EMail Archiver for FileConverterPro – version 3.0.1
Innovations version 3.0.1:
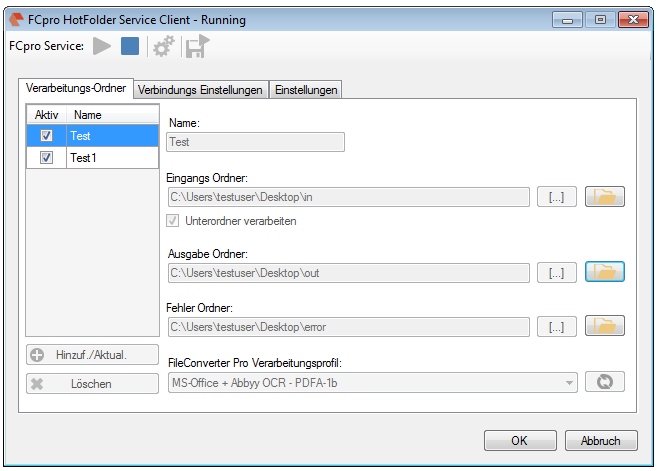
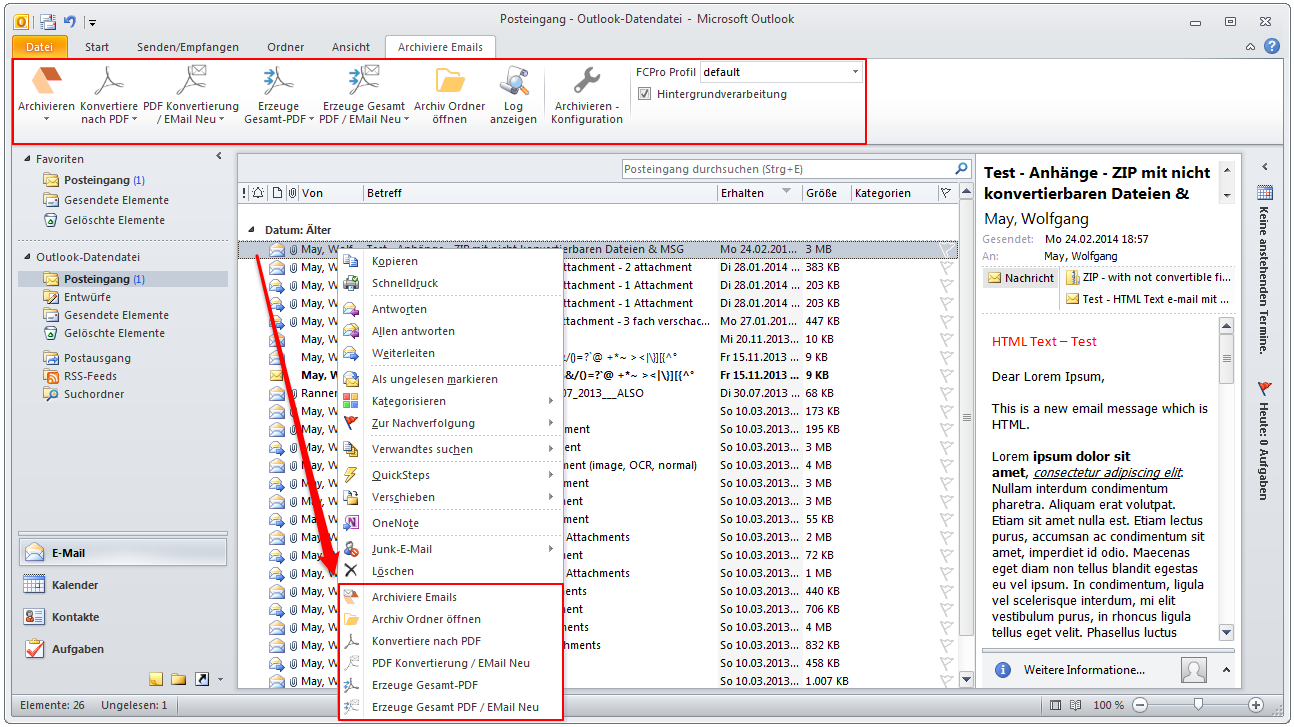
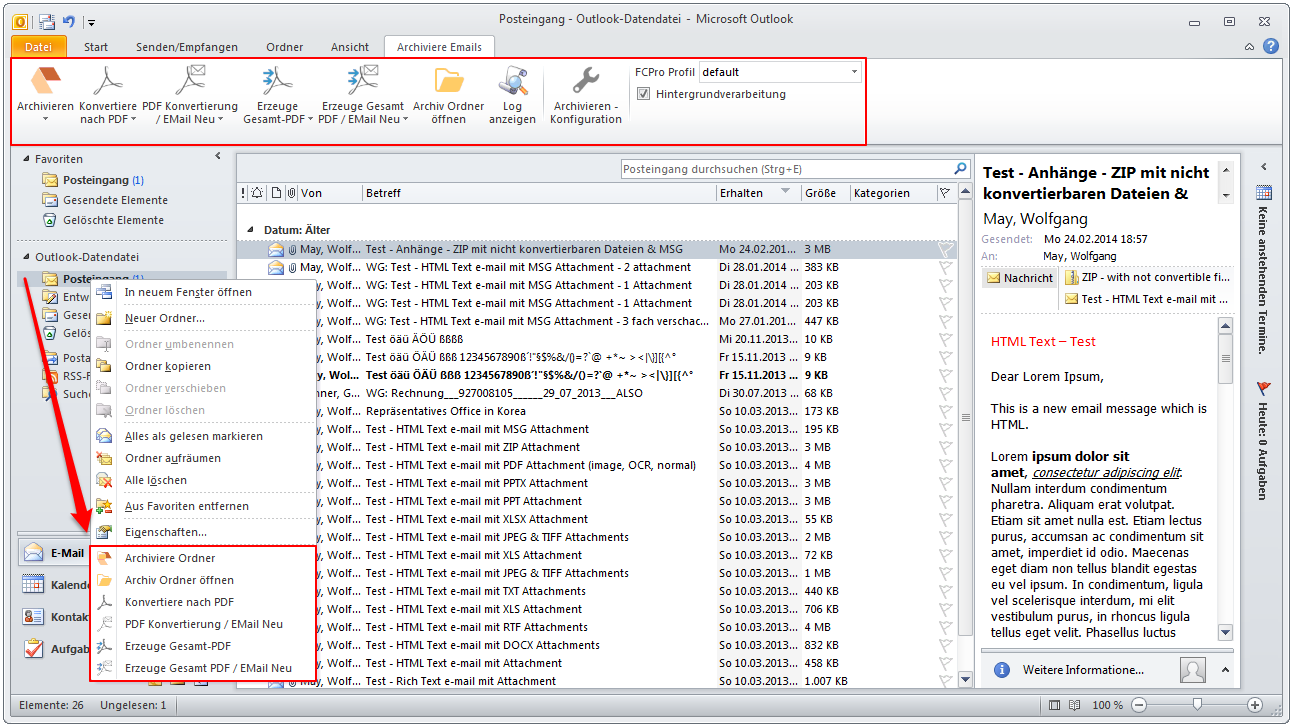
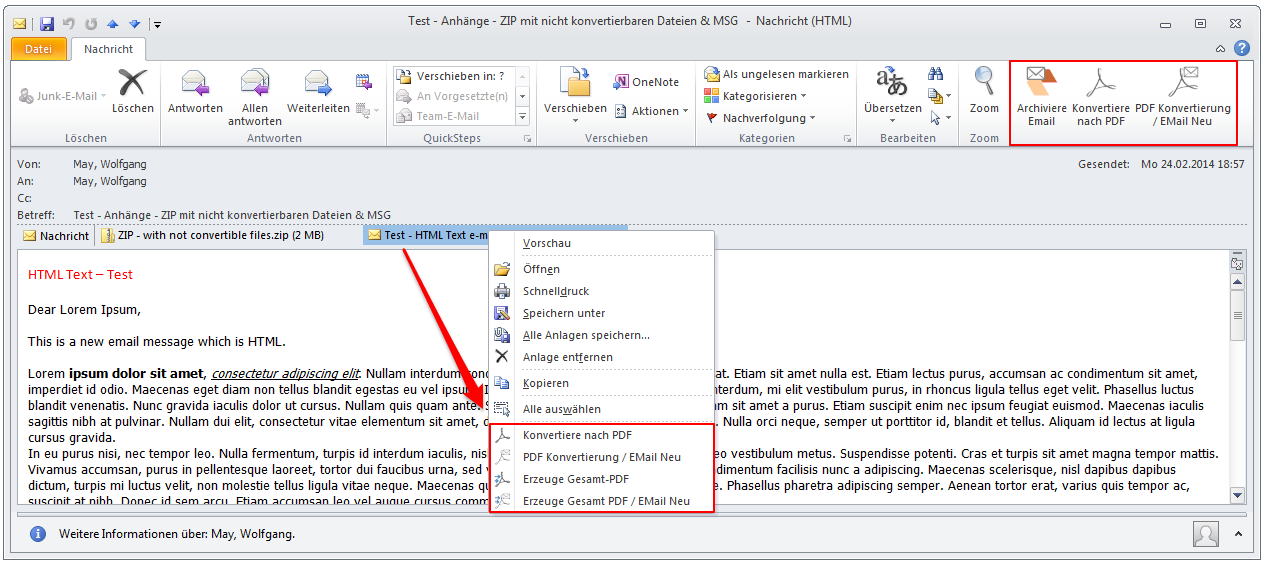
