PDFmdx – Version 2.7.1 – with SOAP / REST interface and extensive enhancements and improvements
Innovations PDFmdx Version 2.7.1:
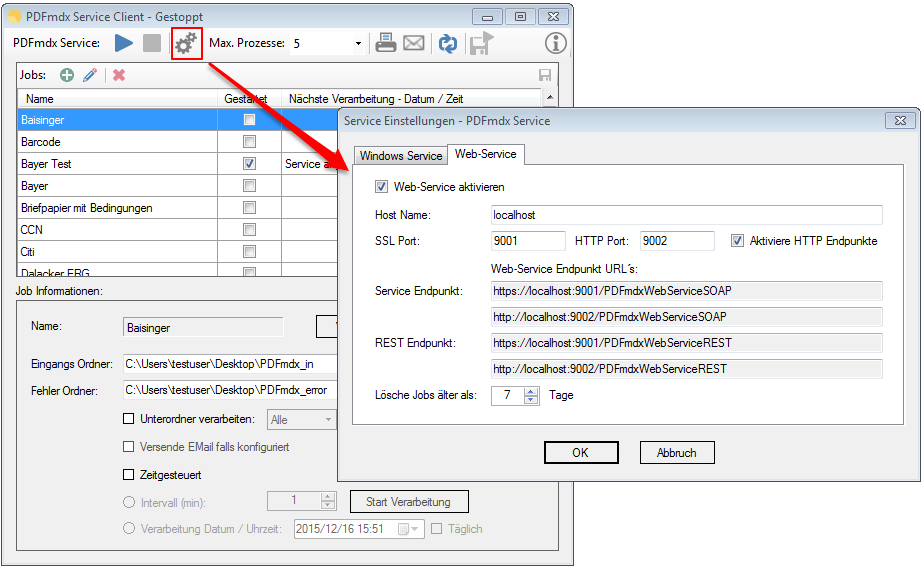
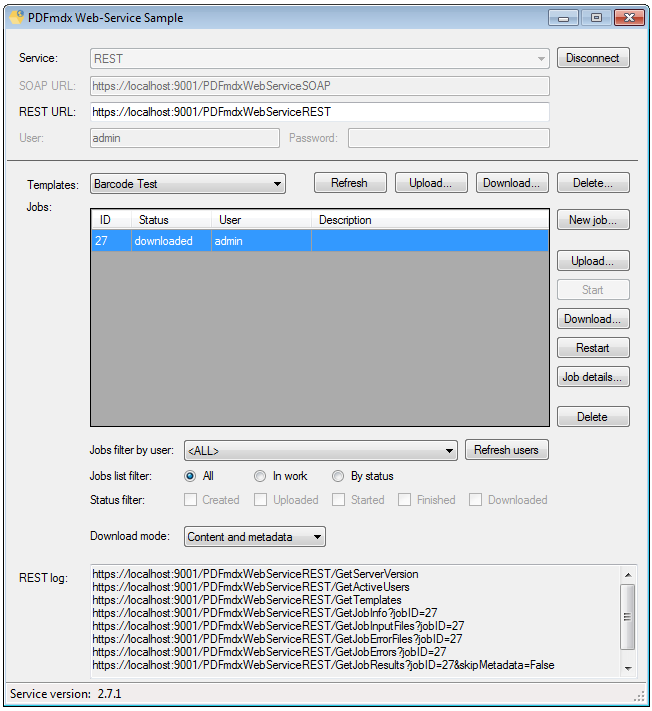
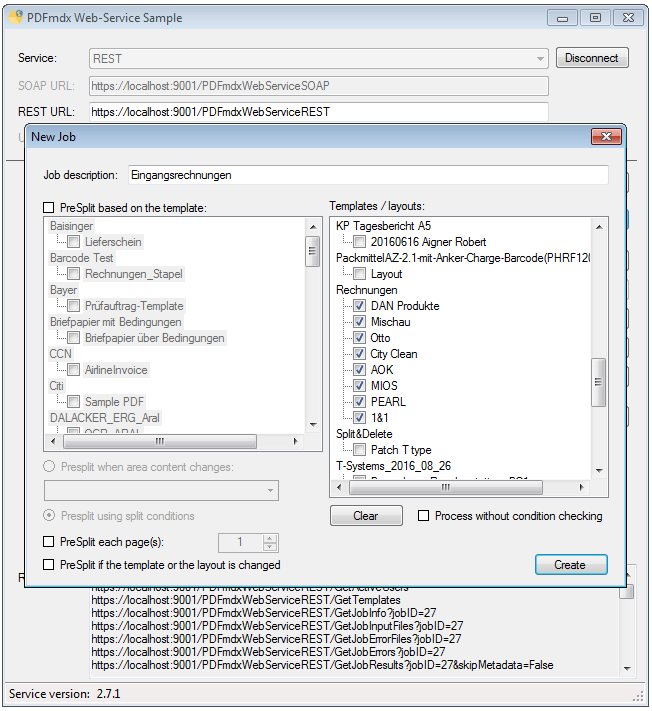
1. Web interface via SOAP / REST – PDFmdx can therefore be integrated into other applications and services. To test which functions via the web services are available, a test client and the source code of this application is installed as a C # project with the Setup.
Features Web-Service Test-Client:
- List of available templates – Refresh / upload / download / delete
- edit job – description, selection of layouts, processing without conditions – Yes / No, preliminary parts – by templates, by pages, by field change or when it changes the layout or template.
