PDFmdx – Version 2.2.1 – with many enhancements and new features
With version 2.x and now with version 2.2.1 a variety of enhancements and new features have been implemented to PDFmdx.
Innovations PDFmdx Template Editor version 2.x:
Completely redesigned template editor – several layouts can now be assigned to a template. Until now had to be created a custom template per layout. EA template now summarizes all the layouts that contain the same fields and have to be processed in the same way. Example: To process input invoices there is a single invoice – template with fields – company, number, date, amount. Per supplier there is just one layout to reflect the different invoice forms. Layouts are recognized over conditions and define the fields on the form.
Stationery control via information from the document: PDFmdx can also apply a PDF stationery as an overlay or underlay to the generated documents. Field contents and criteria control different letterheads via the document content. The fields can also be used for generation of the name and path of the PDF stationery.

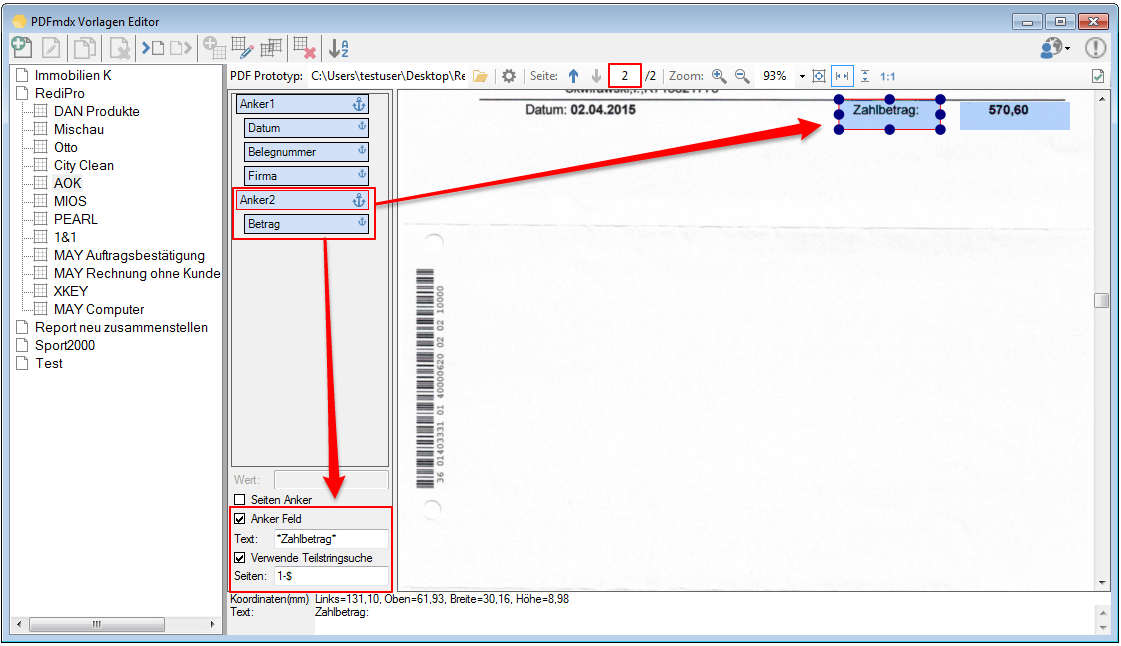
Anchor fields – Substring search and page ranges: Anchor fields are required in order to find reference points in a document to relate other fields absolutely to them. There is information which neither are always in the same place nor on the same page. EA typical example is e.g. the final amount of an invoice – this can be on the first, the last or even on an x any page. In addition, depending on the number of billing positions, the final amount may vary vertically. A fixed definition would not help here. Another challenge are scanned documents. Here, from document to document each field can migrate horizontally and vertically – Depending on how the document was placed and scanned in the scanner may result shifts and distortions. A fixed position definition would cause a high error rate.
In order to read and process the fields reliably, we have implemented the “anchor fields”. These fields are fixed points on which other fields can relate absolute – e.g. letter heads with company names or texts such as “Total” or “invoice amount” etc.
One or more anchor fields can be defined per layout, to which different fields can relate. The search for the anchor fields can be done by substring or fixed texts and it can be specified whether all or only certain pages should be searched.
