pdfFM – PDF Folder Merge – Convert documents with the same name to a total PDF (/A)
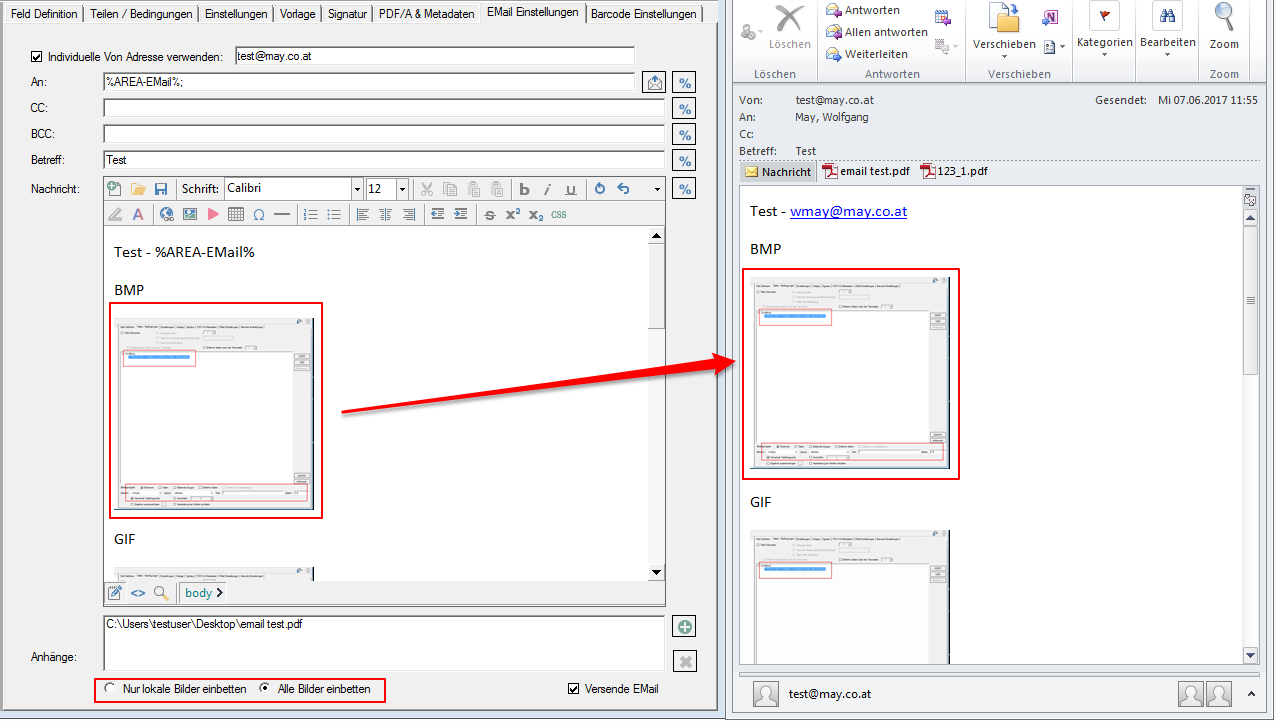
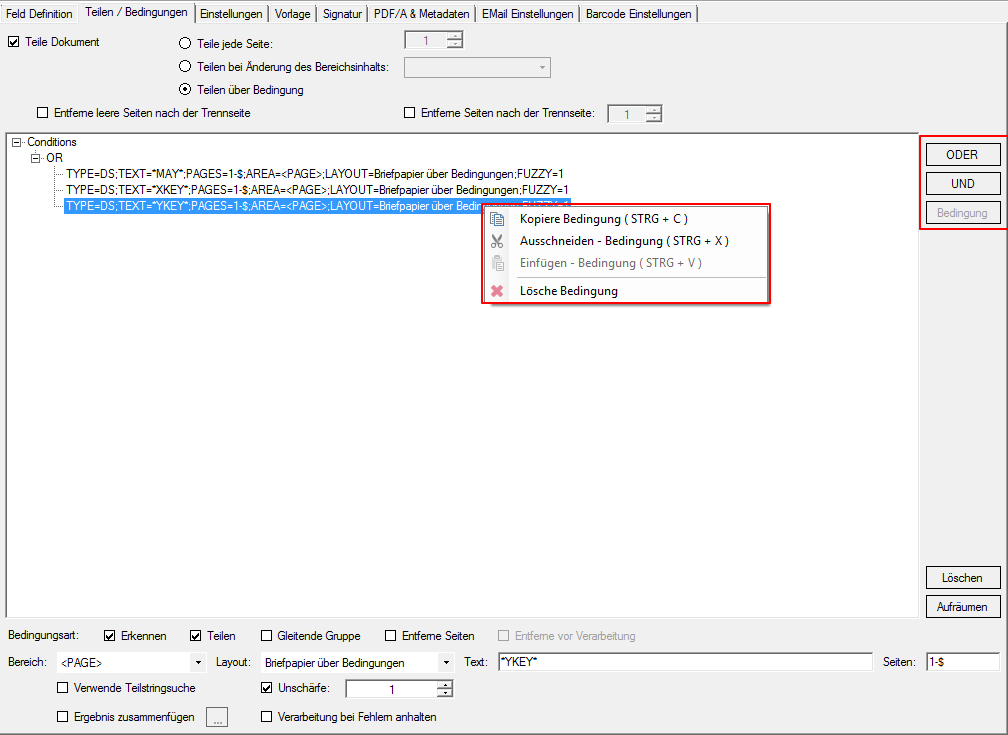
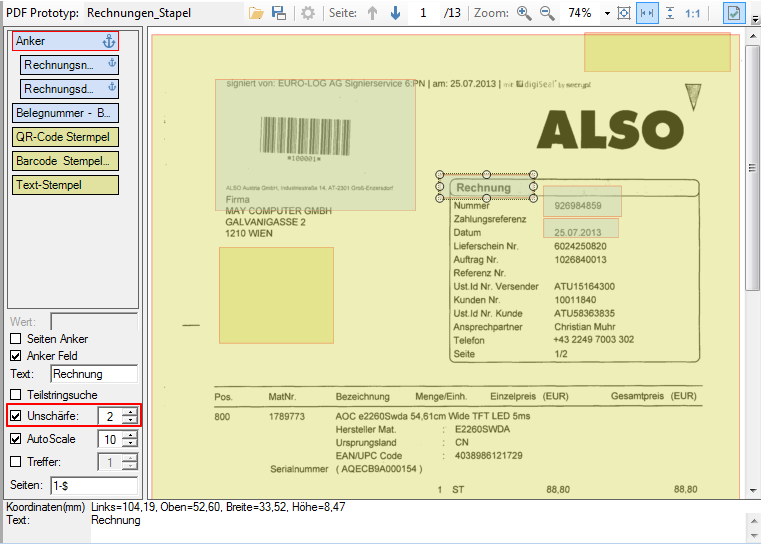
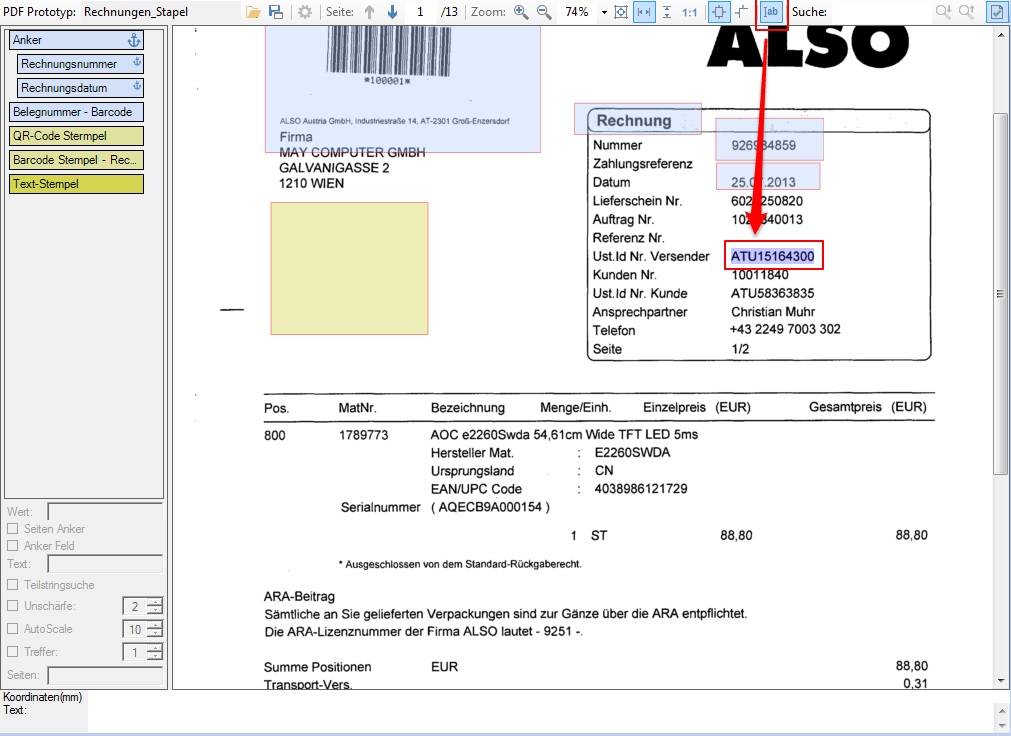
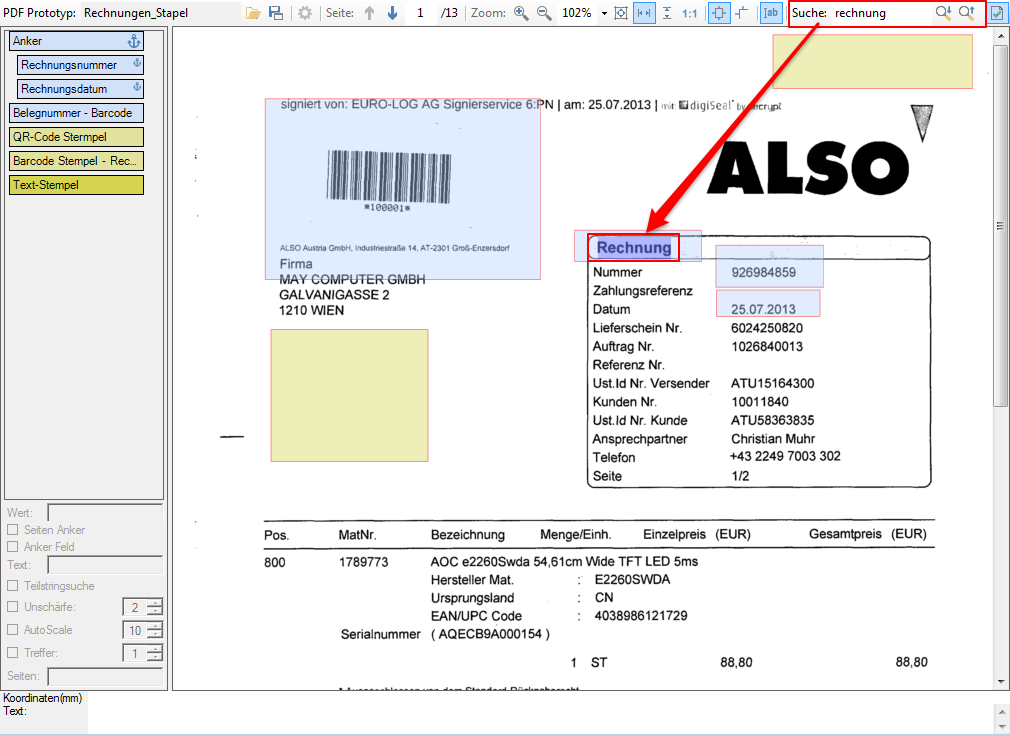
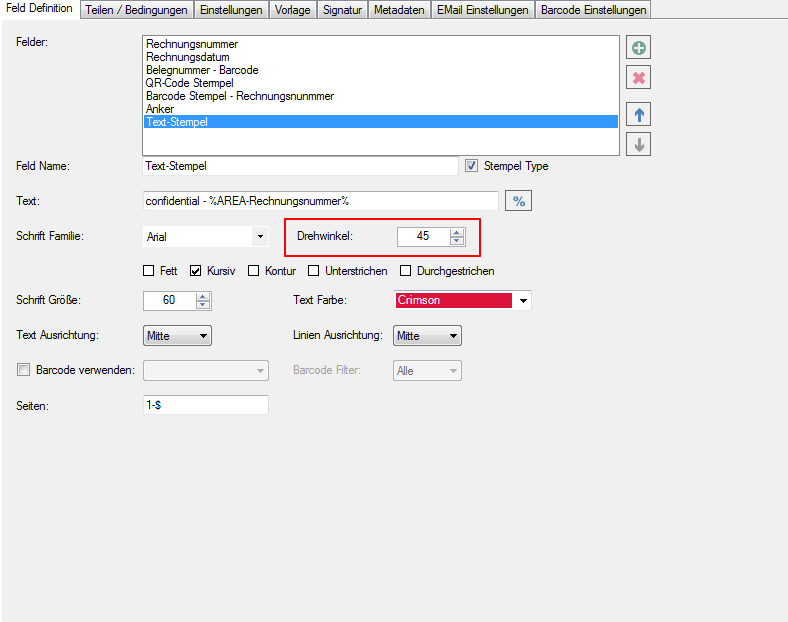