- With the “Upload” function a created job is “filled” with PDF files for processing
- “Start” – processing the uploaded PDFs with the job settings on PDFmdx server
- “Download”: After processing, the results can completely downloaded or viewed on Job Info details and result Files downloaded separately.
- For the “Download” can be selected if only the PDF output files, only the metadata, or both should be downloaded together.Other data to be processed can be recharged via “upload“ in a created job and “Restart” will also be processed.
- “Delete” allows delete existing jobs
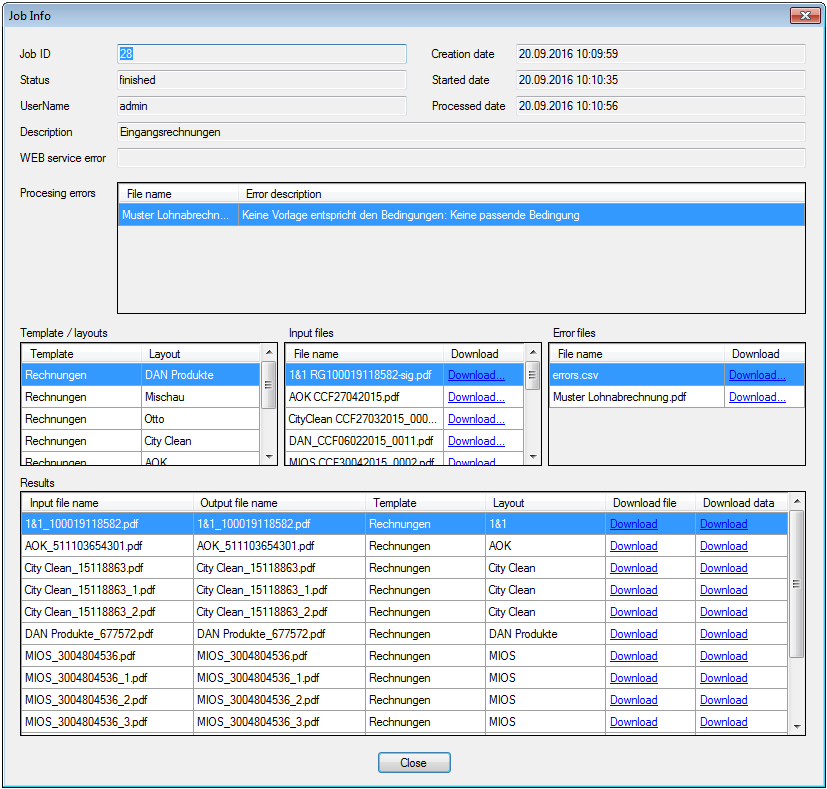
- Jobs can be queried and displayed as a list – ID, status (created, uploaded, started, finished, downloaded), user, description – are displayed. The job list can be filtered by the user and the status.
