ifresco Client for Alfresco DMS/ECM – New version in labor
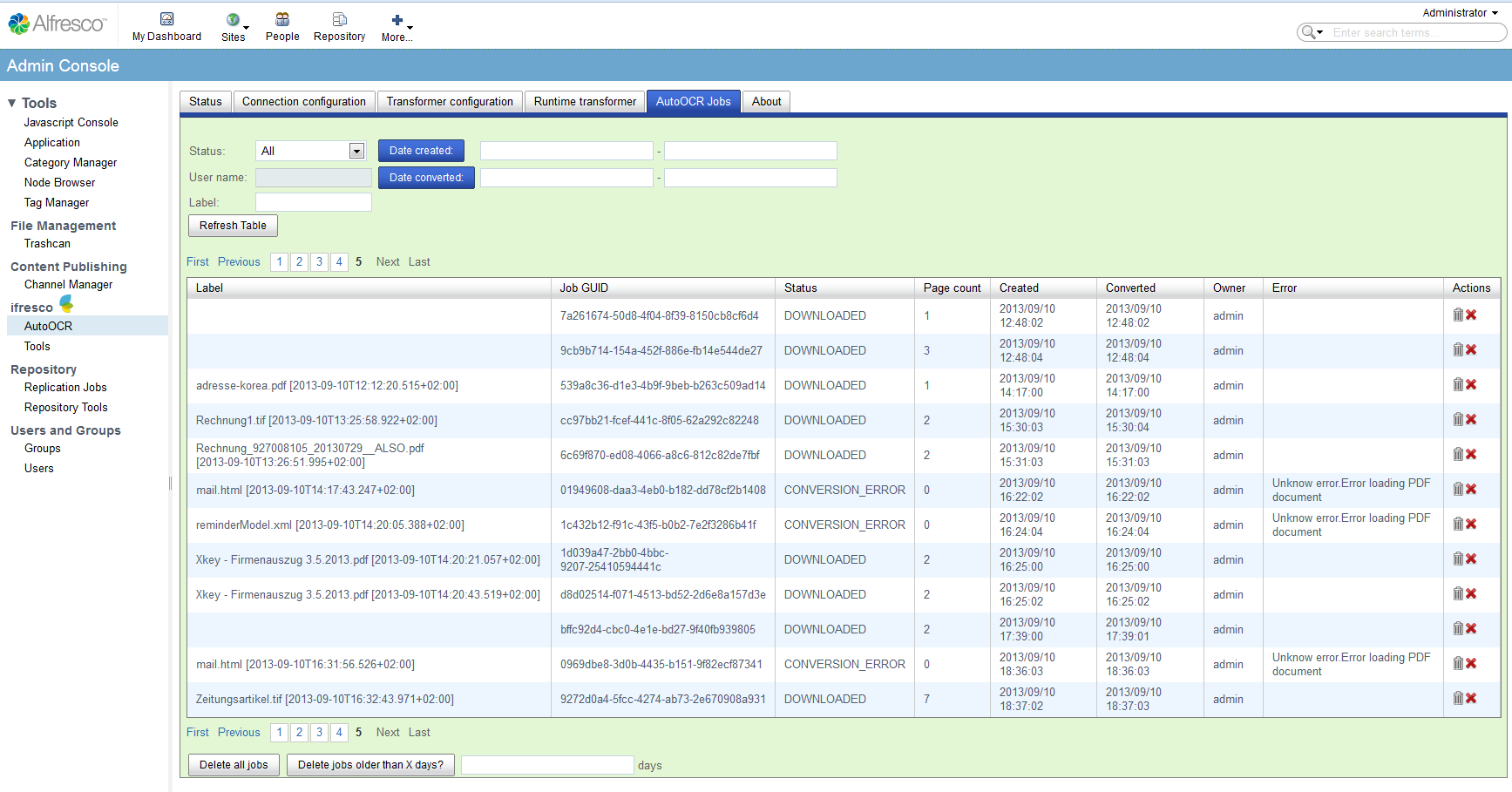
