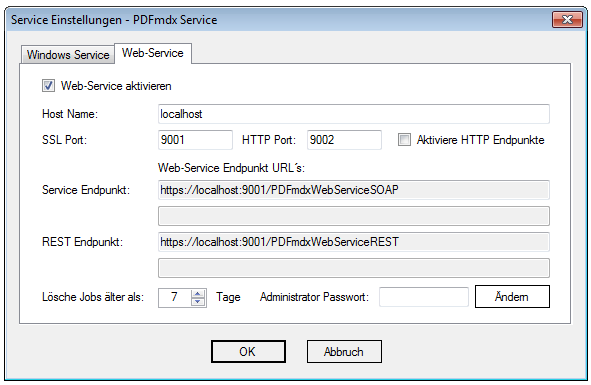
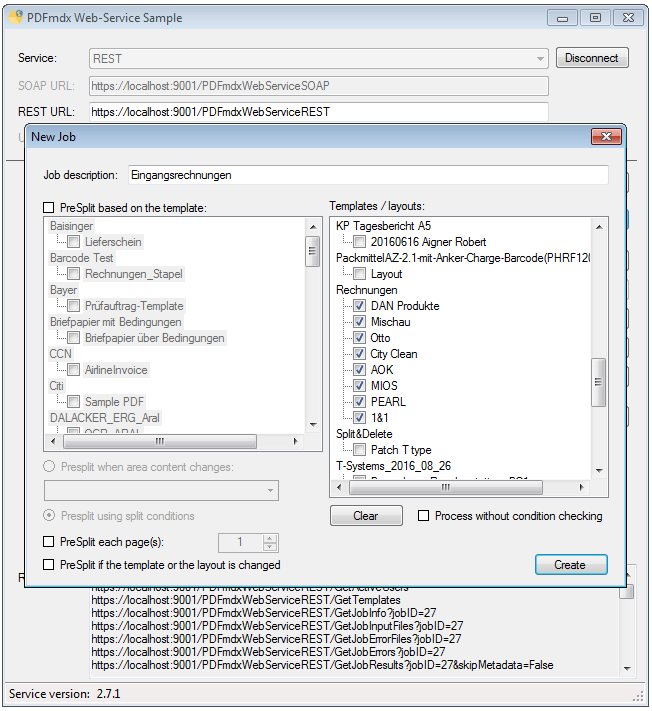
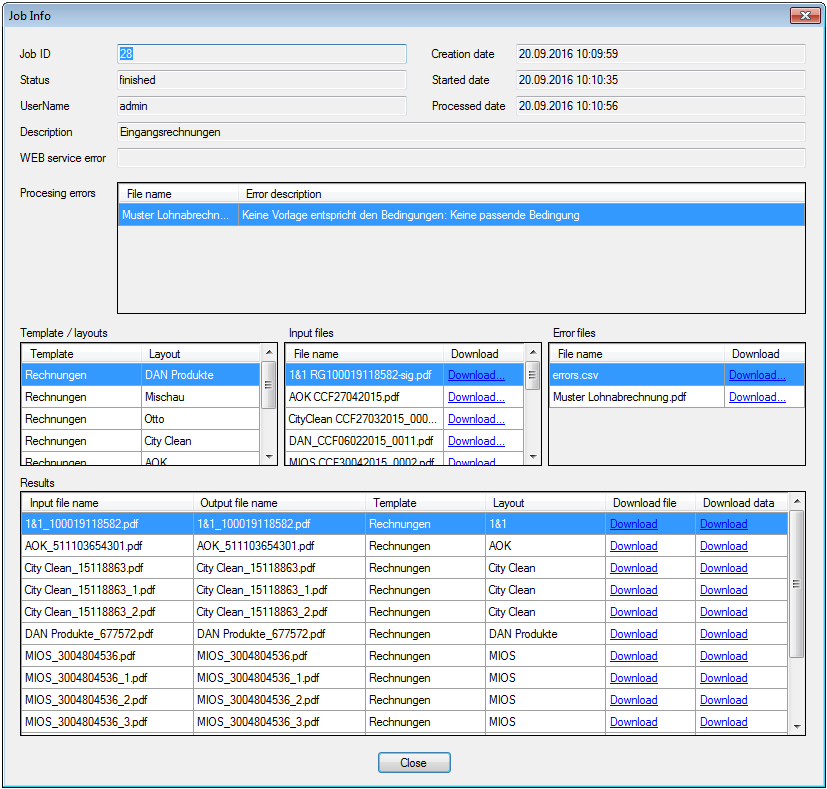
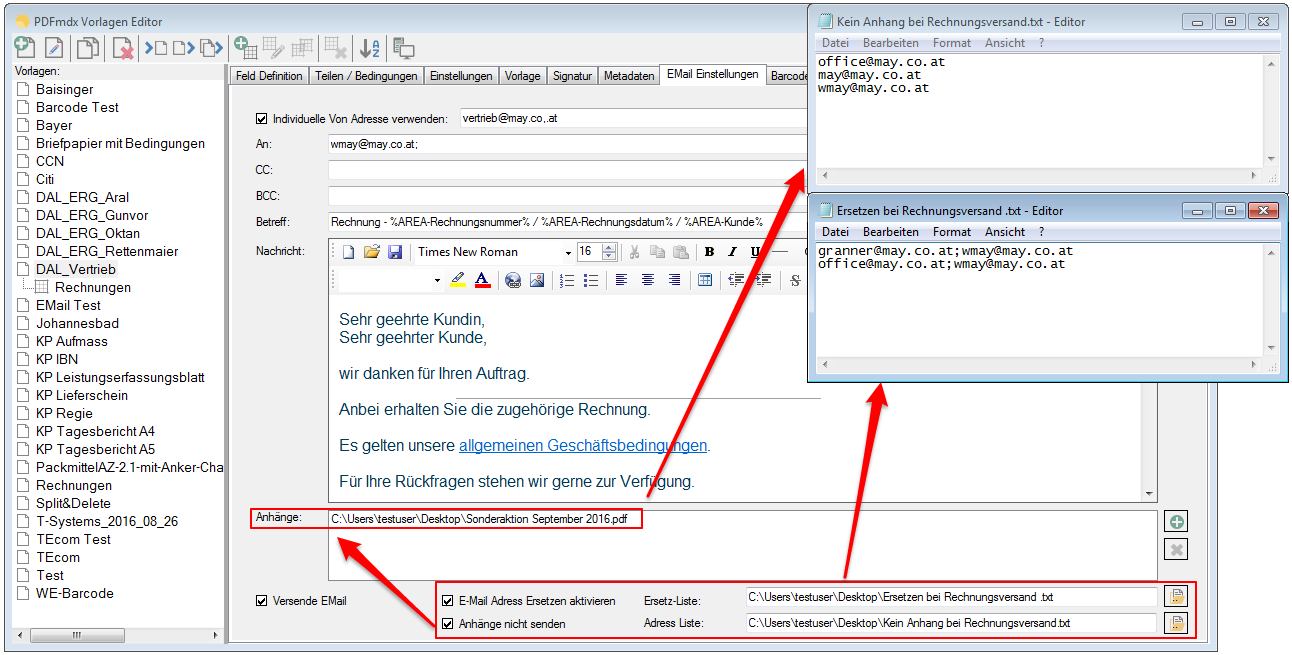
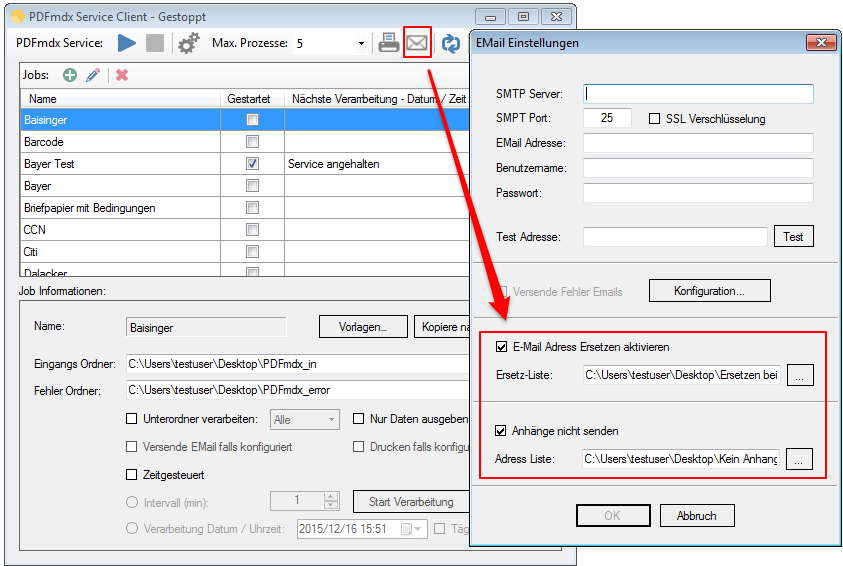
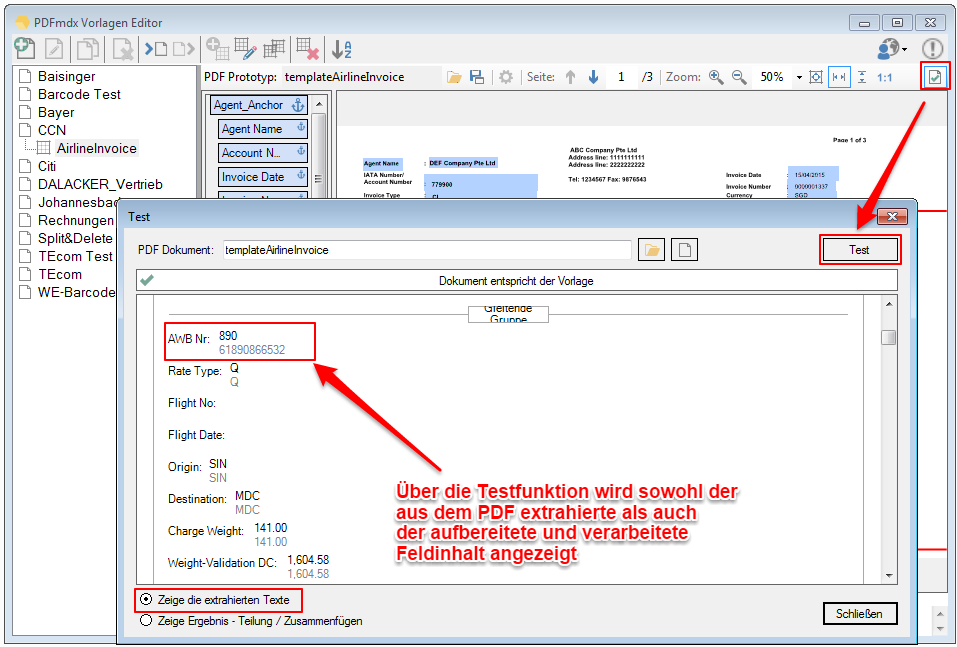
PDFmdx Version 3.2.7 verfügbar
Neuerungen PDFmdx Version 3.2.7:
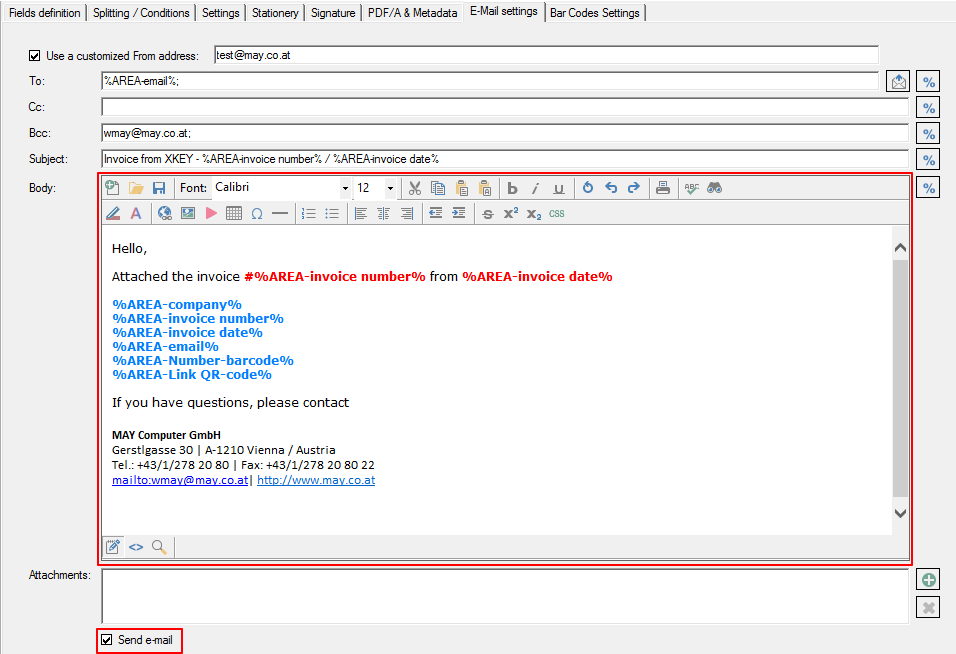
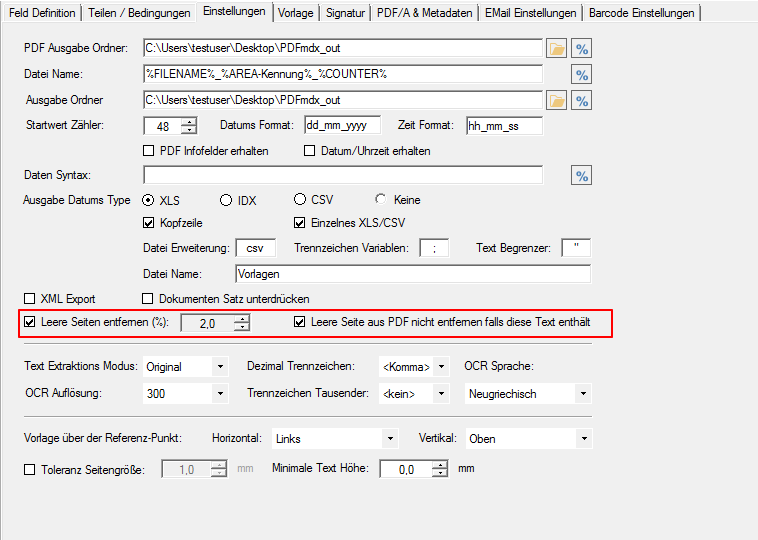
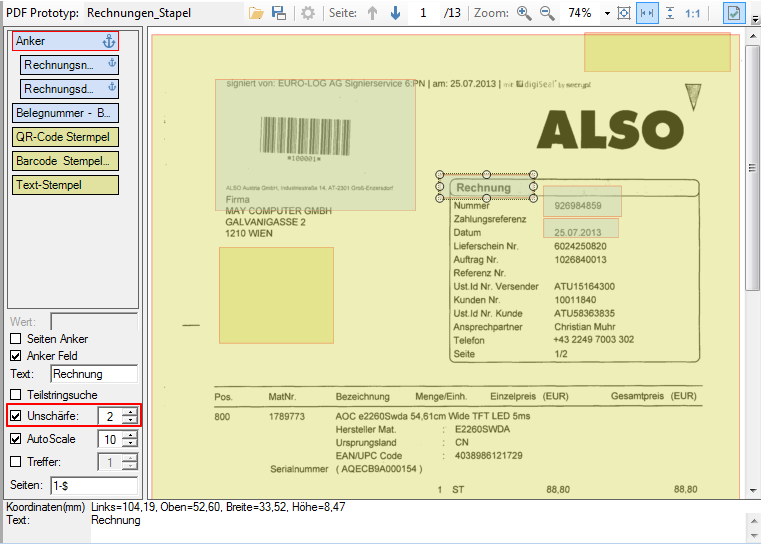
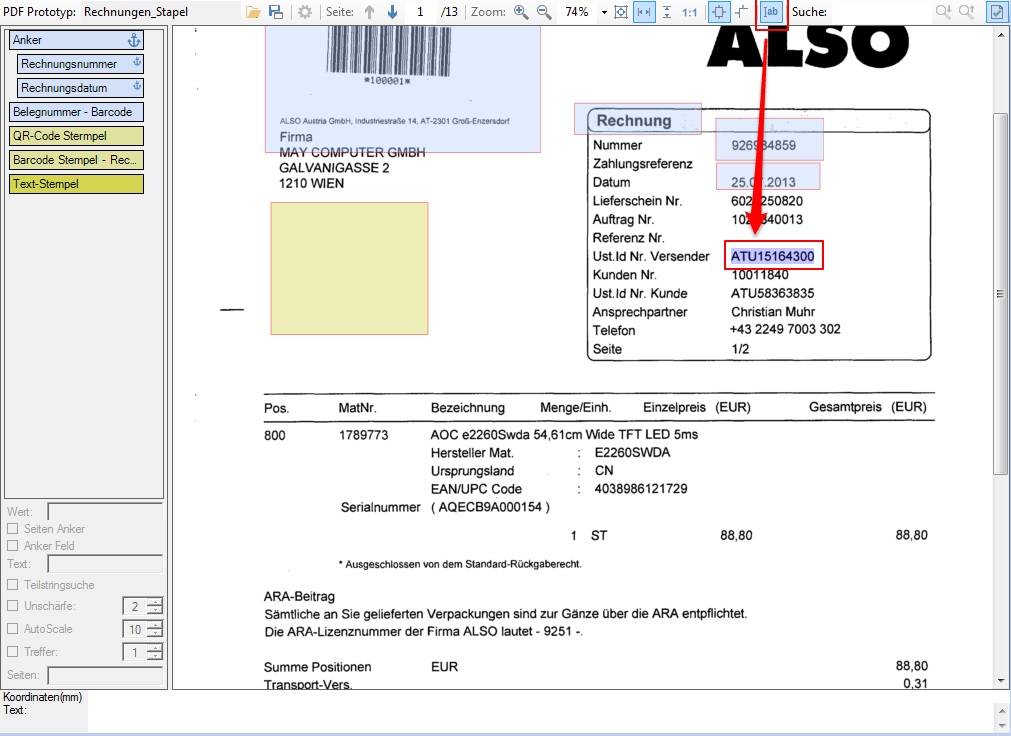
