. Das PDF kann ohne Fehlermeldung geöffnet, angesehen und ausgedruckt werden.
Die einzige Möglichkeit um solche PDF wieder herzustellen und den Text richtig zu codieren besteht durch OCR. Dabei wird das PDF bzw. nur die betroffene Seite „gerendert“ und der Text über die OCR Verarbeitung neu erzeugt.
AutoOCR Version Version 2.0.41 bietet diese Möglichkeit sowohl für die iOCR als auch für die OmniPage OCR-Engine. Dabei kann für jede Seite des PDF´s herausgefunden werden ob diese „defekten“ Text enthält oder nicht. Wird eine solche Seite erkannt so wird der Text über die OCR Funktion neu erzeugt, Seiten mit korrektem Text werden keiner weiteren OCR Verarbeitung unterzogen.

Download – AutoOCR – OCR Server inkl. OmniPage OCR (ca. 640MB) >>>
Download – AutoOCR light – Low Cost OCR Server (ca. 410MB) >>>
Download – iOCR (vsOCR) Setup – zusätzliche Sprachen (ca. 1200MB) >>>