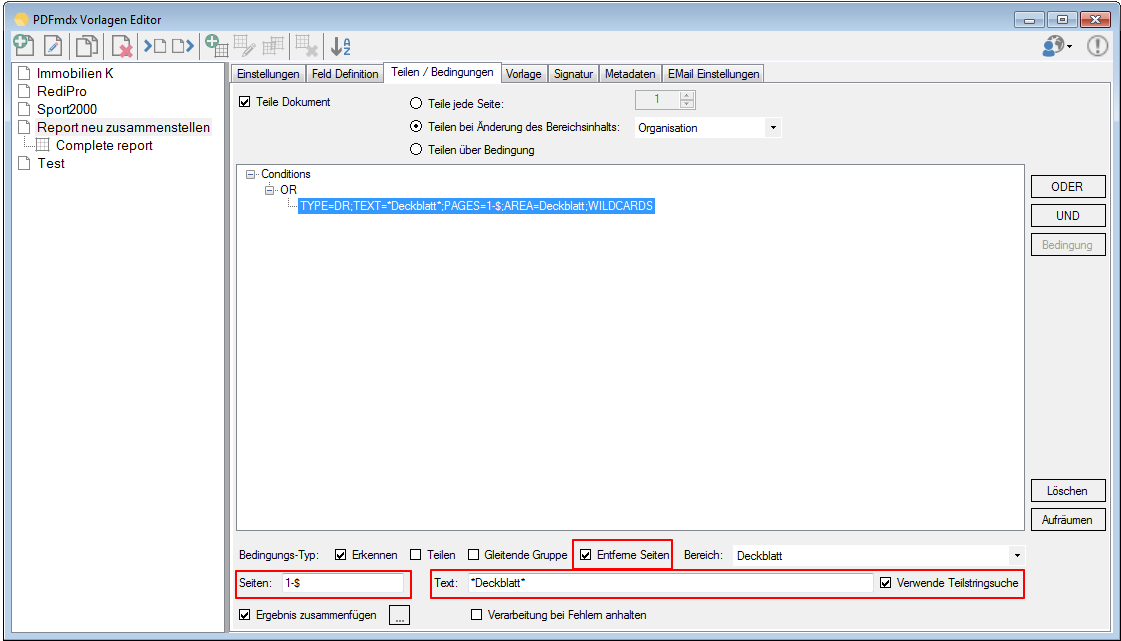
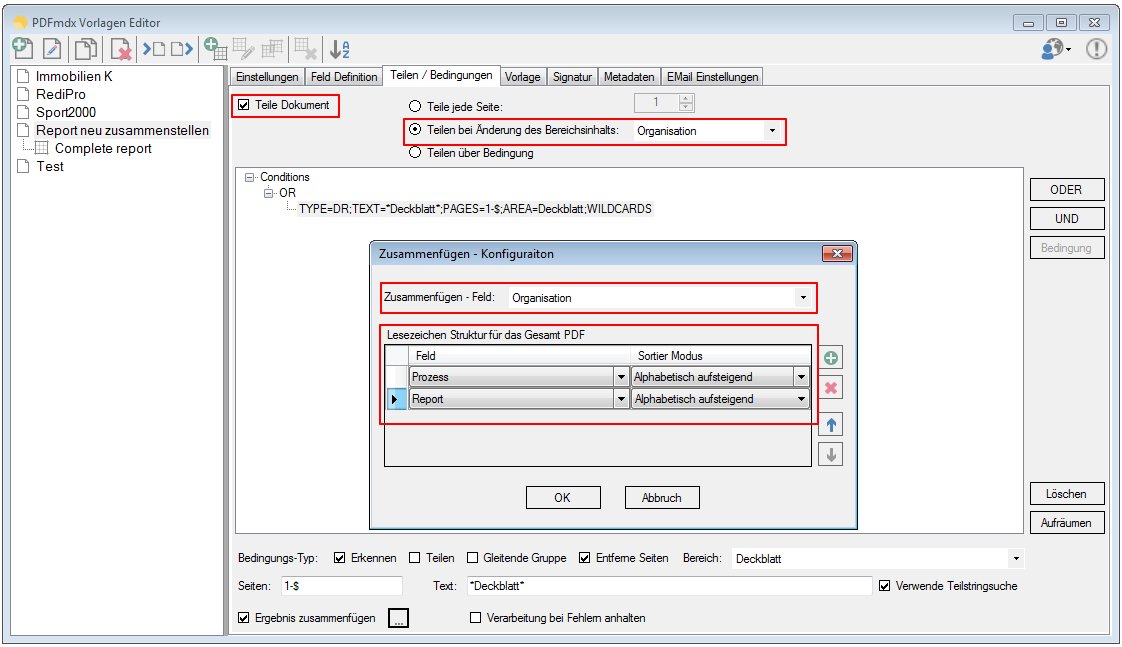
Delete Pages – Sometimes it is necessary to delete certain pages and not to take over in the target document. E.g. with cover or slip-sheets. The pages are like the layouts identified via conditions from the content.
