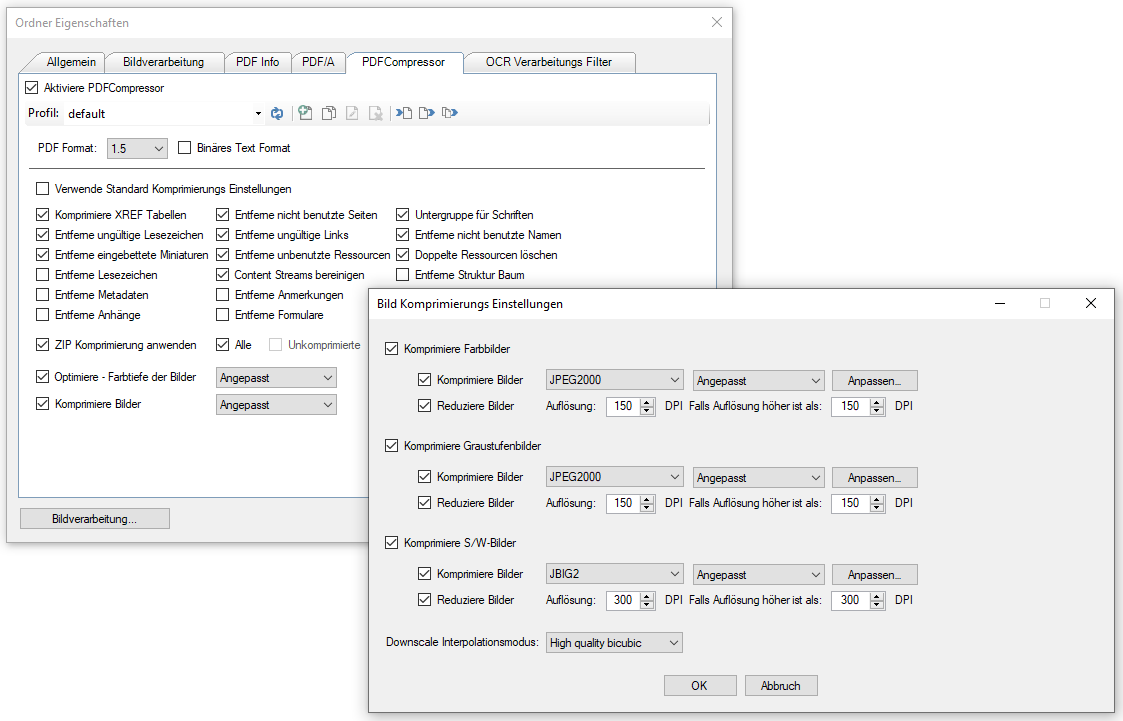
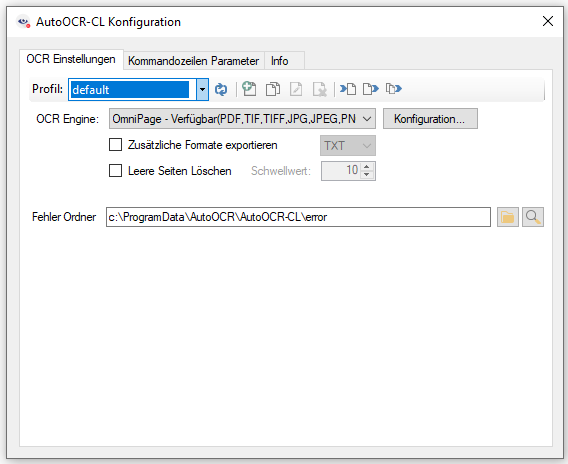
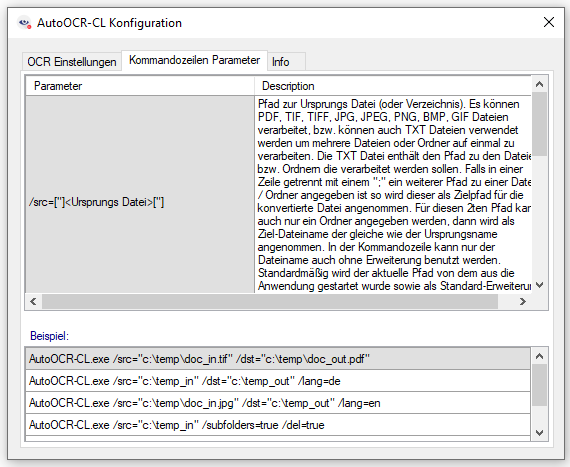
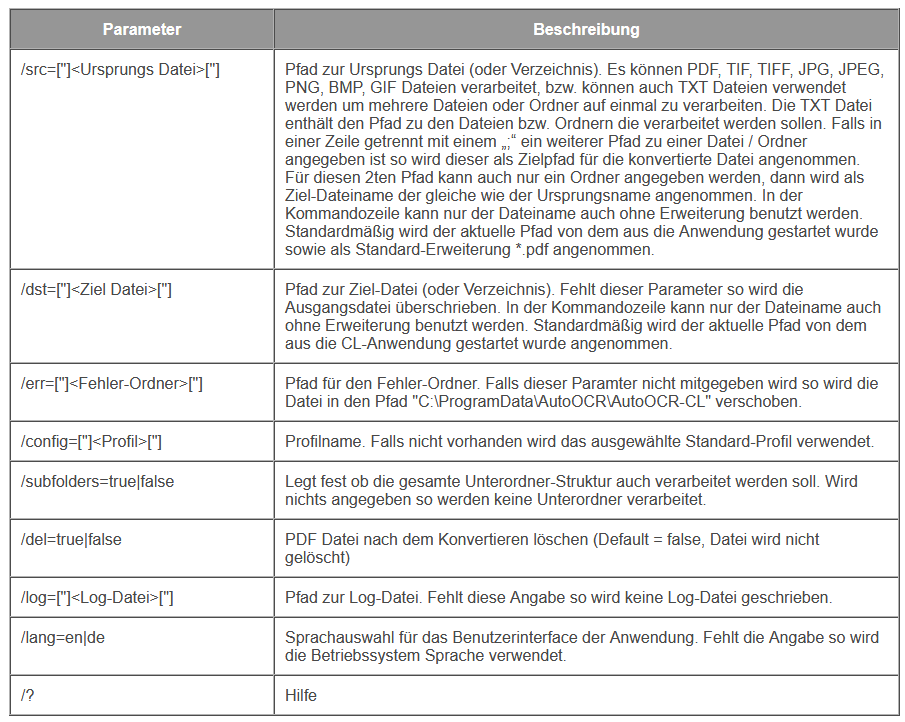
AutoOCR & AutoOCR light Version 2.0.41
Innovations AutoOCR & AutoOCR light 2.0.41:
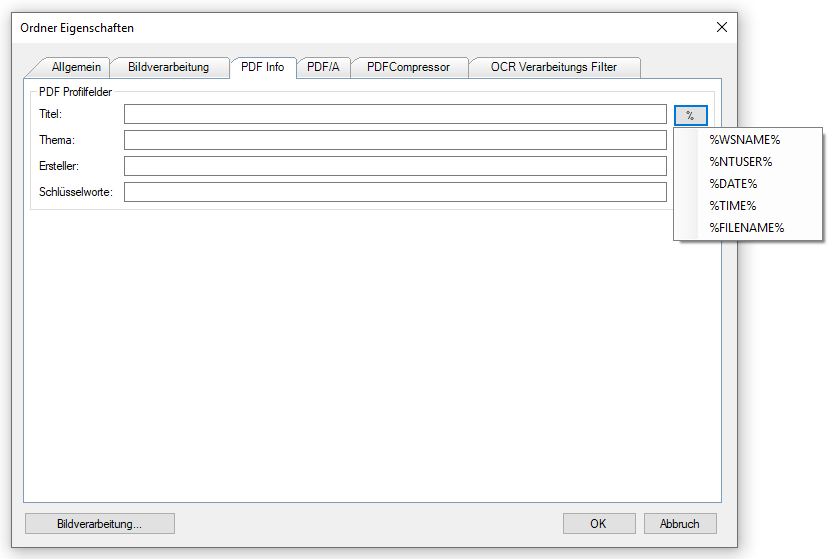
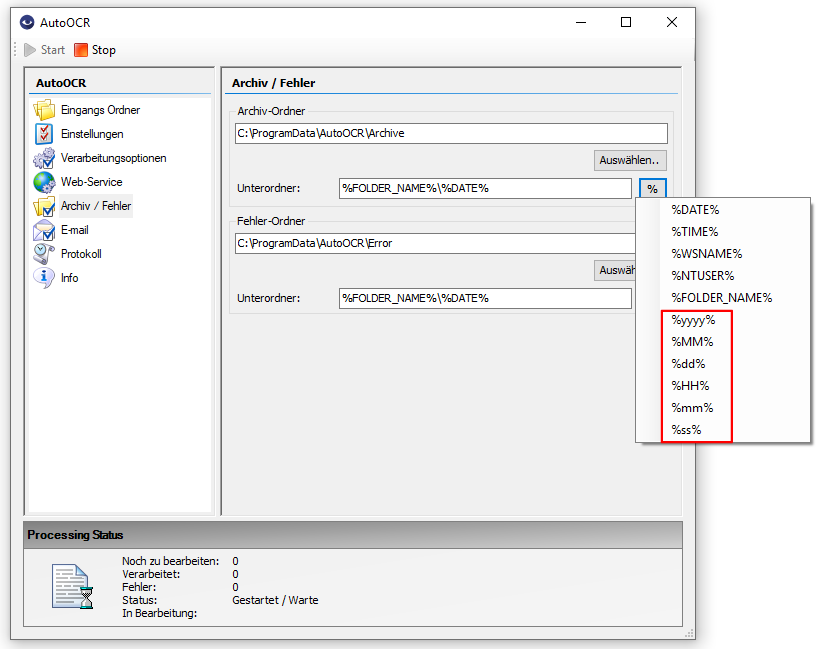
- Target file name / folder via variables: Some variables can now be used for the output file name and for the