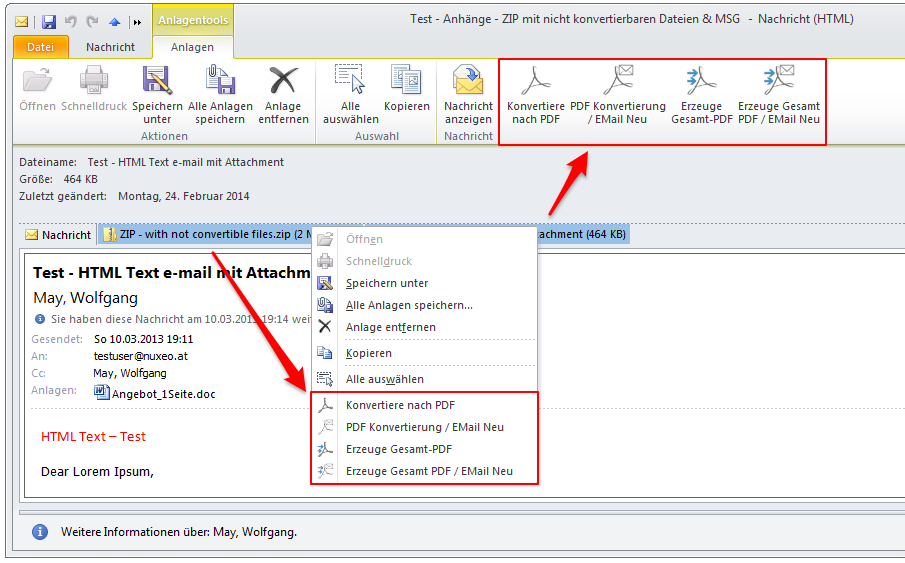
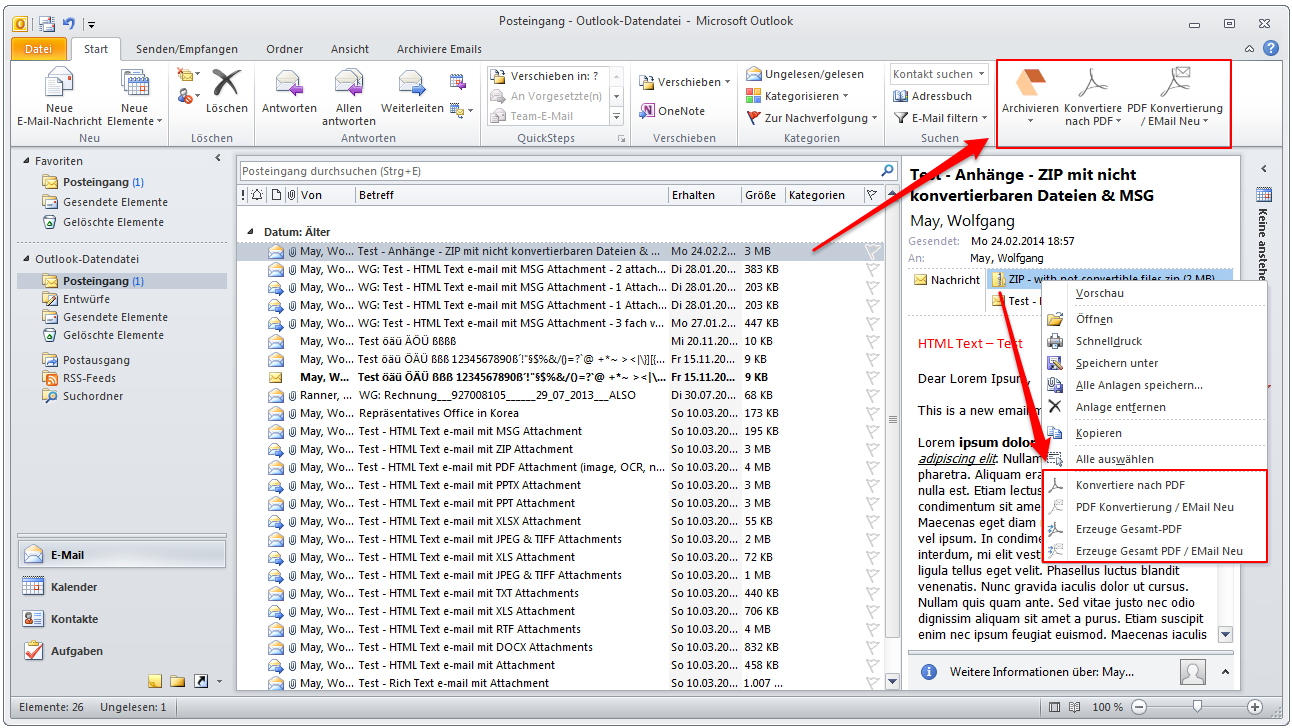
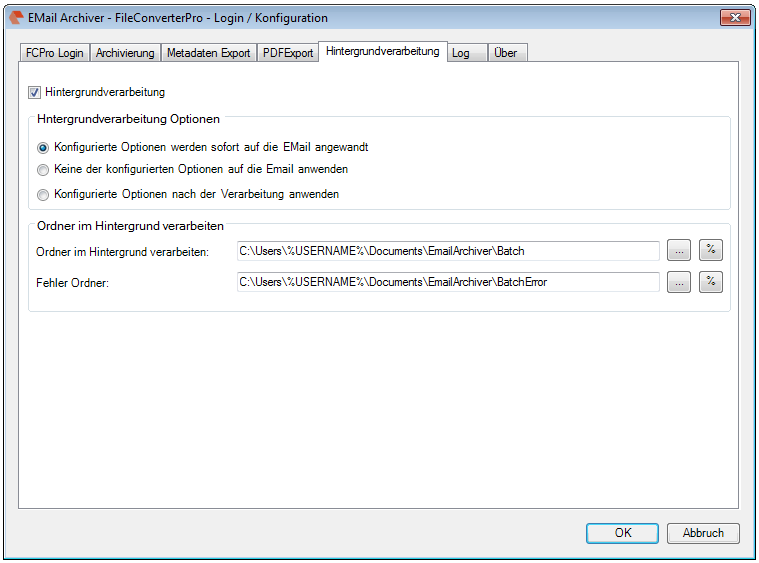
- The background-processing was reimplemented and is now instead of as Windows service implemented as startable Icon Tray application.
