ifresco Tools – RepoWorker scripts – convert Alfresco documents to searchable PDF or PDF/A automatically
The module ifresco Tools offers the following functions for the Alfresco ECM / DMS:
- ifresco-RepoWorker – enables time-controlled execution of a repository-JavaScript on a definable amount of documents.
- ifresco-ScriptAction – enables the definition of share-actions which execute Repository-JavaScript on documents.
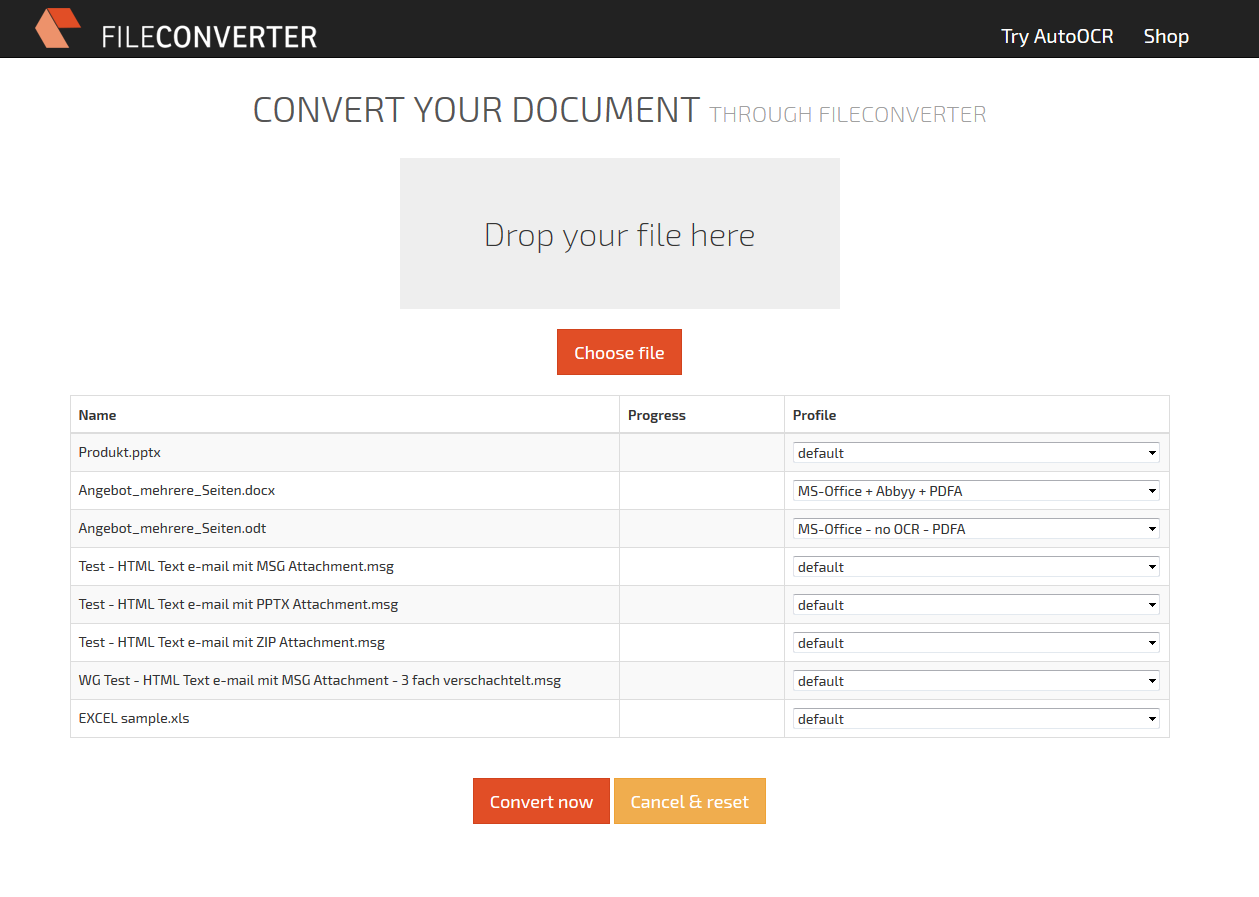
RepoWorker – scripts integrate AutoOCR and FileConverterPro:
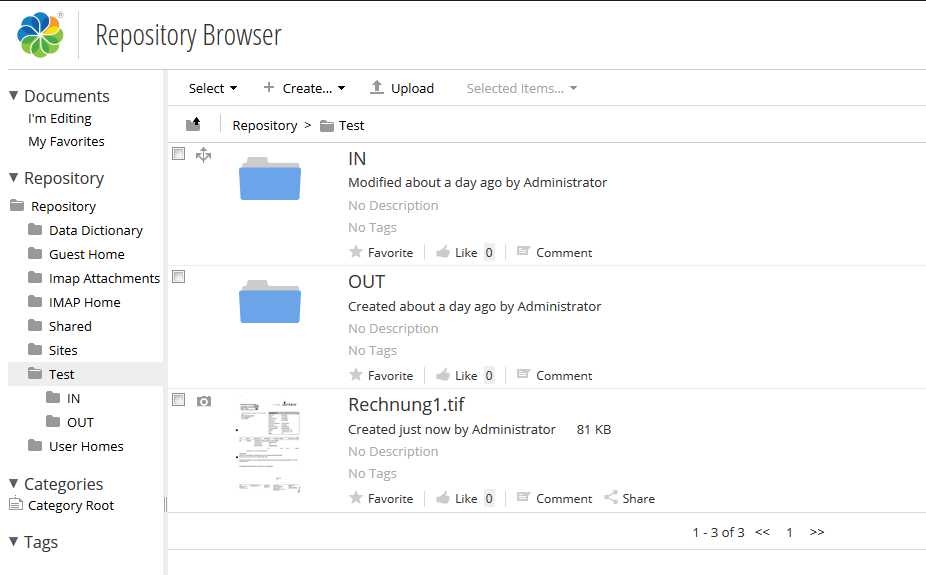
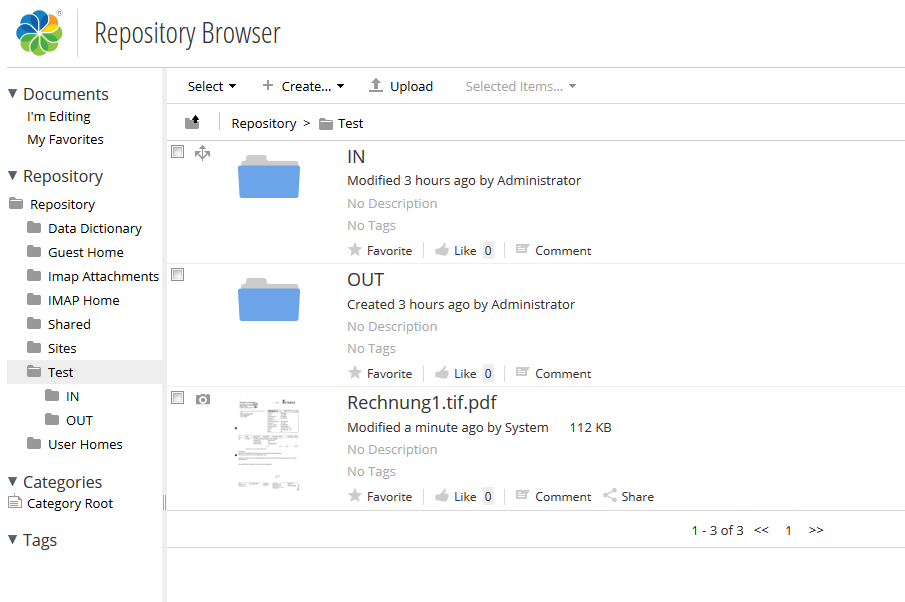
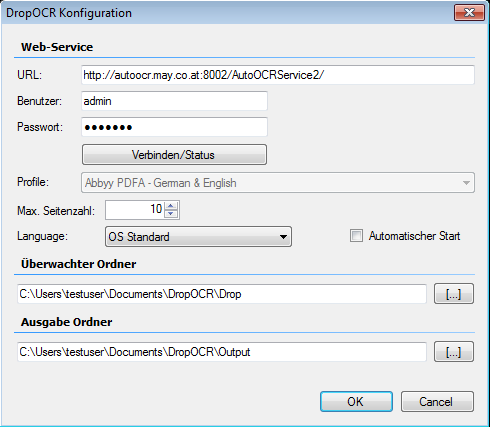
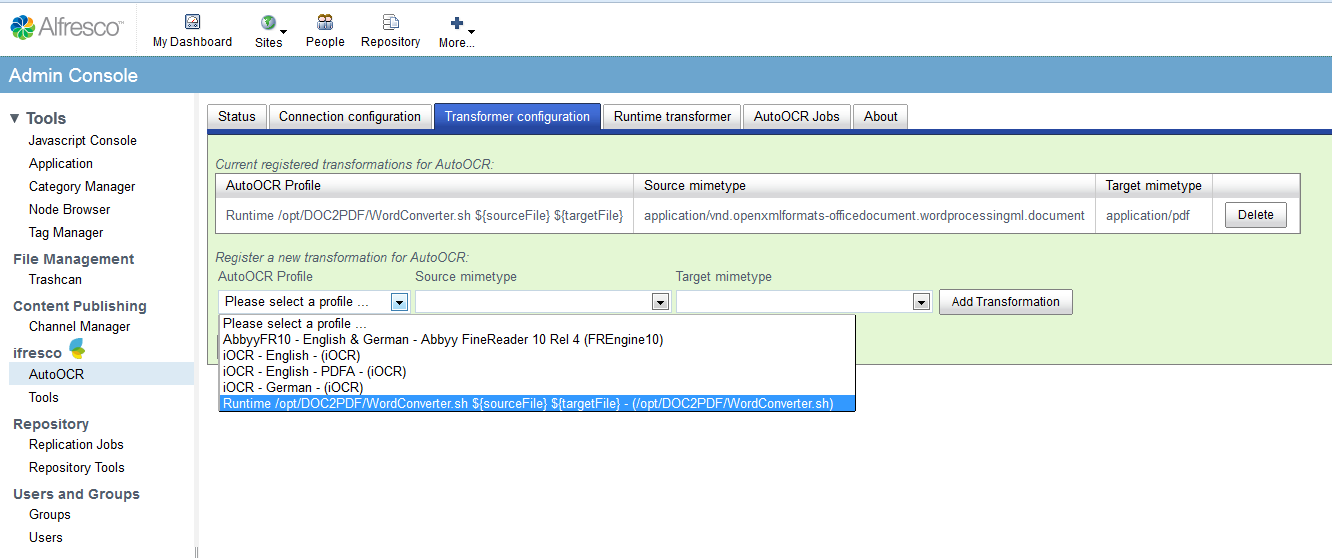
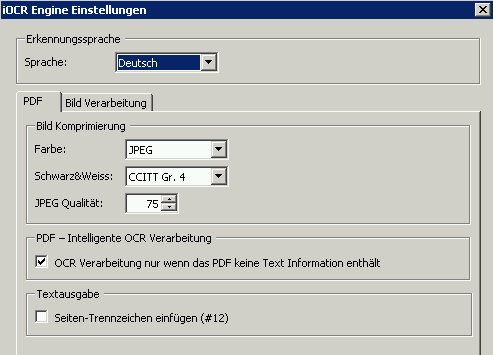
With the RepoWorker we created an extension for the ifresco Transformer based on scripts. With that all existing and / or newly added documents of specific content- or MIME-types of an Alfresco server are converted to searchable PDF or PDF/A documents. The user doesn’t has to be concerned with it, the conversion takes place at the server automatically, indepent of how the documents are added into the ECM / DMS.