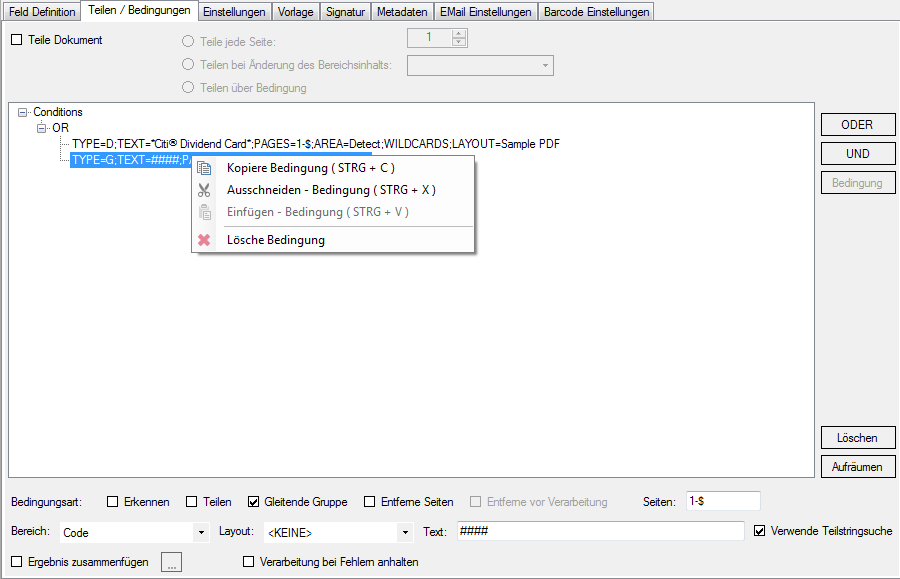
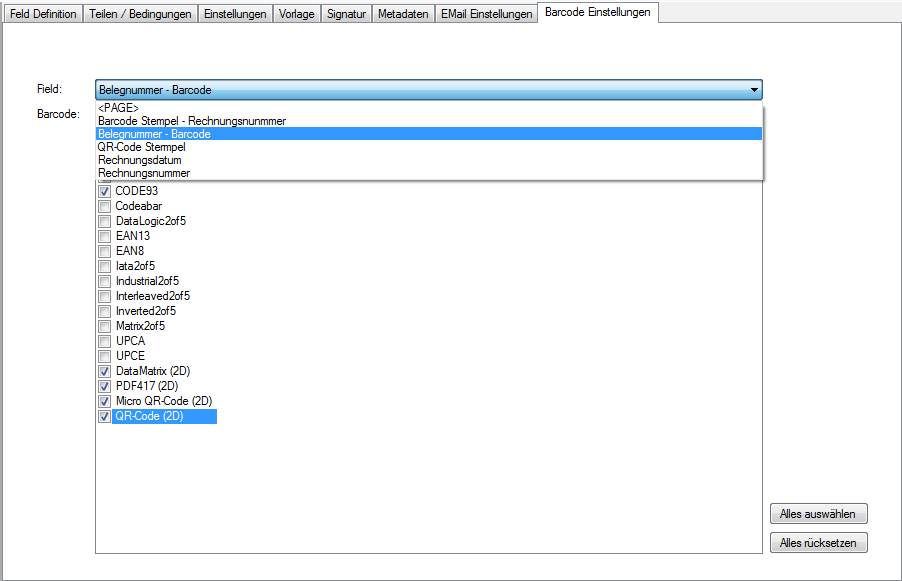
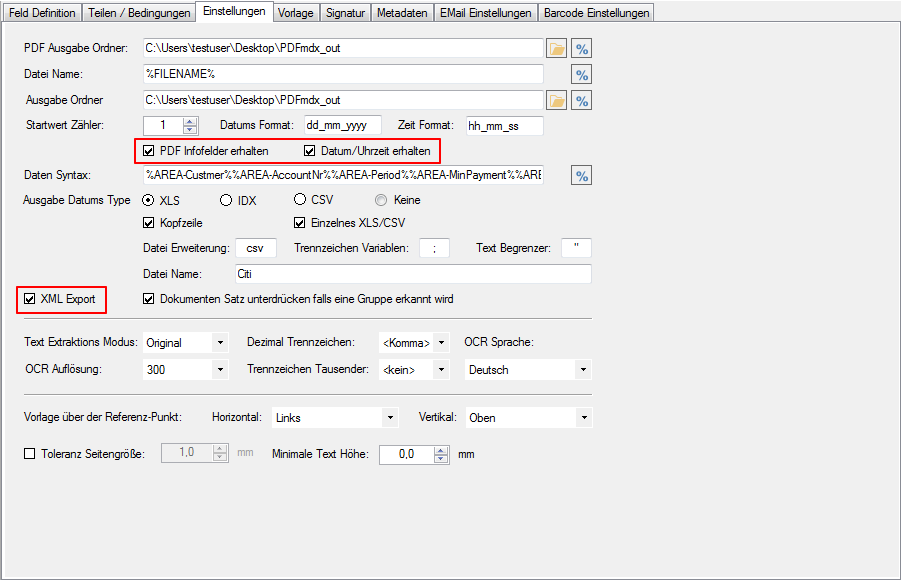
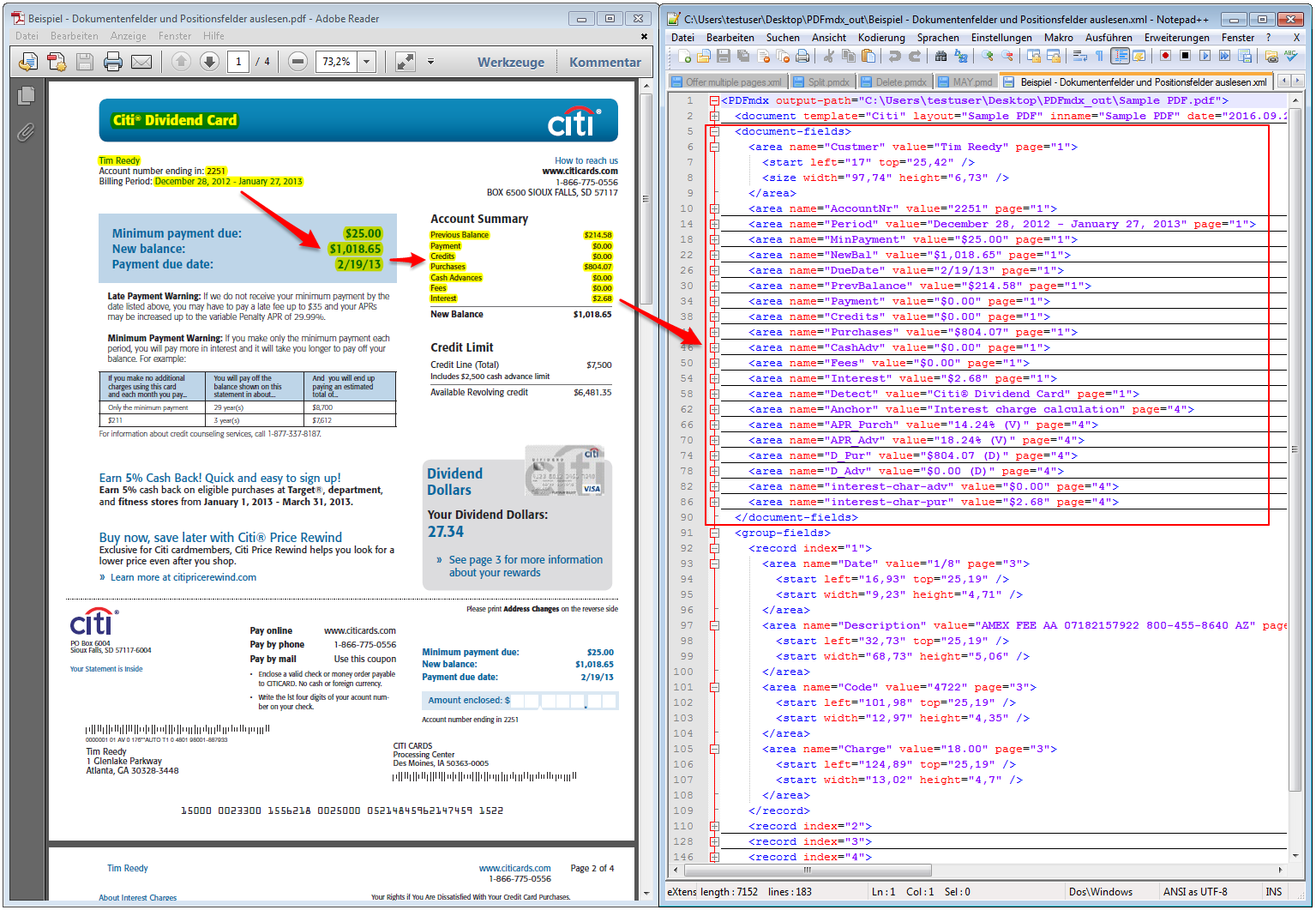
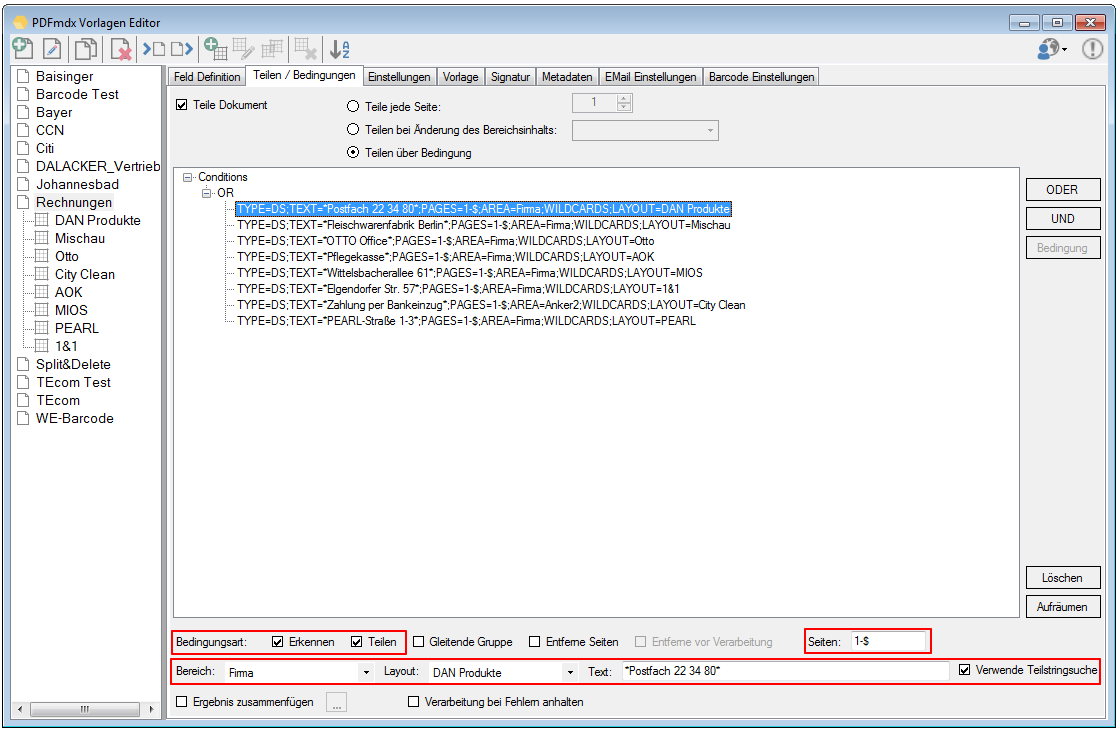
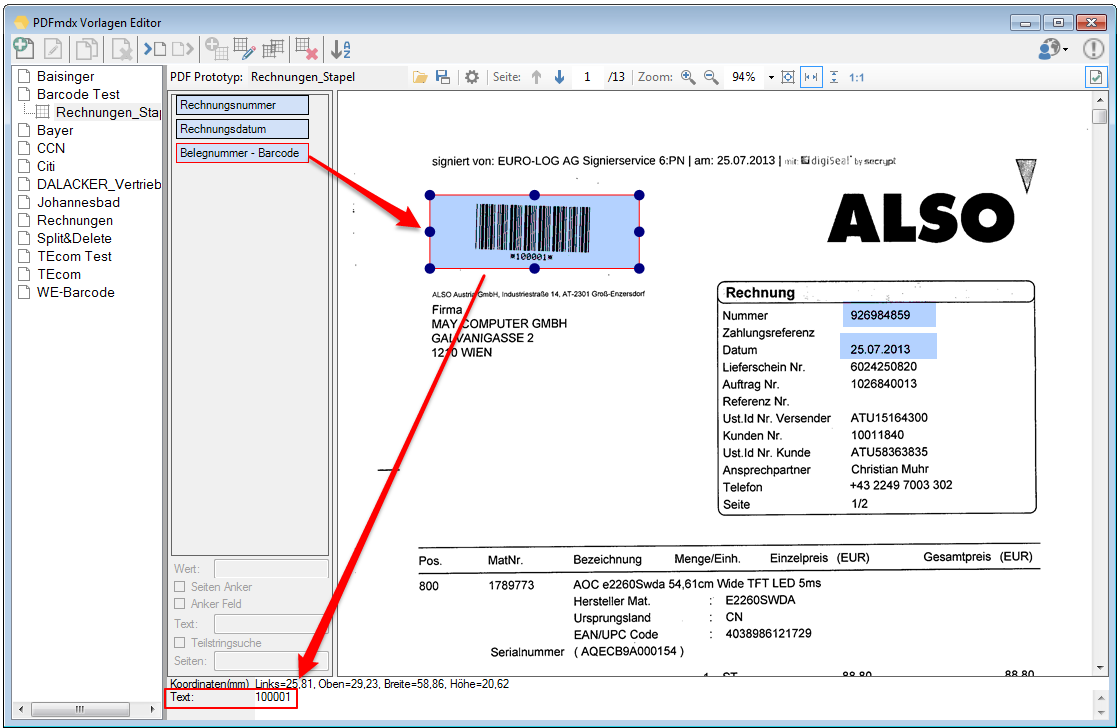
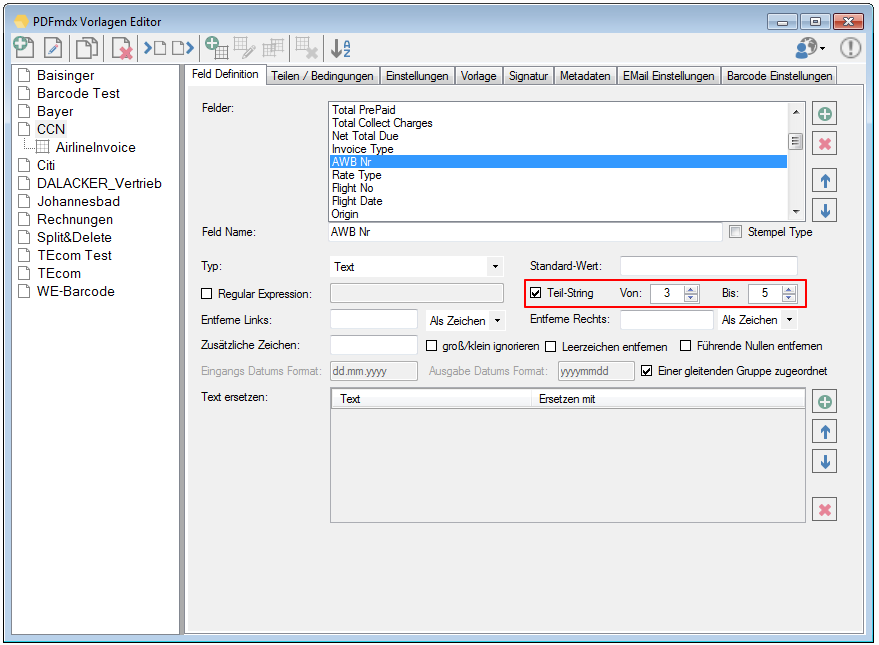