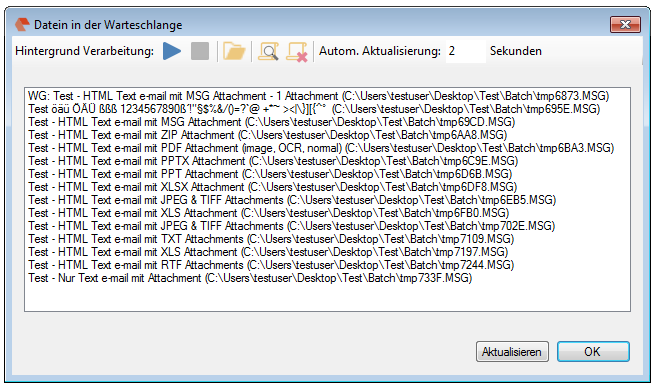
- The jobs currently opened in the queue of the background-processing can be displayed. The updating of this queue is done automatically.
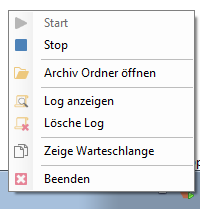
- Via the context-menu of the background-processing – the processing can be stopped, started, the archive folder can be opened, the log can be displayed and deleted as well as the queue can be displayed.
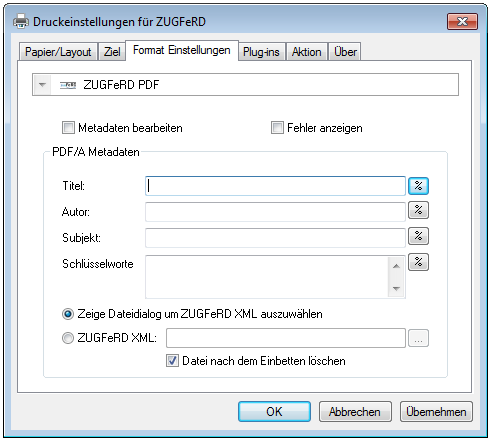
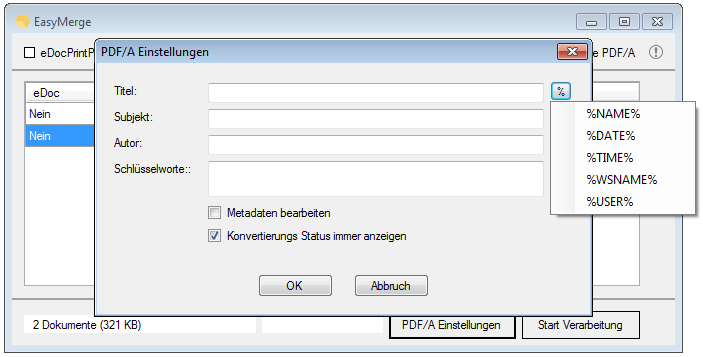
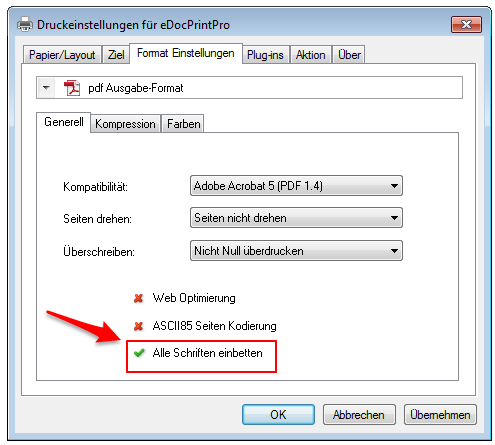
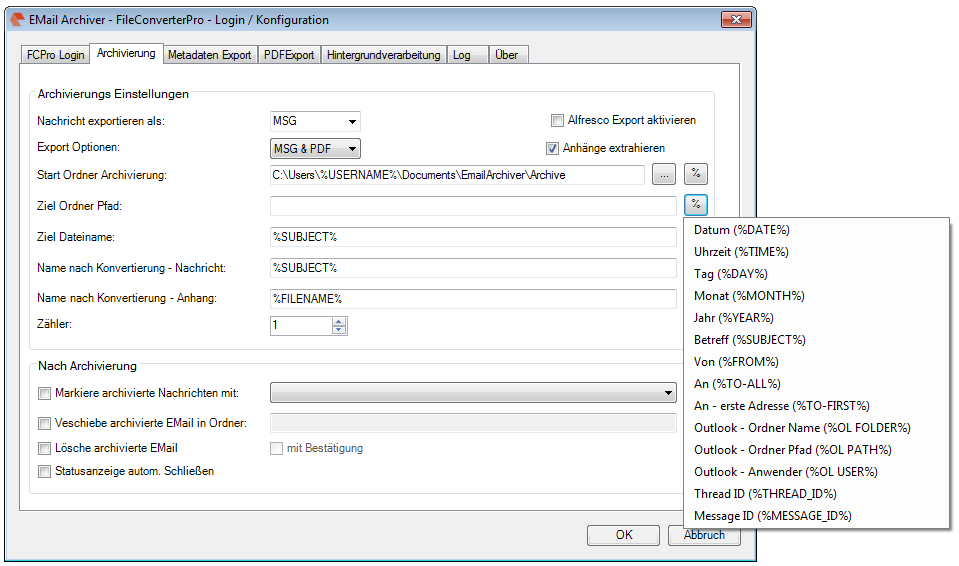
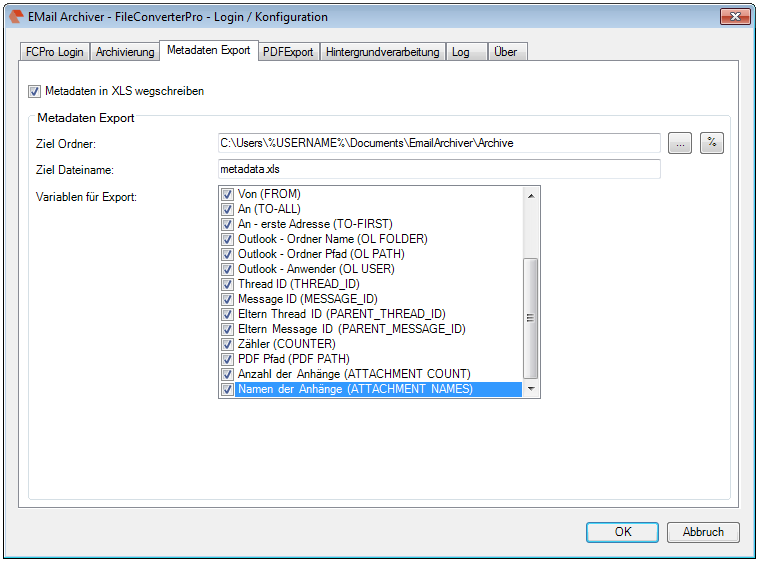
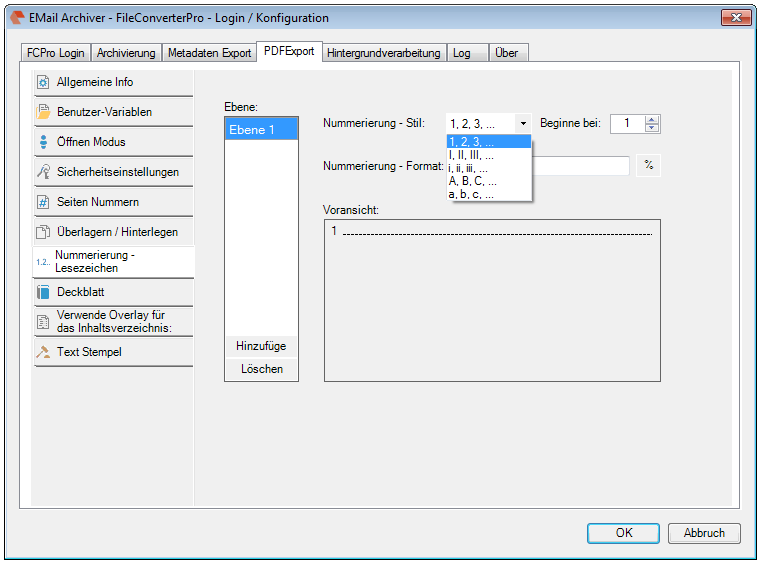