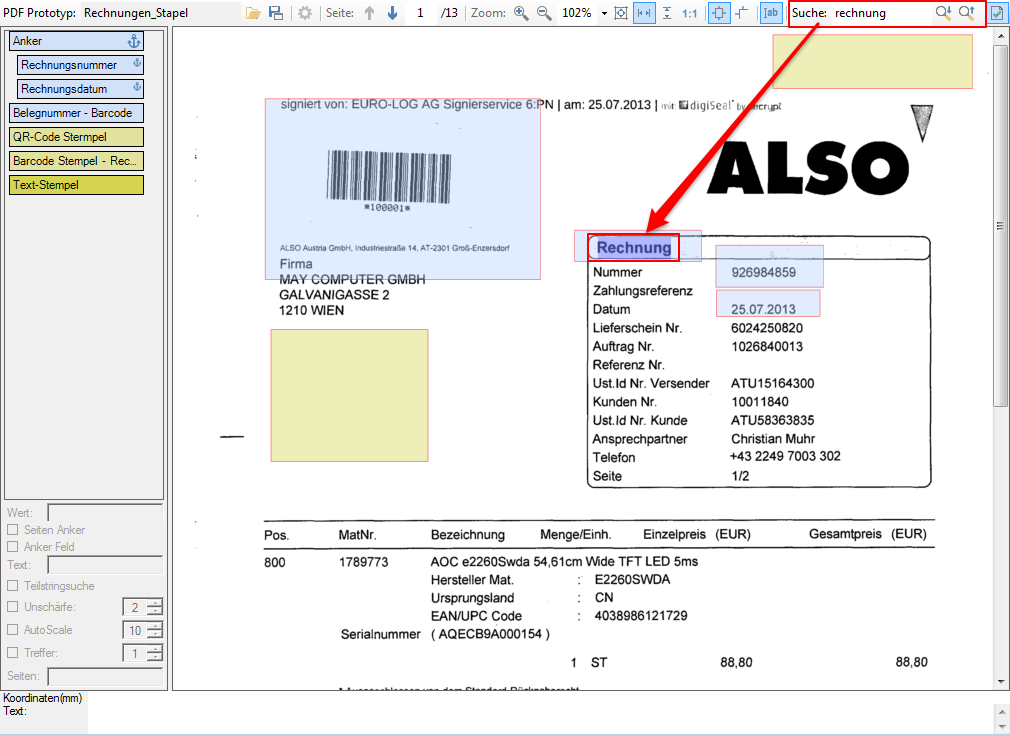
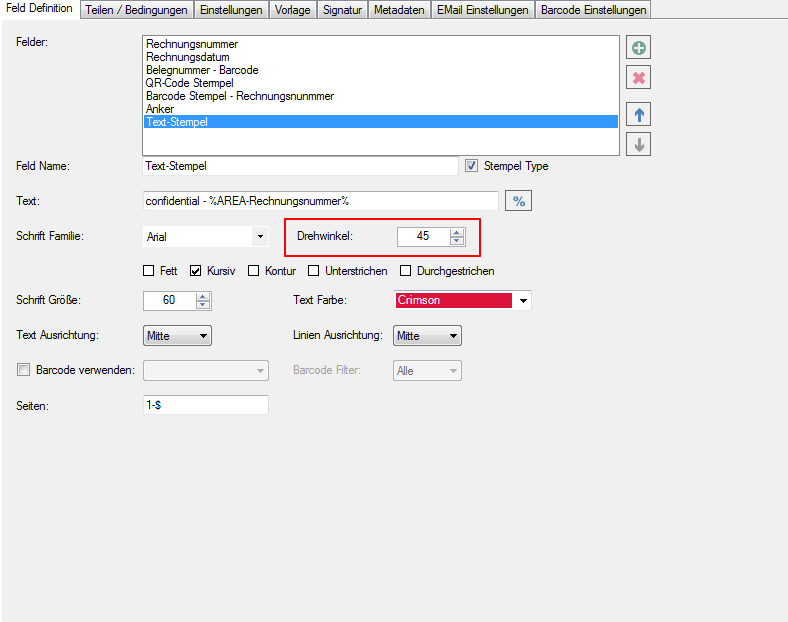
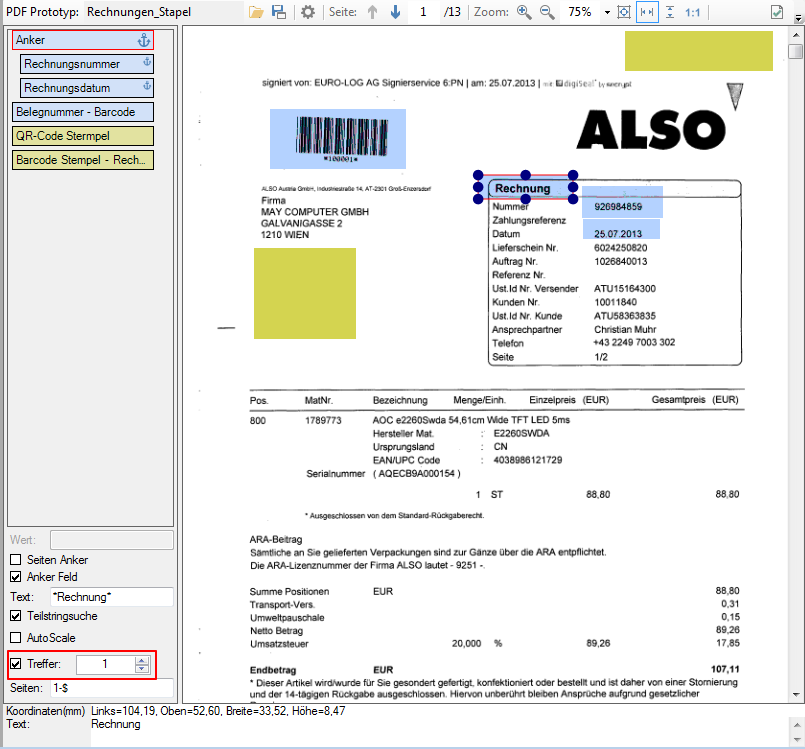
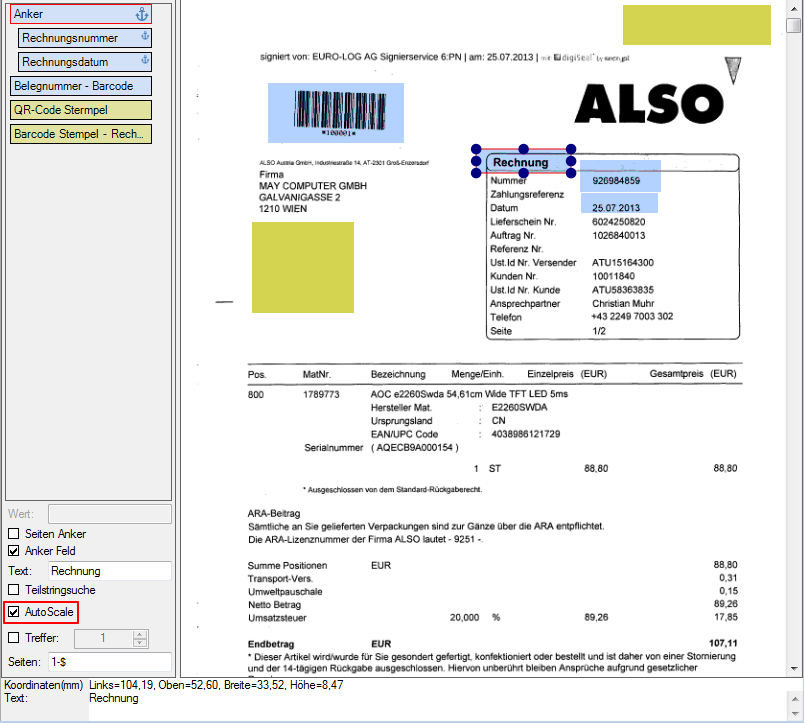
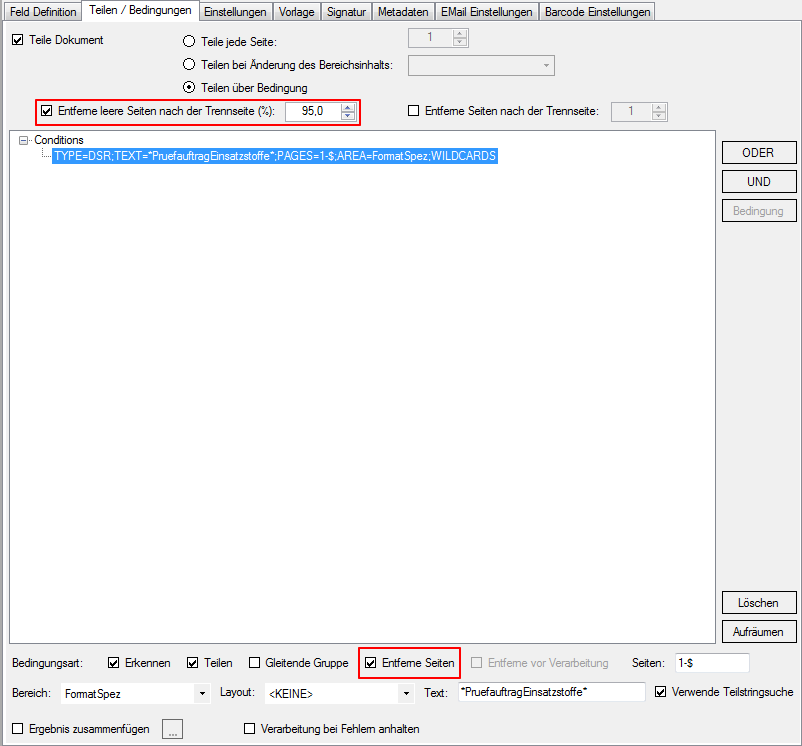
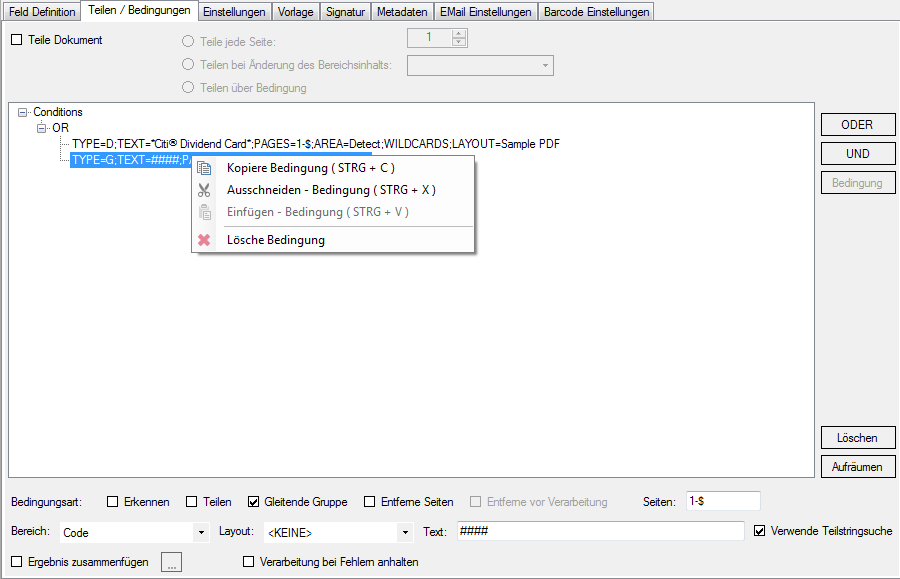
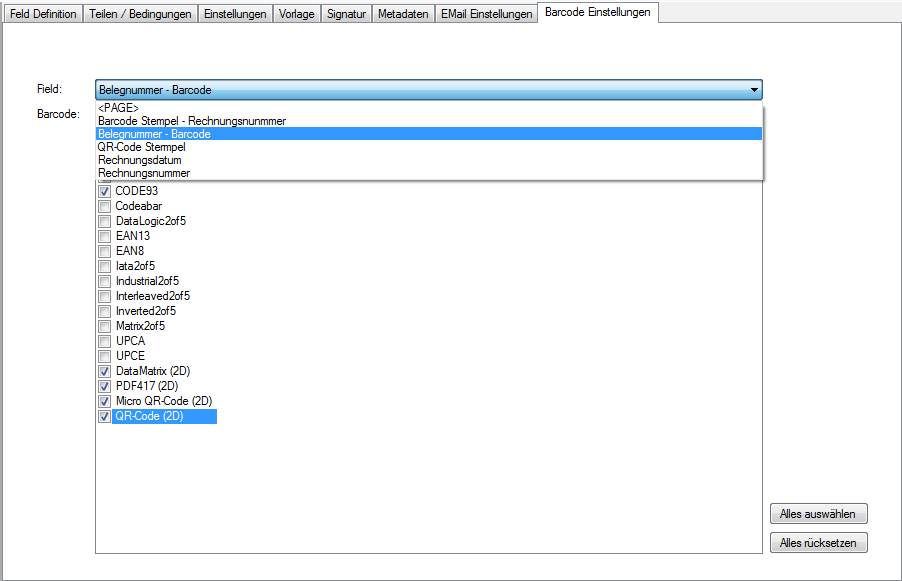
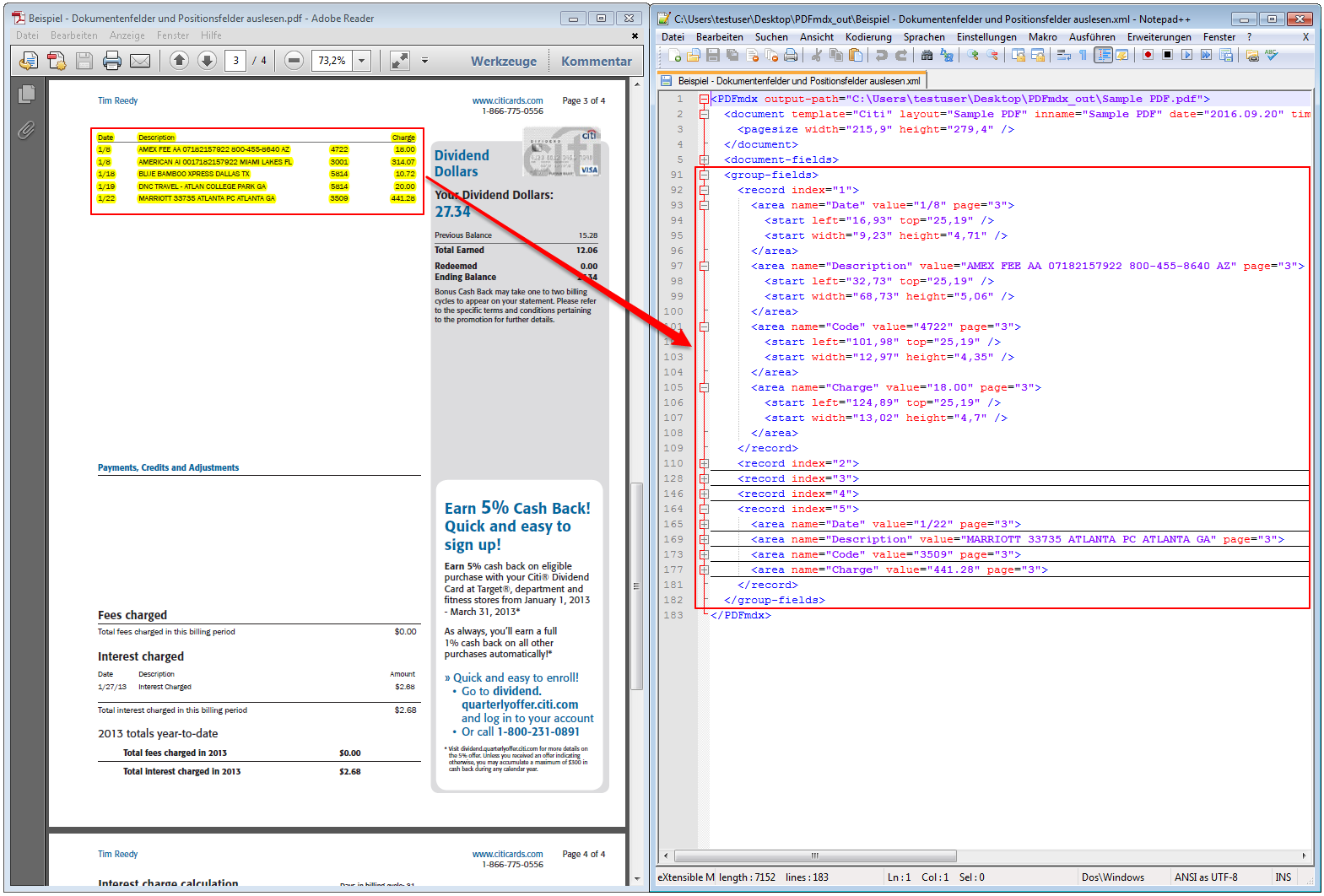
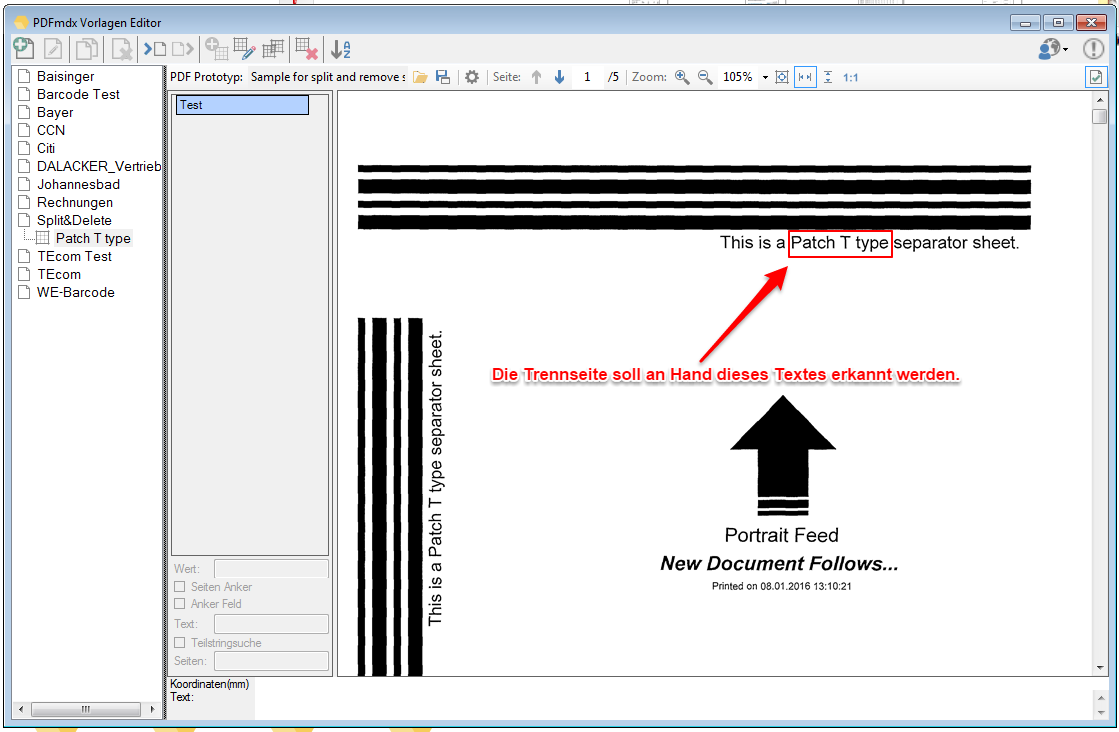
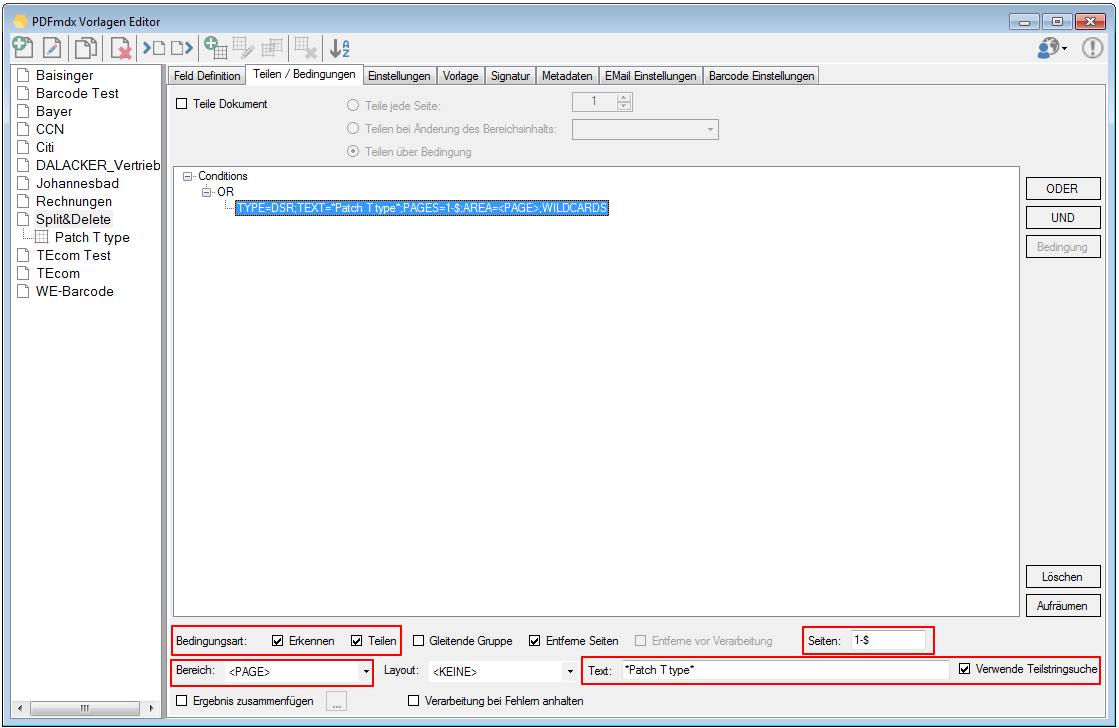
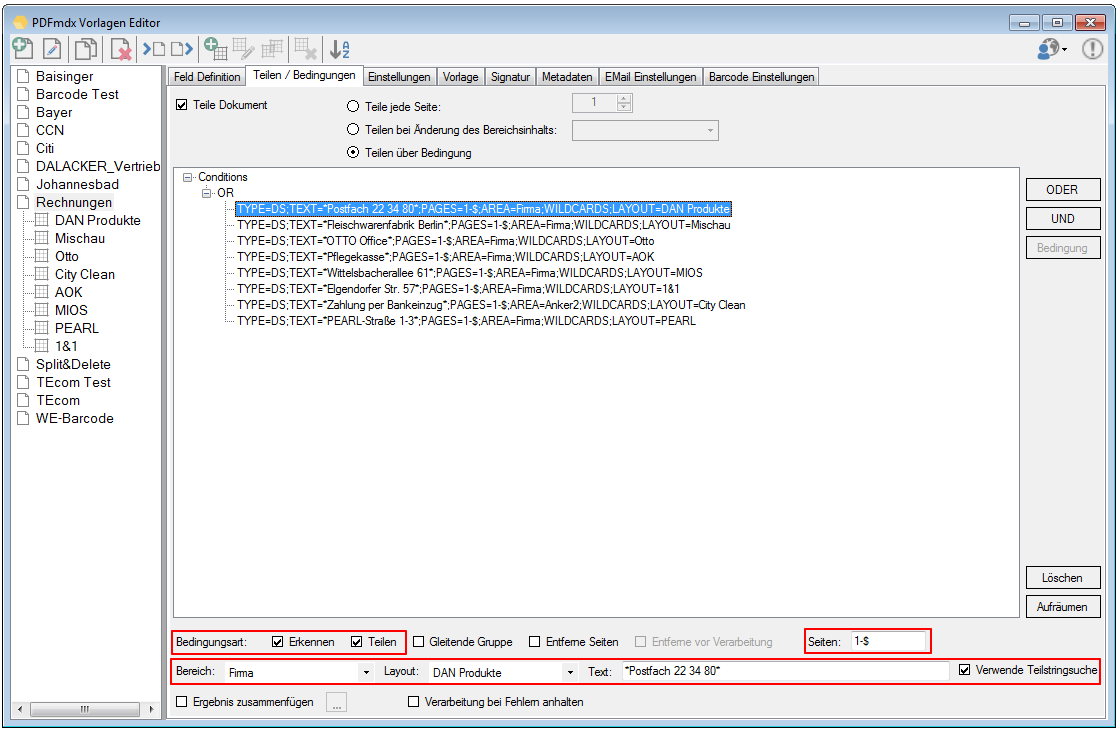
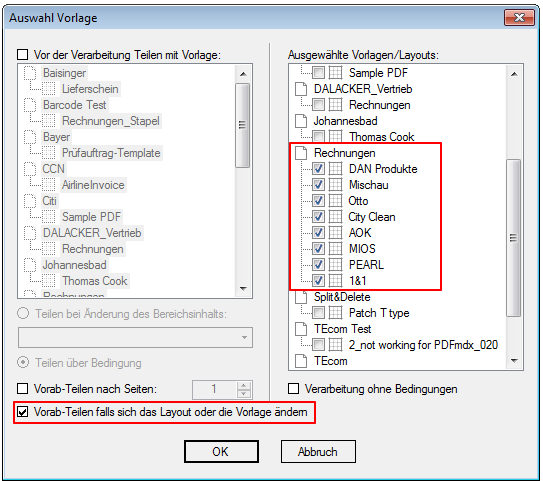
