AutoOCR / AutoOCR light Version 2.0.15
Neuerungen AutoOCR Version 2.0.15:
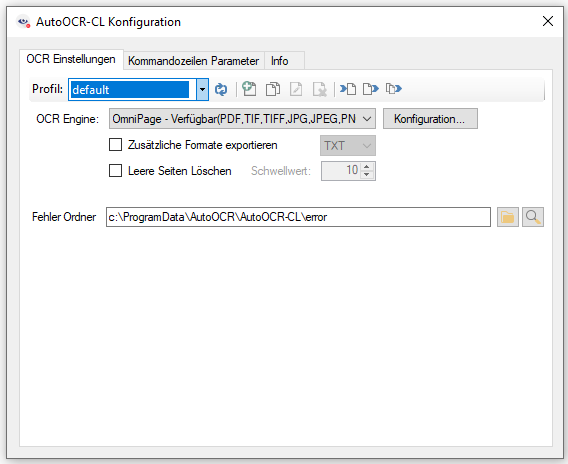
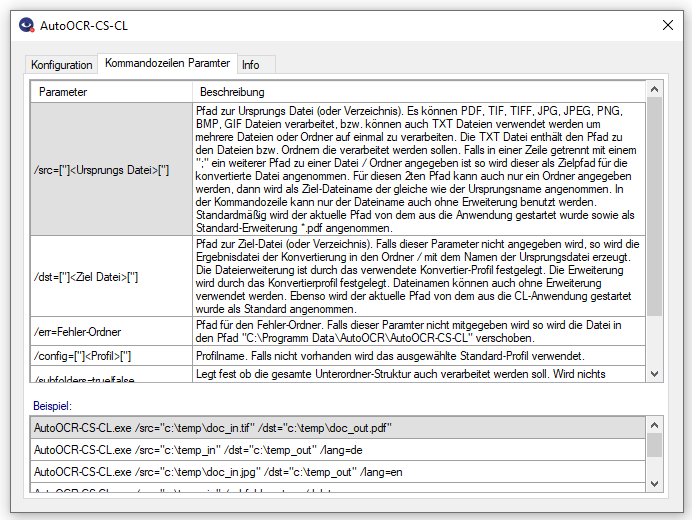
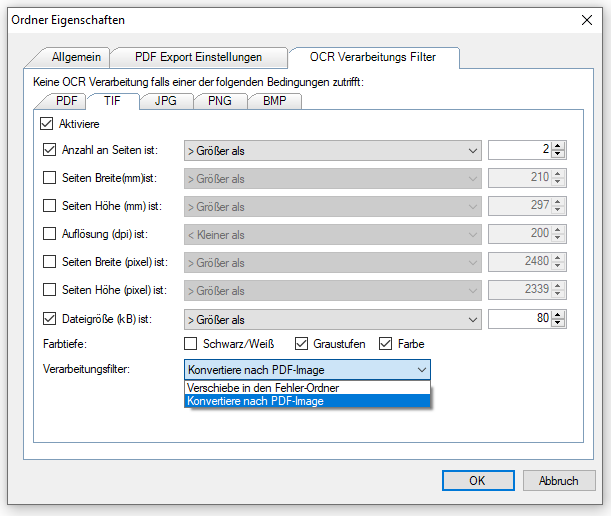
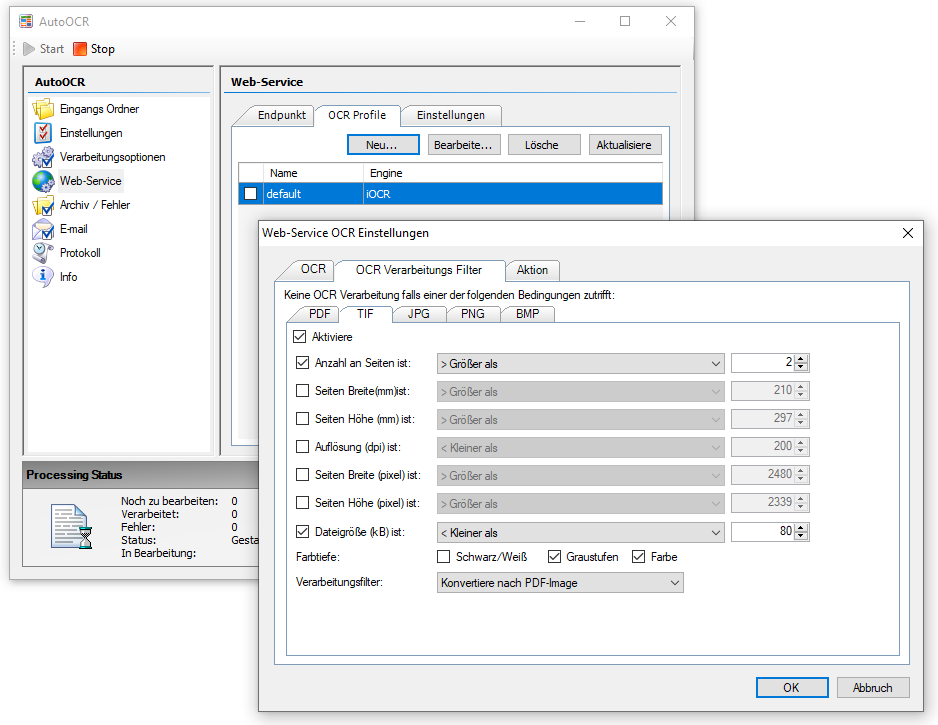
- Neue Funktionen / Tabs für „Bildverarbeitung“, „PDF Infofelder“, „PDF/A“ und „PDF Compressor“