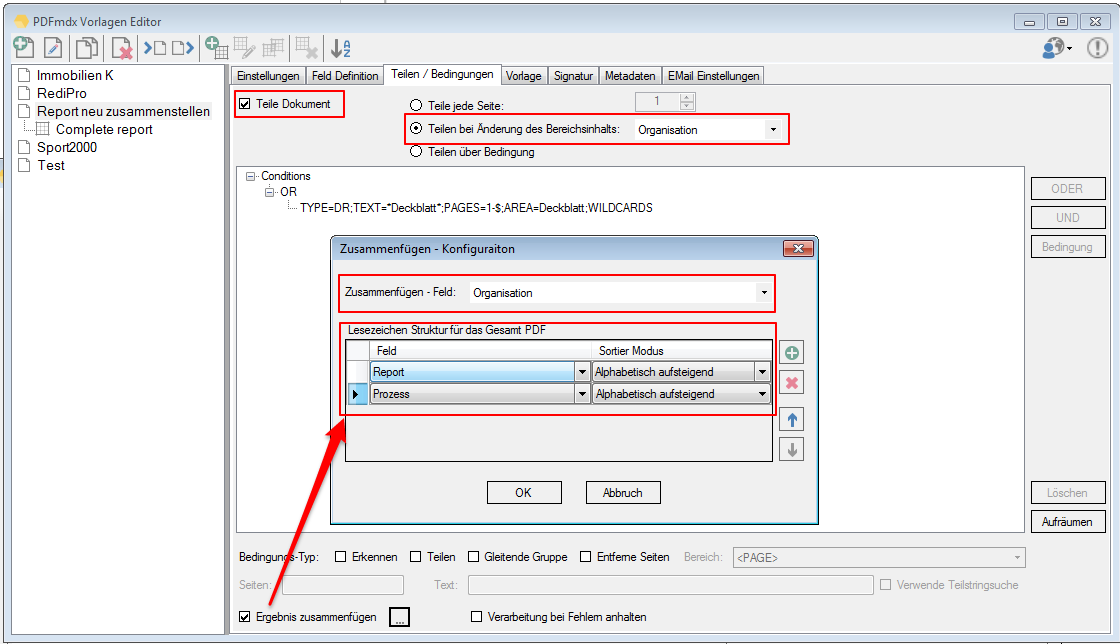
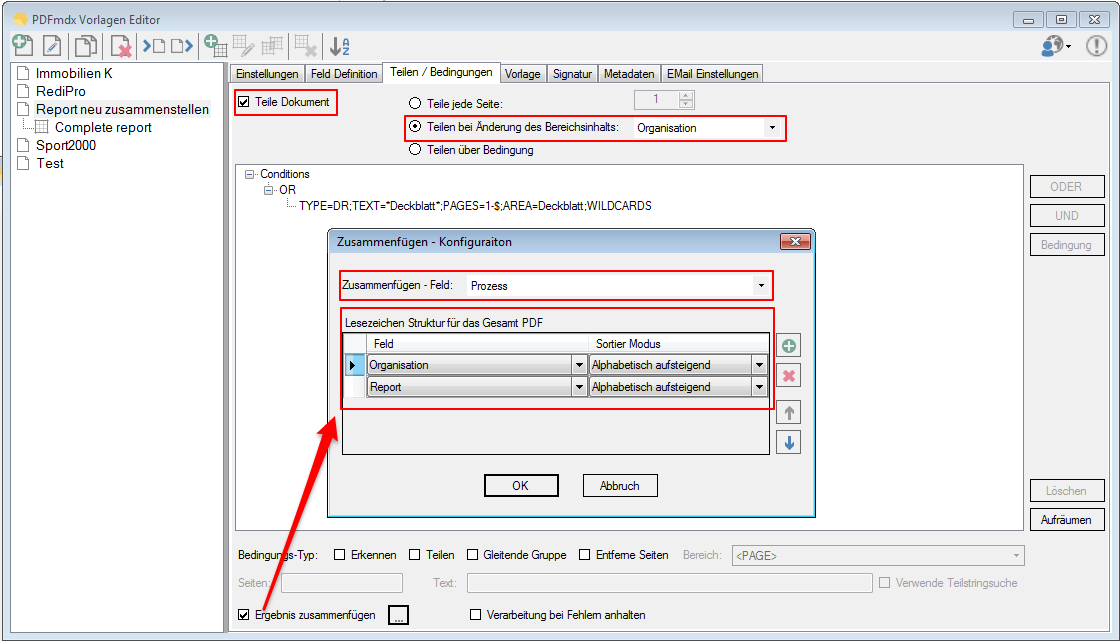
With PDFmdx, document stacks can be easily split into single documents according to the most diverse criteria and named range contents can be named. Sometimes, however, it may also be necessary to automatically create documents with the same name from