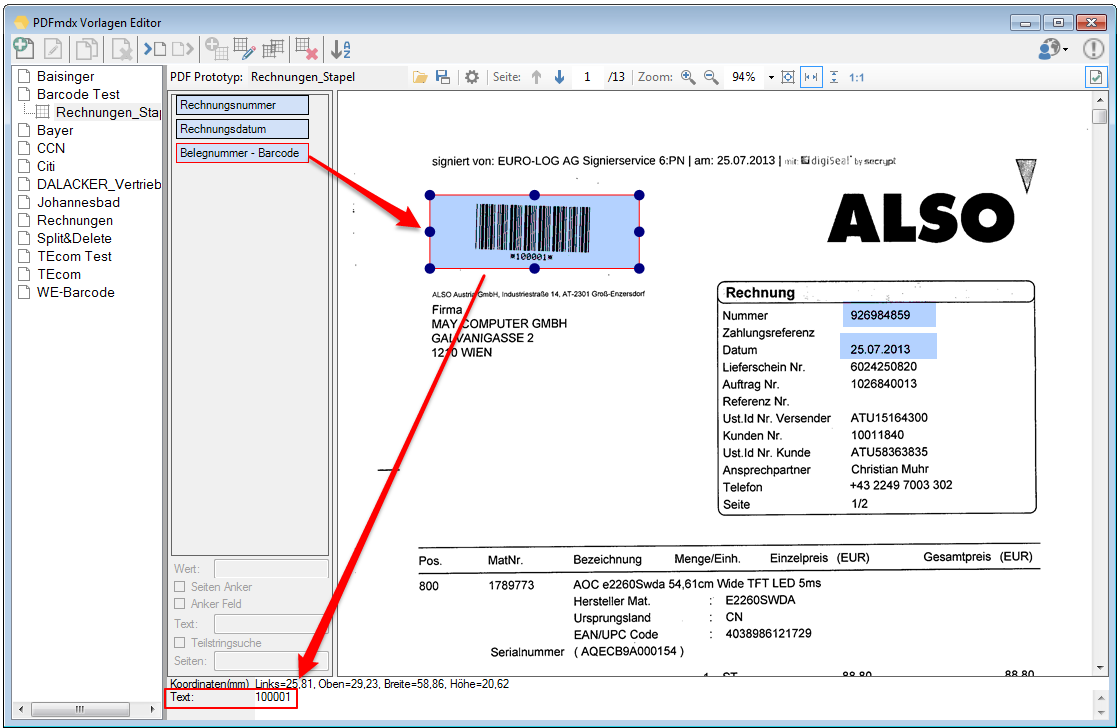
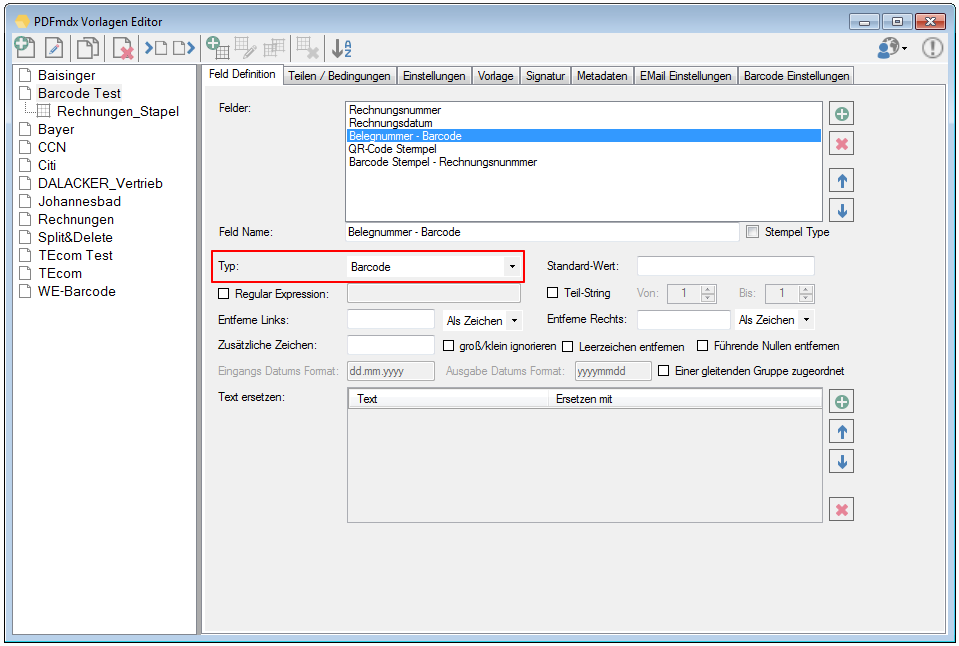
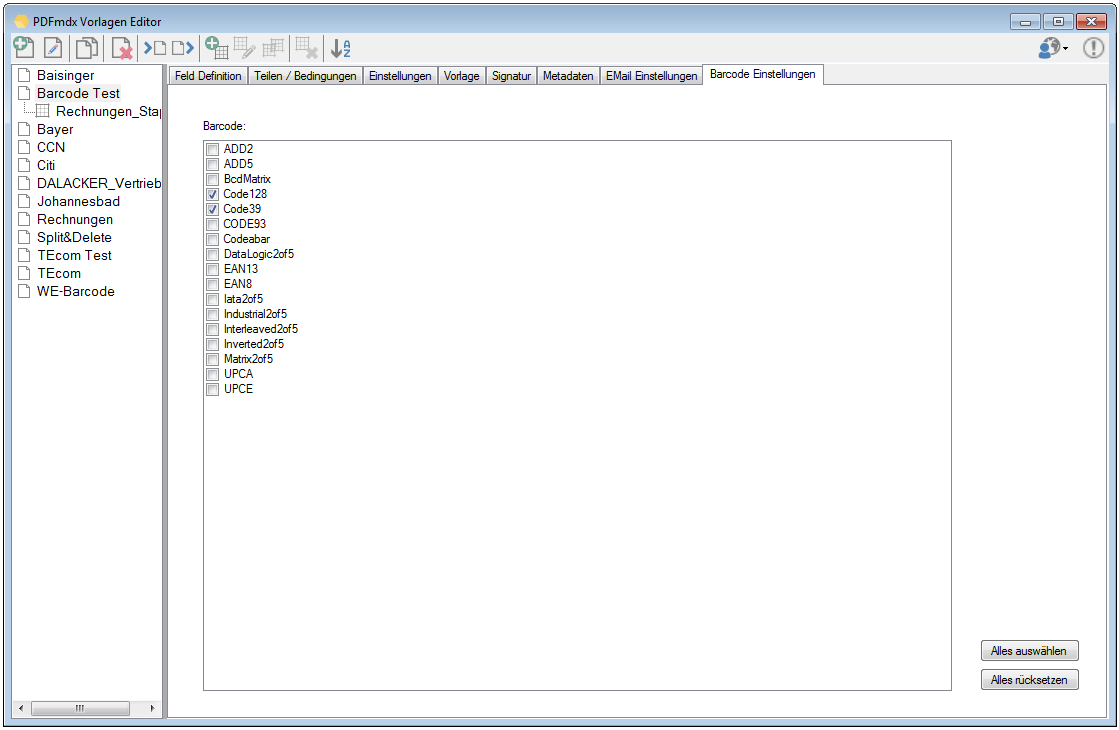
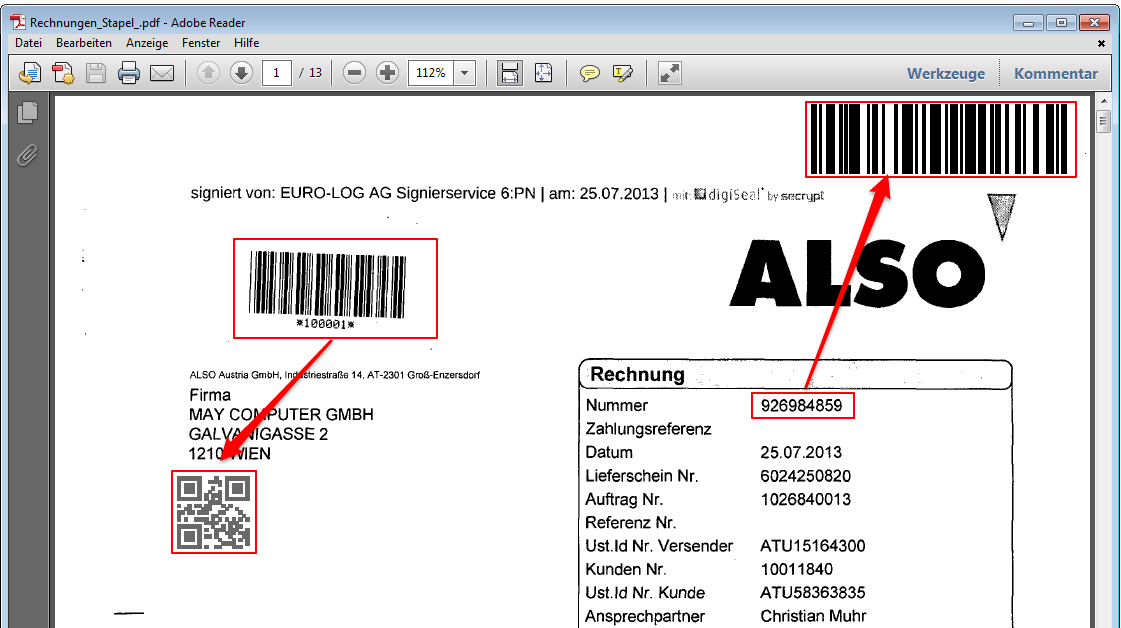
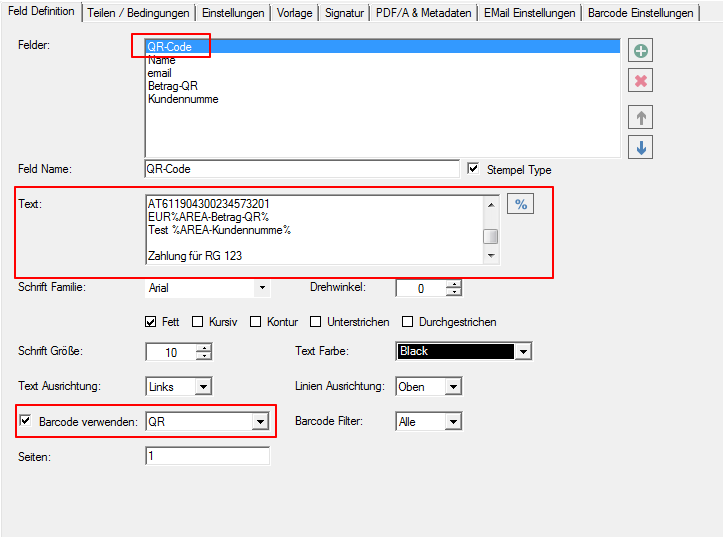
- Multiline Edit Box für Barcode- und Text-Stempel – QR-Code für Zahlungsanweisungen erstellen – Bisher konnte für die Text und Barcode Stempelung nur ein einzeiliger String angegeben werden. CR/LF wurde nicht berücksichtigt. Jetzt gibt es zum Erfassen der