- Image Processing: Die Image Processing Funktionen wurden wesentlich erweitert und stehen außerhalb der OCR Engines zur Verfügung. Damit können die Scans vor der OCR Erkennung noch optimiert und verbessert werden, um die Erkennungsgenauigkeit zu erhöhen und die Bildqualität zu verbessern. Image Processing ist auch Bestandteil von AutoOCR light.
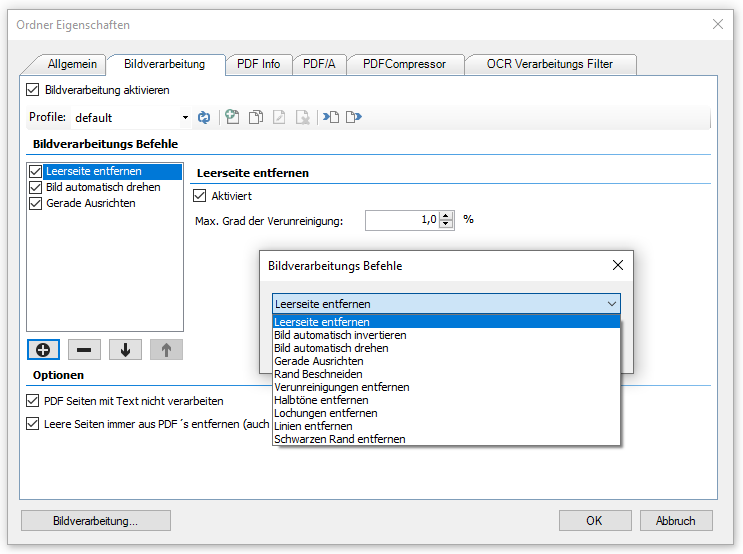
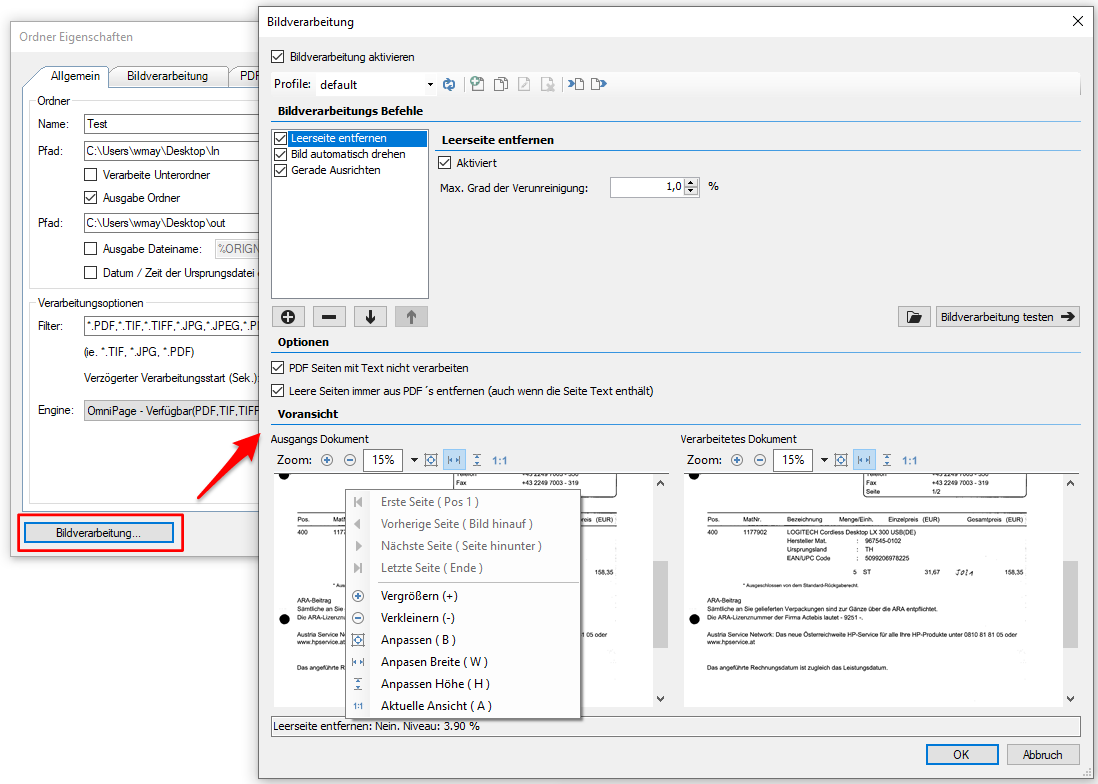
