FileConverter – processing of folders and subfolders – configuration and features
The FileConverter (FC) has several options to control the processing via folders and subfolders.
The first thing important to know is that the processing takes place “transaction oriented”. That means the FC needs to know when the processing of the files from the in-folder and the subfolders it possibly contains can be started – because there could be new files added any time.

Trigger to start the processing – there are 2 possibilities for this:
- The time of the last writing process of the files is used plus a setable delay. If there are no new files added in this period of time all files of the in-folder get recognized as a transaction and the processing starts.
Caution: If an entire folder or folder structure is copied into the in-folder the “old” creation date of the single documents will be preserved. It only gets set newly if the files and not the entire folder gets copied. In this case “ready” files have to be used or the processing can also be initiated with a “stop” and new “start” of the FC-services.
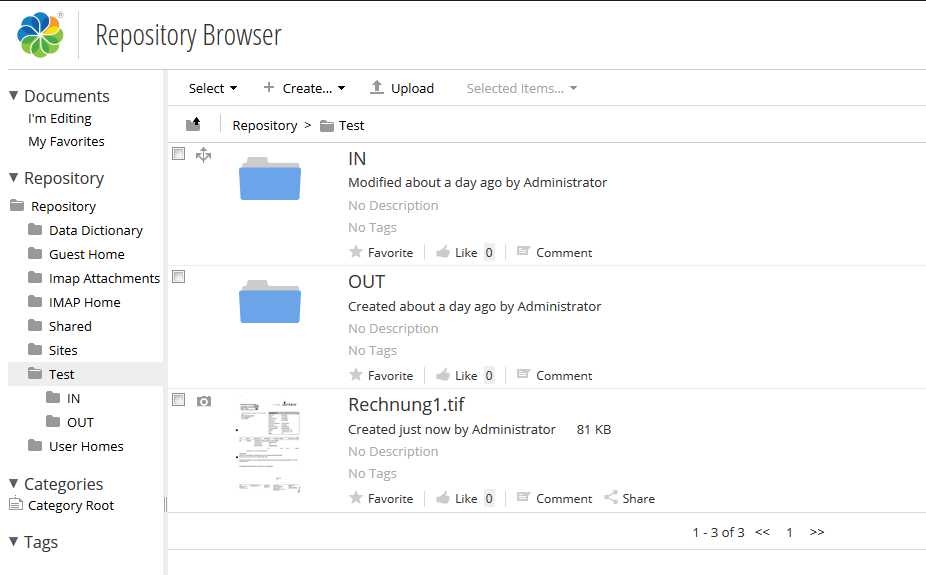
- A “ready” file (ready.rd) is used. As soon as this file appears the available content of the in-folder at this moment is recognized as transaction and processed. The contents of the ready file don’t matter – it also can be empty. The name is configurable. If a ready file is used it has to be available in every folder which should be processed – therefor also in the subfolders of the subfolder processing was activated.
Process subfolders – yes / no:
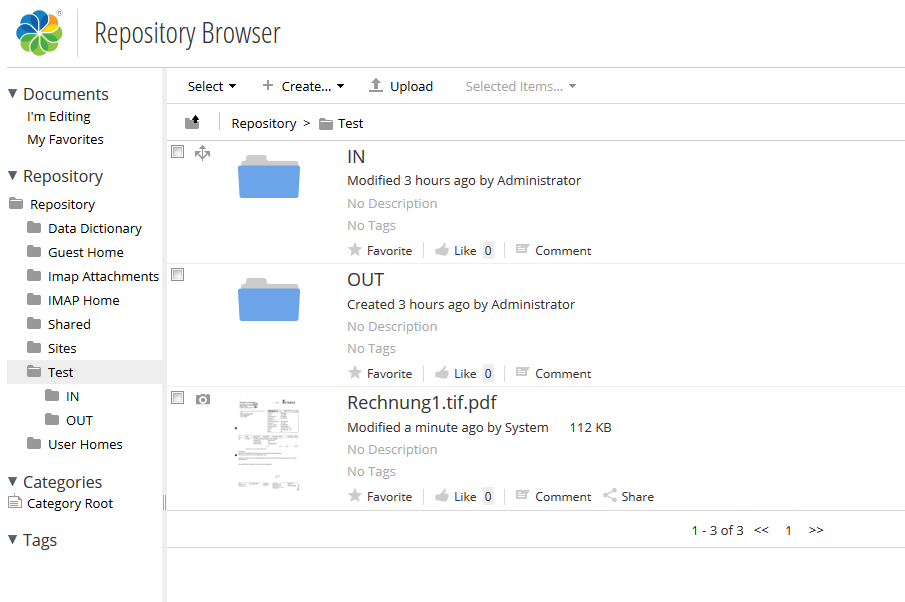
- If this option is not active only files from the root-in-folder get processed. Possibly underlying subfolders get ignored. Inside the out-folder an unique with date and time as name gets created for every transaction. All files created from the transaction get put into this folder.
- If this option is active and the option “subfolder processing from level” is inactive – all subfolders inside the in-folder get processed also. For each folder / subfolder from the in-folder, independent from the level in which it is located a folder with the same name gets created in the root level of the out-folder. In this case a possibly present folder structure from the in-folder isn’t created in the out-folder. This only happens if the option “subfolder processing from level” was activated.
Process all files – yes / no:
- With this option it can be controlled what is going to happen of a file from a transaction couldn’t be converted or creates an error. If this option is active all files get processed – if an error occurs the concerning file gets marked (renamed with .err or moved to an error folder). All other files from the transaction get processed though.
- If this option is not active the whole transaction gets aborted and “faulty” with the occuring of the first error. No other files get processed.
Subfolder processing from level:
With this option it can be controlled from which level the subfolder-processing should start. If e.g. 1 is configured all folders and underlying levels inside the in-folder get processed. The files which are located in the input-folder directly don’t get processed however.
- If this option is active the same folder structure as in the in-folder (beginning at the defined level) gets build in the out-folder.
- If this option is not active the folder structure doesn’t get taken over from the in-folder to the out-folder. For every folder (level-independent) a new folder with the same name gets created in the root of the out-folder. Therefor all in-folders get created in one level in the out-folder.
Download – FileConverter – documentc & e-mails to PDF, PDF/A and TIFF >>>