Texte ein mehrzeiliges Eingabefeld. Zeilenumbrüche (CR/LF) und Leerzeilen werden korrekt auf die Stempel und Barcodes übernommen. Damit lassen sich jetzt z.b. auch QR-Codes für die Erstellung von SEPA Zahlungsanweisungen generieren – Siehe QR-Code „Zahlen mit Code“. Die Grundlage für diesen QR-Code bildet eine Norm des European Payments Council. Viele Banken bieten eBanking Apps für Smartphones an, mit deren Funktionalität solche QR-Code gelesen werden können. Die Information wird dabei automatisch in eine Überweisung transferiert.


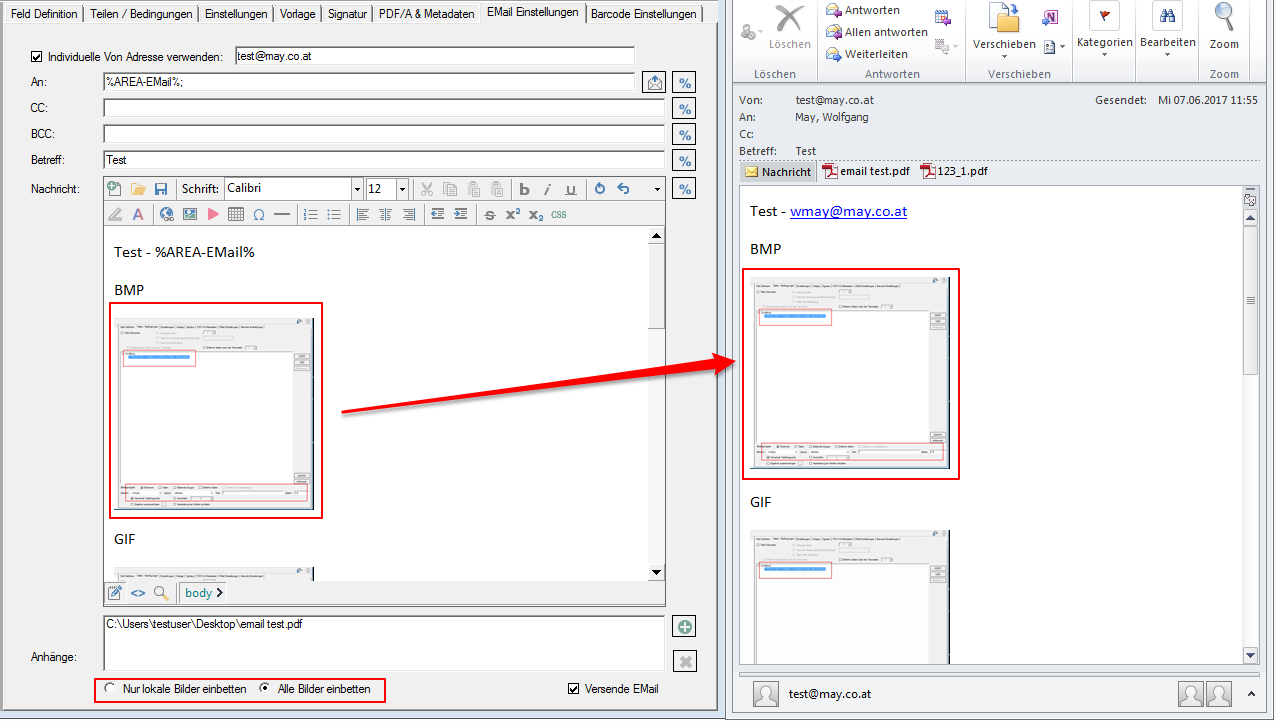
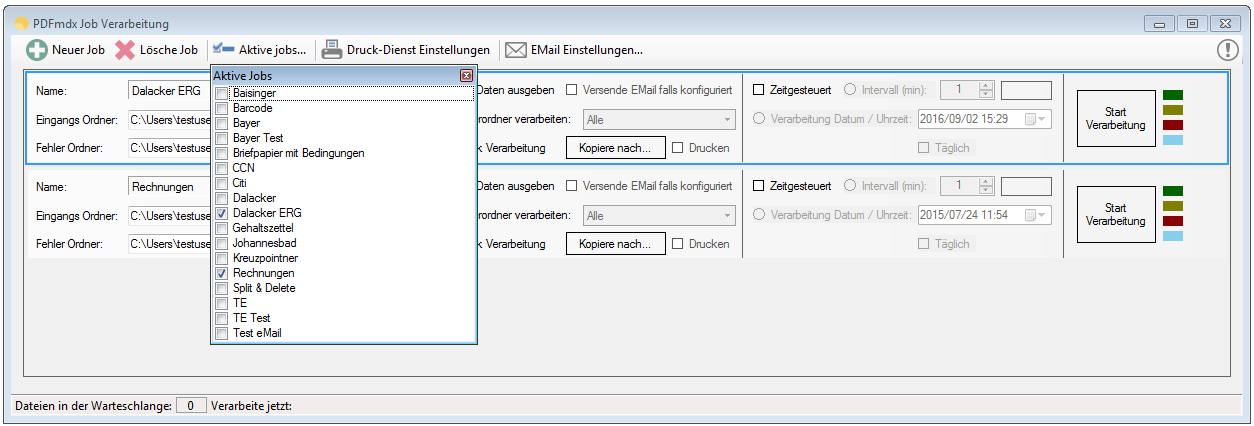
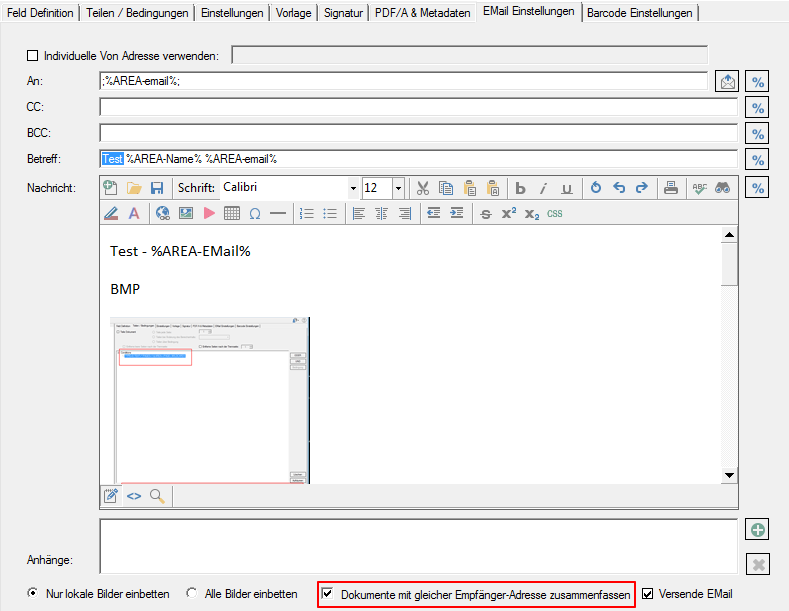
- Gleiche Empfänger zusammenfassen – Bisher konnte jedes erzeugte PDF-Dokument nur in einer eigenen EMail Nachricht verschickt werden. Jetzt ist es auch möglich bei der Verarbeitung eines Jobs alle Dokumente mit der gleichen Empfänger-Adresse zu sammeln und in nur einer Nachricht zu