output folder. The configuration takes place in the field for output file names. By using “\”, a folder structure can be specified in the field, which will be created under the selected output start folder.
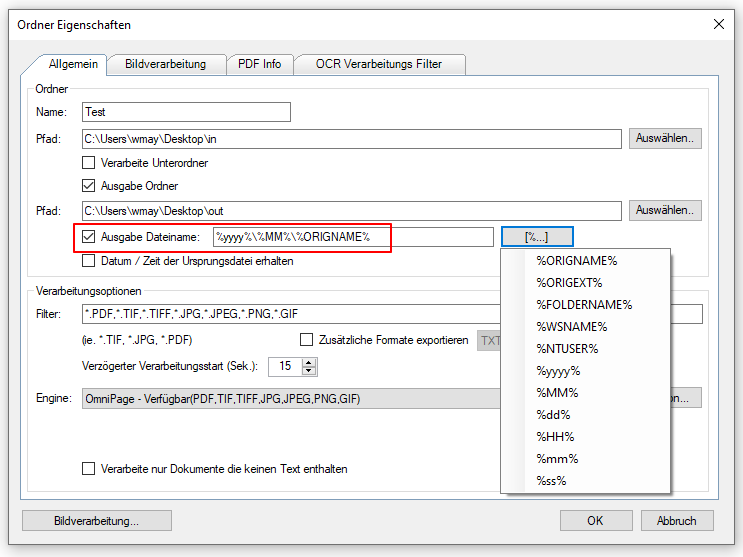
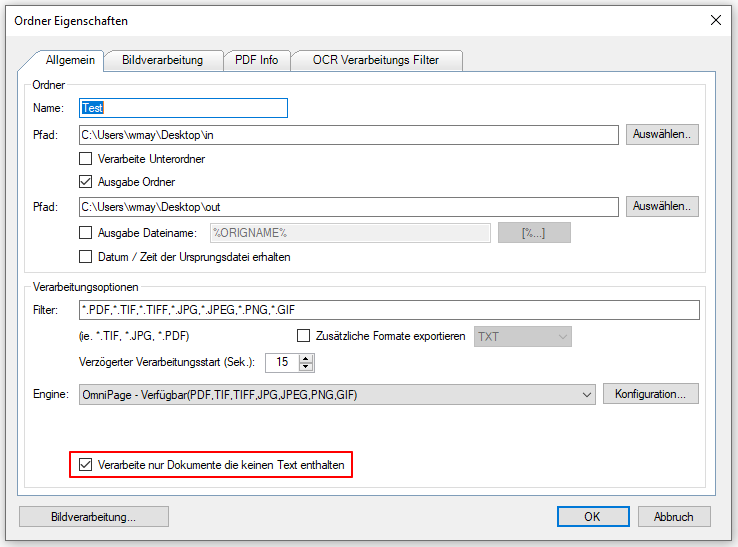
- Eliminating PDF that already contain text: The “intelligent” OCR processing can recognize whether a PDF requires OCR processing or not, but all PDFs from