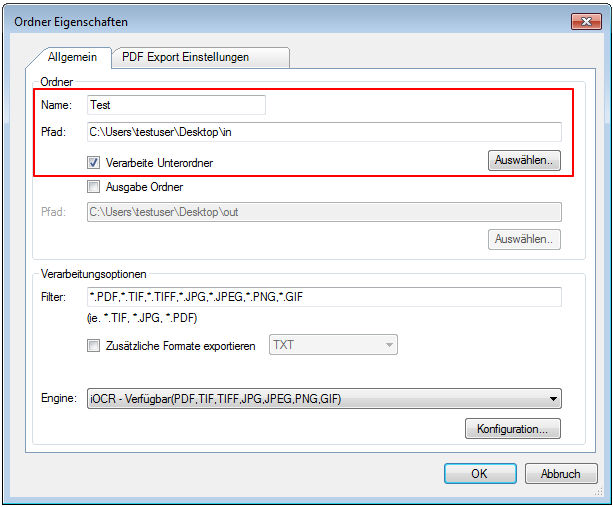
AutoOCR Version 1.15.3 available
Innovations AutoOCR Version 1.15.3:
- New iOCR Engine – We replaced the previous standard iOCR engine with a new product – vsOCR –. This results in a better detection rate as well as a significantly better performance for multicore / multiprocessor computers. With the new OCR Engine, we now support parallel / multithread processing with multi-page TIFF and PDF documents. The OCR processing speed is thereby multiplied, if, for example, 4 or 8 cores are available.

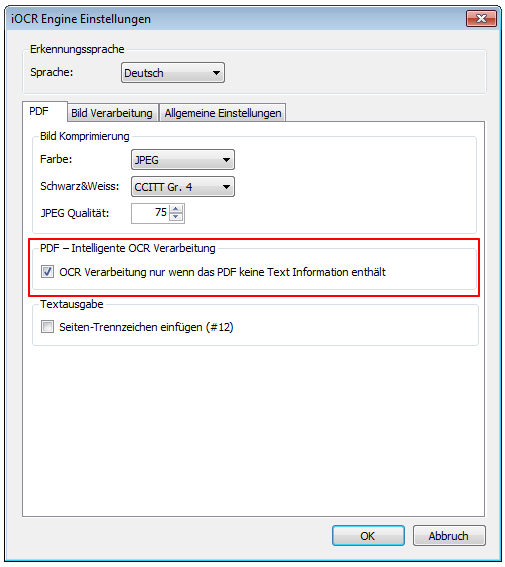
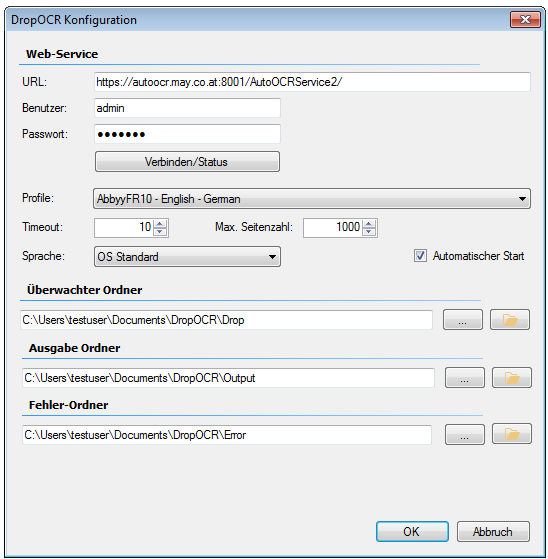
- iOCR – PDF rendering resolution configurable – Since only image / image documents can be processed by OCR, PDF documents are always subjected to an image (rendering) prior to OCR processing. There is now the possibility to configure the rendering resolution for SW and color, whereby the default value for SW and color is 300dpi.

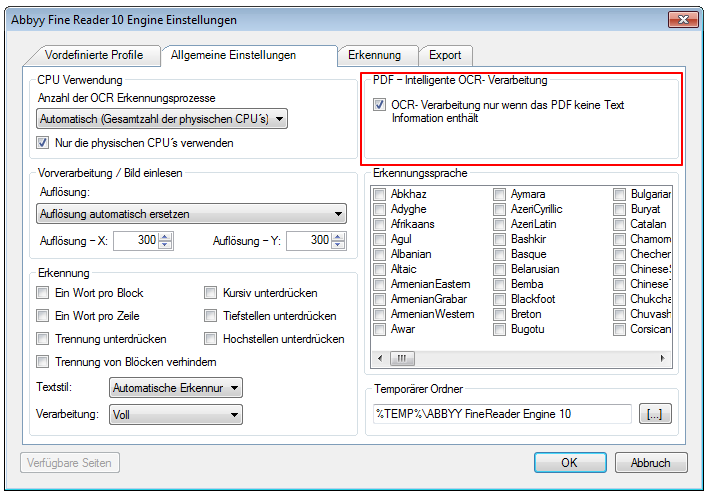
- Abbyy OCR – New default settings – Based on our experience so far, we have redefined the default settings to achieve the best possible recognition rate as well as the highest possible OCR performance. A single option can affect the processing speed, especially for multi-page documents with a lot of text by a factor of 5 or 10 or more – A 10 page document can be stored in either 10 sec. or in 5 min. depending on whether the “Recognize font formatting” option is enabled or not.