Bildverarbeitungs Funktionen:
-
- Mehrere Funktionen können in einer vorgegebenen Reihenfolge hintereinander ausgeführt werden.
- Die ausgewählten Funktionen, deren Parameter und Verarbeitungsfolge werden über Profile verwaltet.
- Profilfunktionen: Neu, Kopieren, Löschen, Umbenennen, In Datei exportieren, Aus Datei importieren.
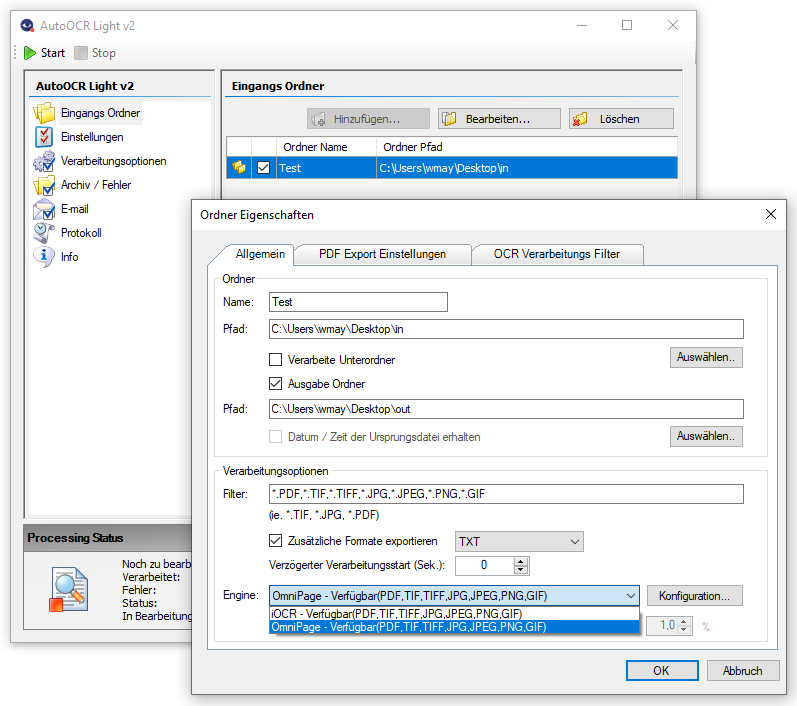
