SplitBarcode – Recognize and read 1D / 2D barcodes, share PDF documents
SplitBarcode is used to recognize 1D / 2D barcodes in PDF documents or to split them into individual documents. The barcode information read out can be used via variables for naming and filing the newly created files. Metadata about the recognized barcodes can be generated individually for each PDF or as an XML, XLSX, CSV overall file.
Supported 1D / 2D Barcode Types: Australian Post, Aztec, Codabar, Code11, Code128, Code16K, Code39, Code93, DataMatrix, DotCode, DutchKIX, EAN13, EAN13Plus2, EAN13Plus5, EAN8, EAN8Plus2, EAN8Plus5, HanXinCode, IATA2of5, IntelligentMail, Interleaved2of5, MailMark4StateC, MailMark4StateL, Matrix2of5, MatrixCode, MicroPDF417, MicroQR, MSI, PatchCode, PDF417, PDF417Compact, Pharmacode, Planet, Plus2, Plus5, Postnet, QR, RoyalMail, RSS14, RSS14Stacked, RSSExpanded, RSSExpandedStacked, RSSLimited, Standard2of5, Telepen, UPCA, UPCAPlus2, UPCAPlus5, UPCE, UPCEPlus2, UPCEPlus5.
SplitBarcode functions:
- Recognition and reading of 1D / 2D barcodes (51 barcode types).
- Split batches of documents into separate files.
- Delete blank pages.
- Generate XML, CSV, XLSX metadata files.
- Configuration is done through the SplitBarcode Editor to create templates (different settings and configurations), with multiple layouts linked to the template (different positions of the fields).
SplitBarcode Editor:One template contains all settings and configurations (fields, conditions, output, PDF info fields, barcodes). One or more layouts are associated with the template. A layout requires a PDF sample file on which the size and position of the fields defined by the template are specified.
SplitBarcode Template Editor – Features:
- Template – add, rename, copy, delete, import/export, Layout – add, rename, copy, delete.
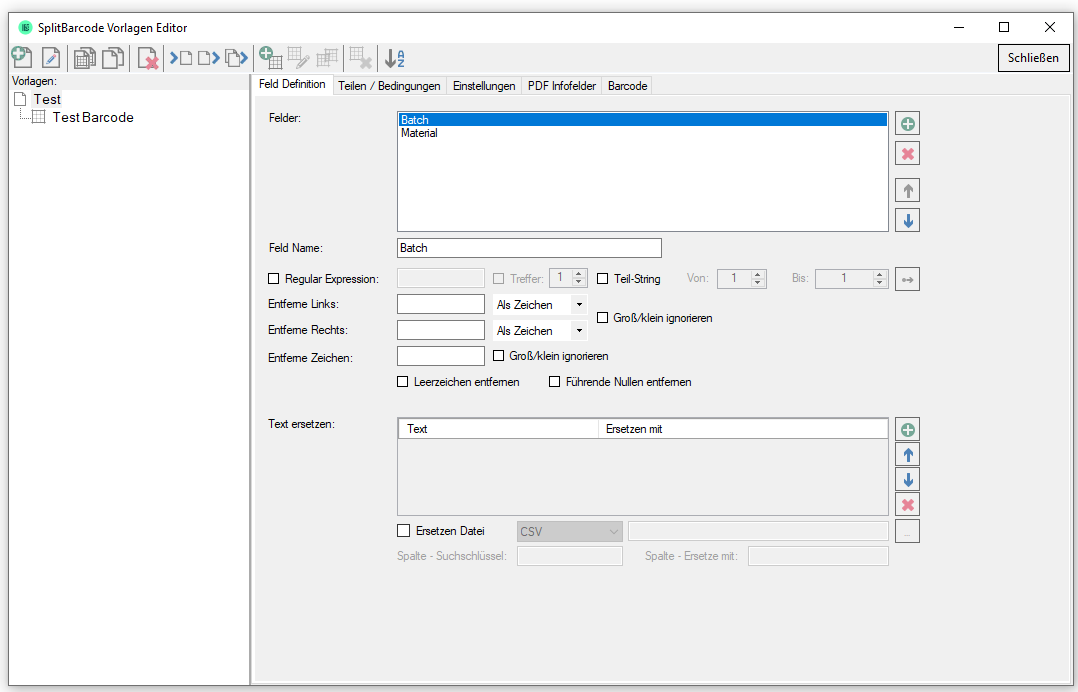
- Definition of fields to be able to use the read out barcode information via variables.