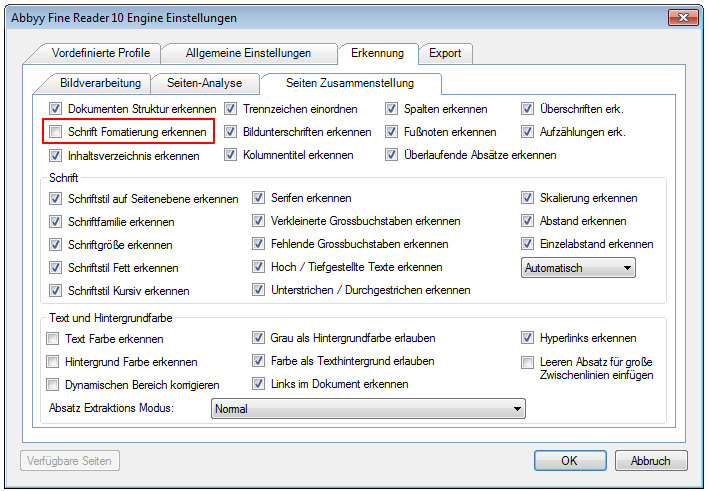

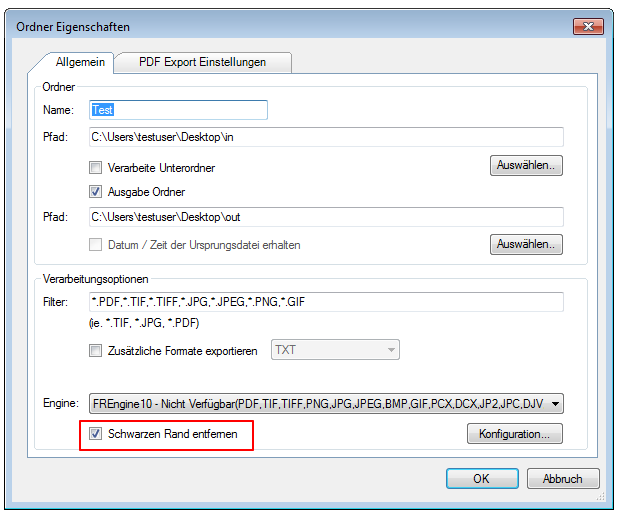
- “Remove black border“ – Was added as a new general image processing function for iOCR and Abbyy. Thus, a possible black border is detected and removed in all documents before OCR processing. The page size is not changed.
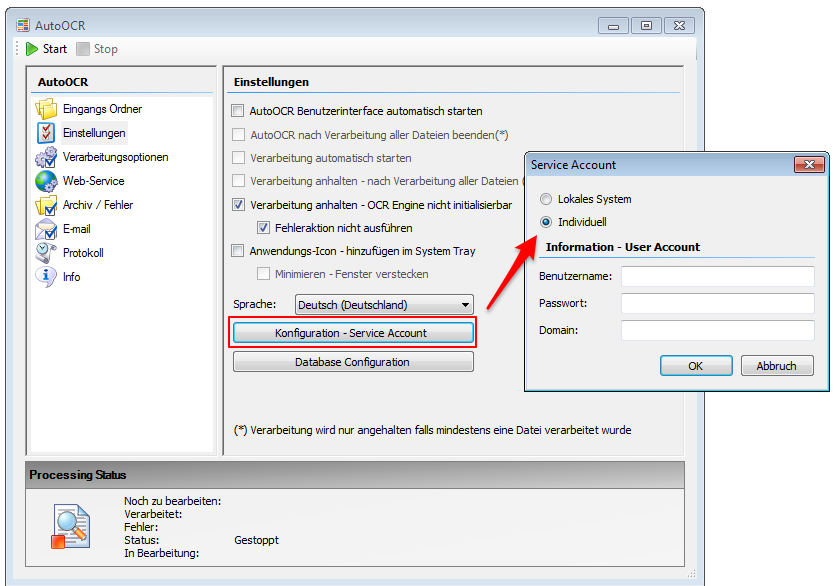
- Configure an invalid license response – Stopping the service (default value) or demo stamp on the document.
