Category: Dies & Das
Result code – CL, CS-CL command line applications
With the current versions of our command line applications (CL, CS-CL), a result code is now returned which can be evaluated. 0 = Successful, -1 = Error. The system variable %ERRORLEVEL% is also assigned the result code.
PDFmdx – Reading position data via a sliding group – Product video
PDFmdx can read information from PDF documents via defined areas and assign them to a field. However, there is also information in a document that occurs several times. For example, position data of invoices – quantity, article number, price etc. These are usually executed as tables in fixed columns and a variable number of rows.
PDFmdx is also able to read position data from PDF documents with the help of “sliding groups”. Fields are assigned to a “sliding group” and positioned on the template document. Criteria define conditions to identify a row as a “sliding group” record. Two delimiters determine in which vertical area of the pages such data records are searched for.
The following video also shows the use of “anchor fields” to find and read information which is “moving” on a page and has no fixed position, e.g. the final amount of an invoice.
PDFPrint Service CS – Client / Server Print – Version 1.1.6 available
PDFPrint Service CS Version 1.1.6 is now based on the latest PDFPrint .NET component.
The following extensions are available:
- New additional „Advanced“ printing method
- Paper source selectable
- Number of copies adjustable
PDFPrint Service CS requires .NET Runtime 4.6 as of version 1.1.6. The setup checks if this version is present and if not it will automatically be downloaded and installed from the internet during the installation process. .NET 4.6 Runtime is already available with Windows 10.
Download – PDFPrint Service CS – Prints PDF’s via HTTP / HTTPS >>>
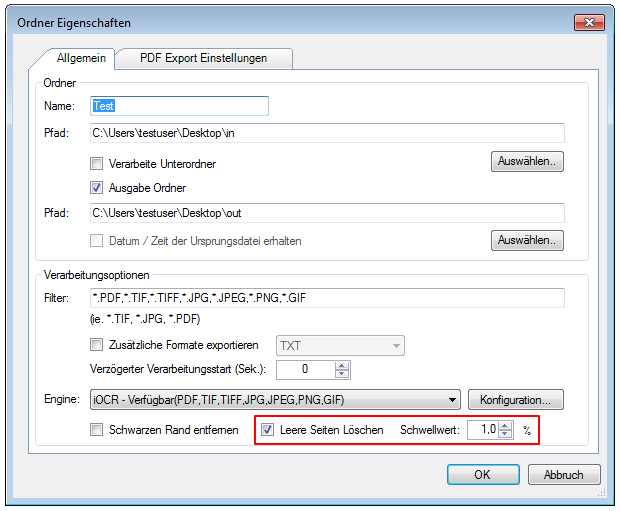
AutoOCR Version 1.17.2 – New function – delete empty pages
With AutoOCR version 1.17.2 there is an option to delete empty pages before OCR processing. The detection of a page as a “Blank” via a set threshold. The default value is 1%. A page is recognized as “empty” if less than 1% of the pixels of a page are “not white”. This value must be adjusted if necessary to be processed scans, as it may be when scanning with impurities also that a blank page having “more pixels”, and certain pages are then not detected as empty. However, if the threshold is set too high, it may be that pages with little content are also recognized as empty and thus deleted.