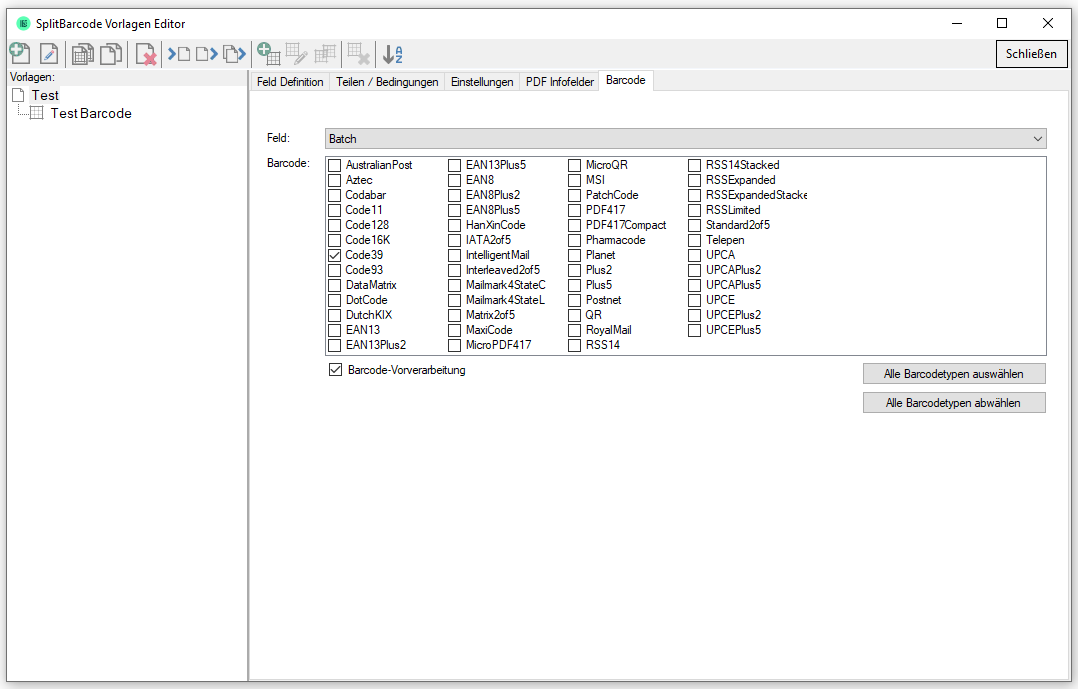
- Assignment of the barcode types to be recognized to the fields. For each field you can specify which of the 51 barcode types should be recognized.
- Preparation of the read barcode values ??via RegEx, remove: right / left / spaces / zeros, replace text via table or via external CSV / XLS file.
- In addition to the read value, further information is also available as “sub-variables” for each barcode field: bc_read – the originally read barcode, bc_processed – the barcode processed according to the configuration value, bc_page – the page on which the barcode was found, bc_type – the barcode type, bc_dir – the barcode orientation in degrees, bc_left – the barcode position on the left in mm, bc_top – the barcode position at the top in mm, bc_width – the barcode width in mm, bc_height< /strong> – the barcode height in mm,
- Identification and assignment of the documents to be processed via template / layout, based on conditions (AND / OR / NOT) and substring (*, #, ?) criteria.
- Split a batch of documents into individual files – by page number, by changing a field value or by criteria.
