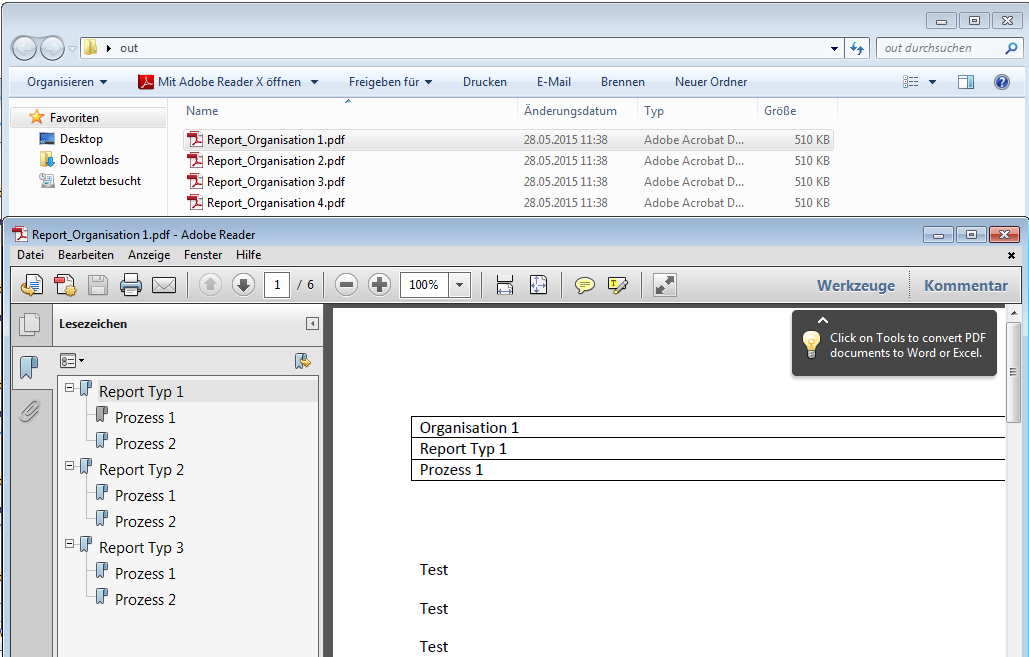
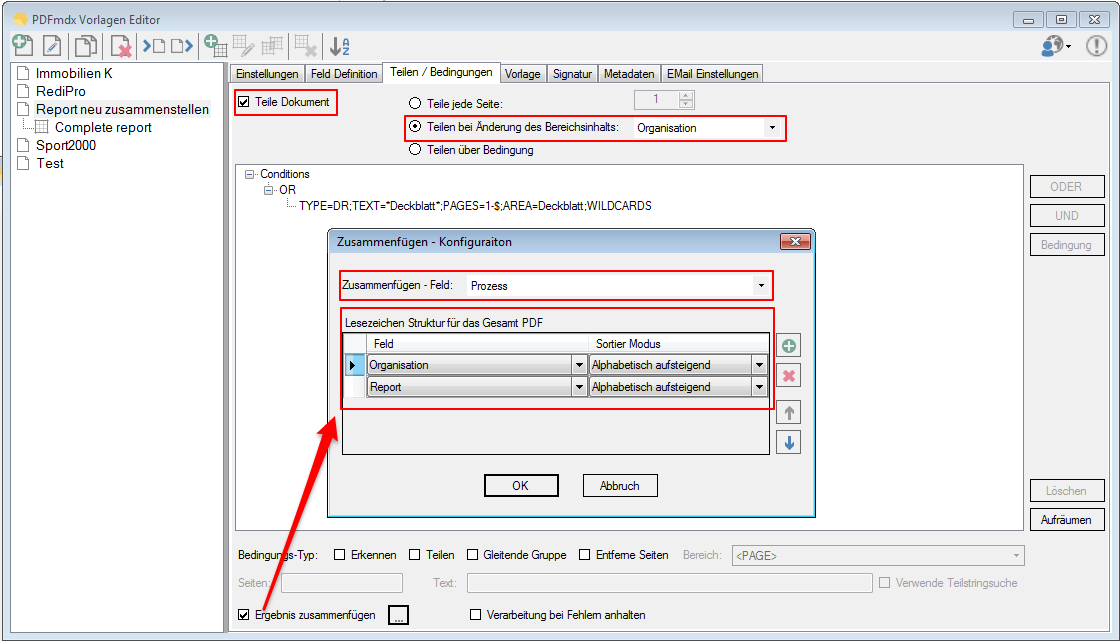
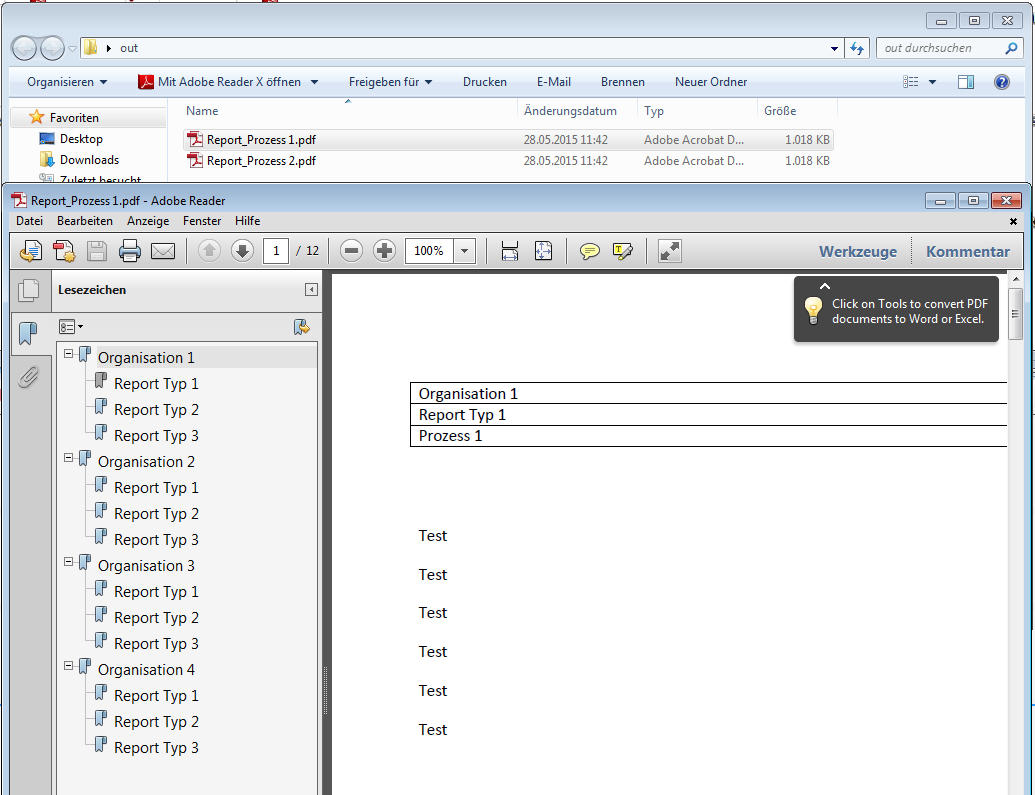
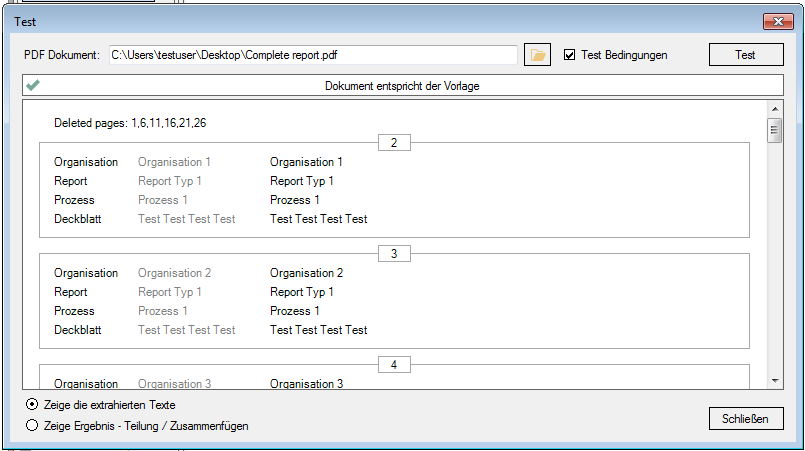
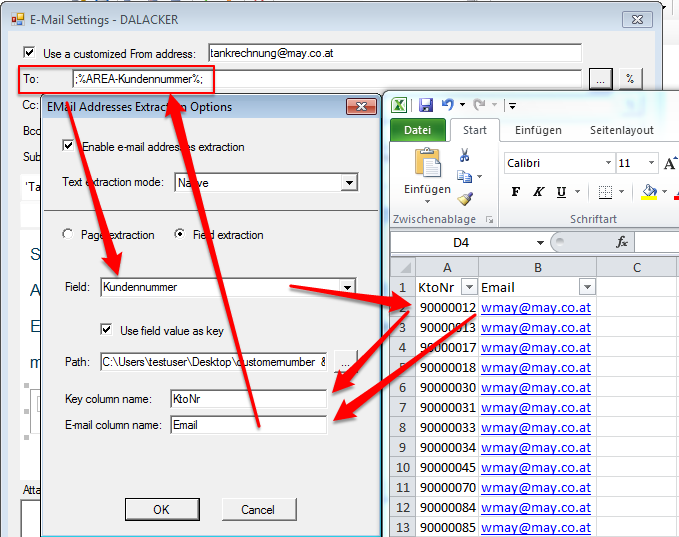
PDFmdx – Version 2.4.3 – Barcode Erkennung & verbesserte Anker / Suchfeldfunktion
