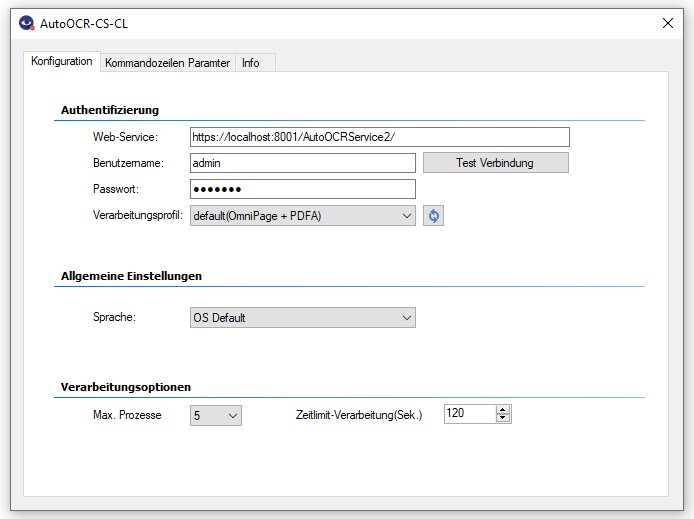
AutoOCR-CS-CL – Command line application for AutoOCR via Web-Service
AutoOCR-CS-CL is a command line add-on application available free of charge for the AutoOCR server. AutoOCR-CS-CL enables the conversion of image PDF, TIF/TIFF, JPG/JPEG, PNG, BMP, GIF files into searchable PDF or PDF/A files. Communication with the AutoOCR server is done with http/https via the AutoOCR SOAP web service interface. The AutoOCR server can be addressed locally, in the same network or via an Internet connection.
Features AutoOCR-CS-CL:
- Free command line application for AutoOCR to generate searchable PDF(/A) via OCR from Image-PDF, TIF/TIFF, JPG/JPEG, PNG, BMP, GIF.
- Processing takes place via SOAP web service on a (remote) AutoOCR server via http/https.
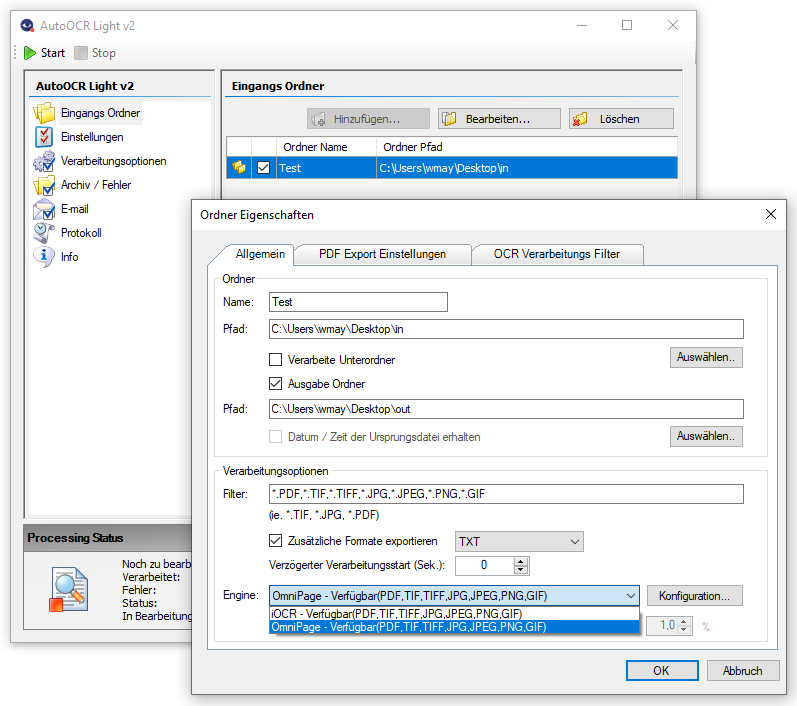
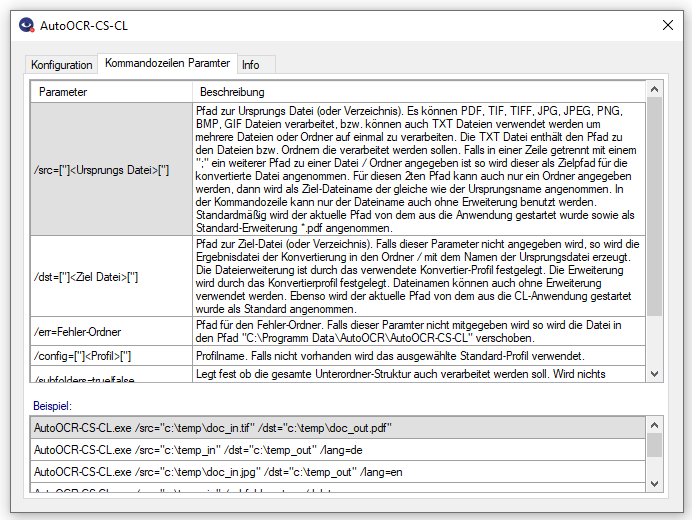
- Processes individual files, entire folders / folder structures as well as lists of files / folders from TXT files.