- Recognition and removal of blank pages by setting a maximum percentage of black
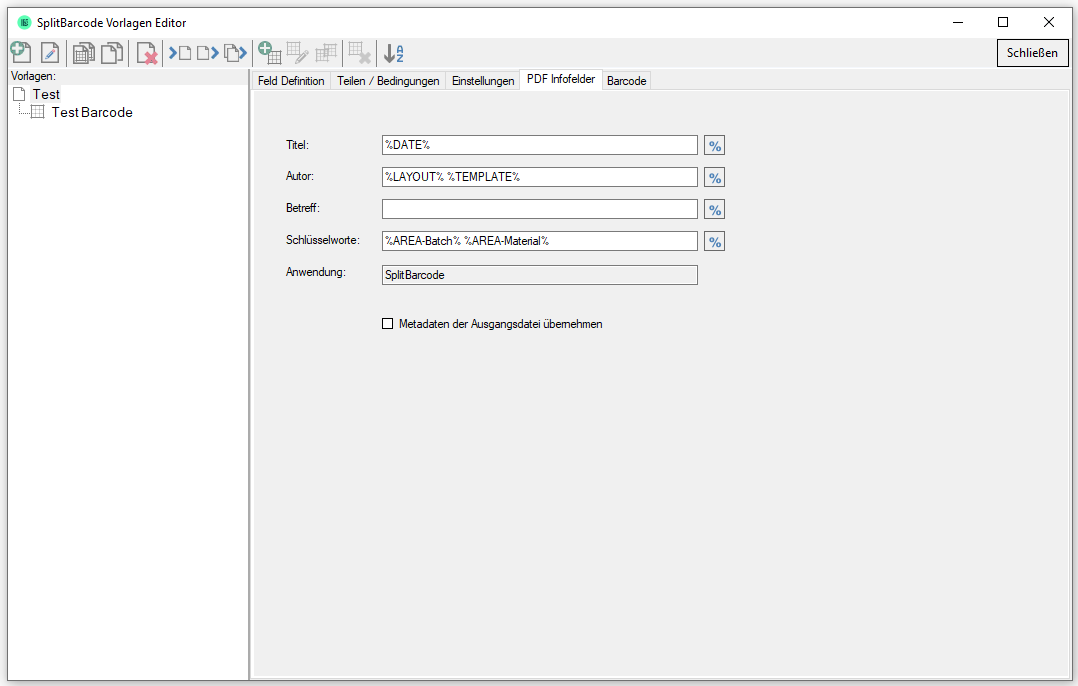
- Filling out the PDF information fields (title, author, subject, keywords) with text or via read-out field values.


SplitBarcode Layout Editor – Features:
- Select / save PDF sample file (prototype), select page, up, down, zoom, view selection.
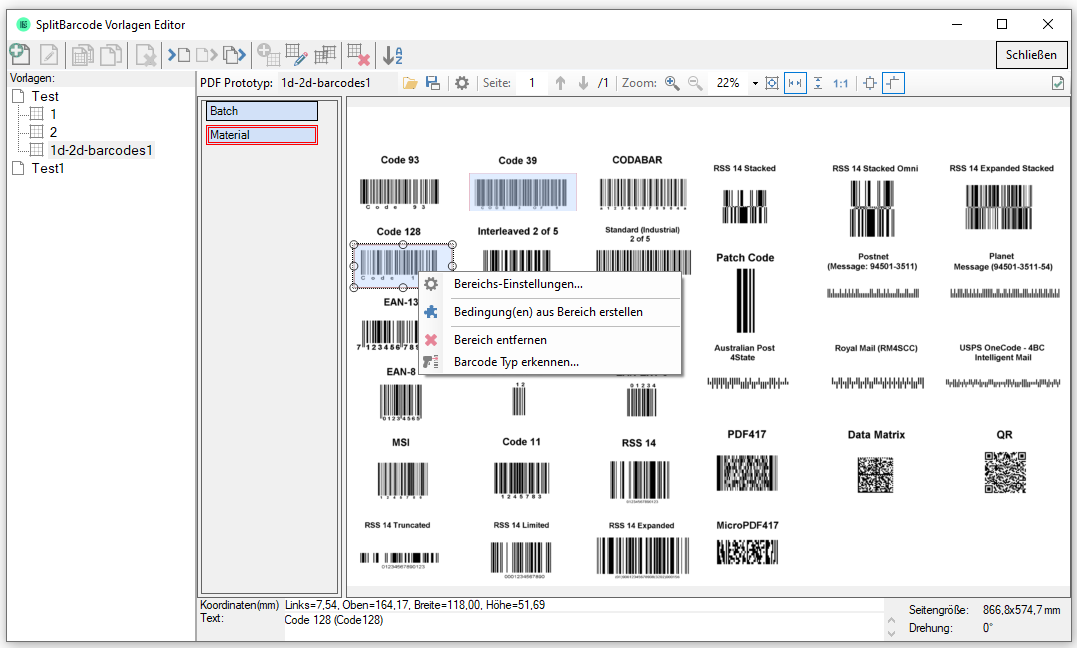
- For each layout, the defined fields can be positioned visually / interactively on a loaded PDF sample file and their size can be specified.