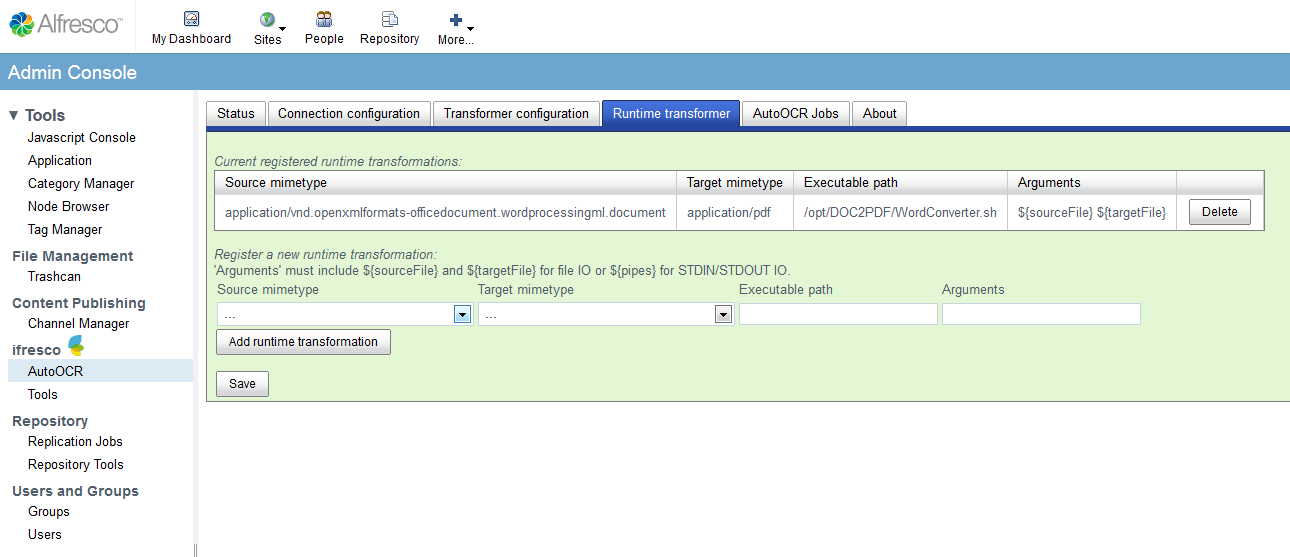
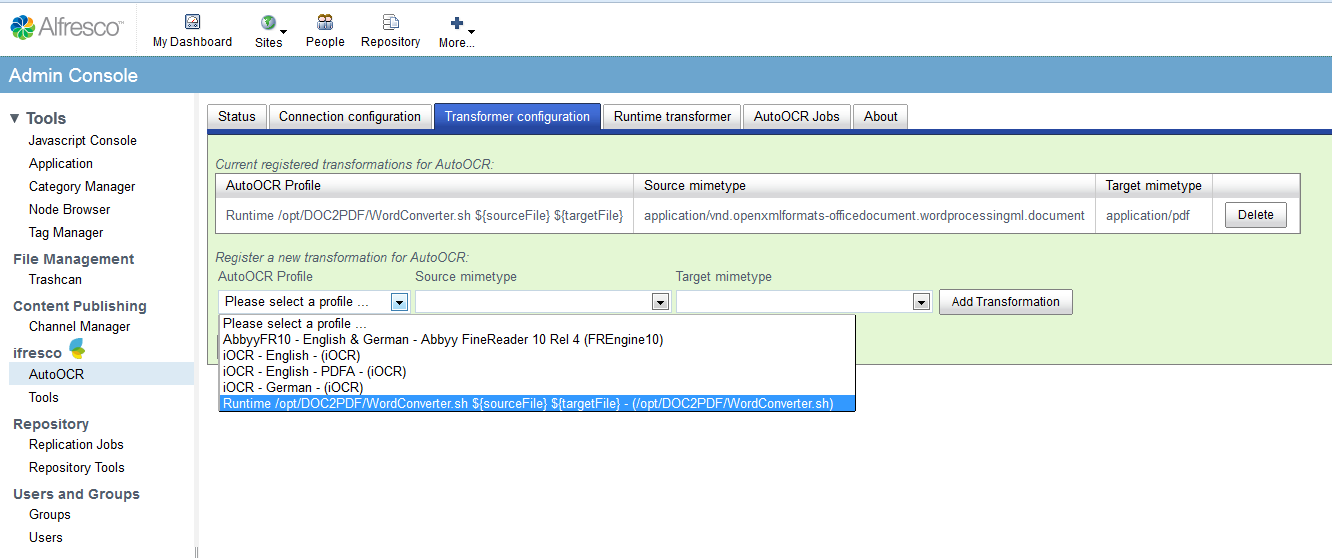
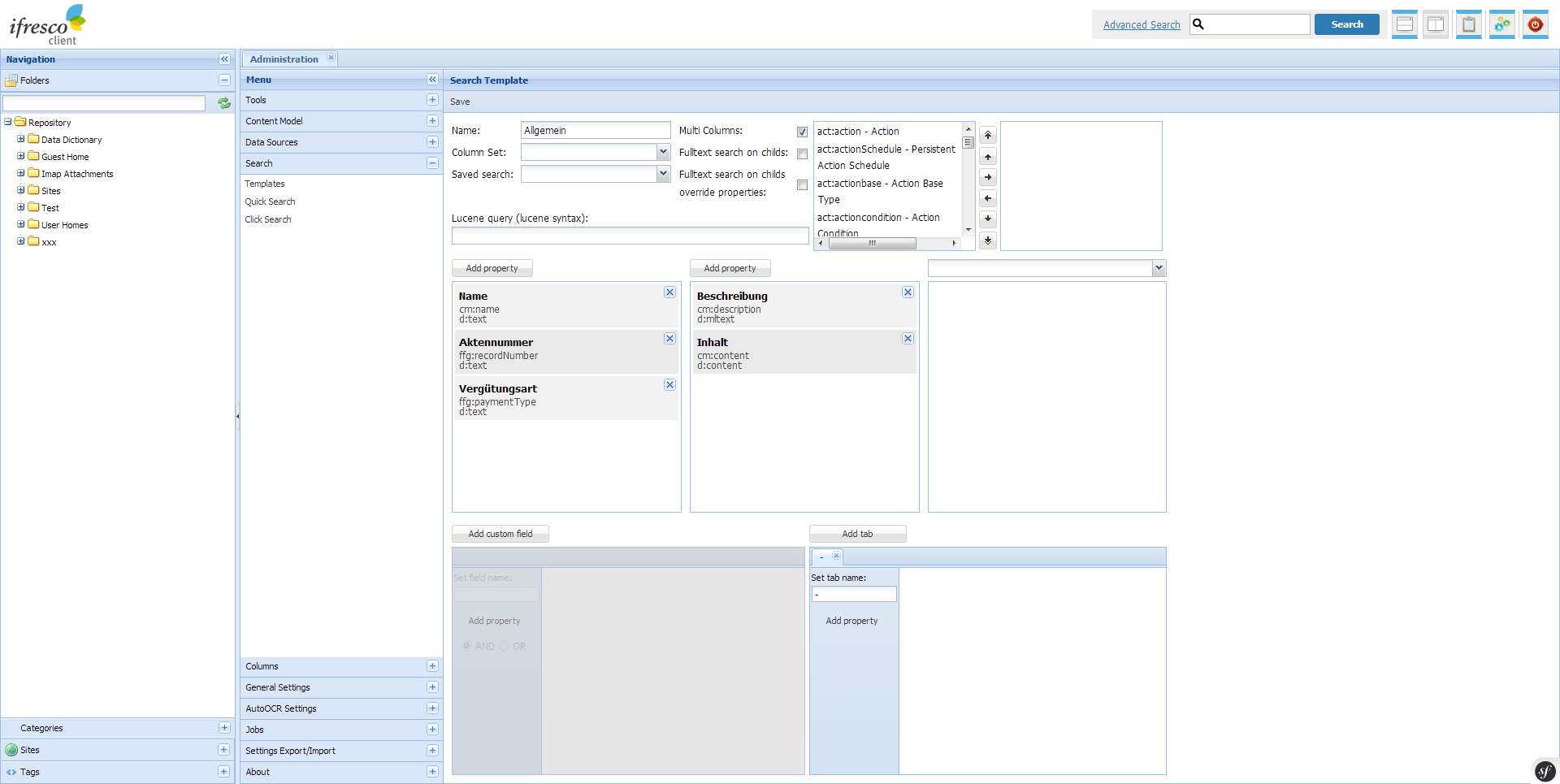