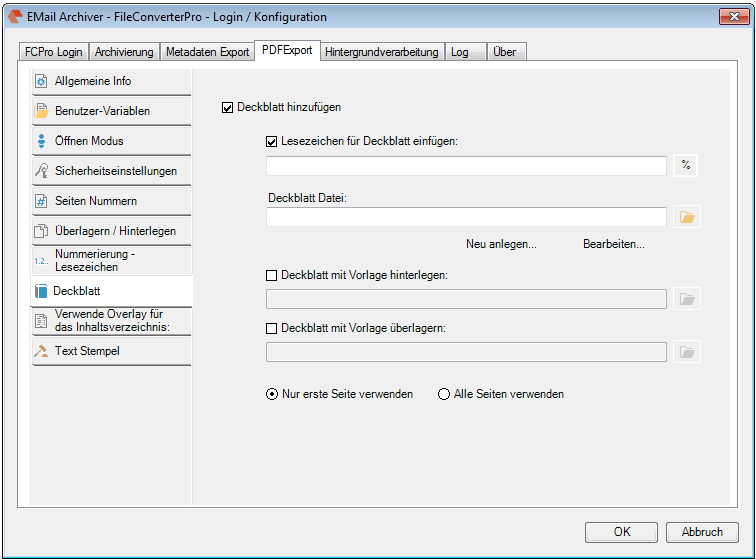
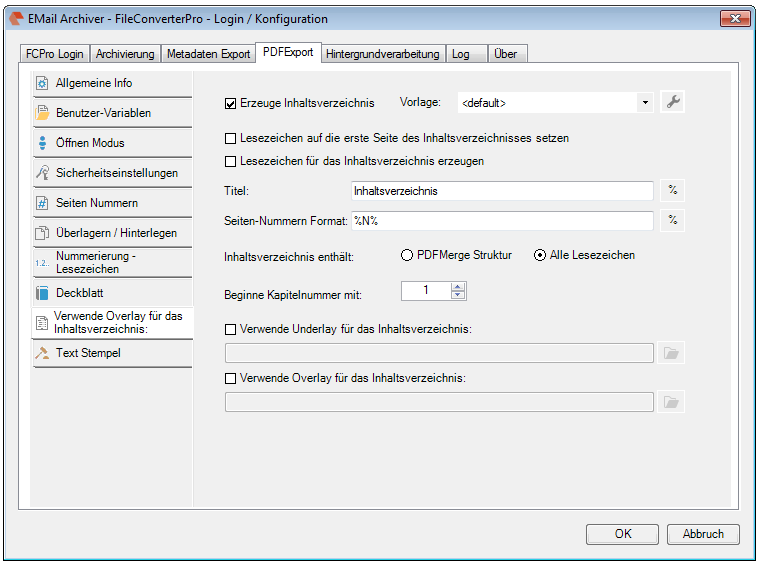
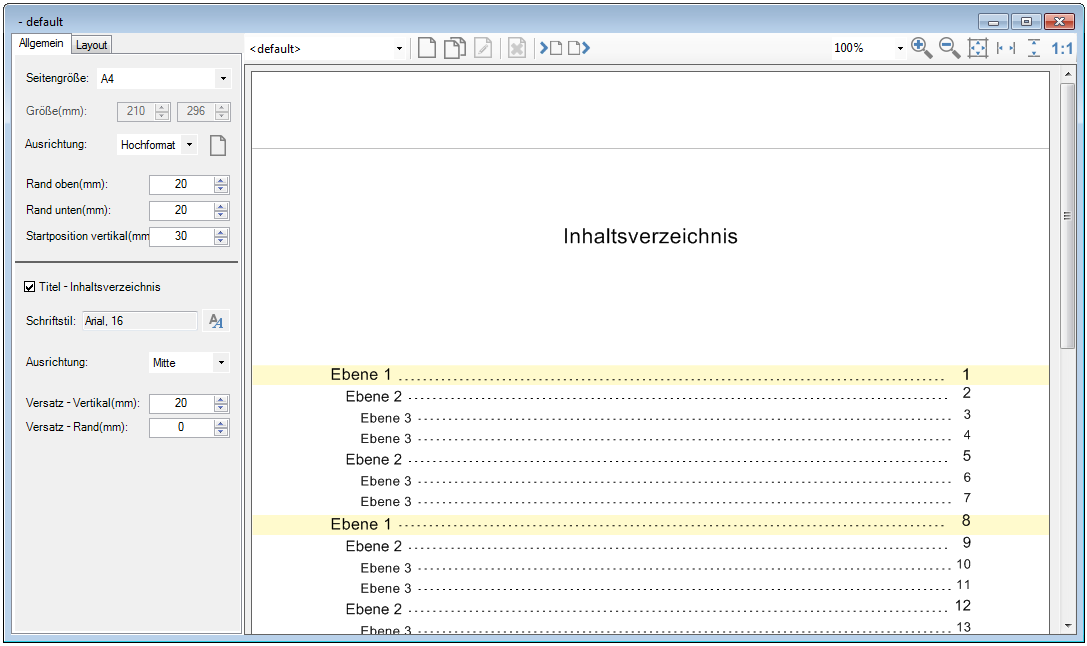
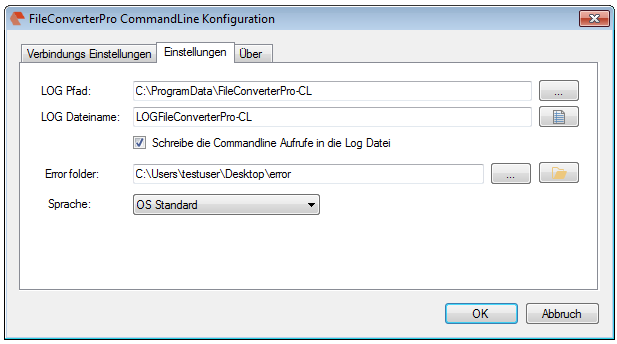
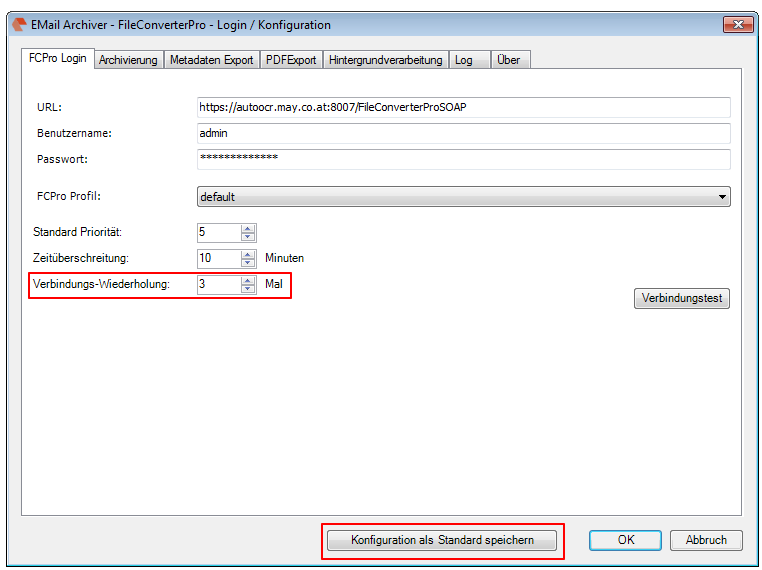