Neuerungen Version 2.4.3:
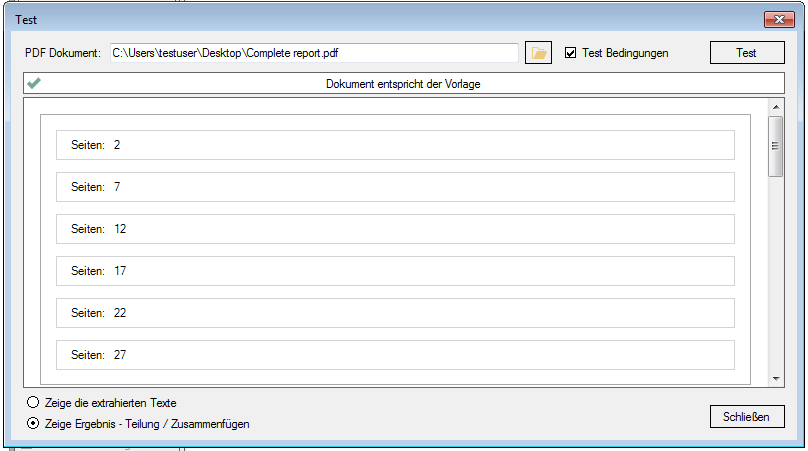
Feld-Typ – Barcode: Mit dem neuen Feldtyp Barcode ist es jetzt auch möglich Felder (Bereiche) als Typ „Barcode“ zu definieren. Aus dem festgelegten Bereich wird nicht der Text