the monitored input folders are always processed and output in the target folder. However, if you only want to output PDFs that really require OCR processing, this distinction was not previously possible. With this new option, only those PDFs that have actually been OCR processed are output in the output folder. All other PDFs are, depending on the configuration, moved from the input folder, e.g .: directly to the archive folder and therefore do not end up in the output folder.
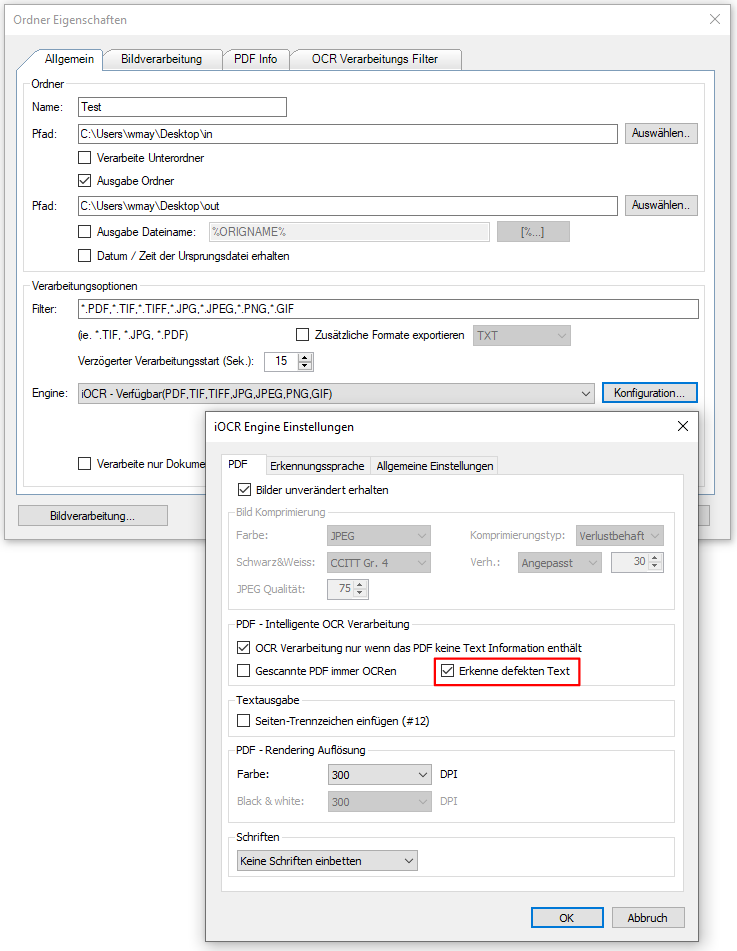
- Detect and correct defective text in PDF: Sometimes PDF contains text, but it is “defective”. The problem lies in the incorrect creation of the PDF. Texts / fonts are coded incorrectly or incompletely. The problem often occurs if an existing PDF is printed out again from a display program using a PDF printer driver in order to generate a PDF from it again.