- The current configuration can be saved “as standard” to afterwards use the XML file as draft for the spreading to all computers. Also see usage of a template config file
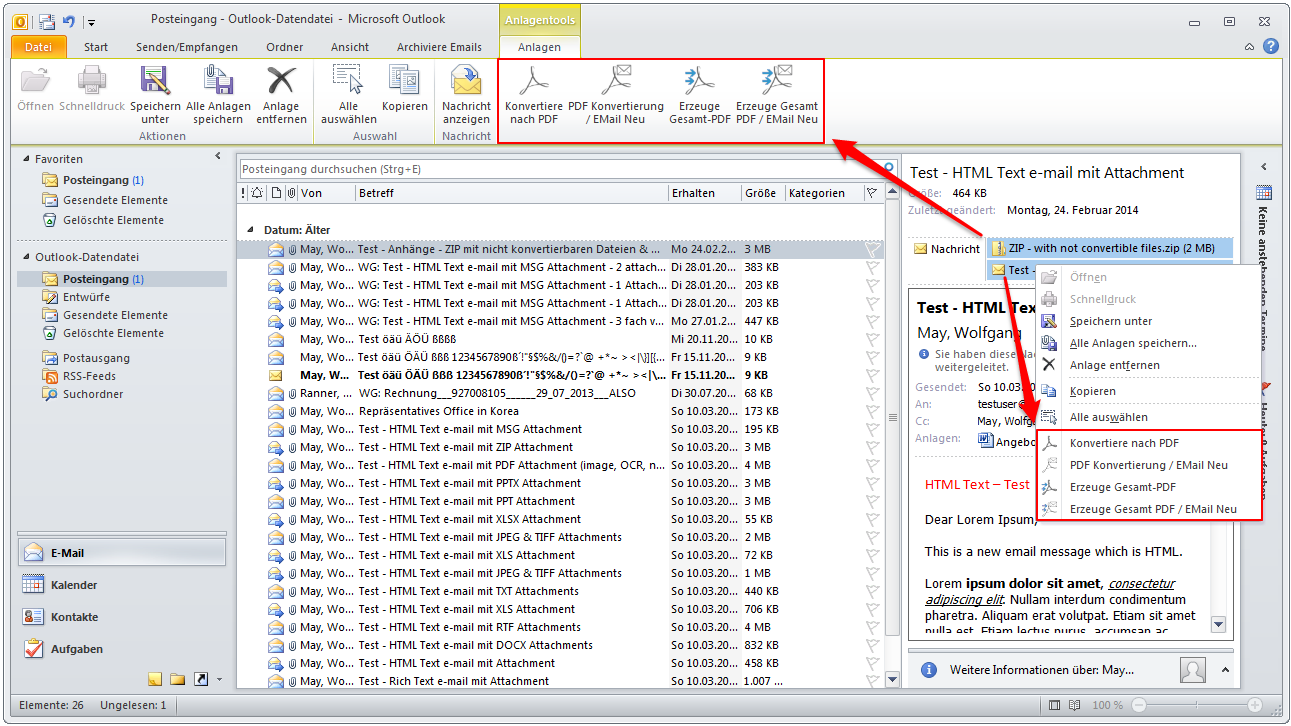
Download – EMail Archiver MS-Outlook Plugin for FileConverterPro >>>