ausgelesen sondern eine 1D-Barcode Erkennung nach dem ausgewählten Barcode Typ durchgeführt und der erkannte Wert zurückgeliefert.
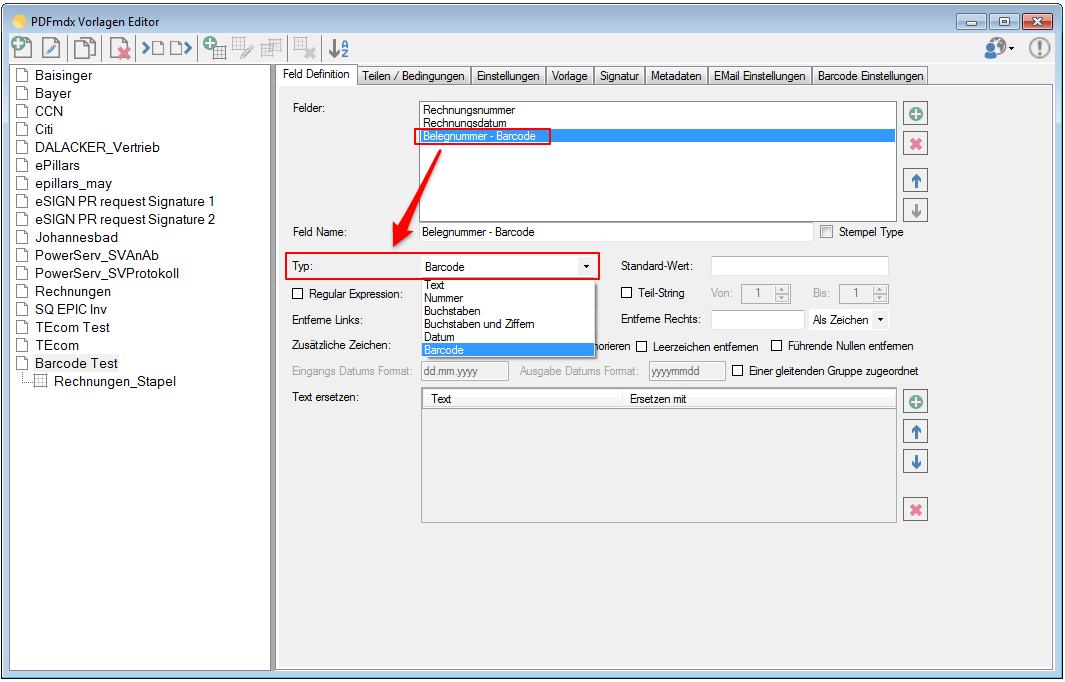
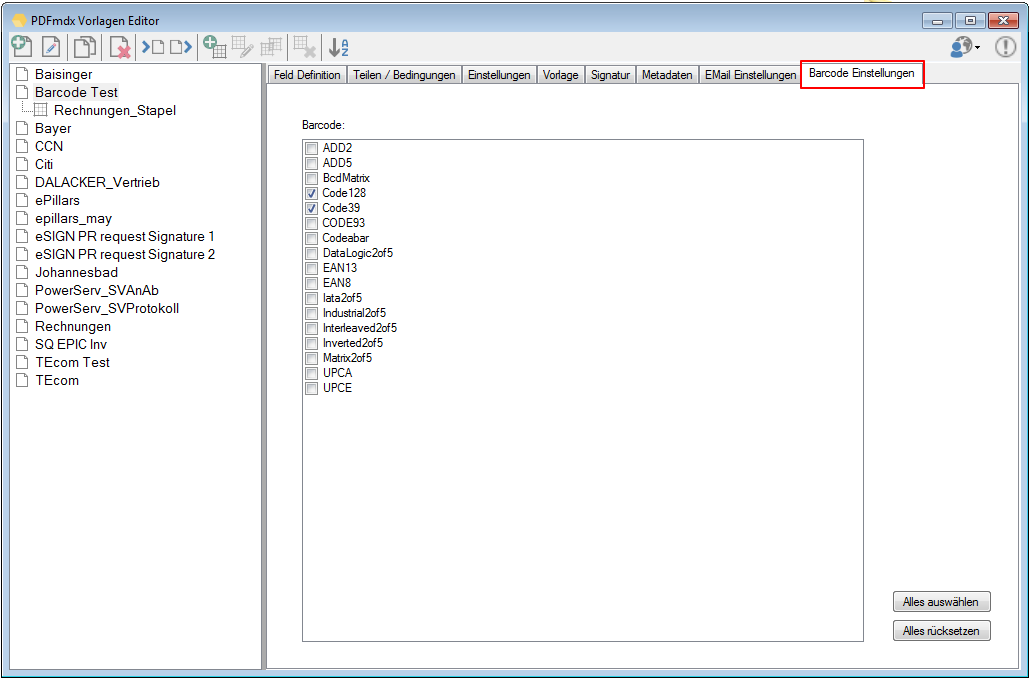

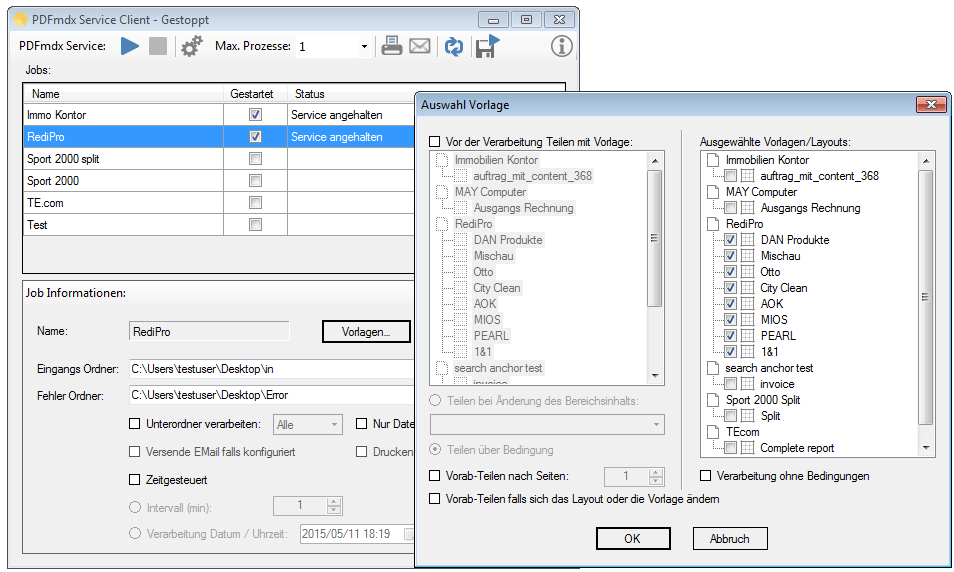