different sources in a certain sequence automatically into an overall document.
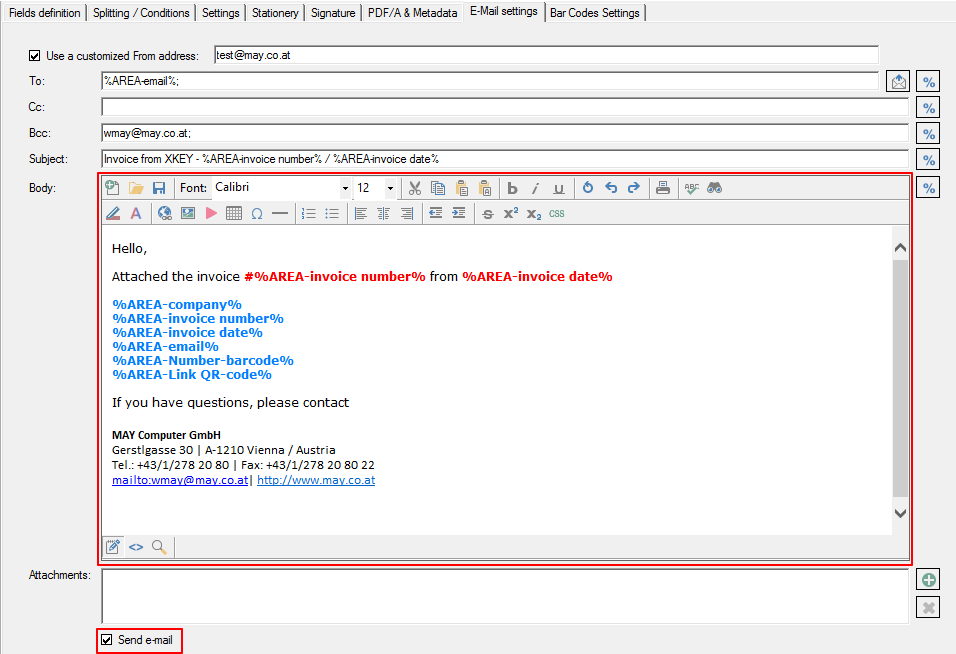
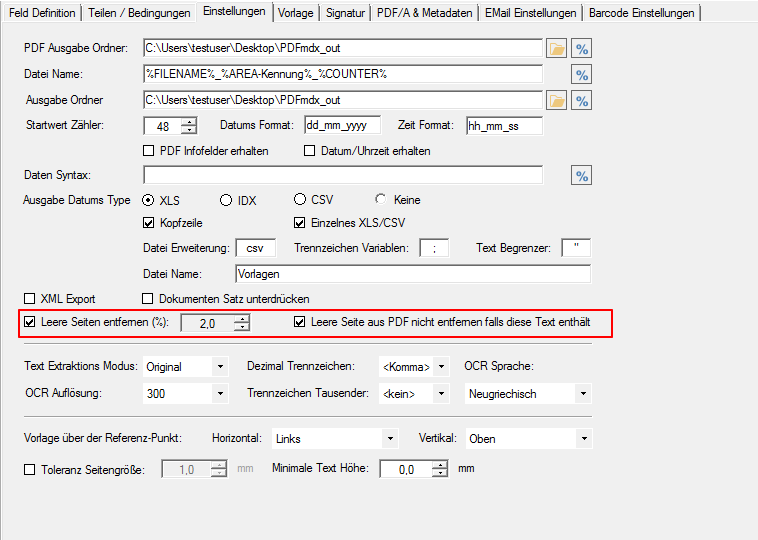
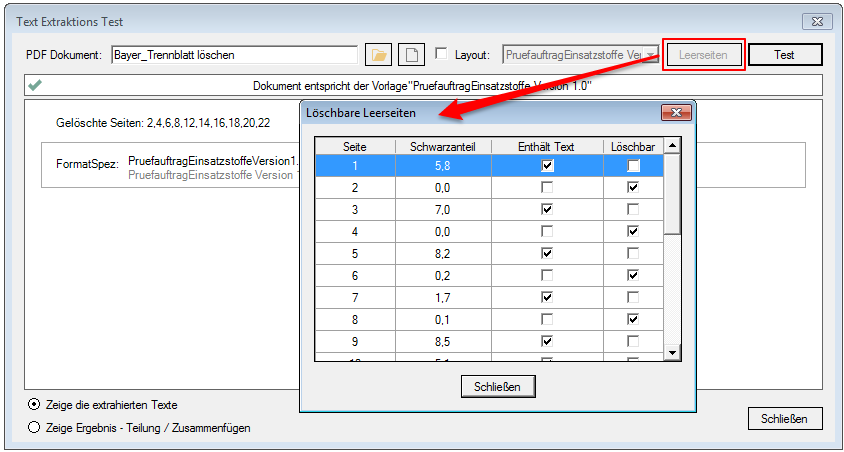
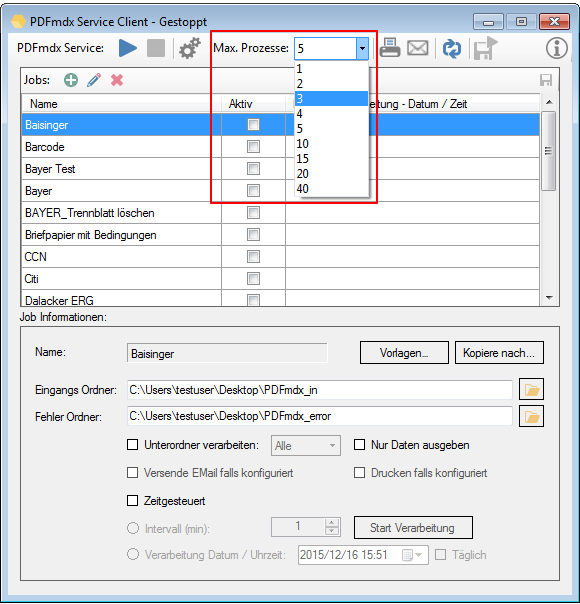
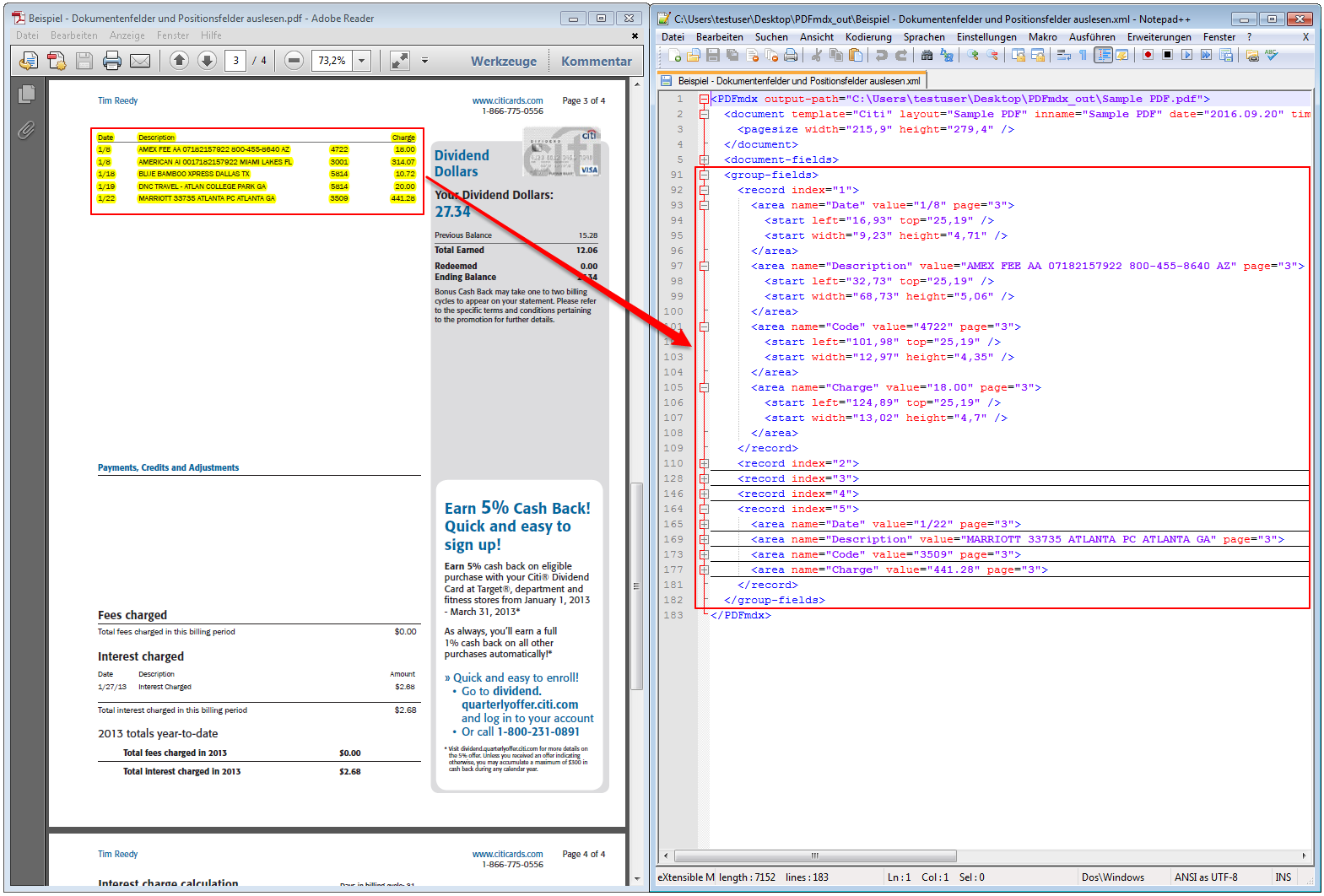
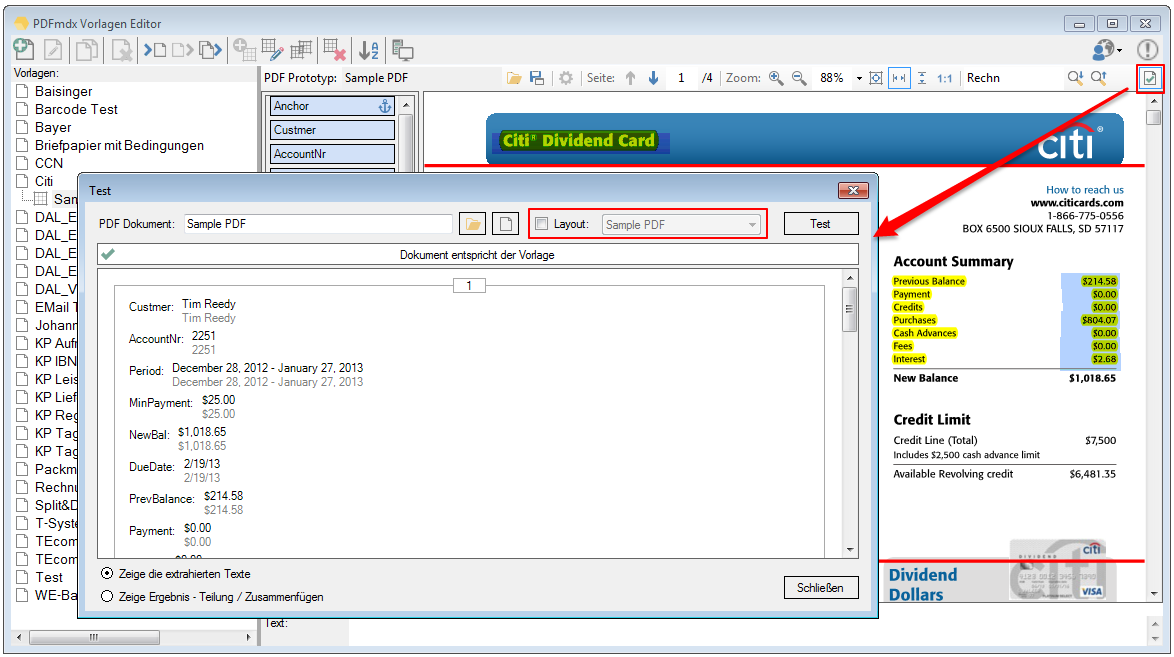