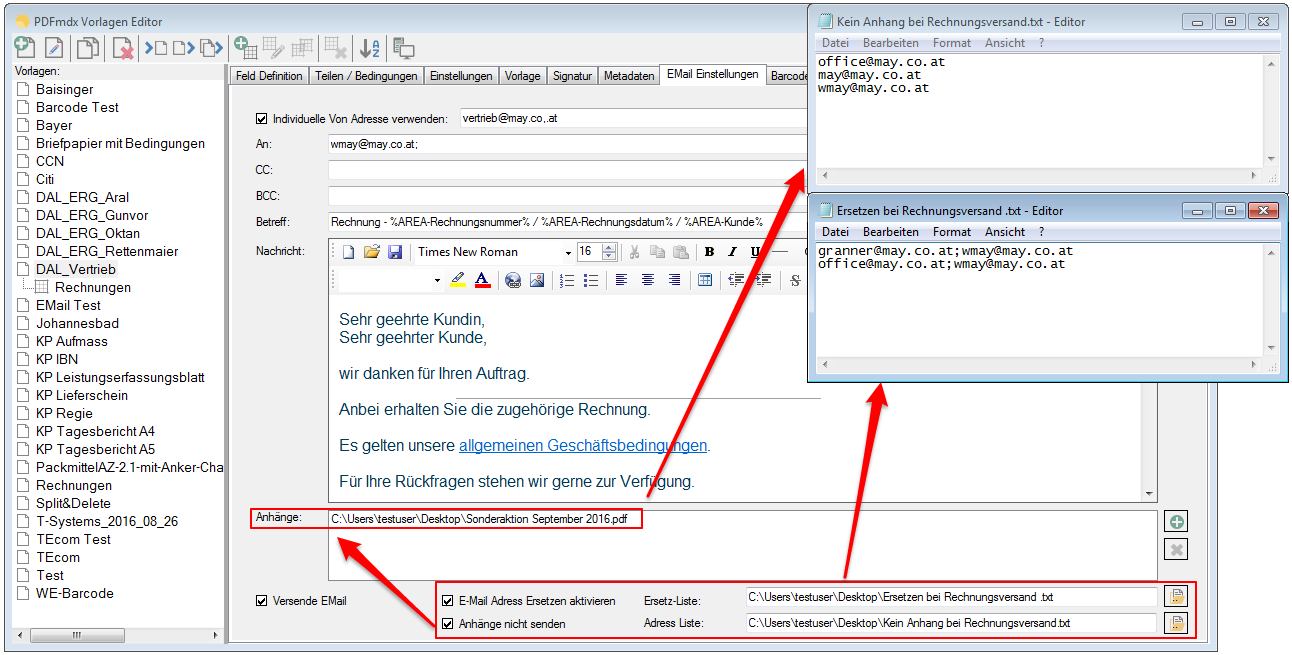
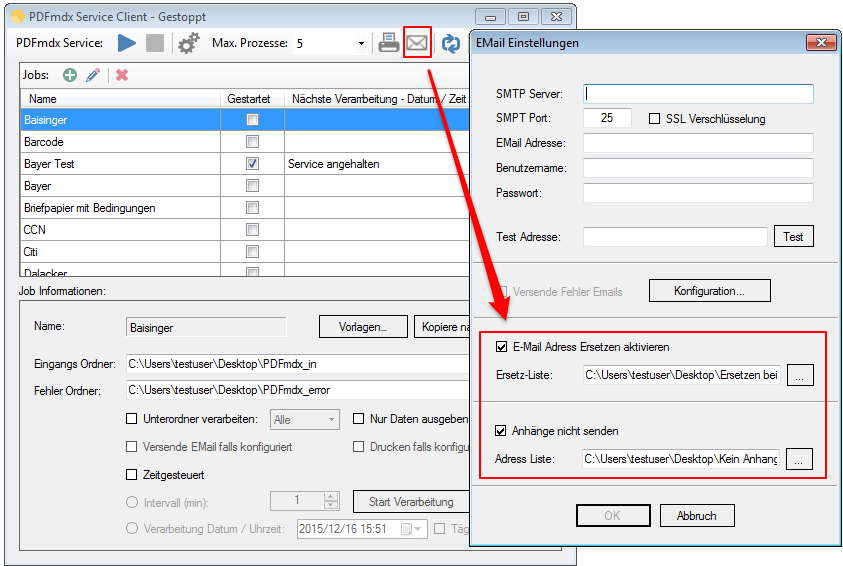
2. EMail attachment negative list – External list of email recipients to whom the additional selected attachment should not be sent. The recipients listed only receive the resulting document from the processing. An additionally configured attachment is not sent. All other e-mail recipients receive the additional attachments.
3. eMail replacement list – An E mail address of “To:”, “CC:” and “BC” may be replaced by an external ASCII / TXT list with another email address.
The attachment negative list and the replacement list can be defined generally or per template. The lists of templates override the general conditions laid down in the e-mail configuration lists.