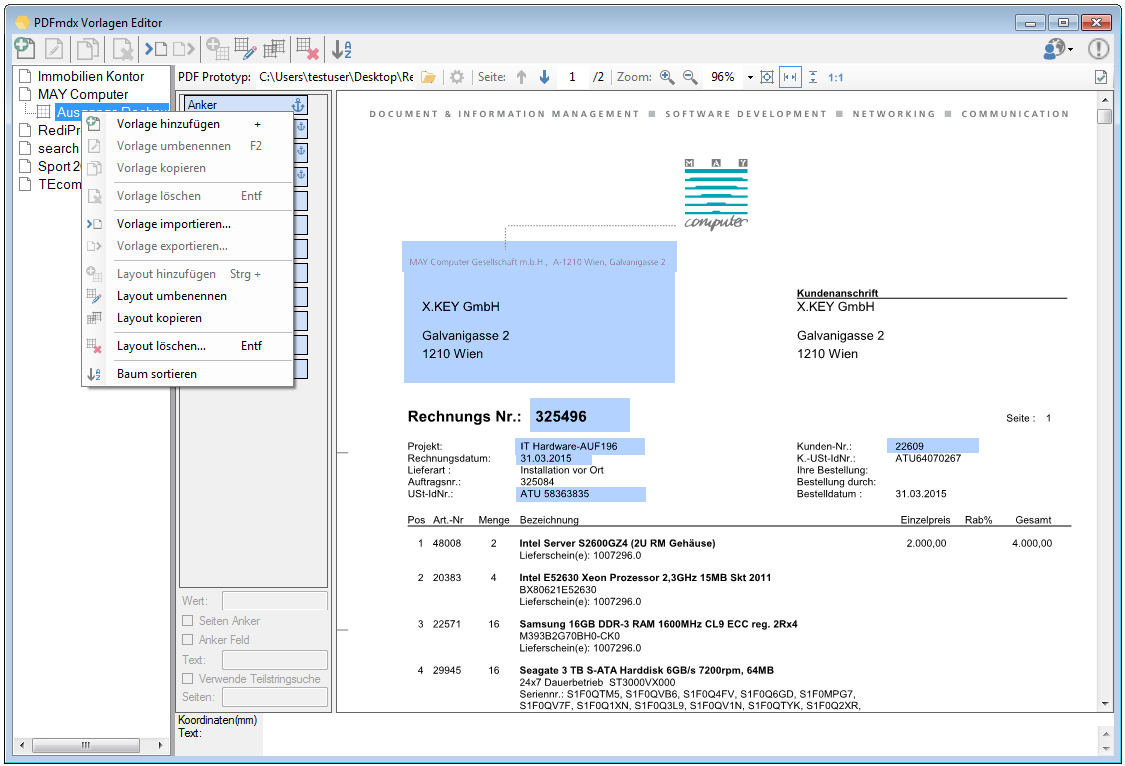
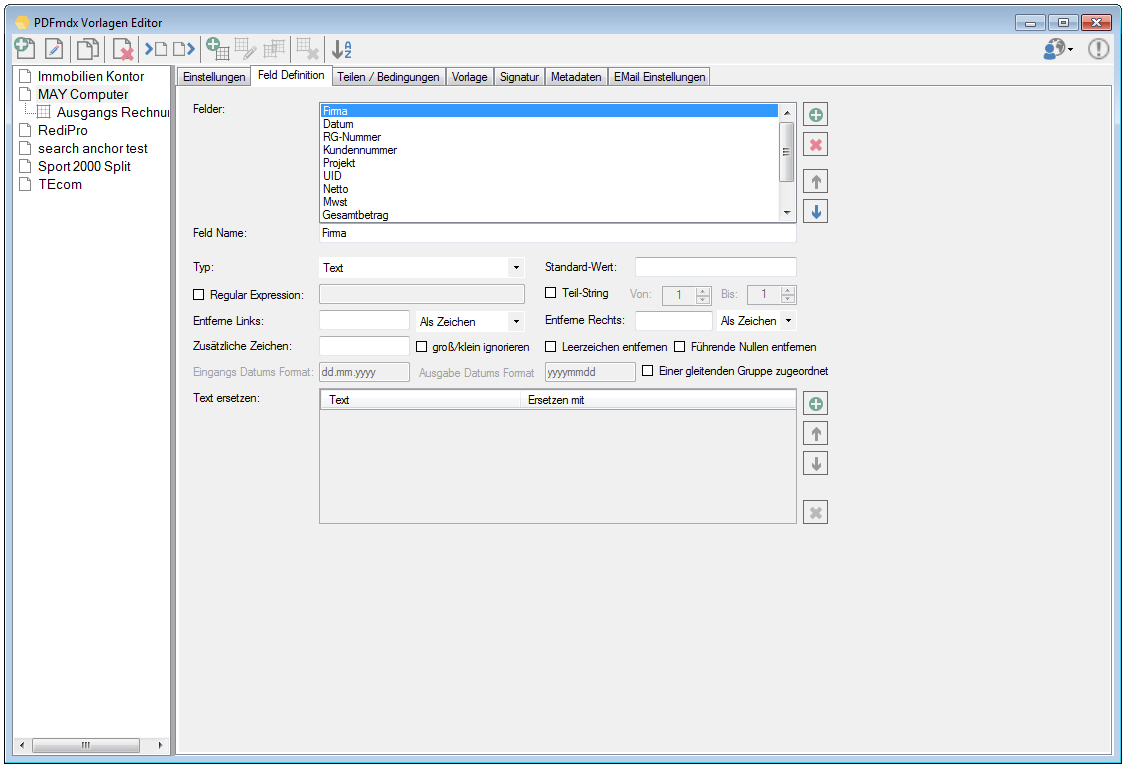
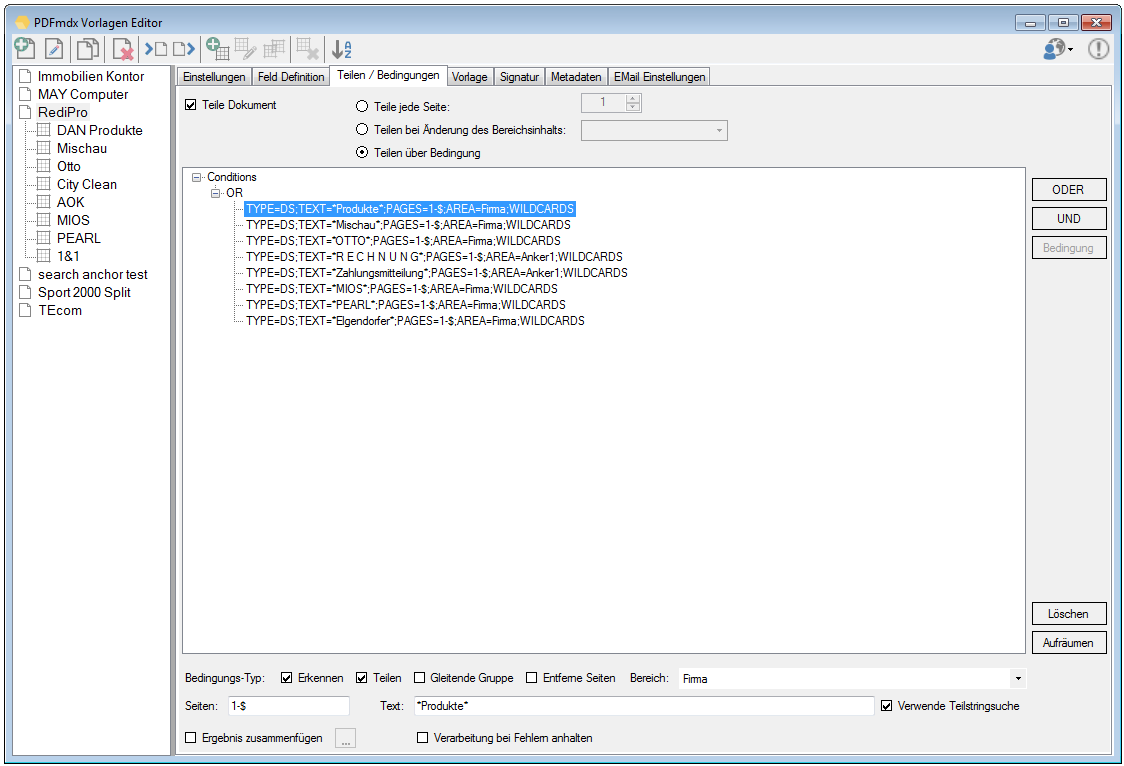
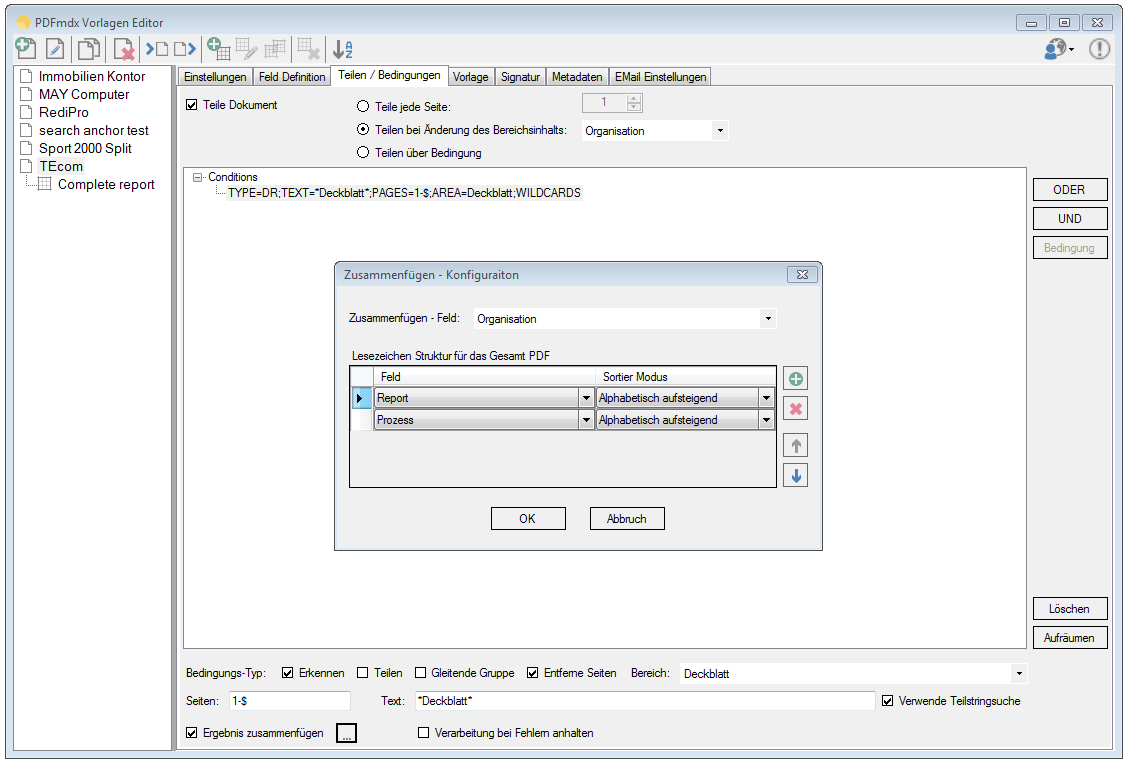
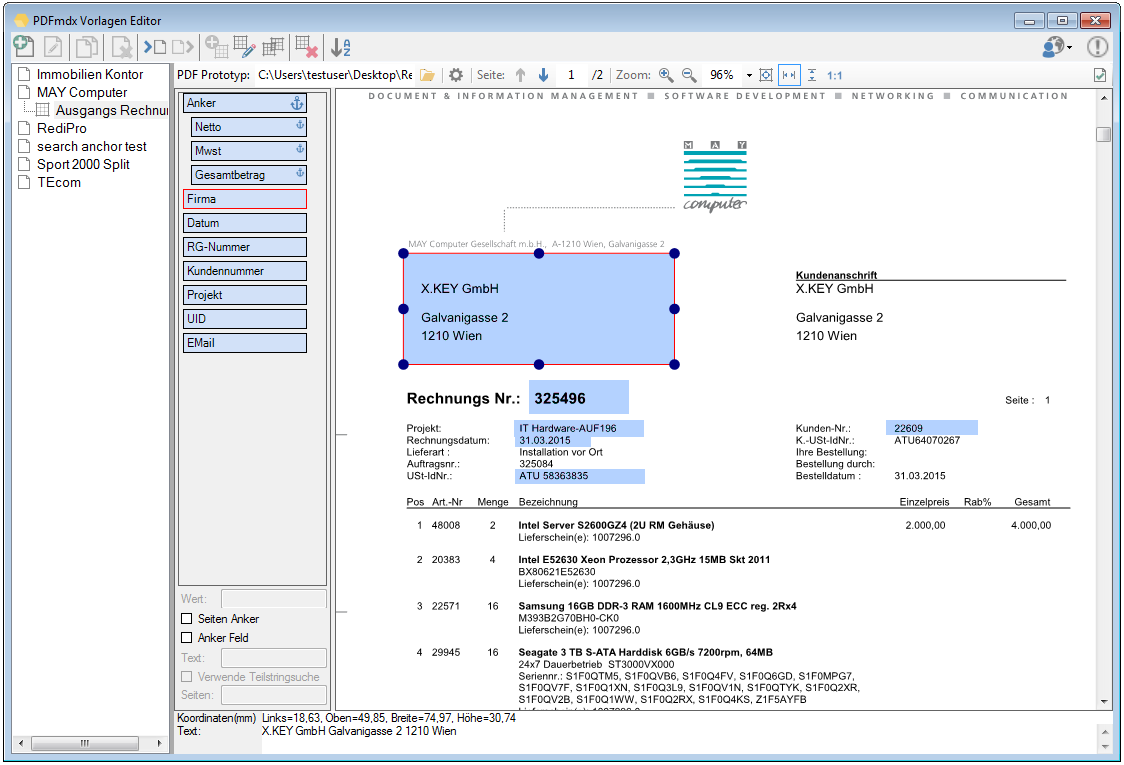
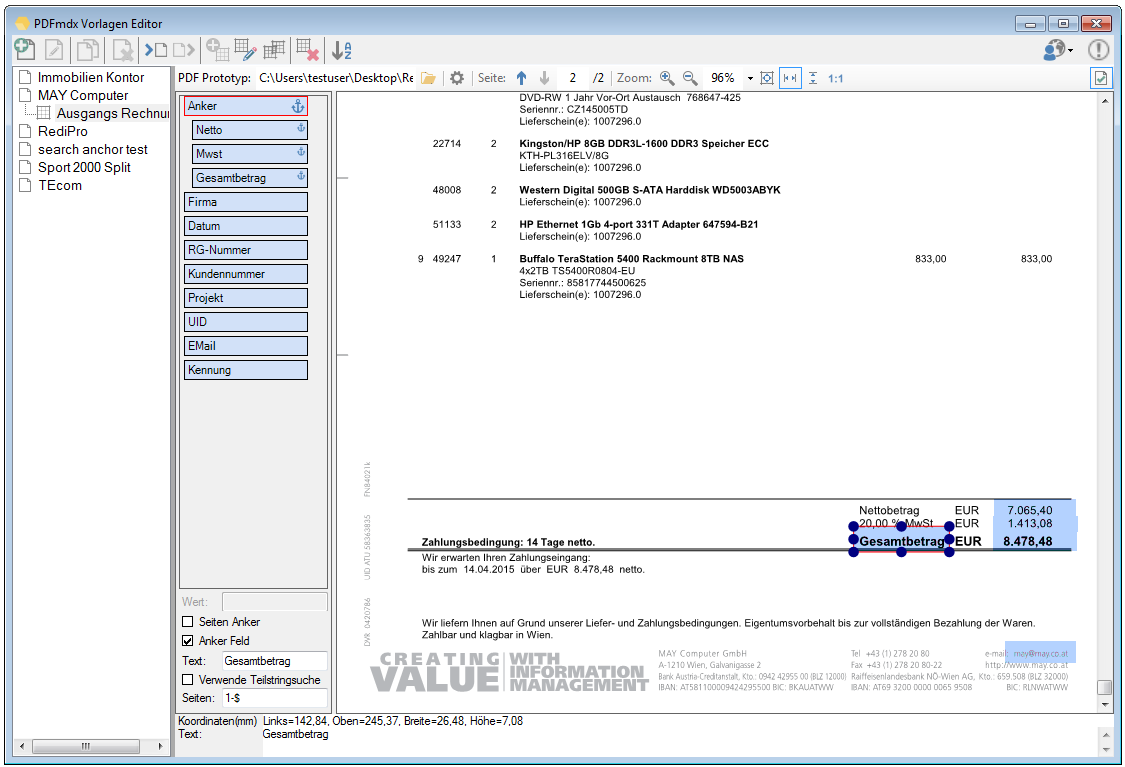
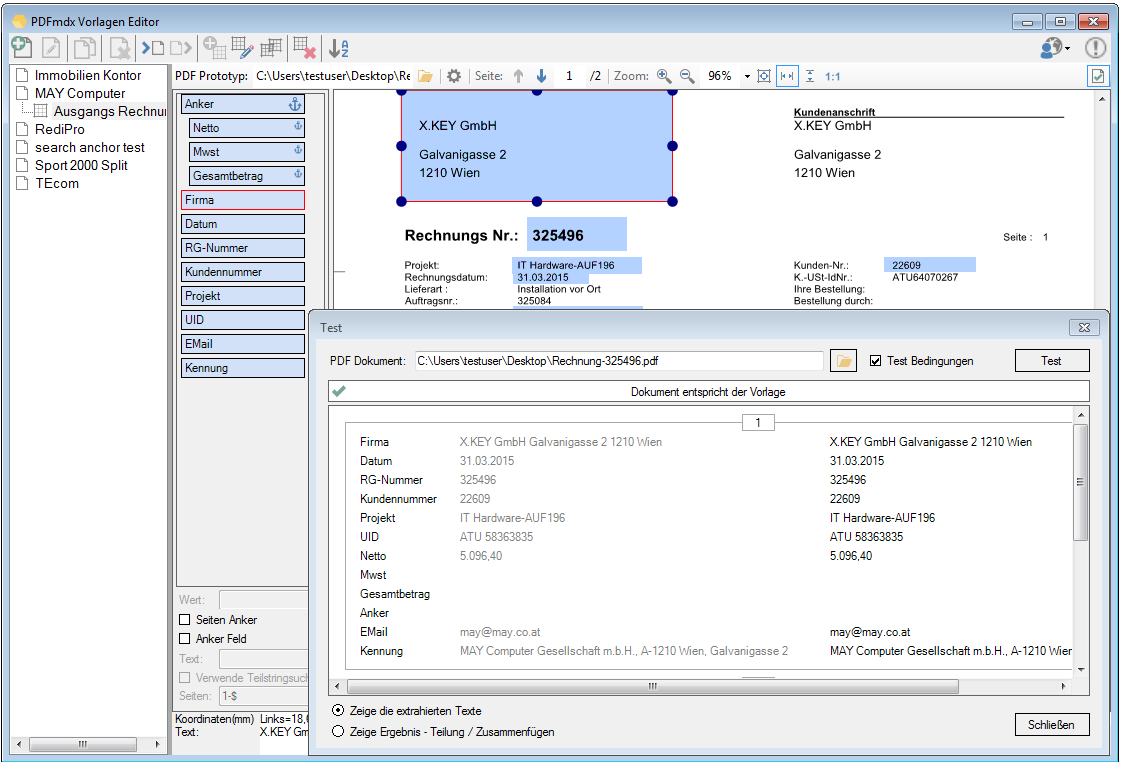