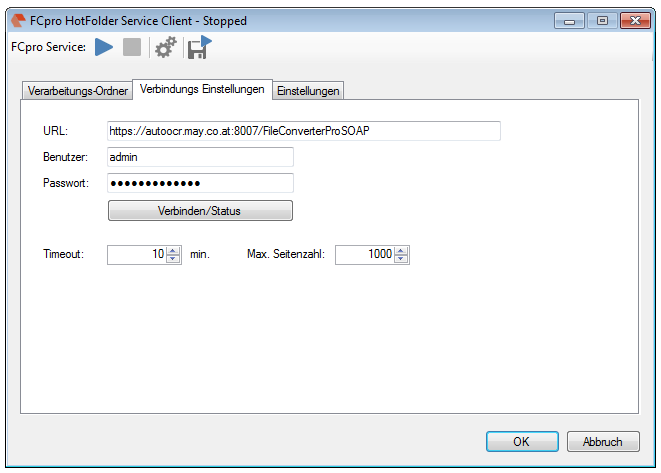
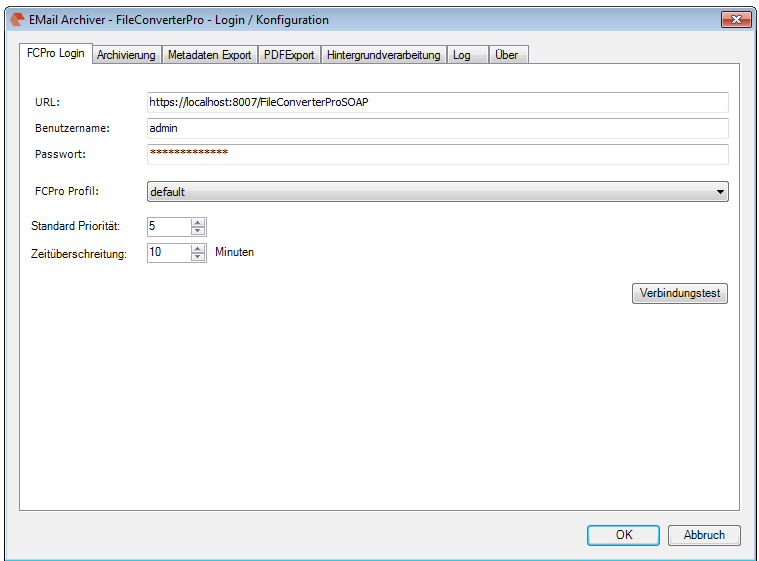
For tests the FileConverter Pro Testserver, hosted by us, can be used – it is set by default in the EMail Archiver after the installation