AutoOCR – Barcode Erkennung über Scripting
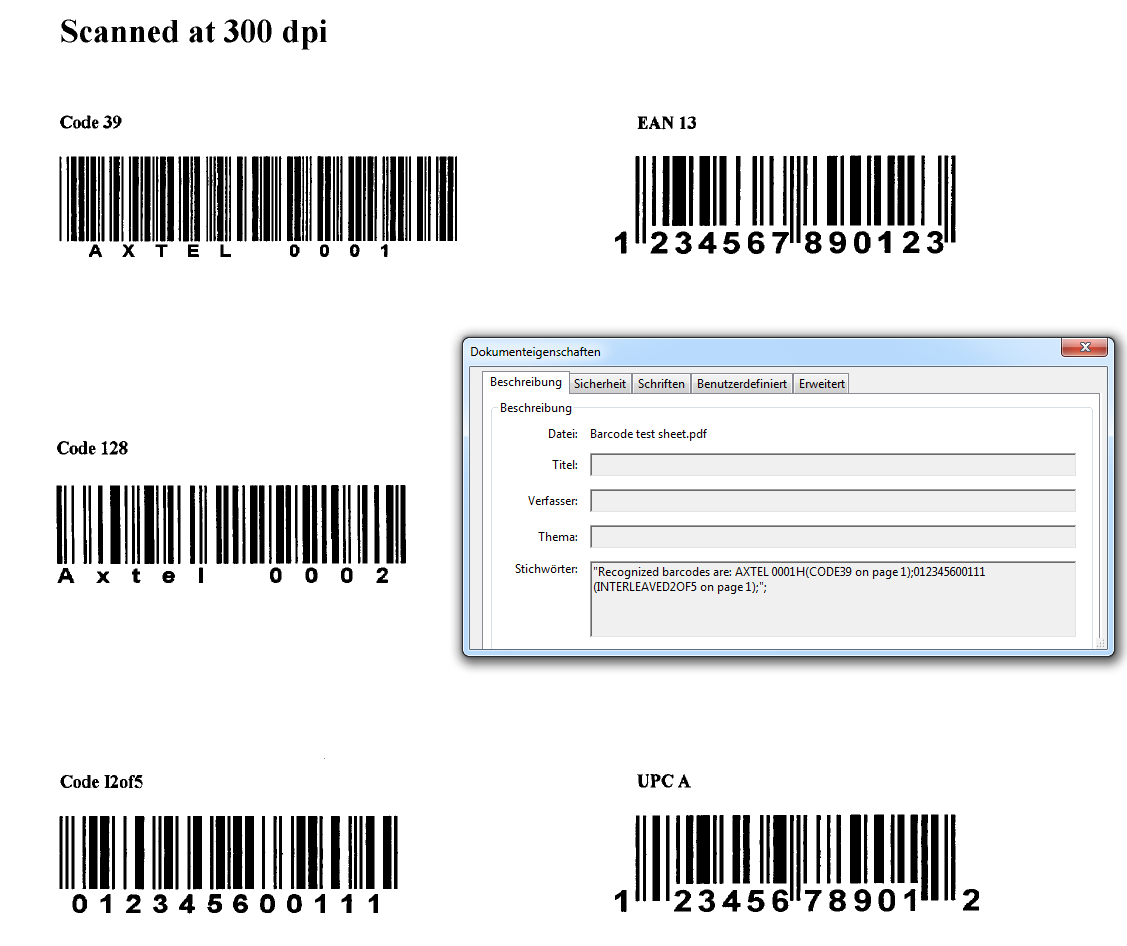
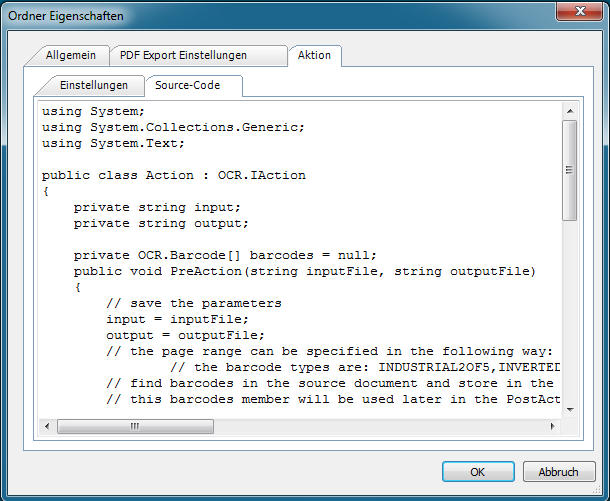
Über die Scripting Funktion von AutoOCR ist es jetzt auch möglich zusätzlich zur OCR Verarbeitung auch eine Barcode Erkennung der verarbeiteten Dokumente durchzuführen. Die erkannten Barcodes können auch in die Felder der PDF Dokumenteninformation geschrieben werden um die Daten direkt weiterzugeben und später wieder auszulesen.
Funktionen AutoOCR Barcode Scripting Add-On:
- 1D – Barcoderkennung folgender Typen: INDUSTRIAL2OF5, INVERTED2OF5, INTERLEAVED2OF5, IATA2OF5, MATRIX2OF5, CODE39, CODABAR, BDCMATRIX, DATALOGIC2OF5, CODE128, EAN128, CODE93, EAN13, UPCA, EAN8, UPCE, ADD5, ADD2
- Barcode Erkennung unabhängig von der Orientierung auf der Seite
- Festlegung auf welchen Seiten die Erkennung erfolgen soll – Einzelseite, Von-bis, Liste, sowie Kombination dieser Angaben.
- Schreiben z.b. von Barcode Type, Barcode Wert, Seitenummer in die PDF Dokumenteninfo Felder – Title , Subject, Author, Keywords
- Weitere verfügbare Barcode Informationen: Koordinaten – Links/Oben, Breite, Höhe
- Verfügbar als AutoOCR Scripting Funktion inkl C# Beispielscript