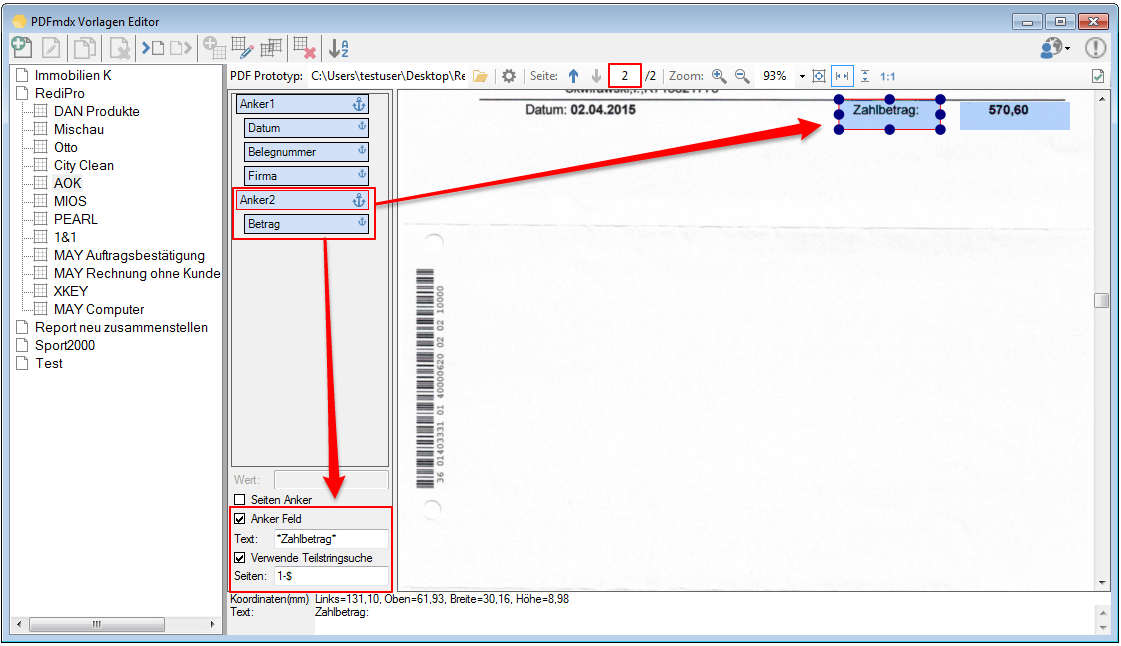
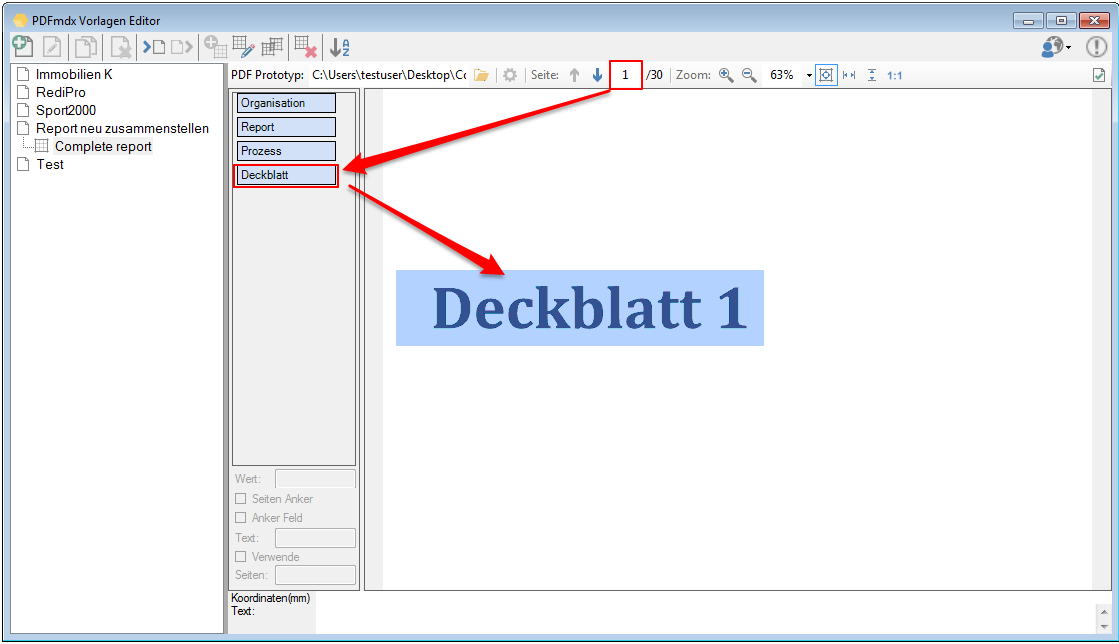
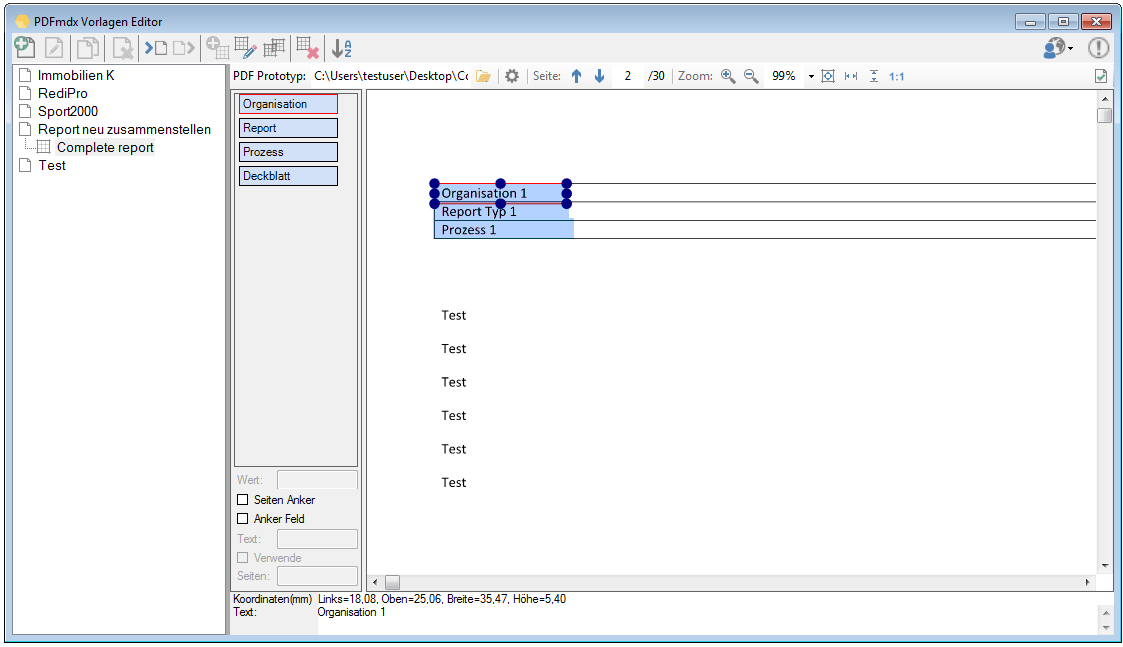
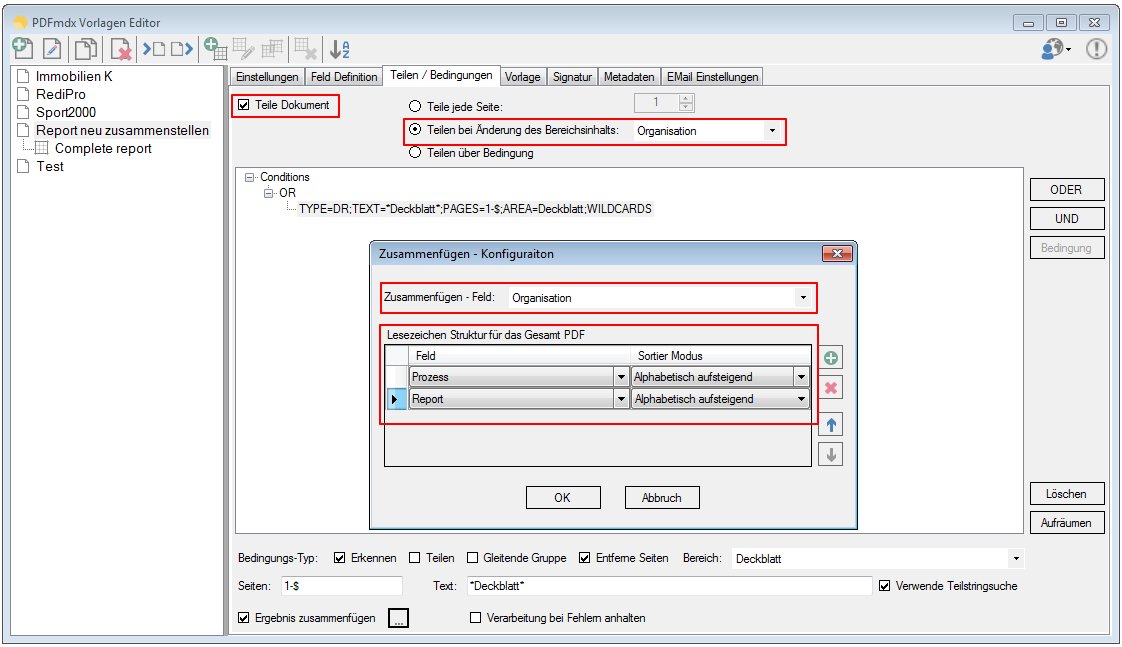
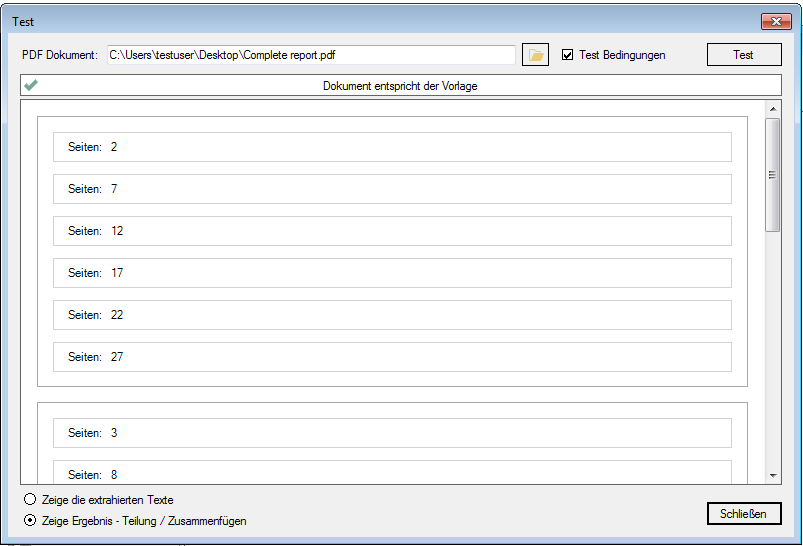
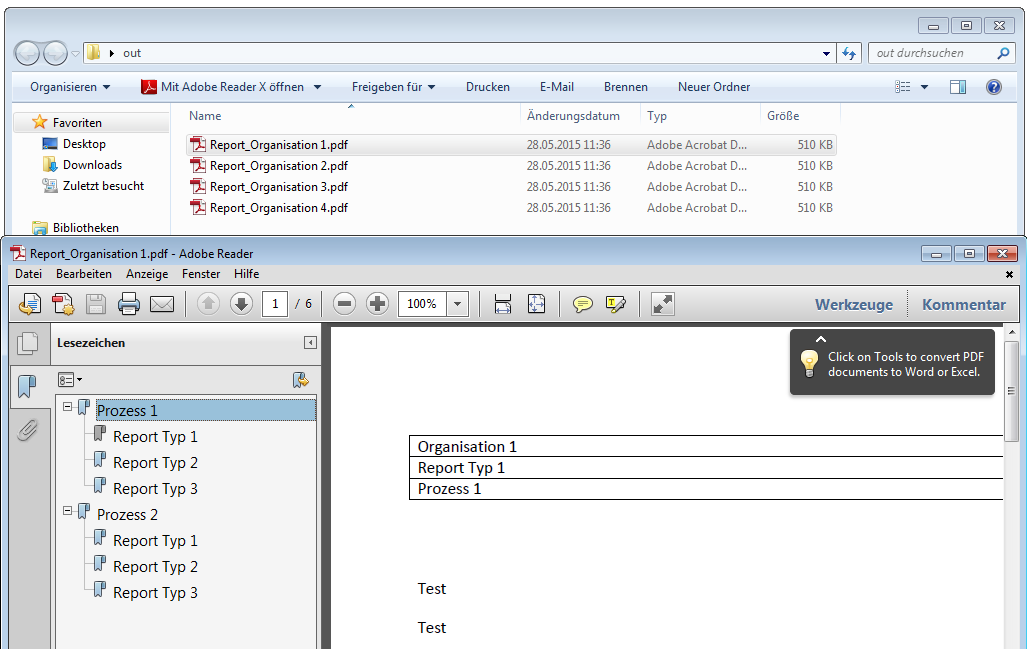