Functions:
- time-controlled execution of JavaScript on a definable amount of documents
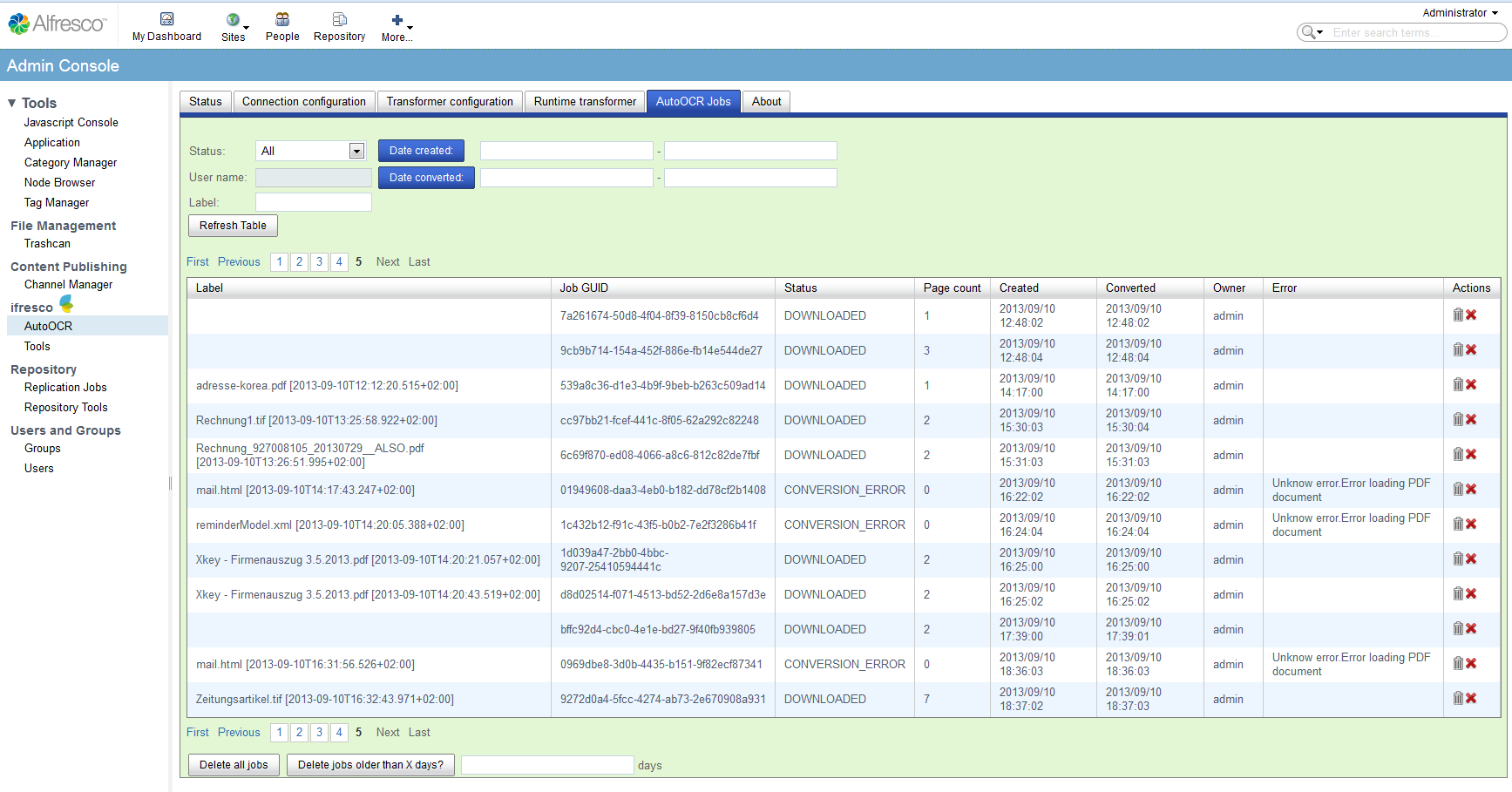
- existing documents of a specific content- and MIME-type get converted to searchable PDF or PDF/A and replace the source-documents.
- processed documents get marked with the “Transform” aspect to prevent a repeated processing.
- singular or in definable time intervals repeated execution of scripts e.g. every 5 min
- scripts can easily and quickly be adjusted to new conditions and requirements.
- easy installation and configuration
Description – RepoWorker scripts for AutoOCR / FileConverterPro >>>
GitHub – RepoWorker scripts for AutoOCR / FileConverterPro >>>
Requirements:
- Alfresco 4.x,
- AutoOCR or FileConverterPro ,
- ifresco Transformer (AMP).
- ifresco Tools (AMP)
A demo installation can also be found on our ifresco / Alfresco testserver (admin / admin)