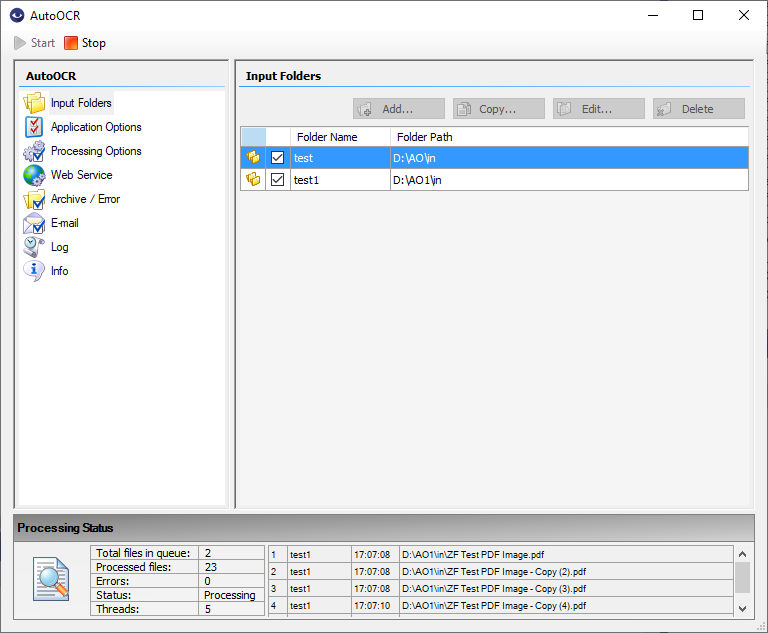
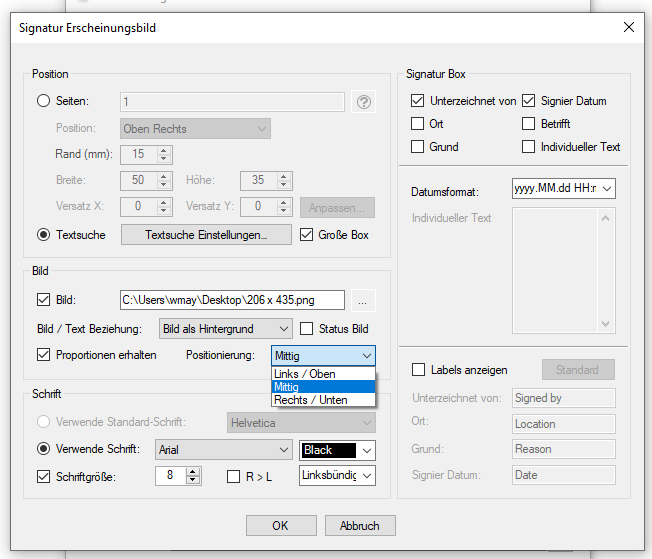
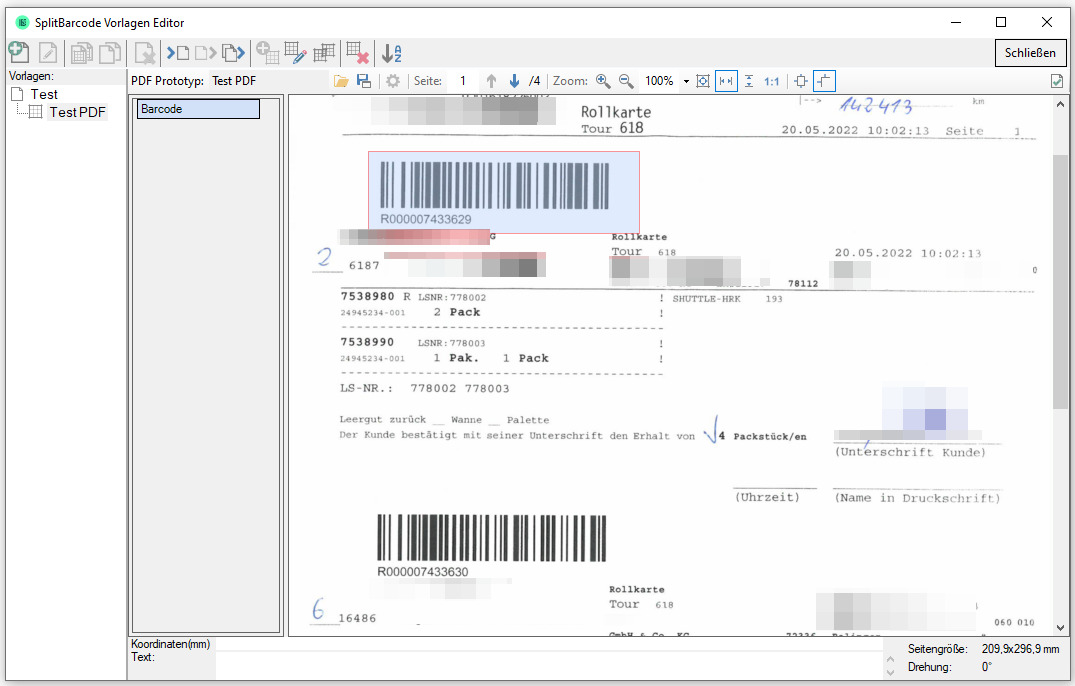
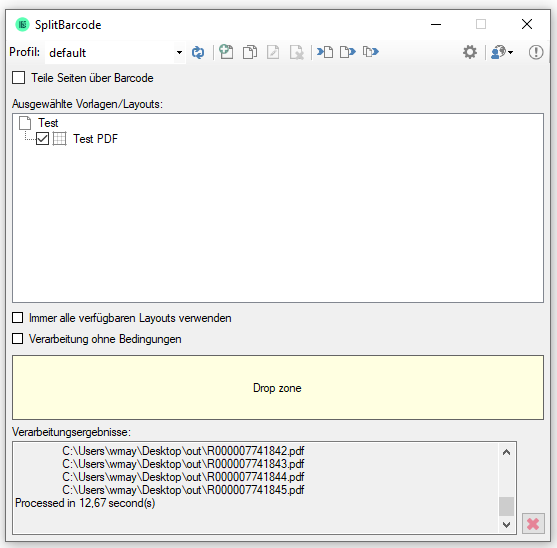
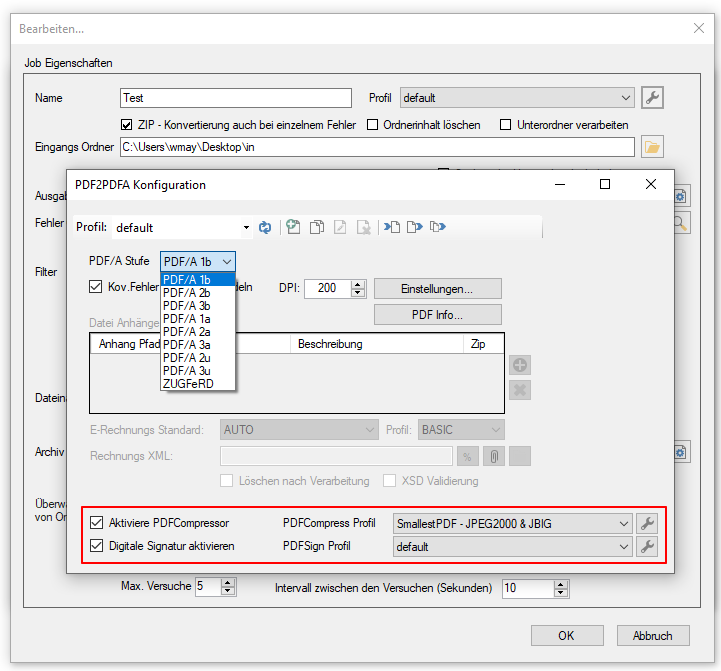
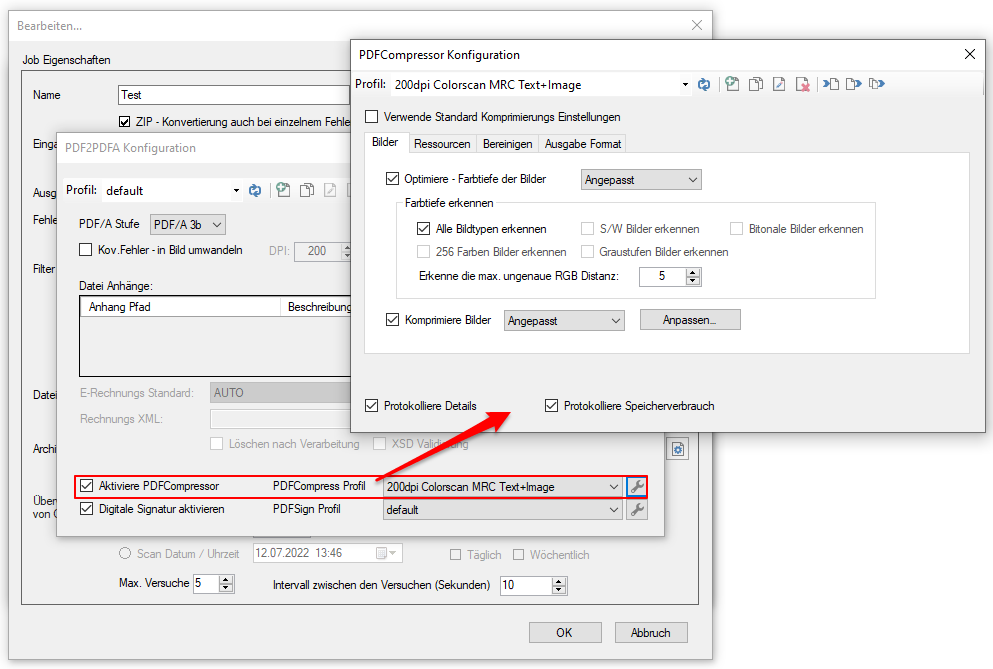
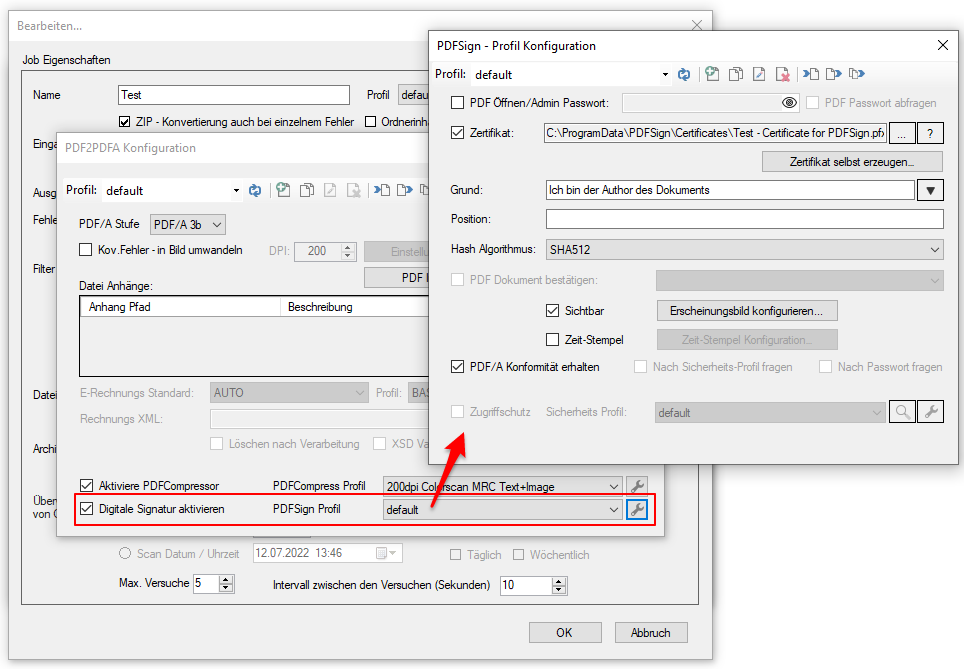
AutoOCR & AutoOCR-light Version 2.1.5
Neuerungen AutoOCR Version 2.1.5:
- Neue PAM Anwendungs ID für AutoOCR = 4AO. Erfordert die Neuaktivierung einer bestehender Installation, falls auf die AutoOCR Version 2.1.5 oder eine