In this case you can mark and copy the text in the PDF, but the extracted text cannot be used and only contains special characters and hieroglyphs. Such PDFs cannot be processed further in a meaningful way. No information can be obtained from the PDF, the PDF cannot be searched and the document cannot be found using full-text search or search engines. This cannot be seen from the outside. The PDF can be opened, viewed and printed out without any error messages.
The only way to restore such PDF and encode the text correctly is through OCR. The PDF or only the affected page is “rendered” and the text is regenerated using the OCR processing.
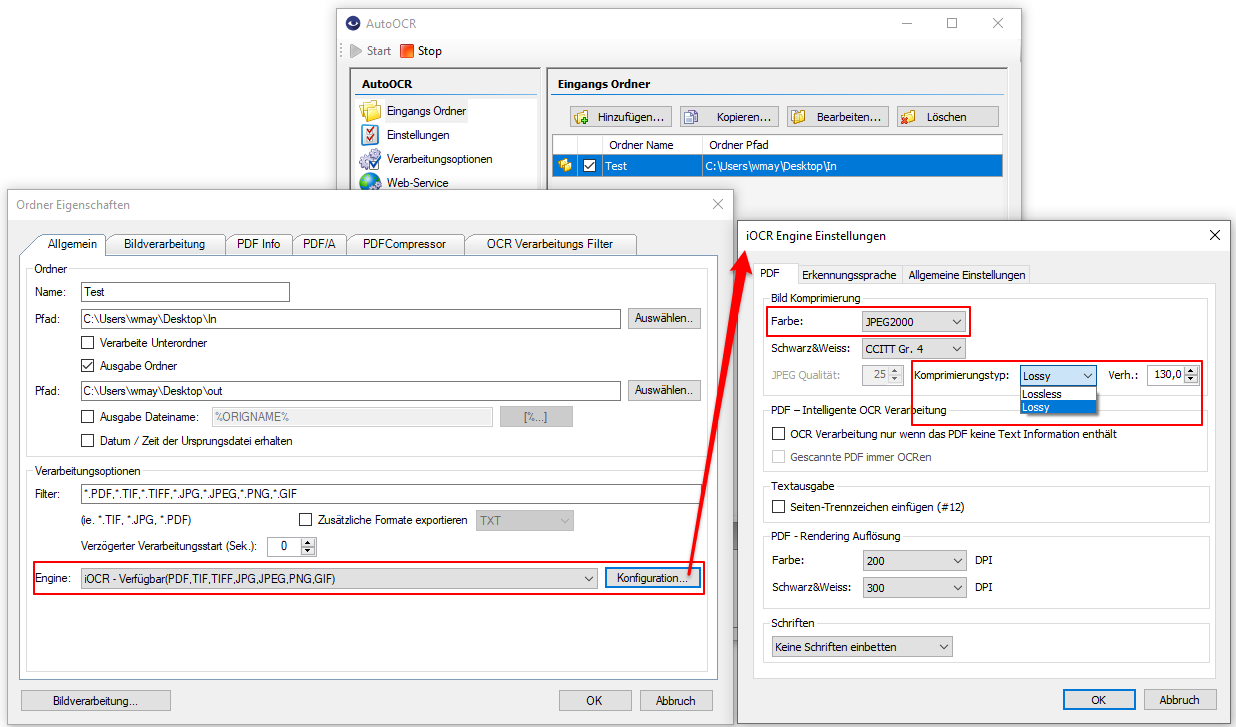
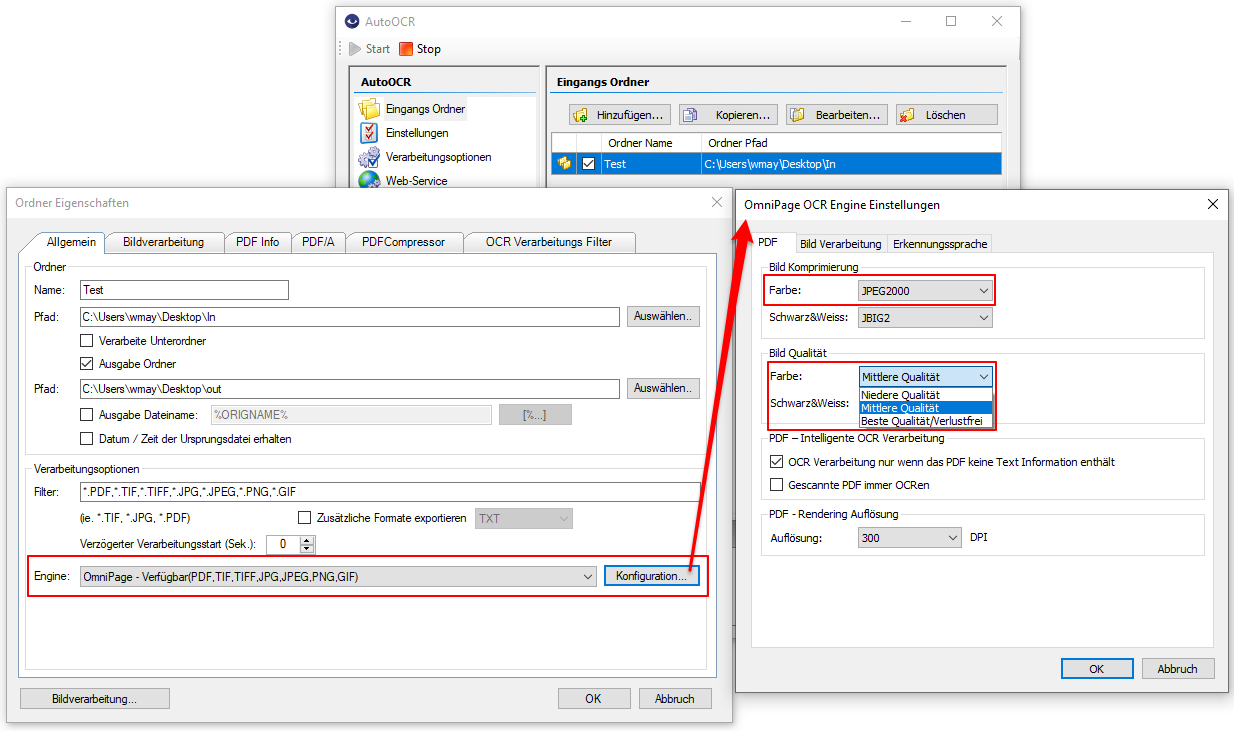
AutoOCR Version Version 2.0.41 offers this possibility for both the iOCR and the OmniPage OCR engine. It can be found out for each page of the PDF whether it contains “defective” text or not. If such a page is recognized, the text is regenerated using the OCR function; pages with correct text are not subjected to any further OCR processing.

Download – AutoOCR – OCR Server incl. OmniPage OCR (ca. 640MB) >>>
Download – AutoOCR light – Low Cost OCR Server (ca. 410MB) >>>
Download – iOCR (vsOCR) Setup – additional languages (ca. 1200MB) >>>