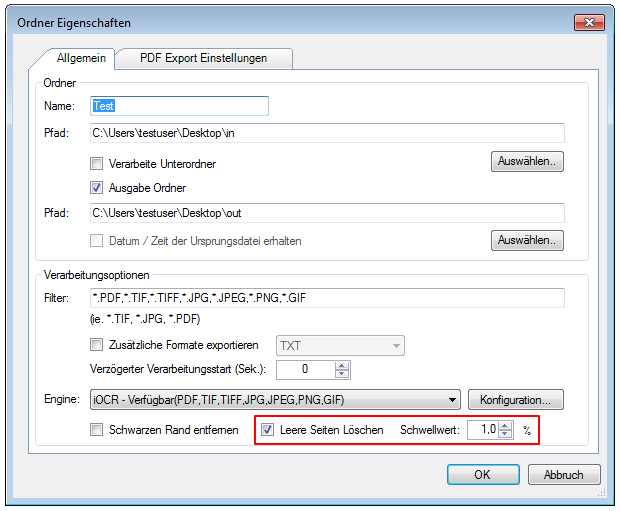
- Option um PDF-Scans / Seiten nur mit Bildinformation bzw. alle PDF Seiten zu verarbeiten.
- Laden einer Musterseite und Test der Bildverarbeitungsbefehle mit Voransicht der Ausgangs- und Ergebnisdatei.
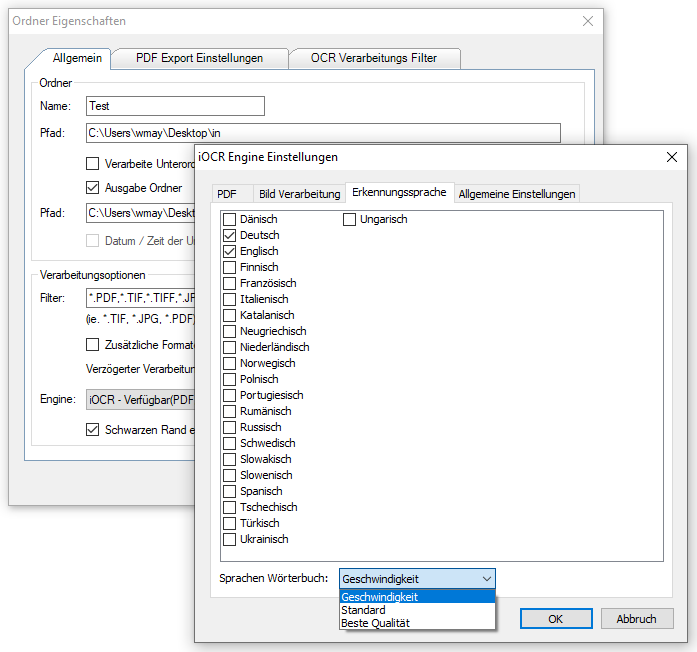
Einzelfunktionen der Bildverarbeitung:
-
- Leerseiten erkennen und entfernen.