Nachfolgeversion upgedated wird. Kunden mit bestehender Softwarewartung erhalten die dafür erfoderliche neue Lizenz automatisch eingetragen. Die neue 4AO Lizenz kann über die PAM Funktion – „Activate Application“ mittels der vorhandene Kunden-ID / Passwort abgerufen werden.
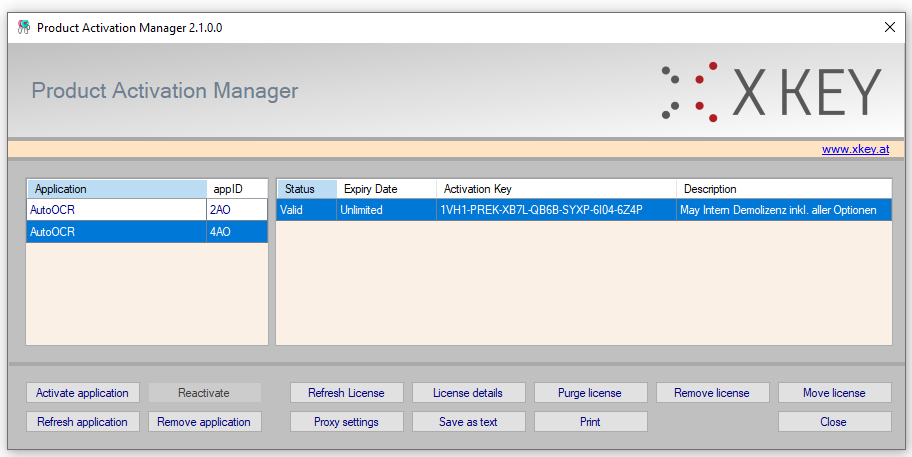
- Neue PAM Anwendungs ID für AutoOCR-light = 4AL. Erfordert die Neuaktivierung einer bestehender Installation, falls auf die AutoOCR-light Version 2.1.5 oder eine Nachfolgeversion upgedated wird. Kunden mit bestehender Softwarewartung erhalten die dafür erfoderliche neue Lizenz automatisch eingetragen. Die neue 4AL Lizenz kann über die PAM Funktion – „Activate Application“ mittels der vorhandene Kunden-ID / Passwort abgerufen werden.
Download – AutoOCR – OCR Server inkl. OmniPage OCR (ca. 670MB) >>>
Download – AutoOCR light – Low Cost OCR Server (ca. 670MB) >>>
Download – GenOCR – OCR Testanwendung für iOCR (ca. 680MB) >>>
Download – iOCR (vsOCR) Setup – zusätzliche Sprachen (ca. 1200MB) >>>