versenden. Der Empfänger erhält also statt bisher mehrere EMails mit nur je einem Anhang eine EMail in der alle Dokumente enthalten sind.
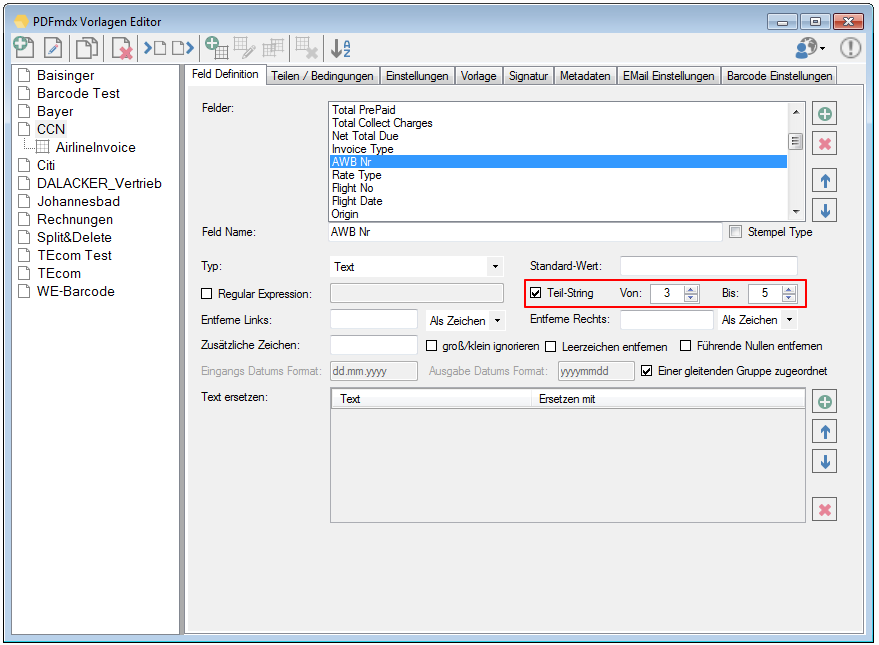
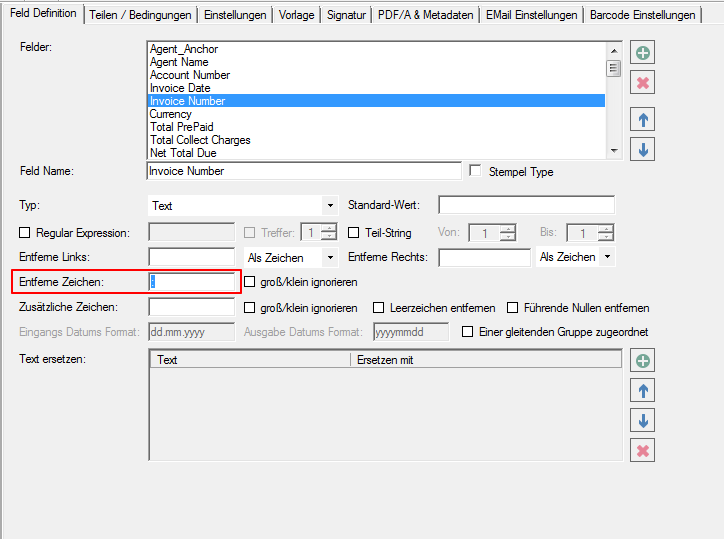
- Zeichen entfernen – Bisher hat es nur die Funktion gegeben um an Beginn bzw. am Ende eines ausgelesenen Feldes bestimmte Zeichen zu entfernen. Jetzt gibt es auch die Möglichkeit ein oder mehrere festgelegte Zeichen aus dem ganzen ausgelesenen String zu entfernen – egal an welcher Stelle diese stehen.
- Mehrere Zeichen auf einmal ersetzen – Es gab bereits die Funktion um mehrere Zeichen zu definieren die ersetzt werden sollten. Jedoch wurde die Funktion nicht „auf einmal“ sondern nacheinander ausgeführt. Damit war es z.b. nicht möglich 1,234.56 auf 1.234,56 zu konvertieren. Das wurde geändert und die Funktion wird mit allen definierten Ersatz-Zeichen auf einmal ausgeführt wodurch solche Konvertierungen jetzt möglich sind.