- Seiten automatisch drehen
- Seiten gerade ausrichten
- Bilder invertieren (schwarz nach weiß)
- Schwarzen Rand entfernen
- Rand beschneiden
- Verunreinigungen entfernen
- Lochungen entfernen
- Linien entfernen
- Farbe / Graustufen nach Schwarz/Weiß konvertieren
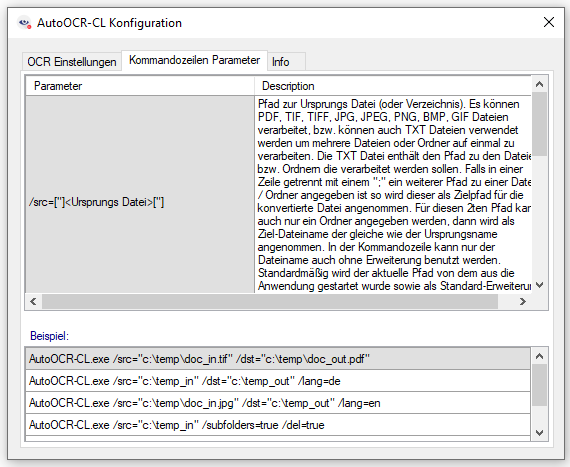
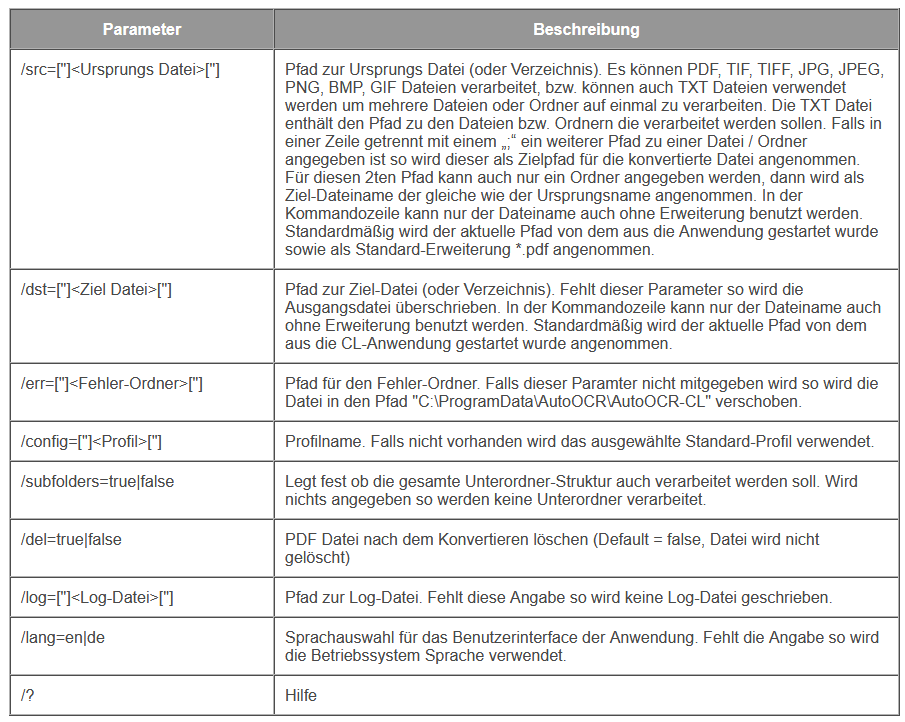
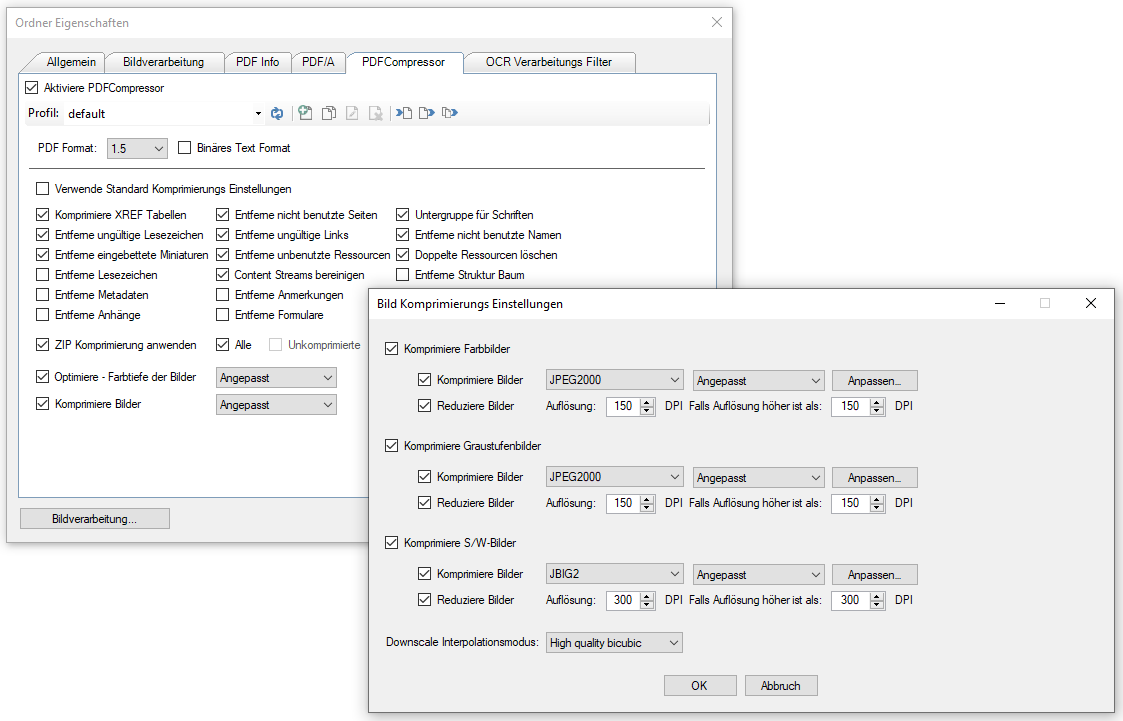
- PDFCompressor integriert: Damit können die durch den OCR Vorgang erzeugten PDF Dateien optimiert und auf ein Minimum komprimiert werden. Als Input für die OCR Verarbeitung sollte immer ein möglichst guter Scan mit entsprechend hoher Qualität und Auflösung (300dpi bei Schwarz/Weiß und 200-300dpi Farbe) verwendet werden. Das