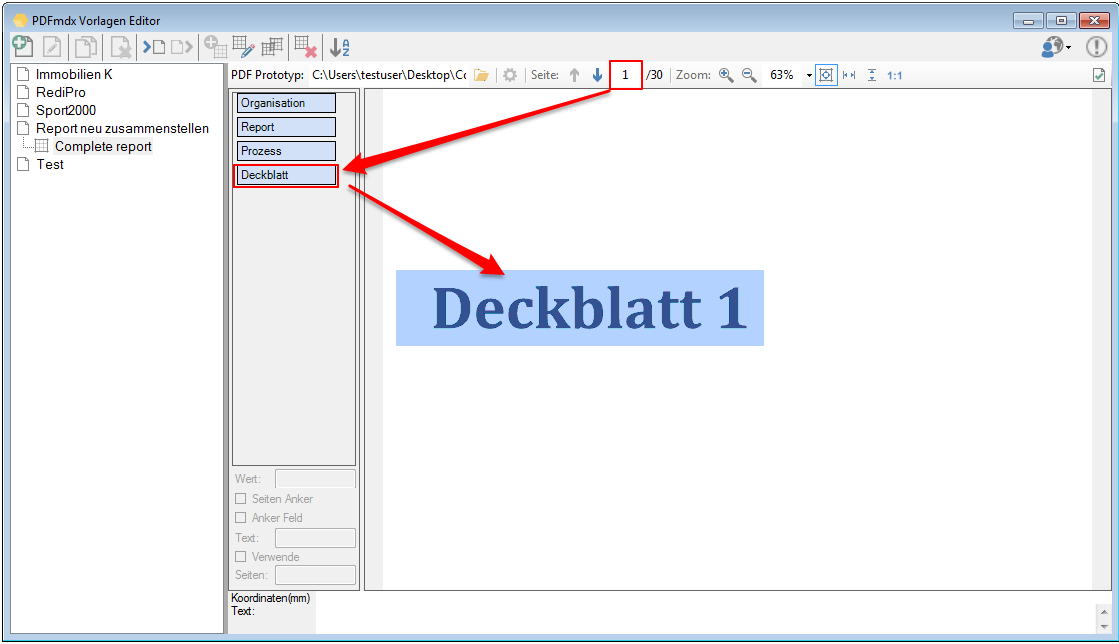
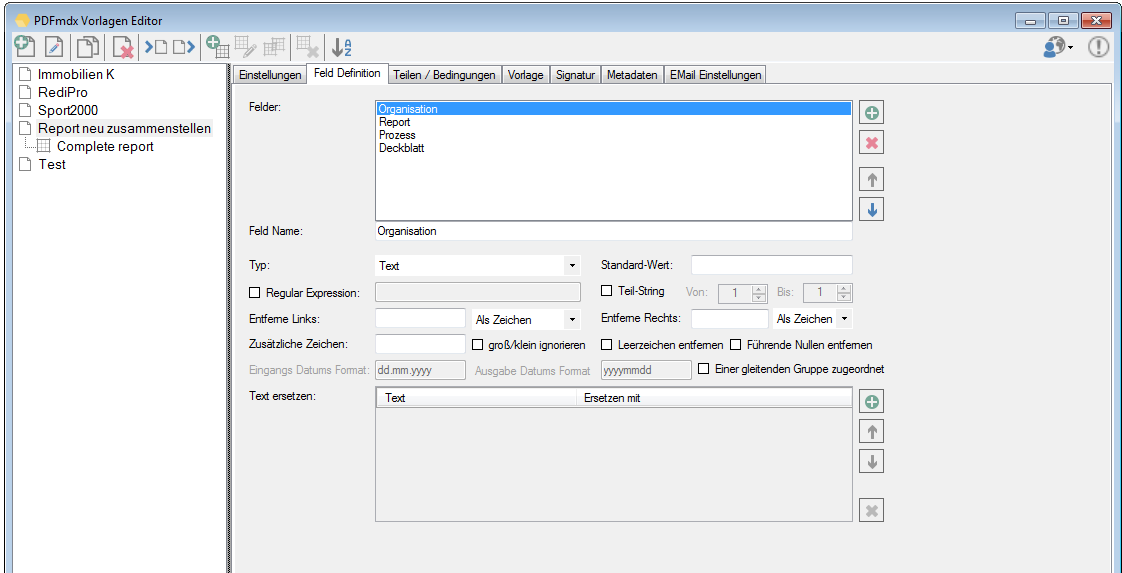
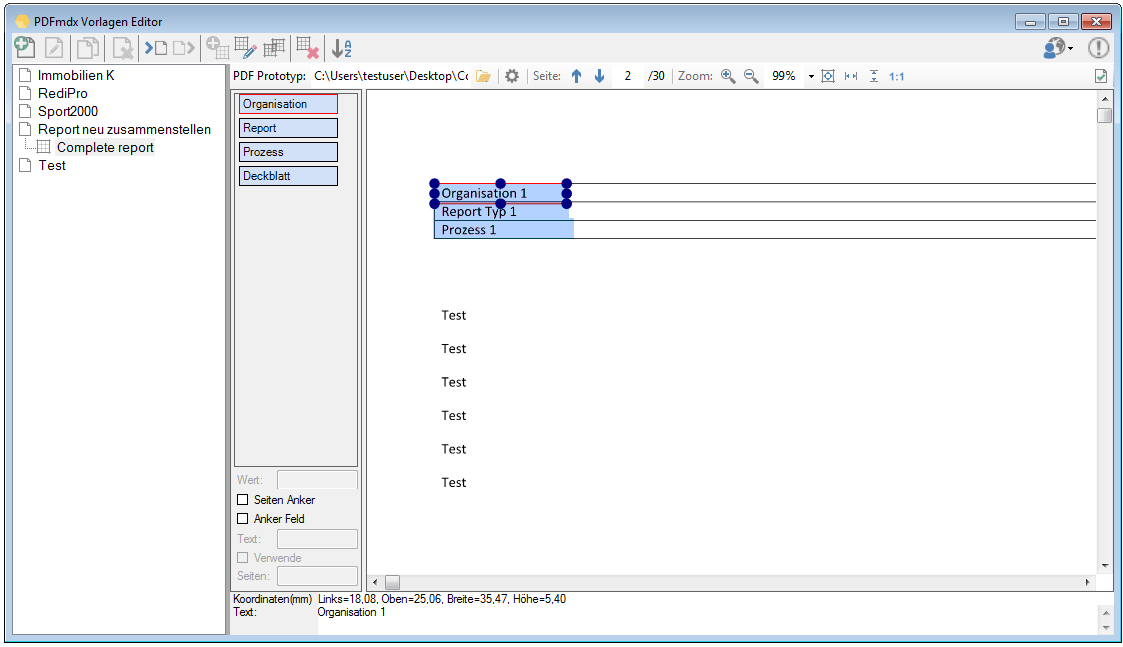
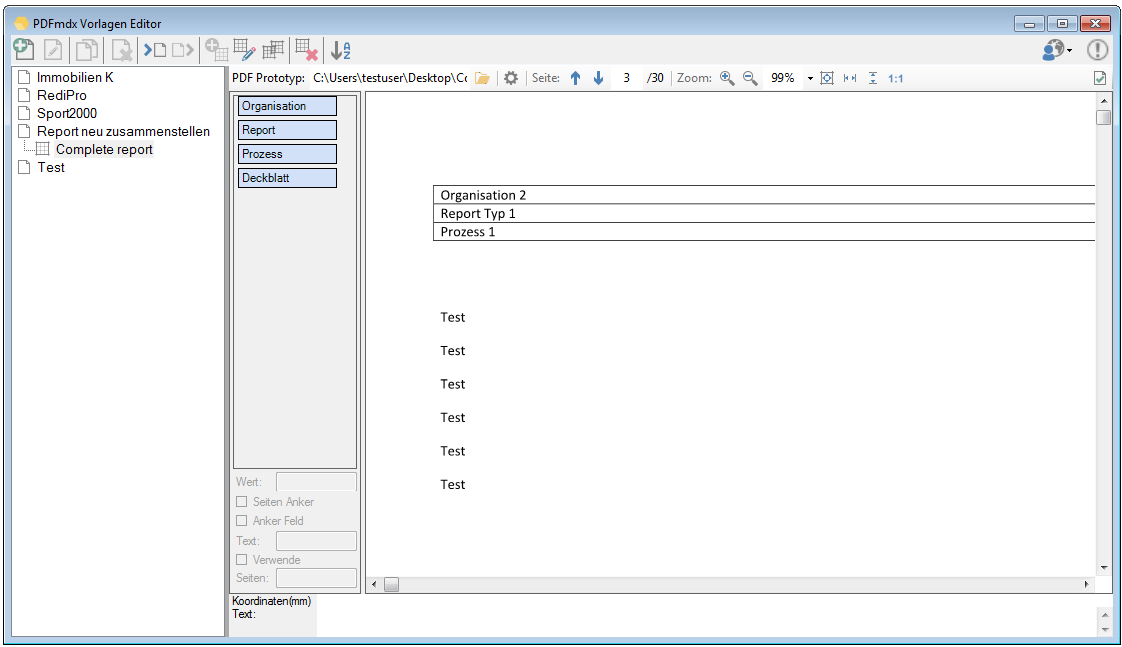
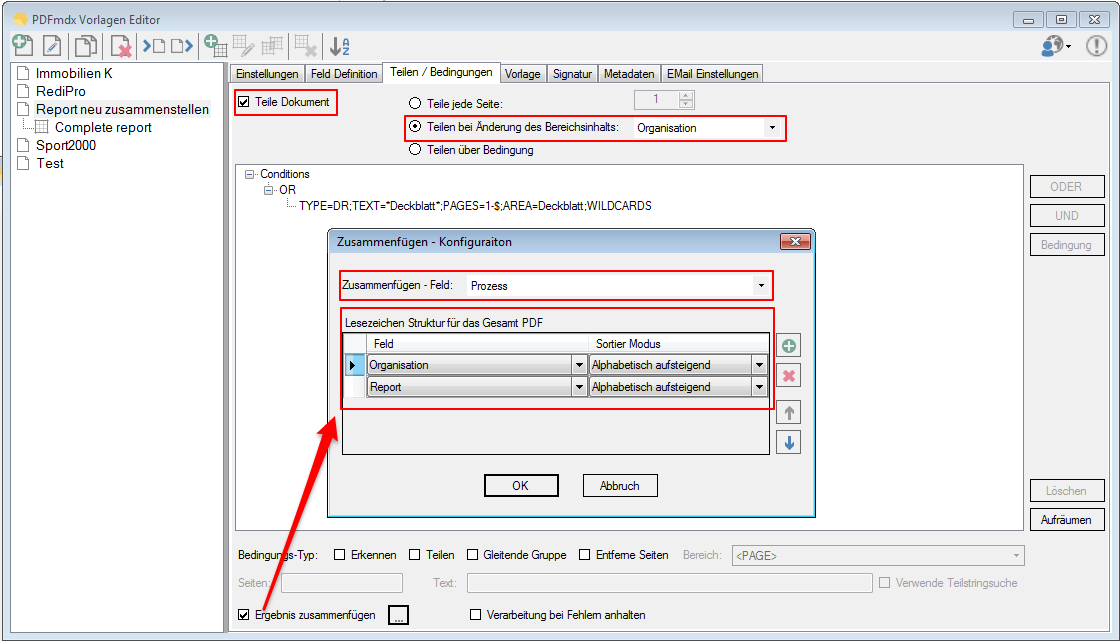
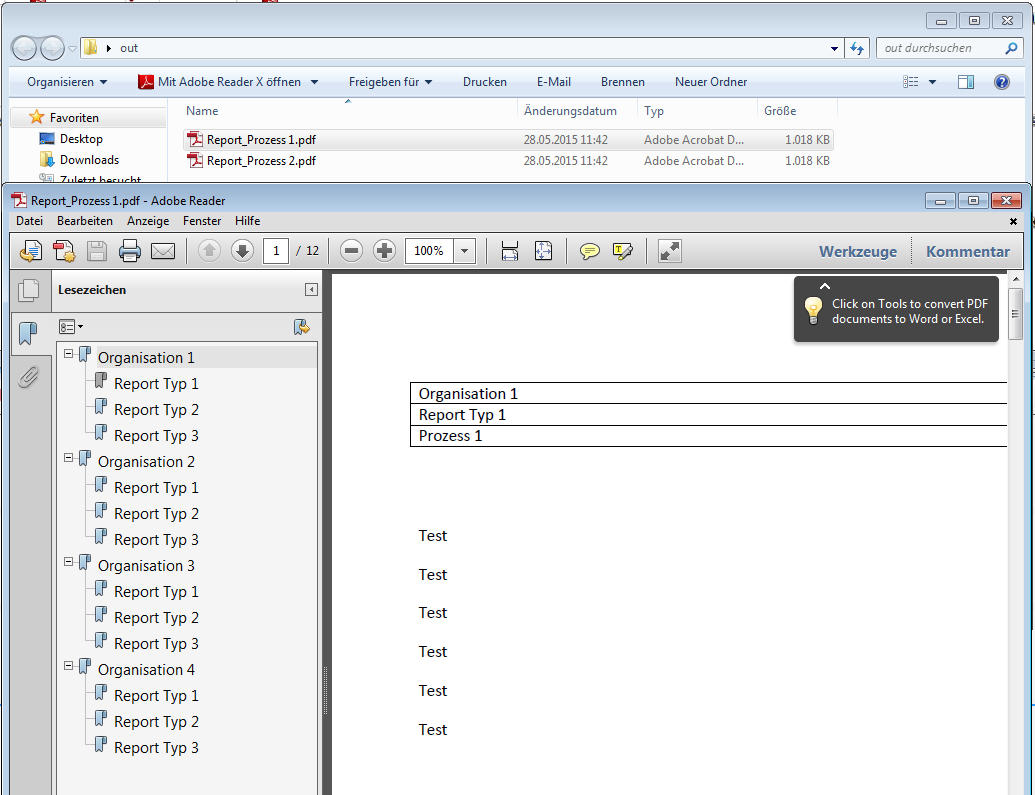
Split & Merge New: PDFmdx is able to split stacks of documents according to criteria in individual documents – e.g. via page number, via change of a specific field (eg invoice number) or via freely definable and / or criteria. A new addition is now a function, to reassemble these split documents, according to other