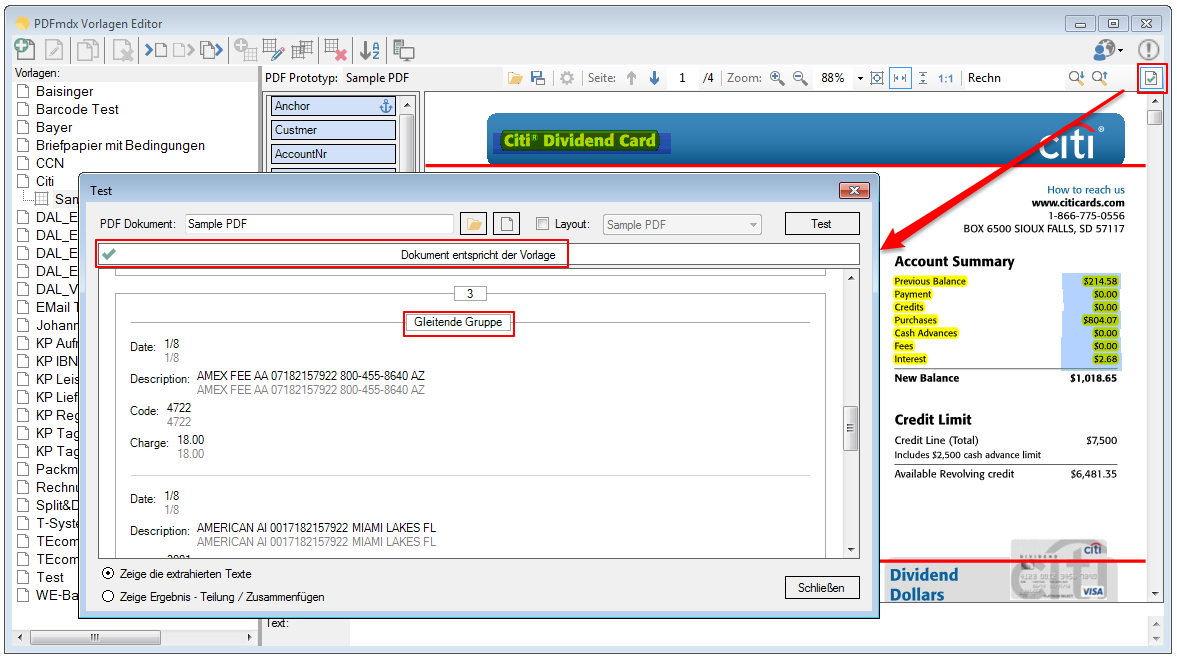
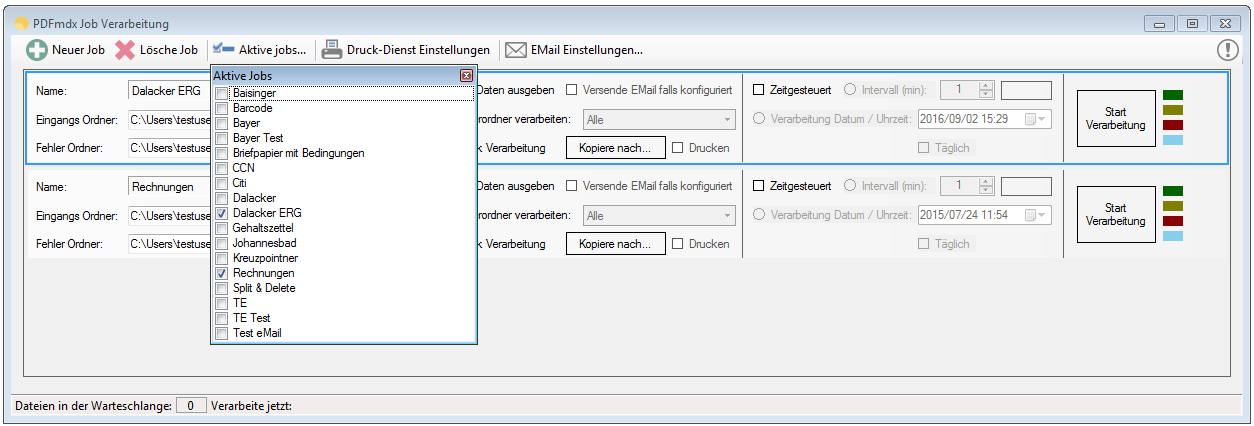
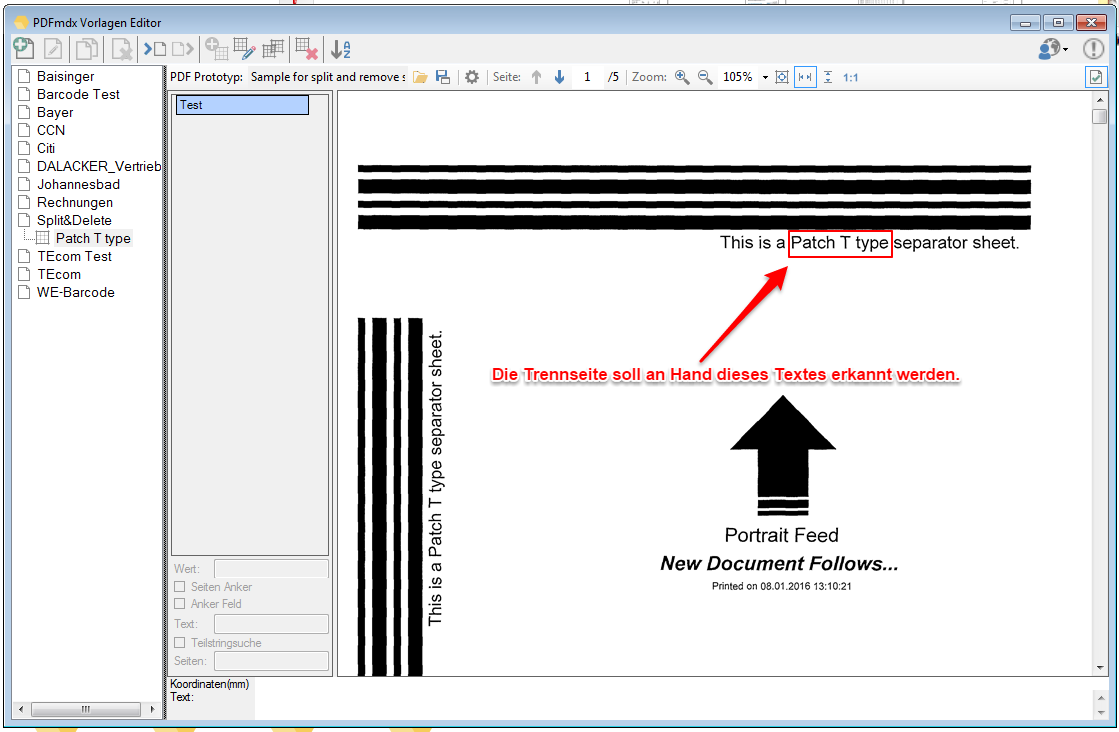
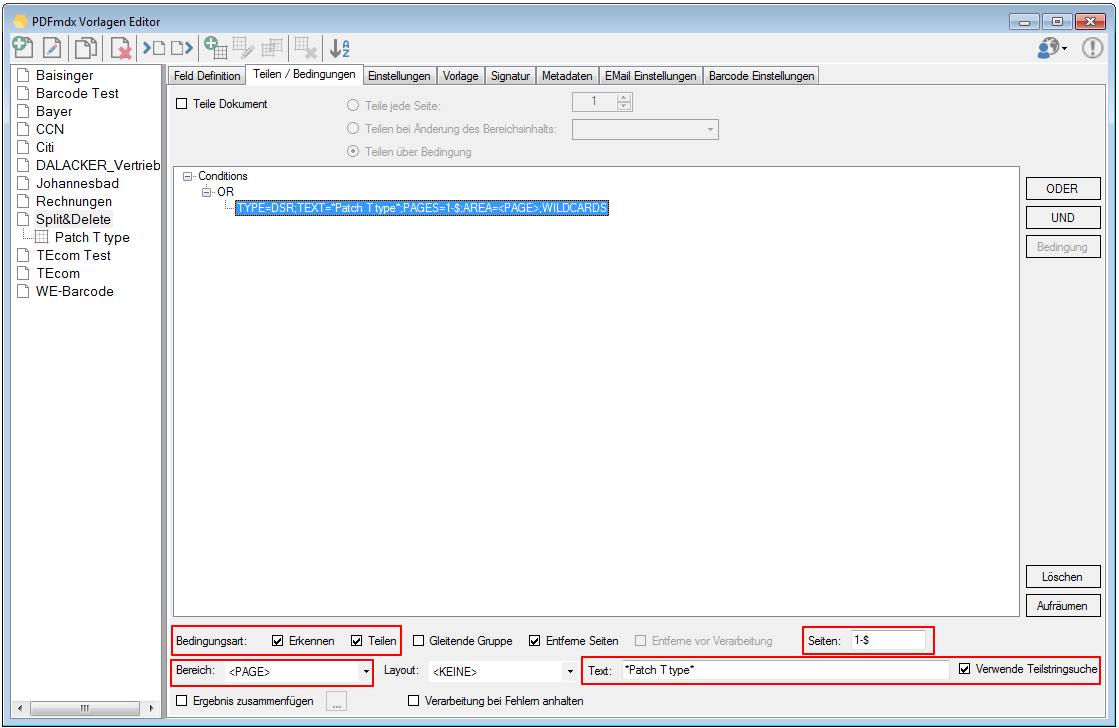
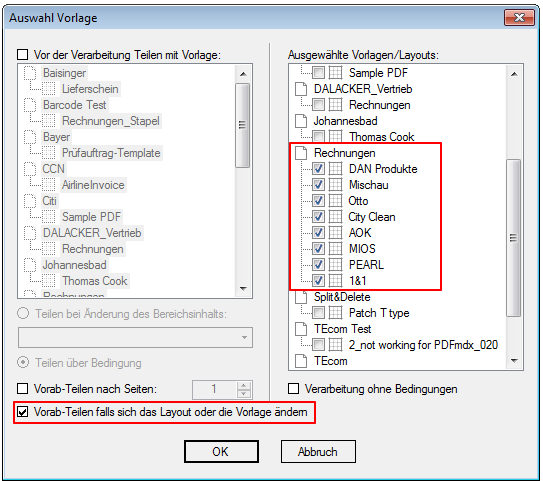
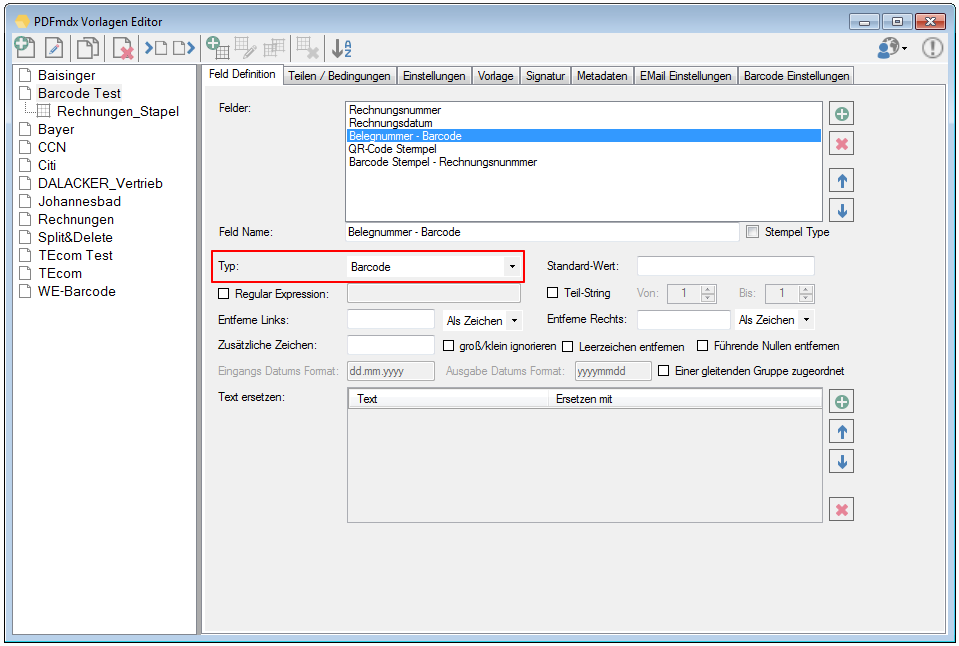
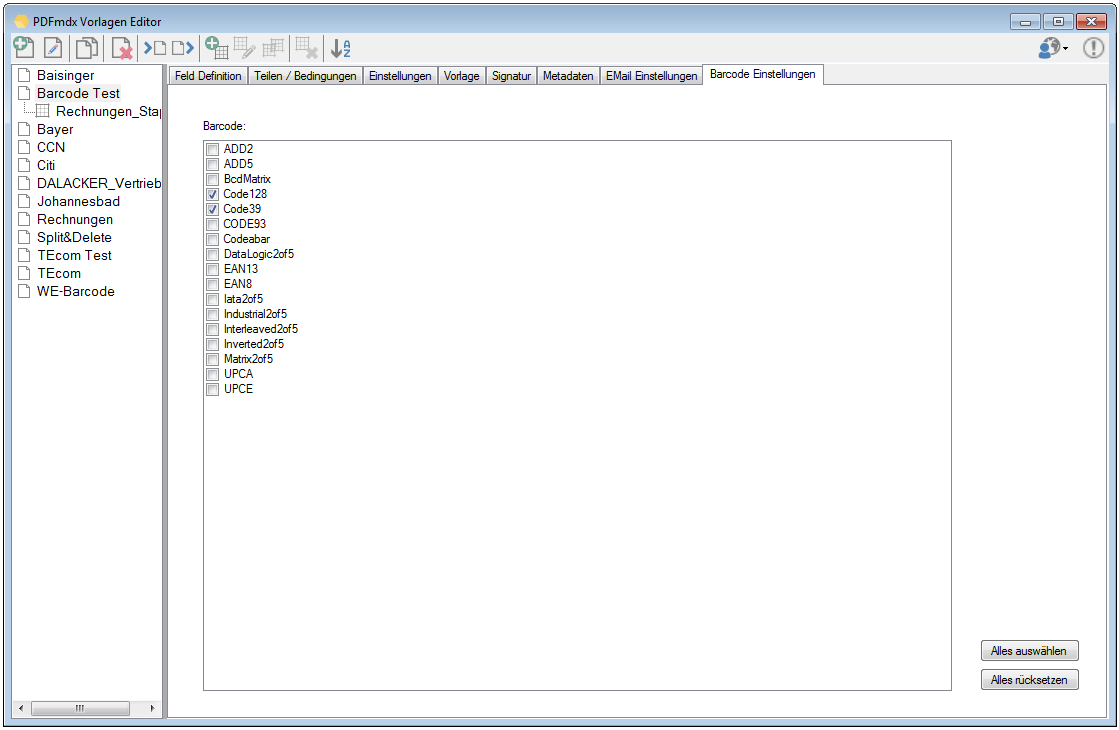
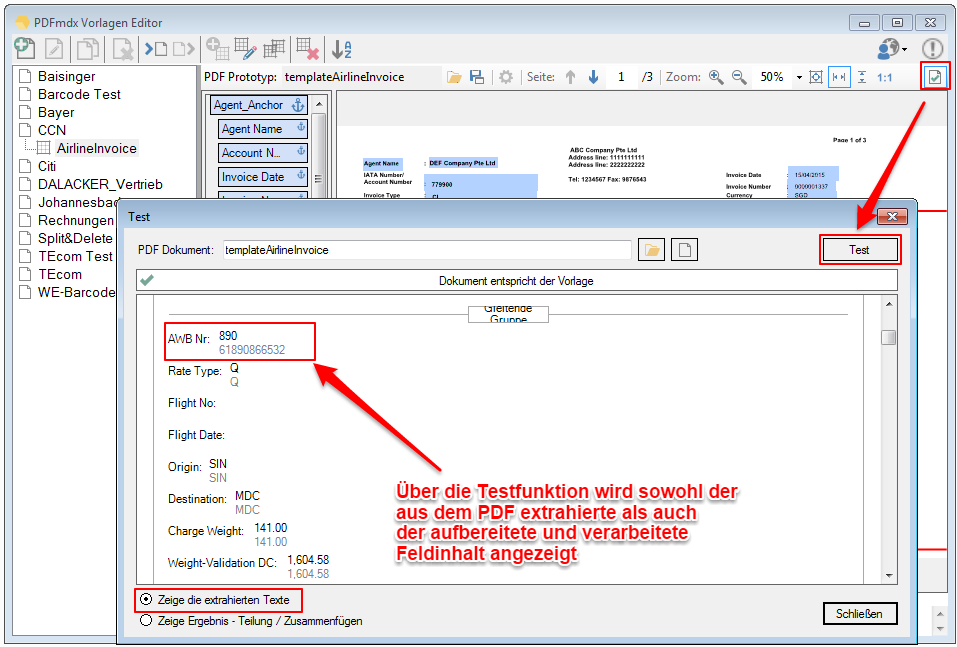