ist gut für die OCR Erkennung, erzeugt aber große Ergebnisdateien. Um im Endergebnis nach der OCR Verarbeitung möglichst kleine PDF Dateien zu erzeugen kann die PDFCompressor Verarbeitung dem OCR Vorgang nachgelagert werden um z.b. die Auflösung der Bilder auf z.b. 150dpi zu verringern. Damit kann eine gute OCR Erkennung bei möglichst kleinen Ausgabedateien erreicht werden. 150dpi bietet ausreichende Lesbarkeit, wäre aber für die OCR Erkennung zu gering. Der PDFCompressor ist für AutoOCR als Option verfügbar.
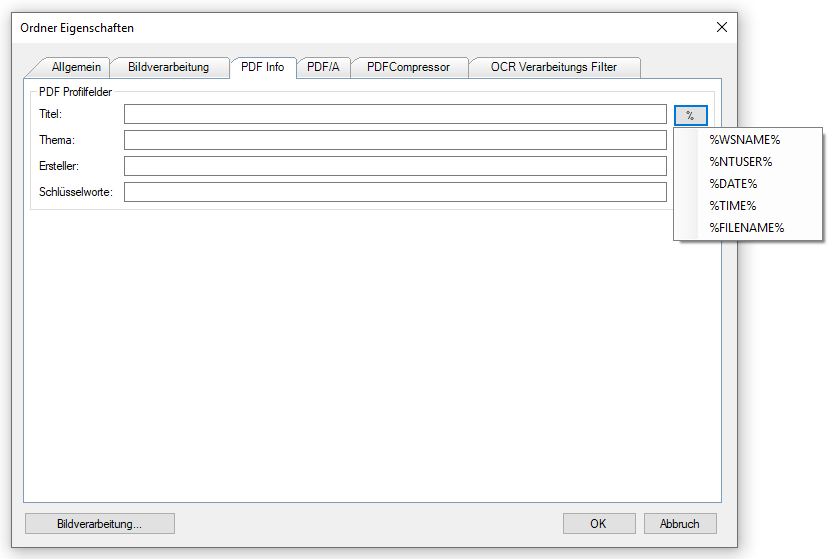
- PDF Infofelder: Die PDF Infofelder stehen jetzt auch unabhängig von der PDF/A Funktion über einen eigenen Tab in allen AutoOCR Varianten zur Verfügung.