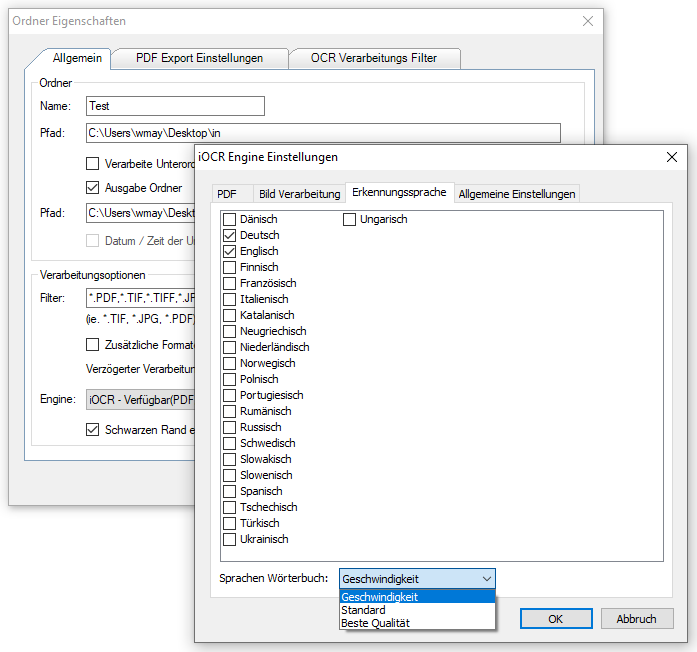
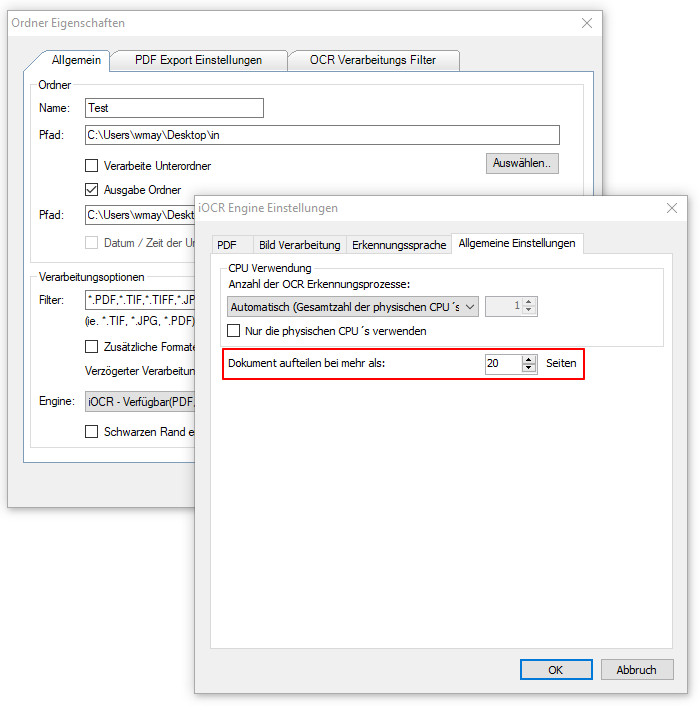
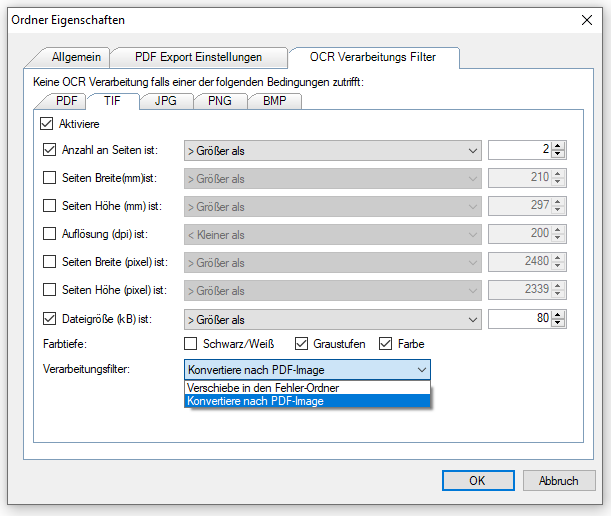
- Selection of the processing parameters by specifying an OCR profile stored on the AutoOCR server.
- Parallel multiple upload / download to AutoOCR server configurable for optimal throughput.

Download – AutoOCR-CS-CL – Command line application for AutoOCR via Web-Service >>>
Download – Readme / Help – AutoOCR-CS-CL >>>