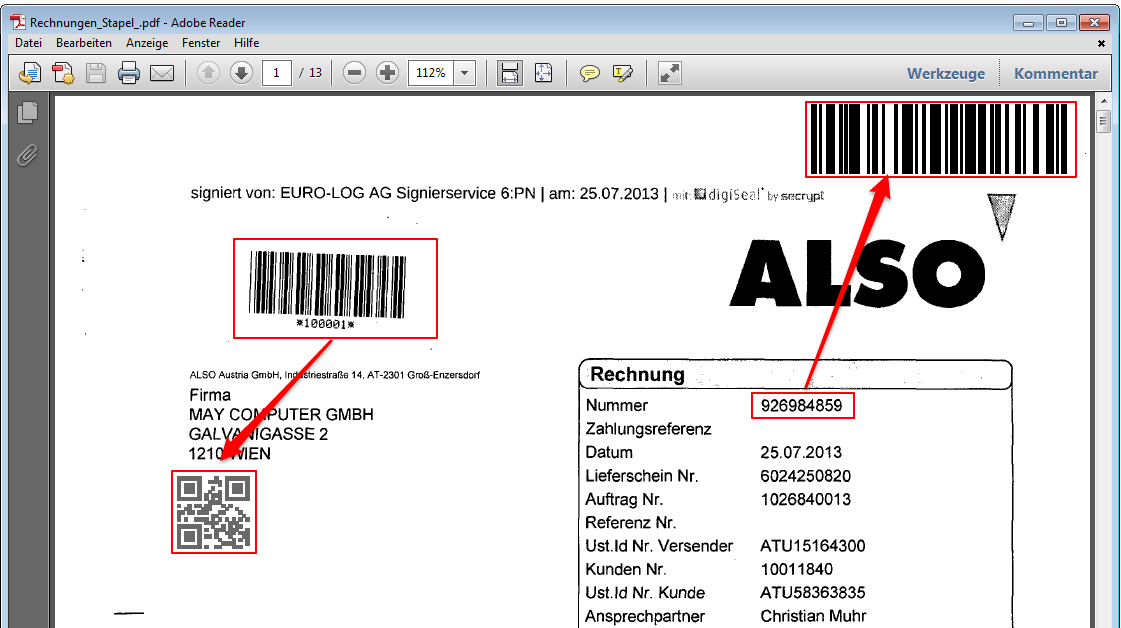
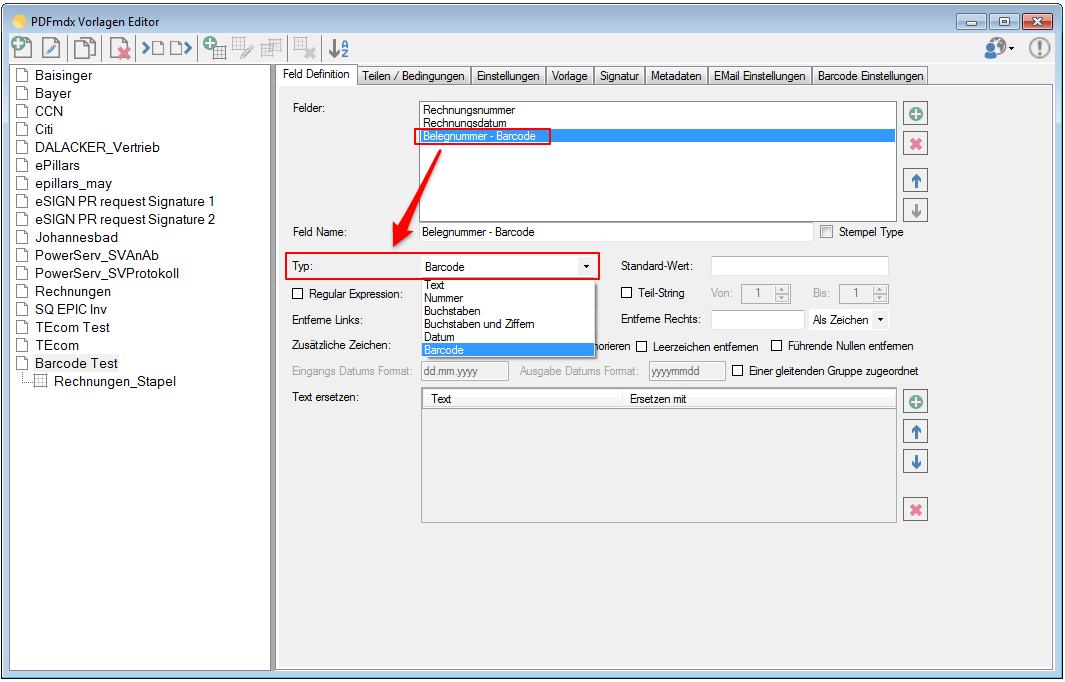
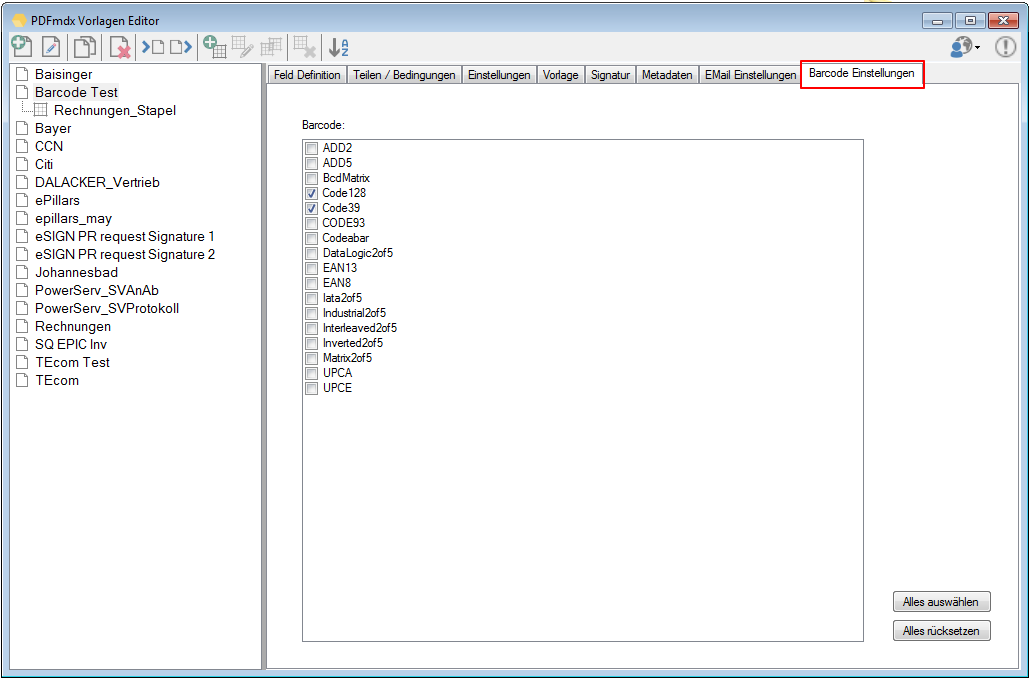
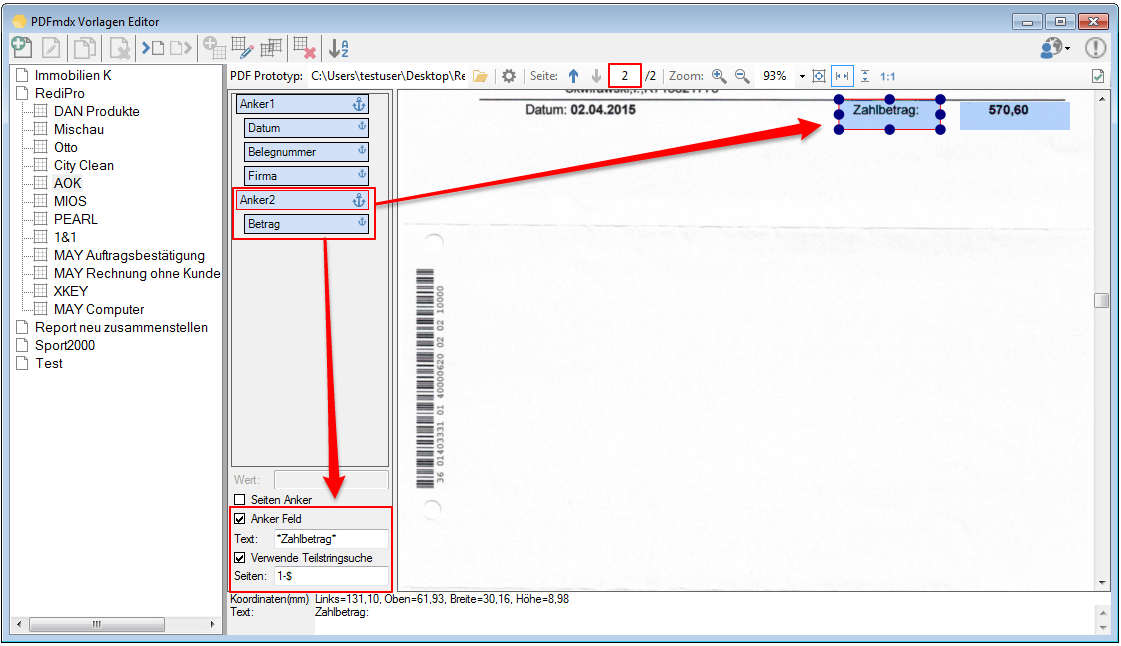
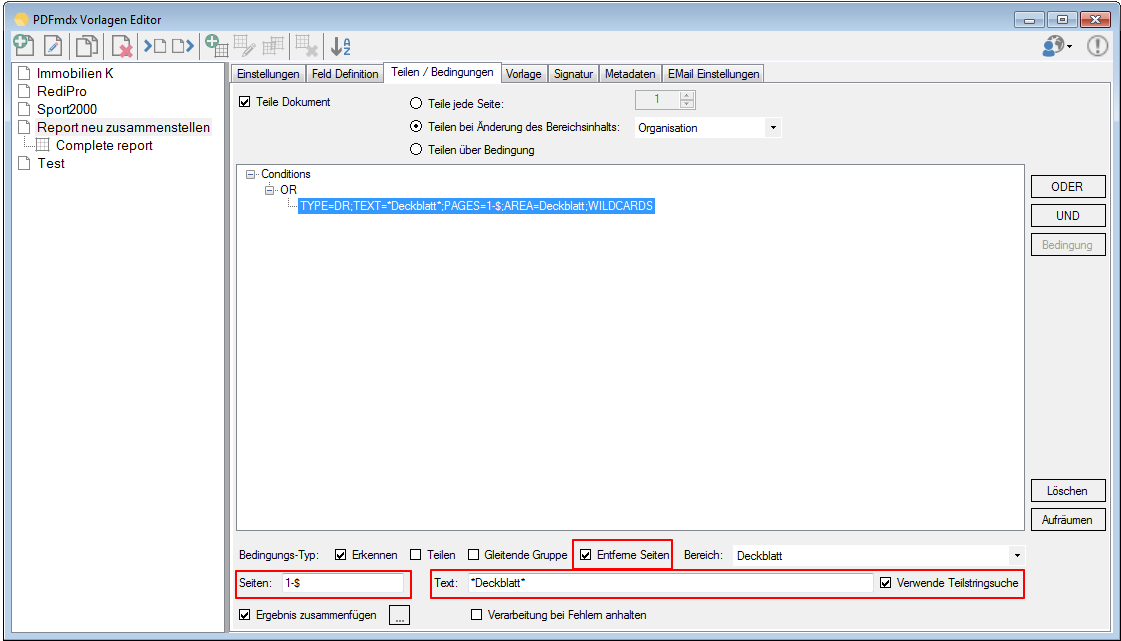
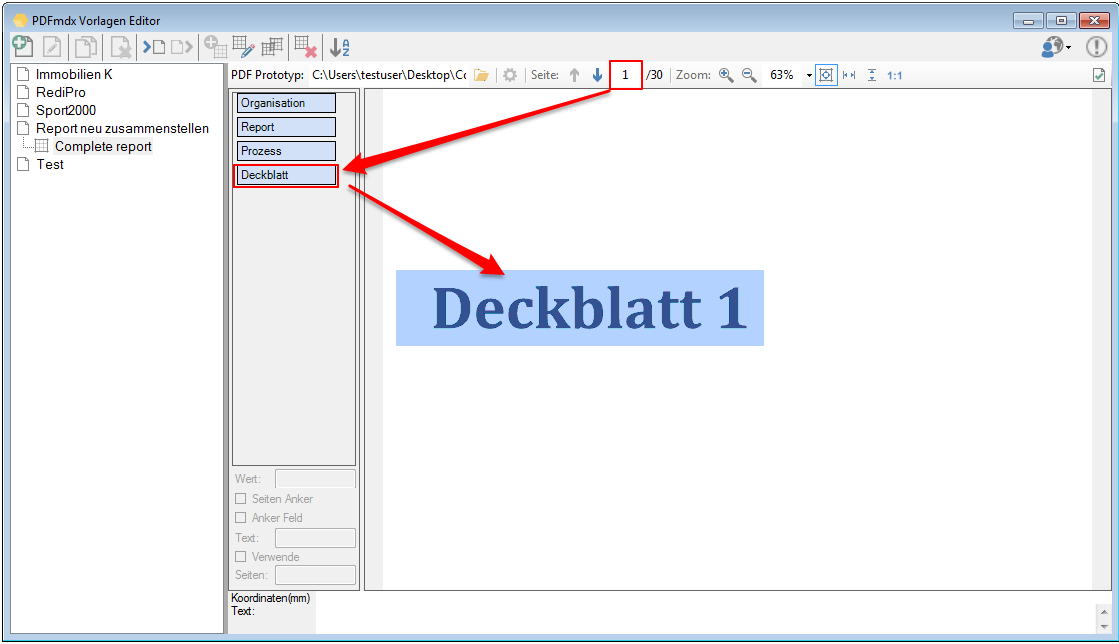
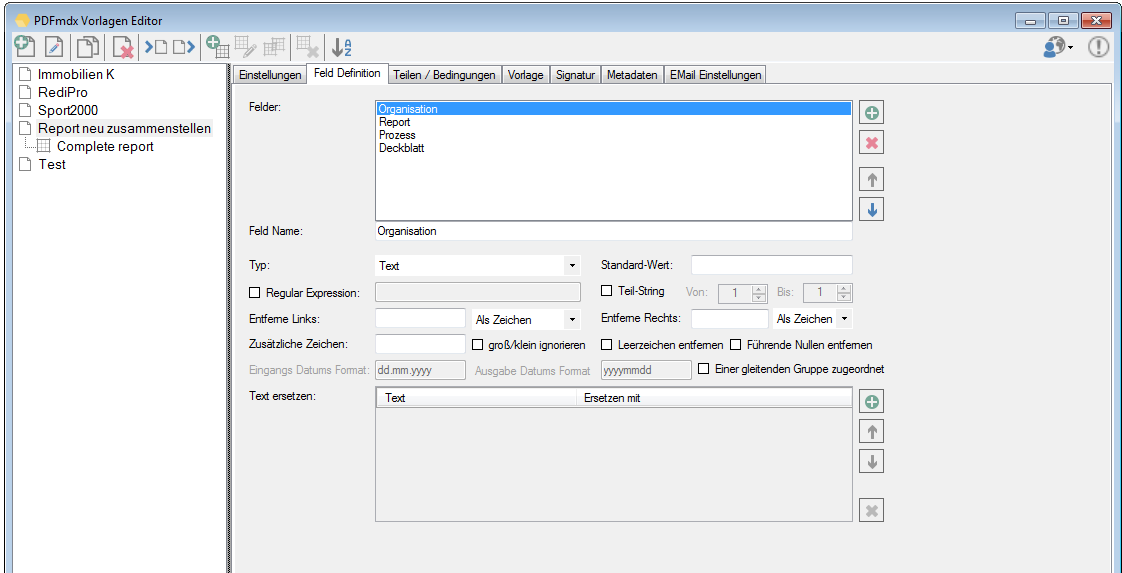
