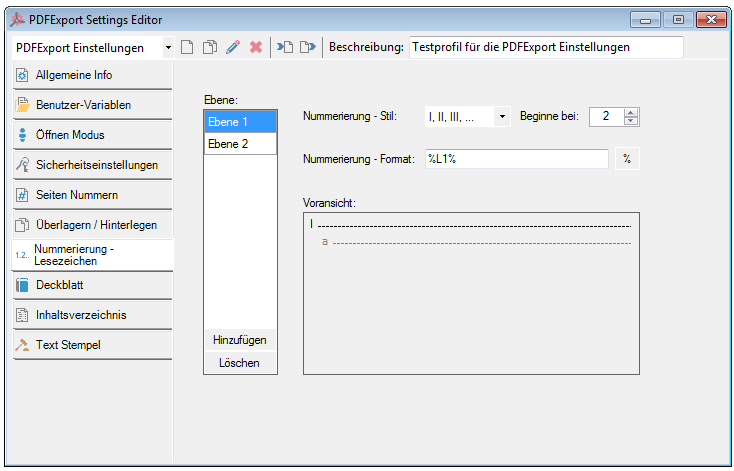
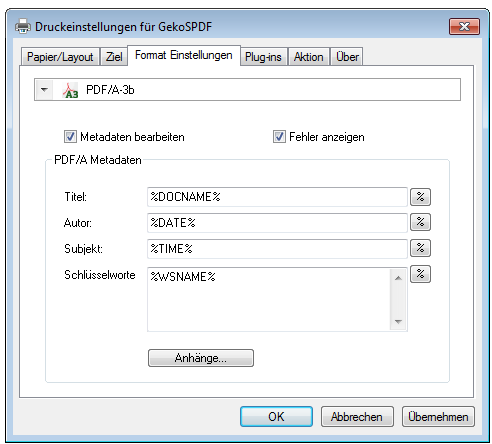
Software-Setup´s – Message “invalid signature or corrupted cabinet file” – Code-signing certificates – SHA-1 and SHA-256
Since 01/01/2016 we received repeatedly the message that our software Setup’s can not be installed on certain systems. It happens when you run Setup, an error message “invalid signature or corrupted cabinet file“.
It is because from 01.01.2016 no SHA-1, but only SHA-256 Certificates may be used for signing software. But not every old OS version supports SHA256 certificates.
![]()
Info from Microsoft PKI Blog:
“Effective January 1, 2016, Windows (version 7 and higher) and Windows Server will no longer trust new code that is signed with a SHA-1 code signing certificate for Mark-of-the-Web related scenarios (e.g. files containing a digital signature) and that has been time-stamped with a value greater than January 1, 2016. This cut-off date applies to the code-signing certificate itself.
This restriction will not apply to the time-stamp certificate used to time-stamp the code-signing certificate or the certificate’s signature hash (thumbprint) until January 1, 2017. After this time, Windows will treat any code with a SHA-1 time-stamp or SHA-1 signature hash (thumbprint) as if the code did not have a time-stamp signature.”
What does that mean?
Any files signed with an SHA-1 certificate need to have a timestamp showing a date and time prior to Jan 1, 2016 for continued support. Those files will still be allowed through the ‘Mark-of-the-web” system until Jan 14, 2020, when all SHA-1 support will stop in all current versions of Windows. All new signatures created or timestamped after Jan 1, 2016 must be SHA-256 based signatures or they will cause a “digital signature is corrupted or invalid” error when downloading.
What versions of Windows support SHA-256 signatures?
SHA-256 signatures are not supported in Windows XP SP2 or earlier. SHA-256 is only supported in User Mode for Windows XP SP 2, Vista and Windows Server 2008R1 — SHA-256 certificates are not supported for drivers on any version prior to Windows 7.
Microsoft is announcing the availability of an update for all supported editions of Windows 7 and Windows Server 2008 R2 to add support for SHA-2 signing and verification functionality. Windows 8, Windows 8.1, Windows Server 2012, Windows Server 2012 R2, Windows RT, and Windows RT 8.1 do not require this update as SHA-2 signing and verification functionality is already included in these operating systems. This update is not available for Windows Server 2003, Windows Vista, or Windows Server 2008.
Workaround:
Please contact us in this regard, We then provide you with a setup without code signature. Then the software can be installed on “old” operating systems that do not support SHA-256 encryption.