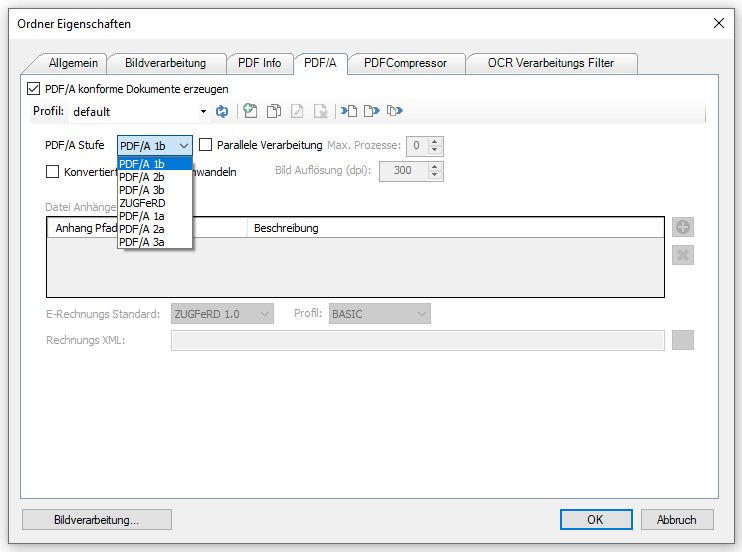
- PDF2PDFA Konverter Komponente integriert: Damit stehen alle Funktionen der PDF2PDFA Konverter Komponente in AutoOCR zur Verfügung.
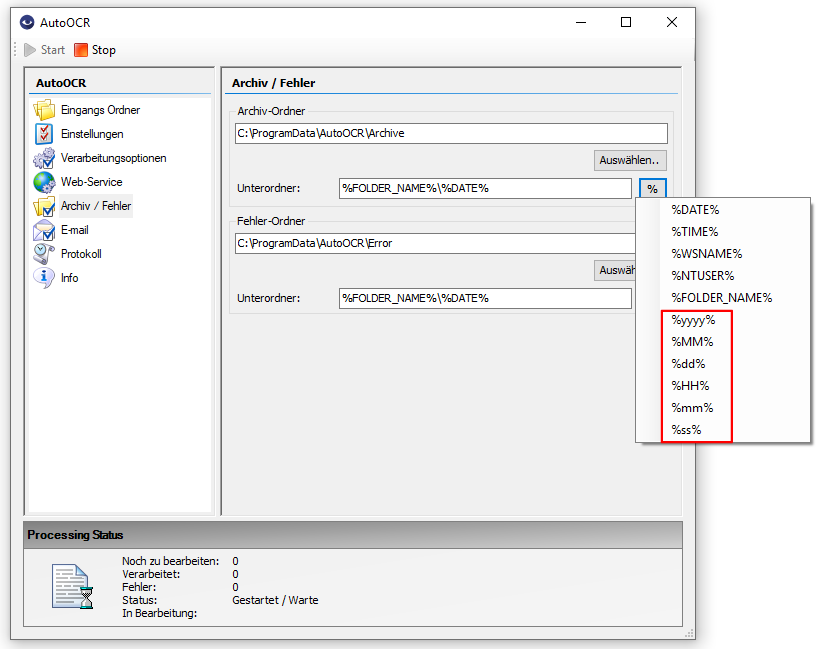
- Archiv-Ordner Konfiguration: Für die Archiv-Ordnerkonfiguration stehen neue Variablen für Datum und Zeit zur Verfügung.
Download – AutoOCRLight – Low Cost OCR Server (ca. 410MB) >>>
Download – AutoOCR – OCR Server inkl. OmniPage OCR (ca. 640MB) >>>