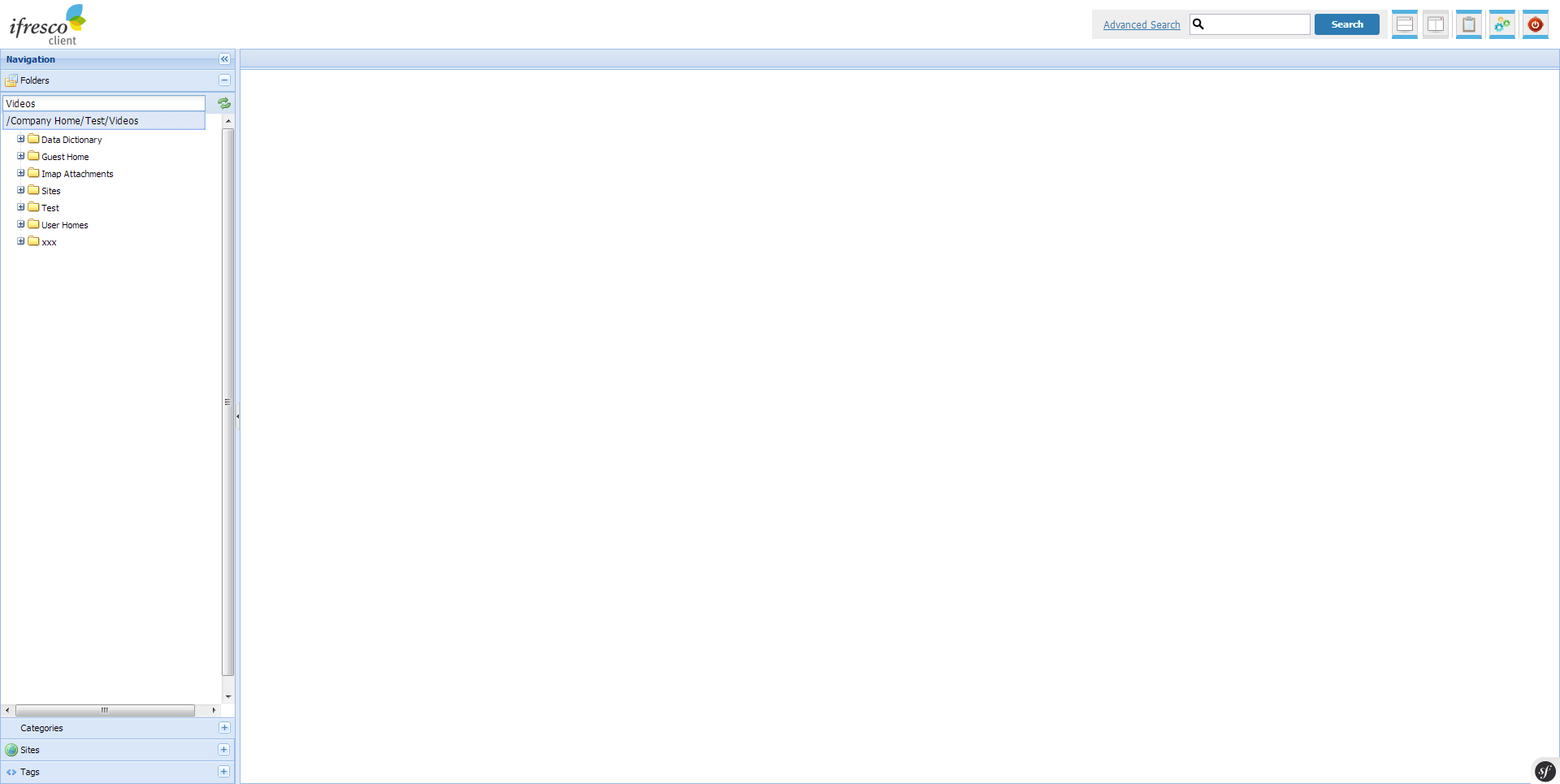
We work on a new version of the ifresco Client for the Alfresco DMS/ECM OpenSource Software and there are already the first screenshots of the new version.