criteria, to new documents. In the document, it can be re-sorted and structured via bookmarks according to data read from the document information. Thus, total reports can be split into single reports and newly reassemble and structure according to other criteria.

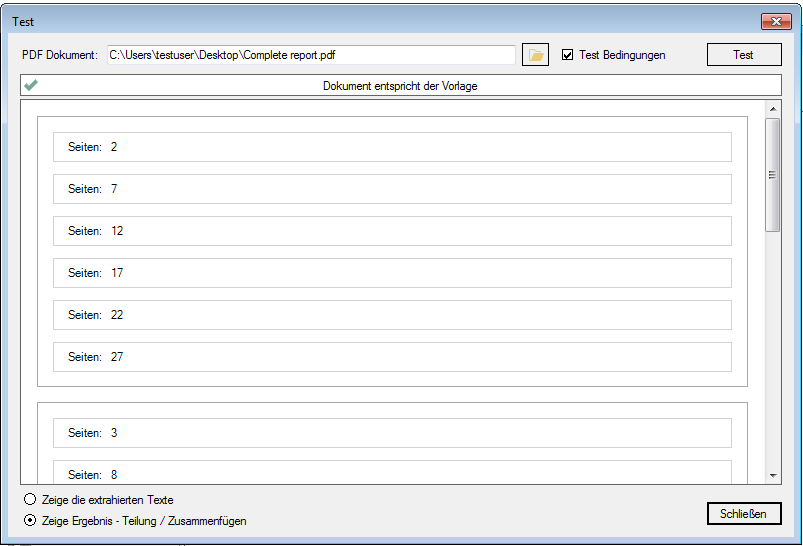
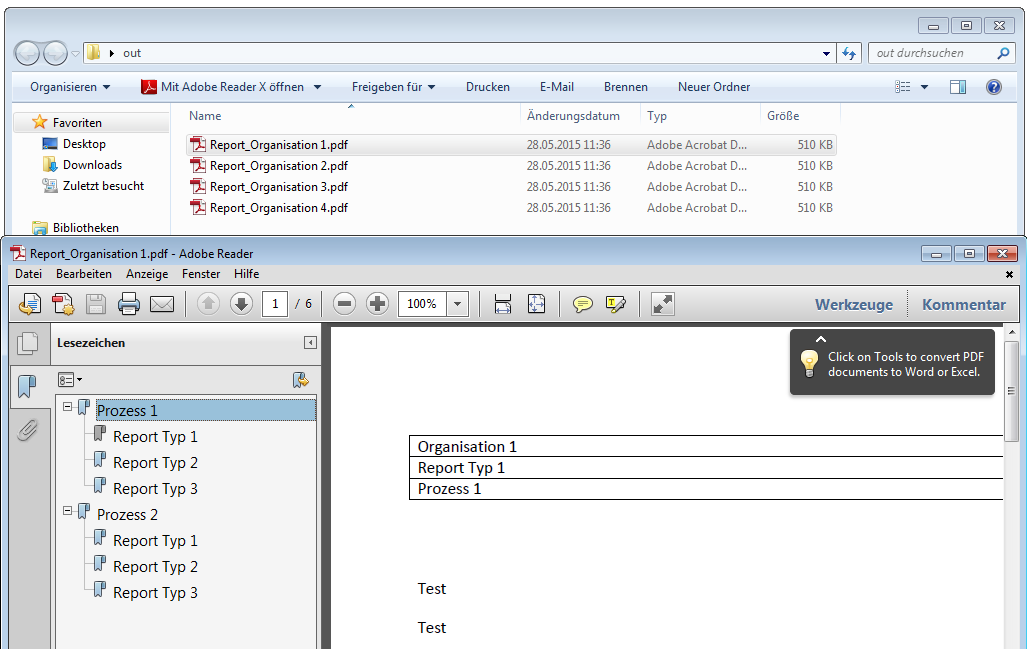
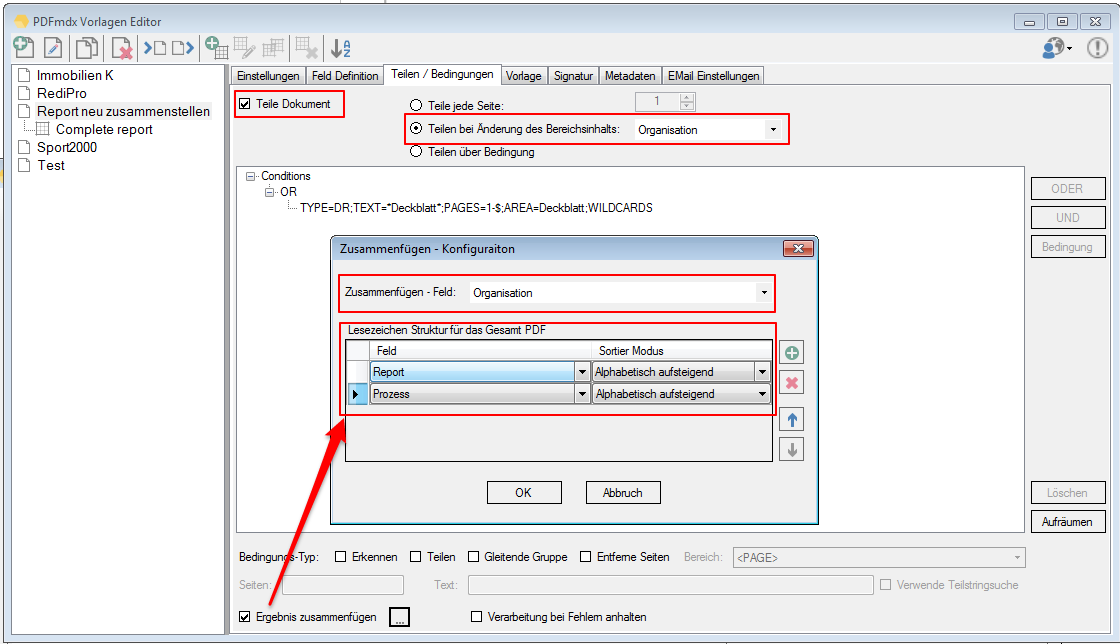
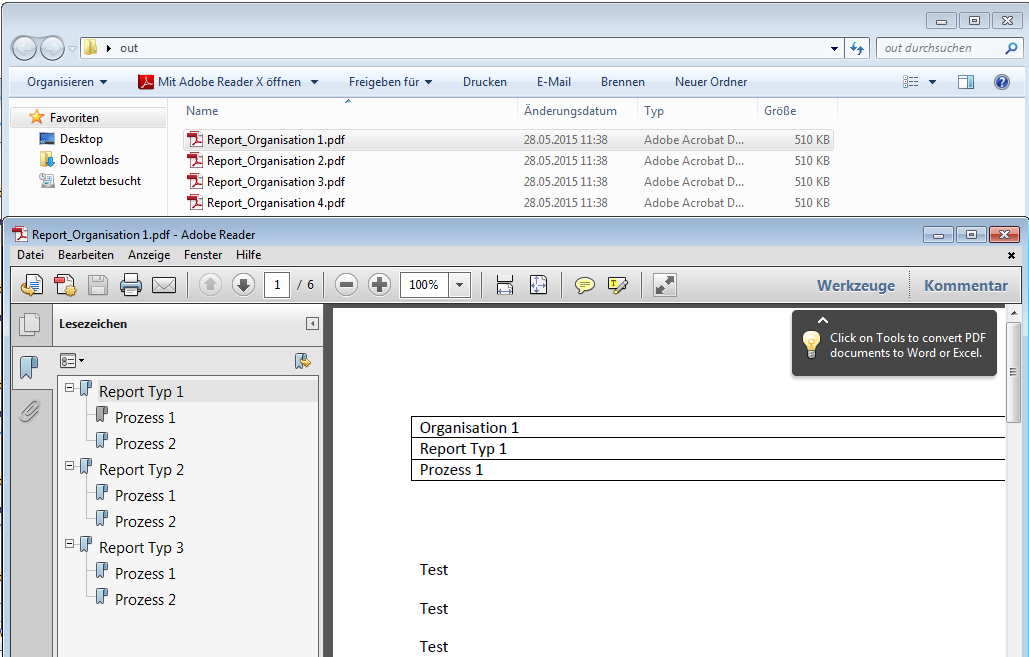
Test – Function – significantly extended: Allows to perform in advance, based on a pattern or template file, a test of the field