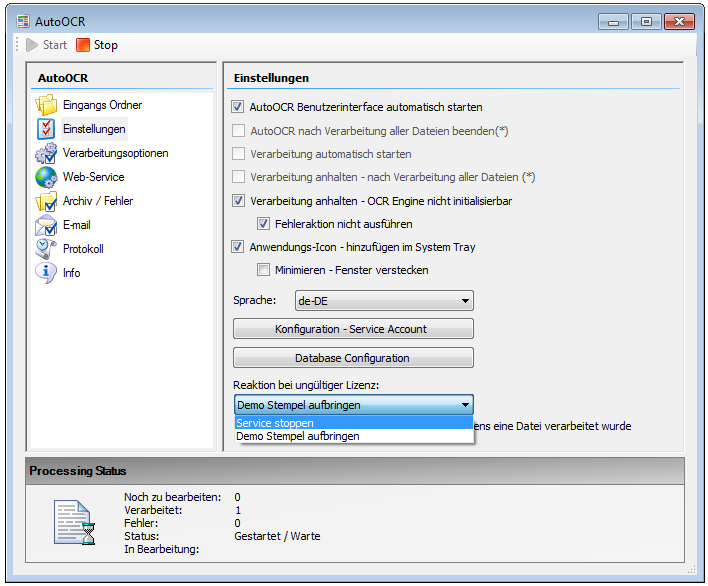
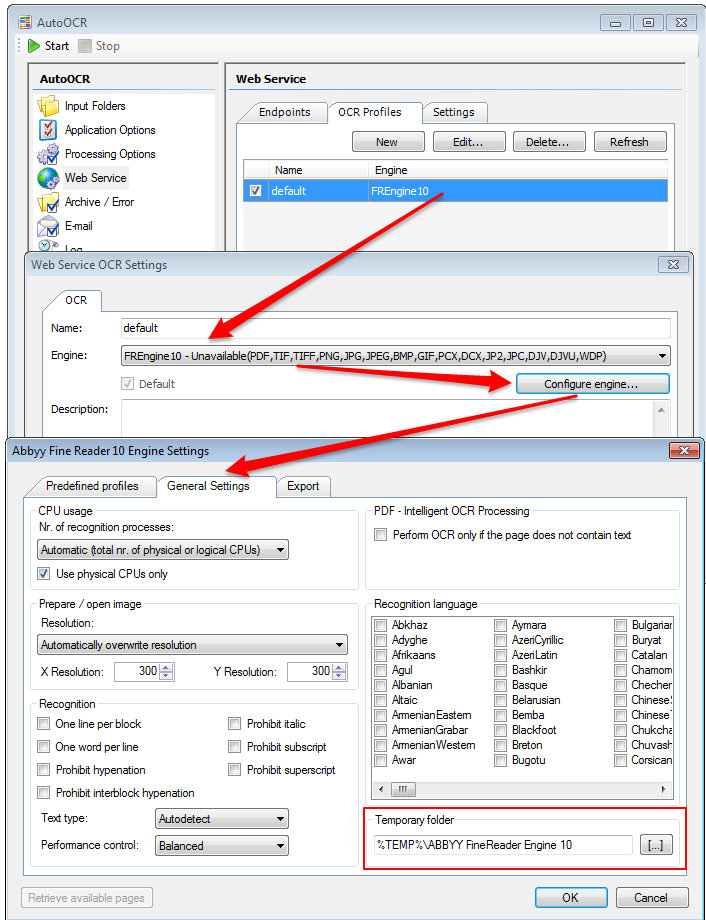
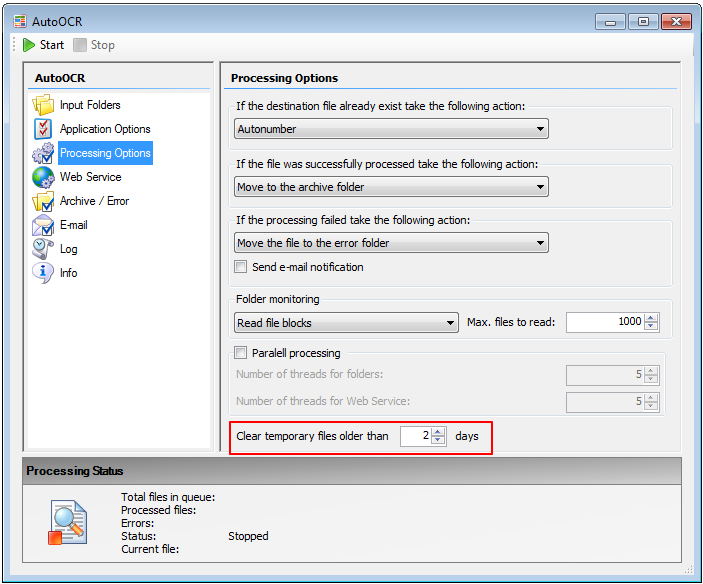
- Further adjustments: Autostart of the AutoOCR User Interface – is now activated by default. Error while creating the optional TXT file with iOCR has been fixed. Read-only PDF documents do not produce endless loops when processing. The temporary Abbyy Folder is now correctly deleted after the set number of days. Language-specific special characters are now encoded correctly with the Abbyy PDF/A output.
Download – AutoOCR – OCR Server ohne iOCR (vsOCR) Engine (ca. 10MB) >>>
Download – iOCR (vsOCR) Engine (ca. 270MB) >>>
See also:AutoOCR – Installation requirements from version 1.15.3
For the Abbyy OCR Engine version 10 demo licenses are available for 30 days or 500 pages – you can request them per mail
Download – Abbyy FineReader 10.x Rel 4 OCR Engine Setup (ca. 460MB) >>>