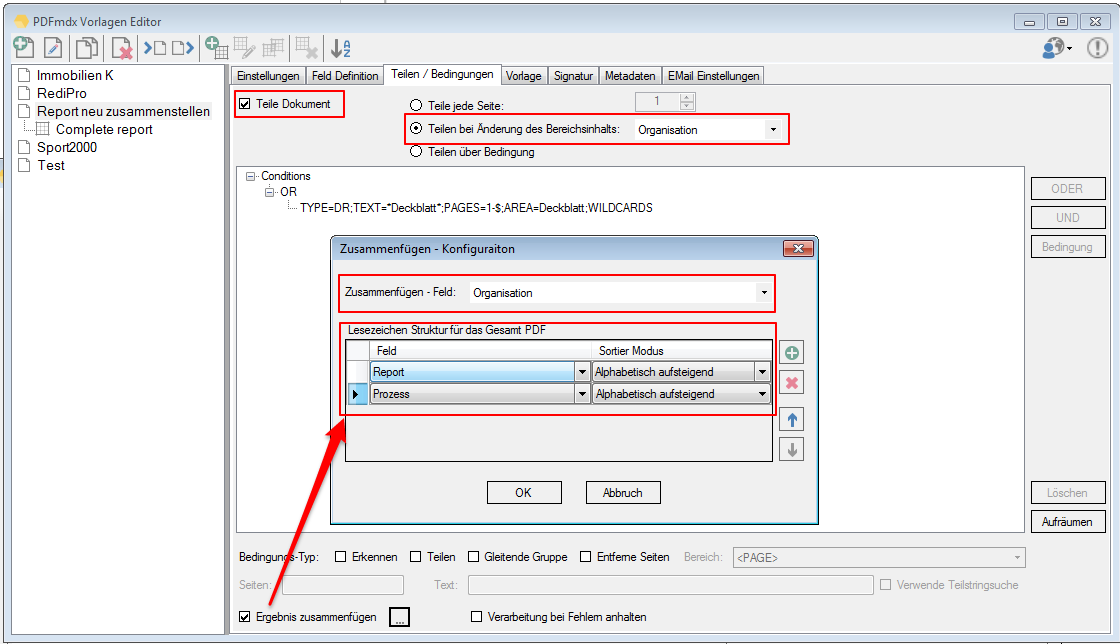
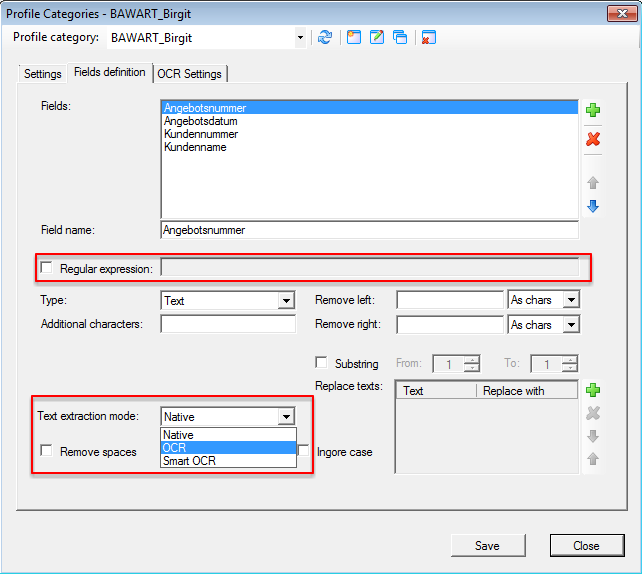
Verbesserte Anker / Suchfeldfunktion: Felder können in Relation zu einem „Anker / Suchfeld“ Feld gesetzt werden. Das Ankerfeld kann über einen Text bzw. Teilstring Suchtext auf einer Seiten gesucht werden. Wird der Begriff gefunden so werden die anderen Felder in Relation zu diesem Feld ausgelesen. Damit kann z.b. „Gesamtbetrag“ und die dazu in Relation stehenden Felder – Netto, Mwst, Brutto – gefunden und ausgelesen werden. Diese Funktion ist auch für die Verarbeitung eingescannter Dokumente wichtig da hier durch den Scanvorgang nicht gewährleistet ist dass sich die auszulesenden Felder immer an der gleichen Position befinden. Auch Barcode Felder können relativ zu Ankerfeldern festgelegt und gelesen werden.