Some of the coming innovations:
- The JavaScript programming is only based on ExtJS. Until now also jQuery was used.
- The new version uses the recent version of the PHP framwork – Symfony
- For the search and for the document- and treeview individual server side JavaScripts in the Alfresco repository get used.
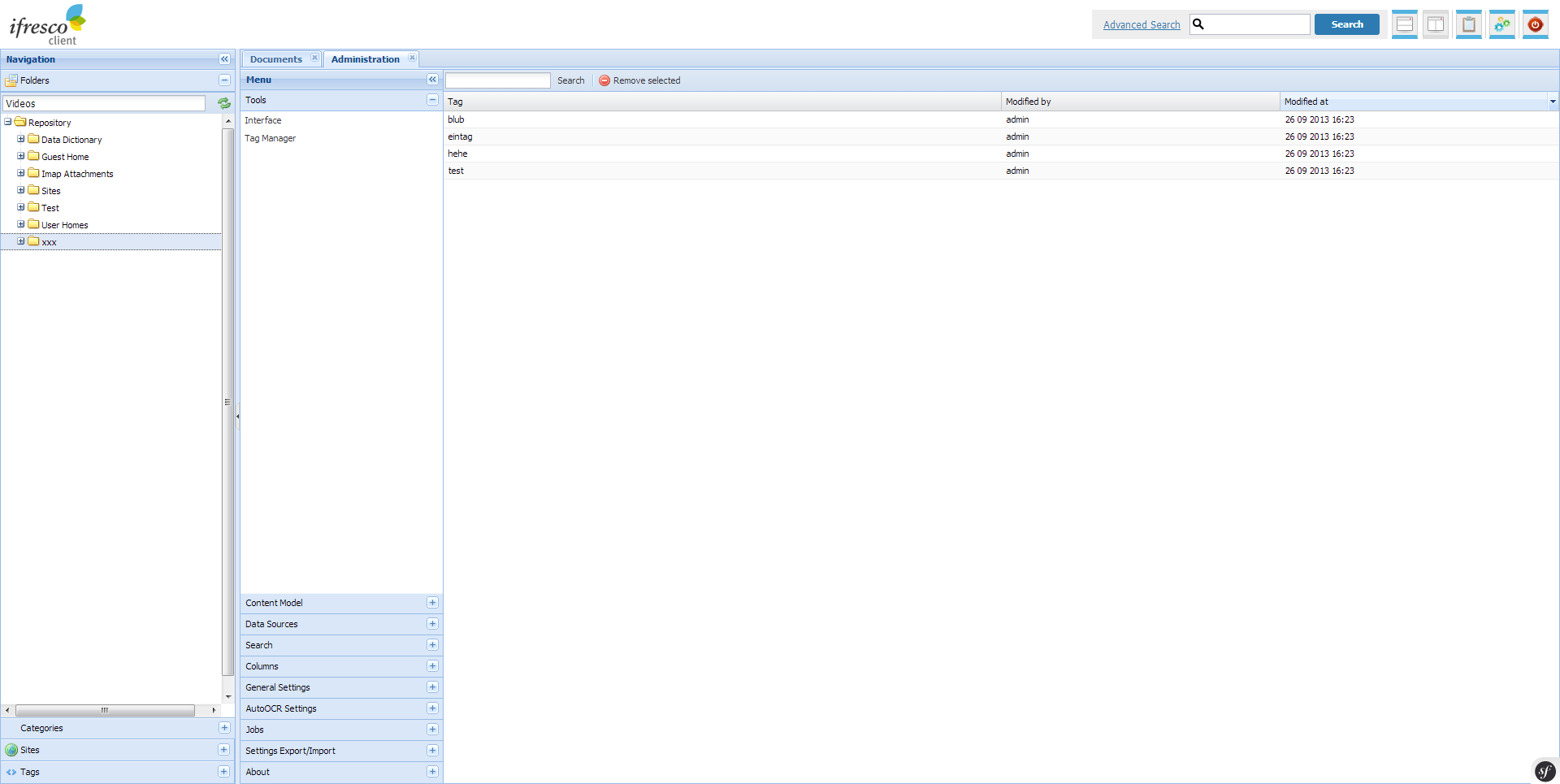
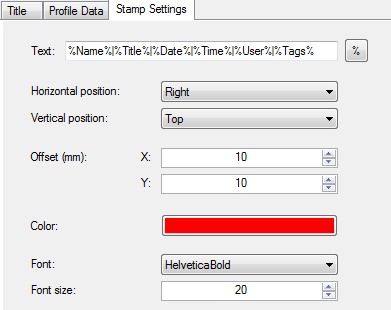
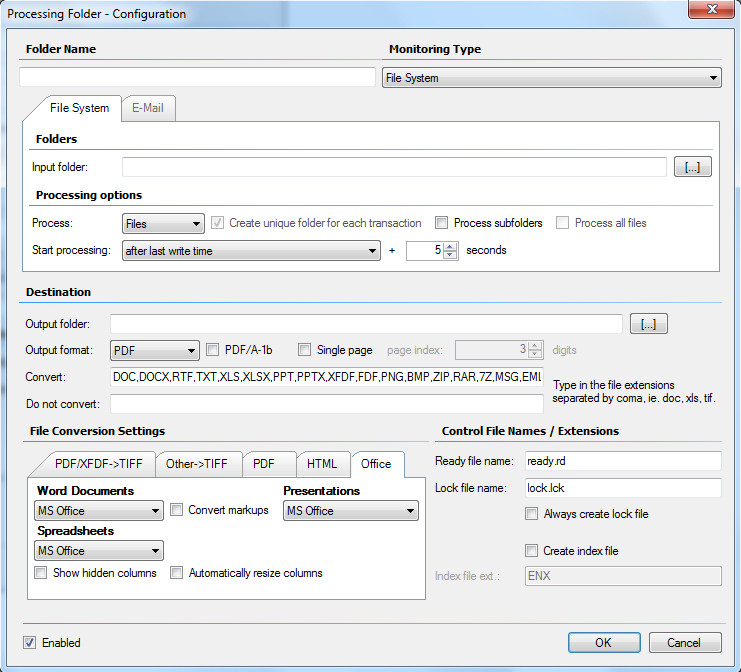
- Essentially improved and revised user interface for the administration and configuration.