search, extraction, preparation, the layout recognition, the pages erase function and document sharing. For the test can also select a different PDF file than the one used for layout.
Fields – assign values: Normally, information can be read from the document and assigned to fields / variables. But there are cases where it is not possible to read out certain information which should be stored. For example, it may happen that in a PDF invoice, the supplier only has used images for the design of the form and therefore is no area which you can read the company name. The layout can also be recognized by other criteria and is clearly assigned. In this case, the “company” is not positioned on the layout, but can be assigned with the name of the company in order to use the information subsequently as a variable or in the metadata.

Innovations PDFmdx processor version 2.x:
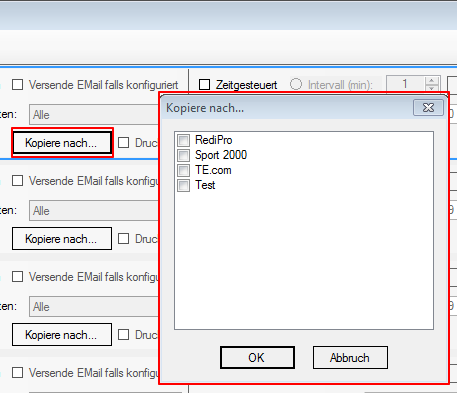
Copy to..: To process a single input file in several different ways, the function is “Copy to ..” – There must be selected only the name of the target jobs from the list. The transfer can also be carried out in parallel on