For a customer project, we have developed pdfFM – an application where 3 folders are specified. When processing, the folders are searched for documents with the same name, the same documents are added to a new total PDF in the order of the specified folders and stored in a destination folder. If a file is missing in one of the folders, these documents are moved to the error folder. A log file logs the processing. The processing can be executed either interactively or via command line call.
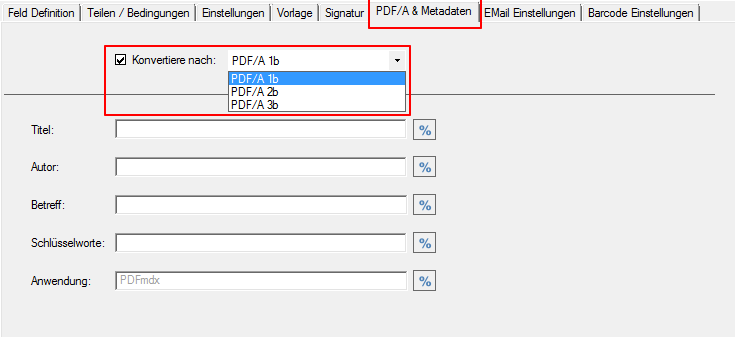
In addition to the merge to an overall PDF, the output file can also be converted to an ISO PDF / A-1b, 2b or 3b file.