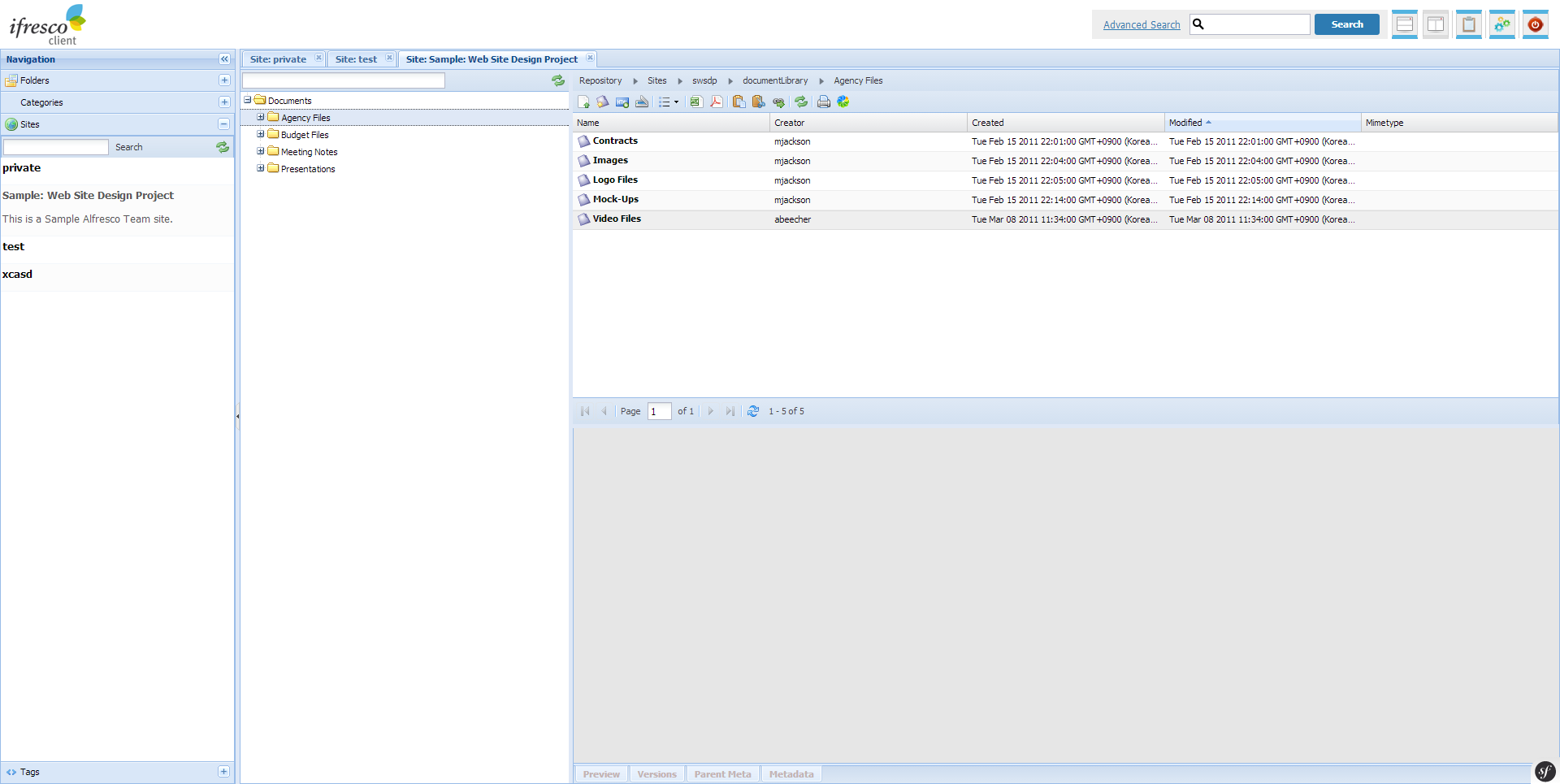
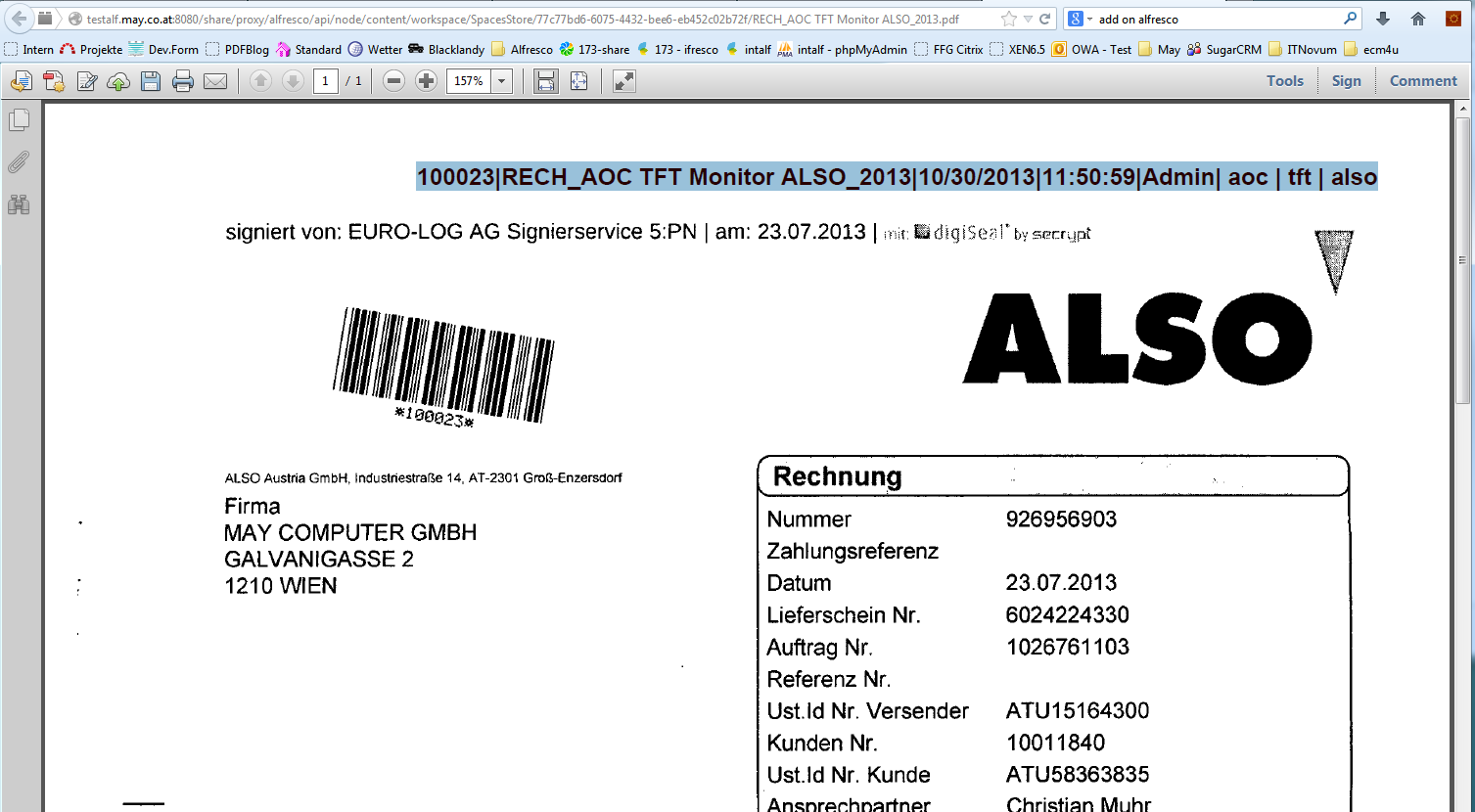
- Search and view of document libraries of the Alfresco sites is supported.
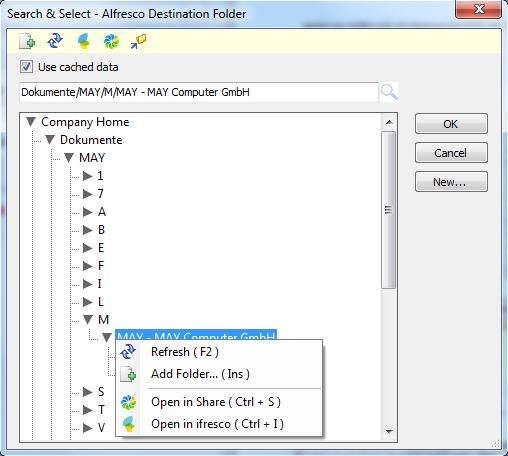
- Direct search for folders to be able to quickly choose the folder in extensive folder structures.
- Tag Manager – Creating and managing of the Alfresco tags.

![]()