multiple jobs. All input files of a job are automatically copied into the input folder of the other jobs. There can be performed automatically several variants of processing with different parameters at once – see also the function “Split & Merge New”
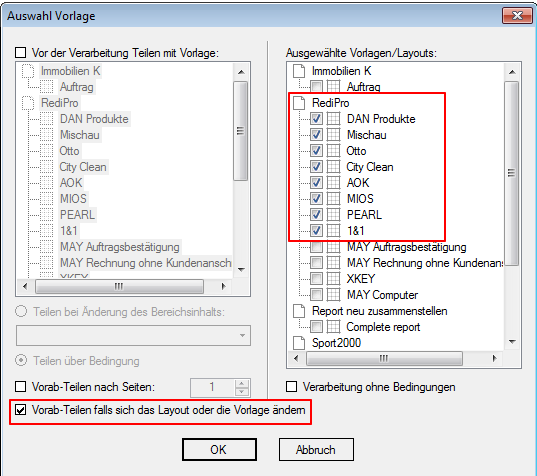
Pre-Split at changing the layout / template: This function allows split into individual documents a stack of documents prior to further processing with reference to the detected layout bzw.- templates and then continue to process. A split in a new document takes place once a detected layout changes. Layouts and templates are recognized via the configured criteria. It is split only at pages where a layout is detected.
PDFmdx service processor – scheduled processing: By default, the processing begins as soon as a new file is detected in any of the input folders. In addition is a scheduled process was possible so far with the startable PDFmdx Processor – with a set interval of x minutes, or even to a specific date and time or even every day at a specific time. This option is now available for the PDFmdx service processor as well.