- Display for positioned fields: position, size, barcode value, barcode type
- Field Functions: Automatically detect barcode type, create condition from field and insert into condition editor.
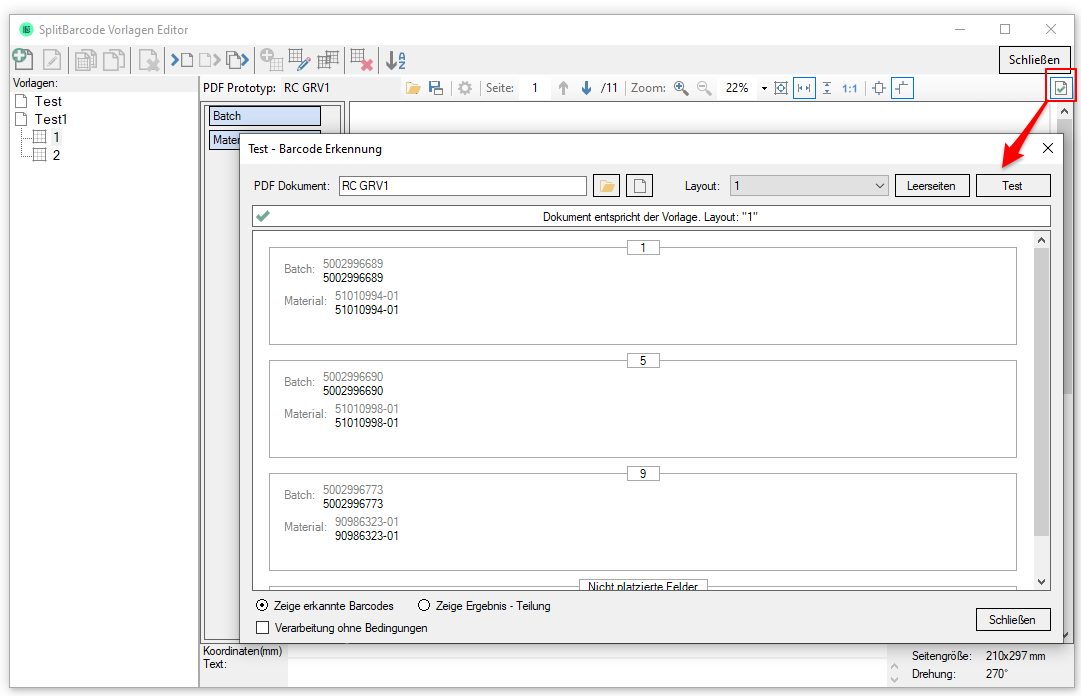
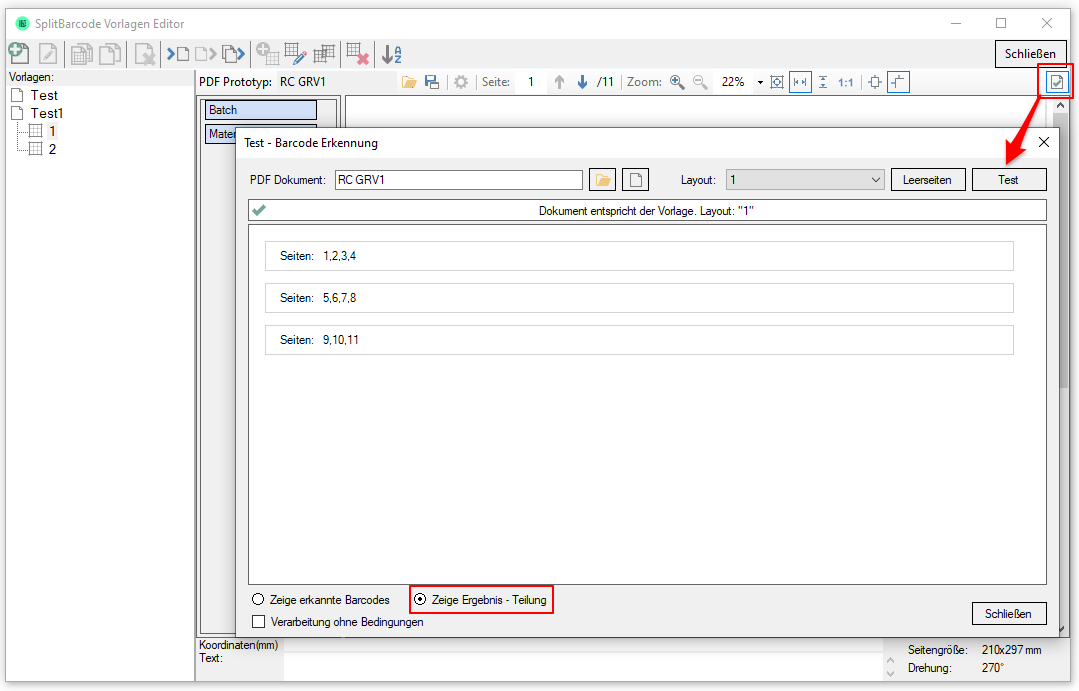
- SplitBarCode Layout Editor test function – tests the current configuration against the PDF prototype or against other PDF files – tests the criteria for recognition and sharing. The recognized layout, the field values read out and prepared, the pages on which the document is divided and the pages to be deleted are displayed.


SplitBarcode Processing:
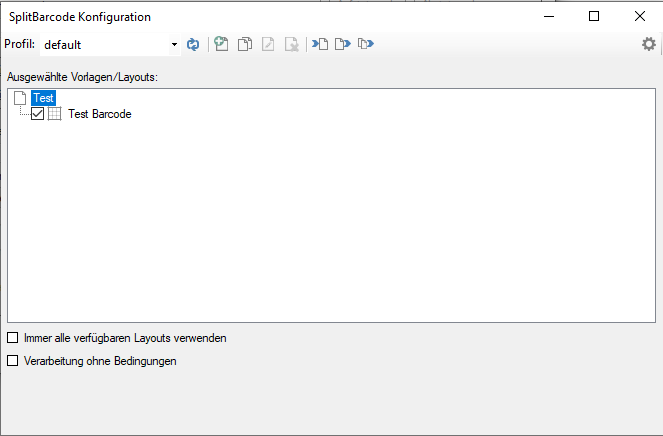
- The templates / layouts to be used are activated for processing and can be managed via profiles.
- The PDF document to be processed is validated against all activated templates / layouts according to the defined criteria. If a criterion applies, the document is processed according to the template definition. If no criterion applies, an error is thrown or the file is moved to the error folder.
- PDF file output – Configuration of destination path and filename using the defined fields/variables. Overwrite, filename count and append can be configured for existing files.
- Metadata Output: Configuration of target path and filename using the defined fields/variables. Output as XML, XLSX, CSV file, as a complete file or as a single file per generated PDF, column definition for the XLSX / CSV file via field / variable selection.
SplitBarCode Applications:
- SplitBarCode – .NET / C# test application to test the functions interactively. Drag & Drop processing one or more PDF files.
- SplitBarCode-CL – Command line application for client / server.
- SplitBarcode-FM – MS-Windows folder monitoring service.
- SplitBarCode-CS – REST / SOAP web service – result is returned as a single ZIP file.
- DropSplit – Interactive workspace application for drag & Drop or via a single watched folder.
- eDocPrintPro SplitBarCode Plugin – Barcode recognition and splitting into individual files via the eDocPrintPro printer driver.