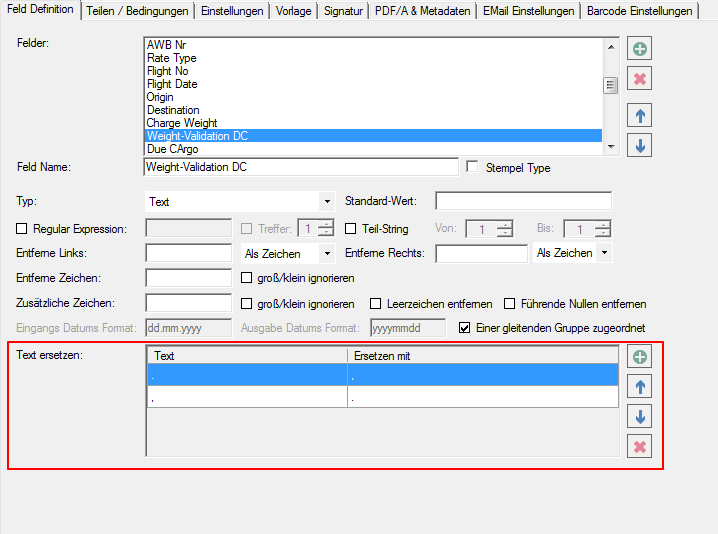
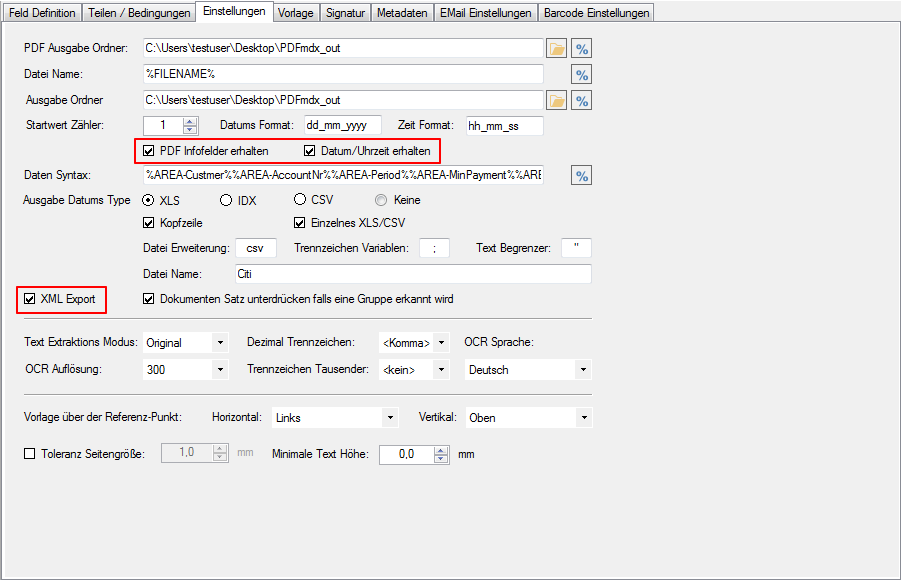
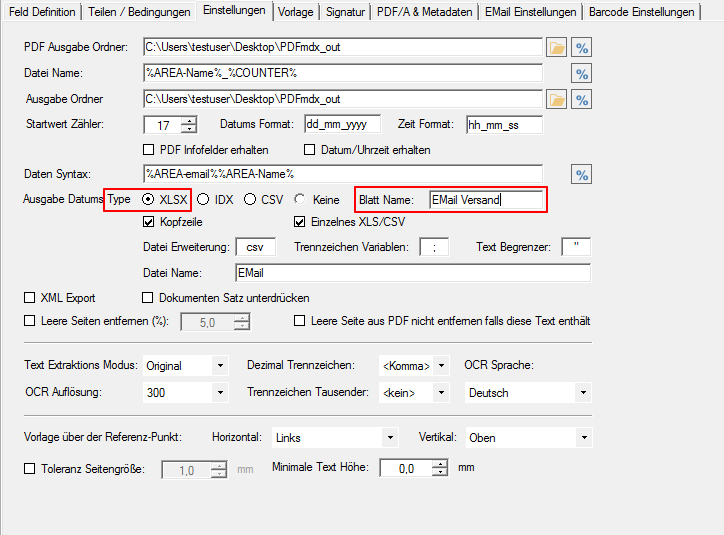
- XLSX statt XLS – sowie Blattname konfigurierbar – Das MS-Excel XLS Format wurde durch das XLSX Format ersetzt. Ebenso kann jetzt der Blattname frei vergeben werden. Bisher was der Blatt-Name im XLS mit „PDFmdx“ fix vorgegeben.
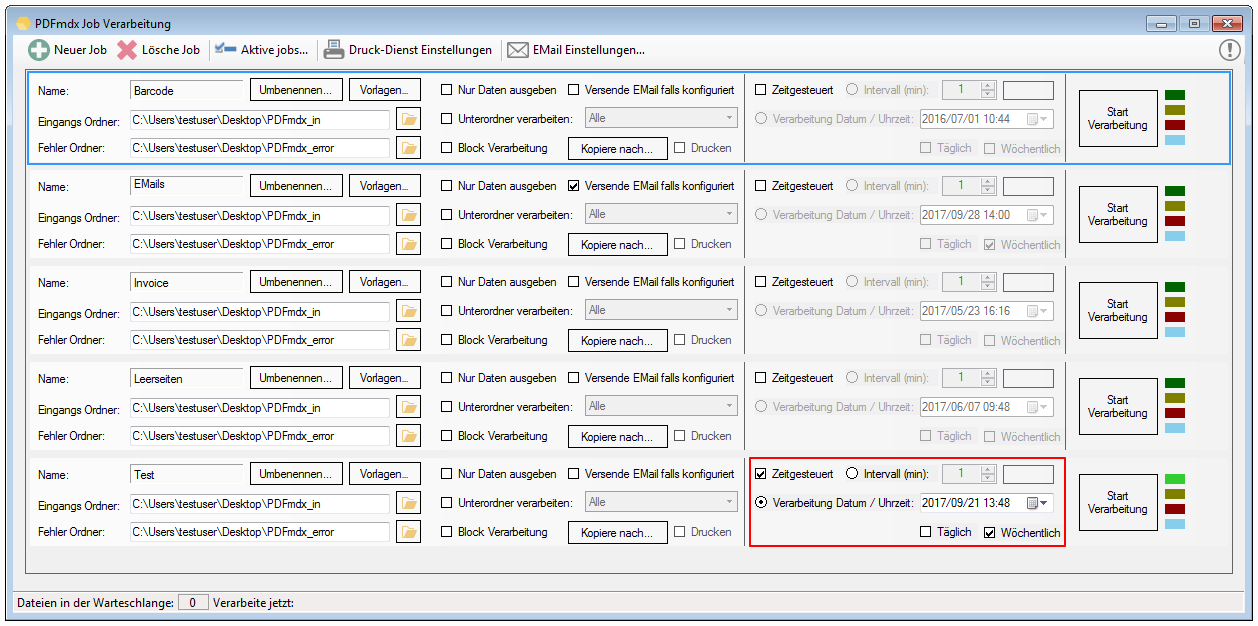
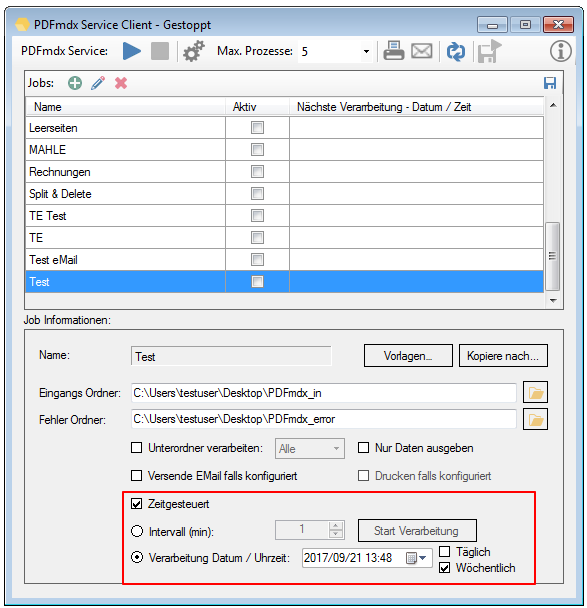
- Job wöchentlich ausführen – Zeitgesteuertes ausführen eines Jobs – Neben der Option „Täglich“ gibt es jetzt auch die Option „Wöchentlich“
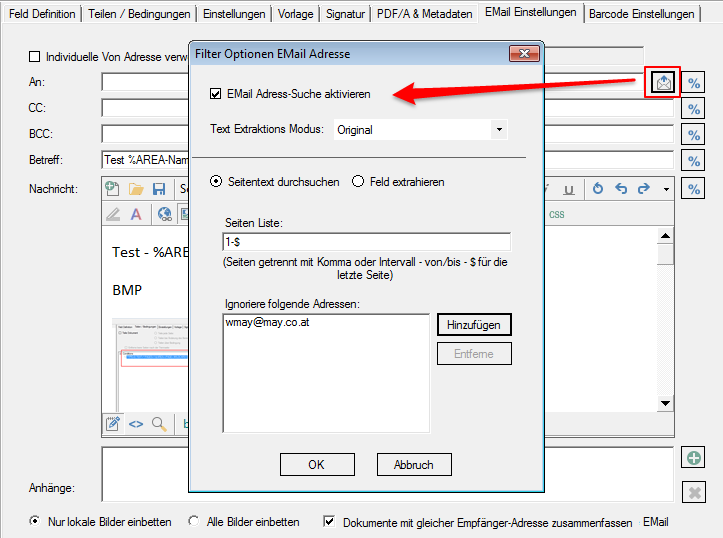
- EMail Adressen suchen – Dokument / Seite – Fehlerbehebung – Neben dem Auslesen von EMail Adressen über Felder gibt es auch die Möglichkeit alle EMail Adressen aus den Dokument bzw. auf bestimmten Seiten zu suchen und für den Versand zu verwenden.
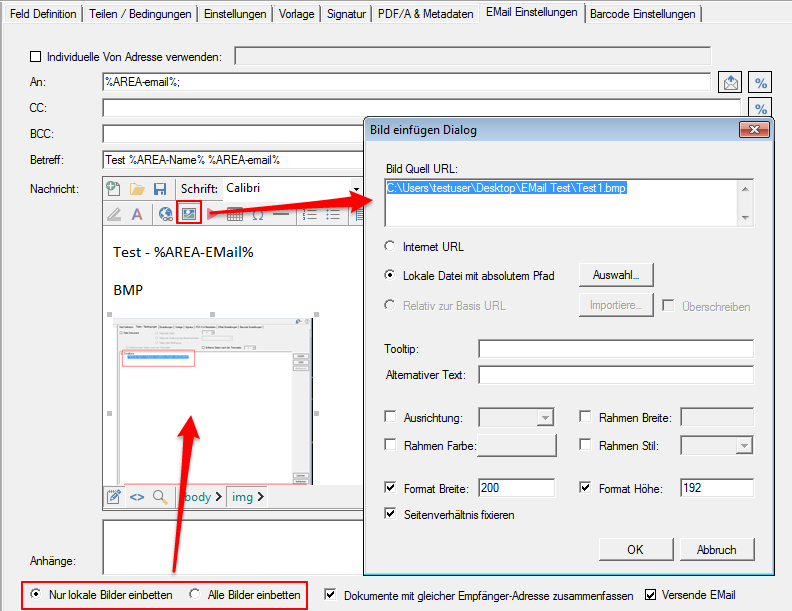
- HTML Body – Bilder einbetten – Fehlerbehebung beim HTML EMail Versand – Bei manchen EMail Clients / Web-basierenden EMail Diensten (z.b. Web.de) wurde falls Bilder im Body eingebettet wurden die Nachricht als HTML Code / Text und damit nicht richtig dargestellt .