4. Condition Editor has been extended to copy / cut and paste to existing conditions. Conditions can therefore be exchanged between the templates.
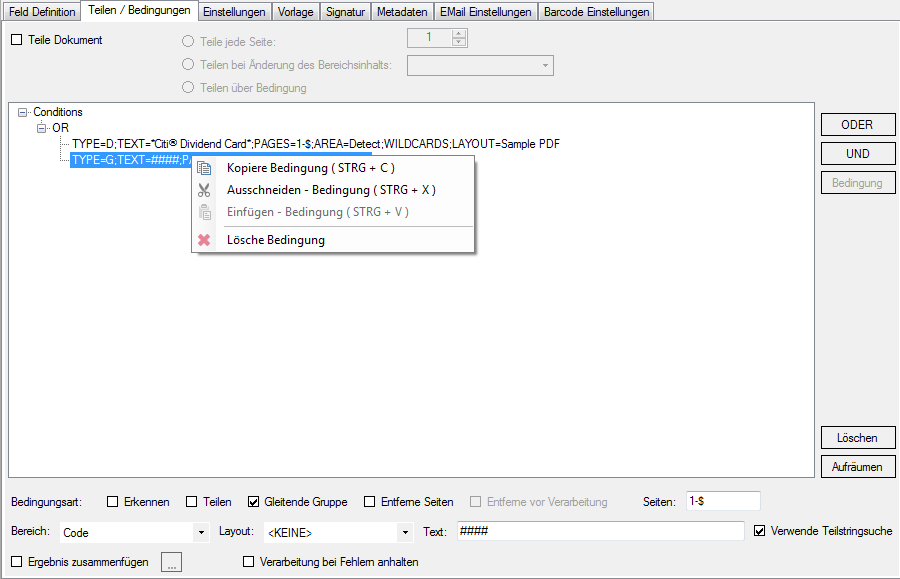
5. The choice of 1D / 2D bar code types for the detection can be set individually for each template and field –So far, the barcode types were set uniquely only in general for the whole application and therefore for all the templates and for all fields – now it is individually possible to field level.
6. 2D barcode recognition for fields or across the entire page. 2D barcodes of types DataMatrix, PDF417, Micro QR Code and QR Code can be recognized and read through the whole page or in a field area now.
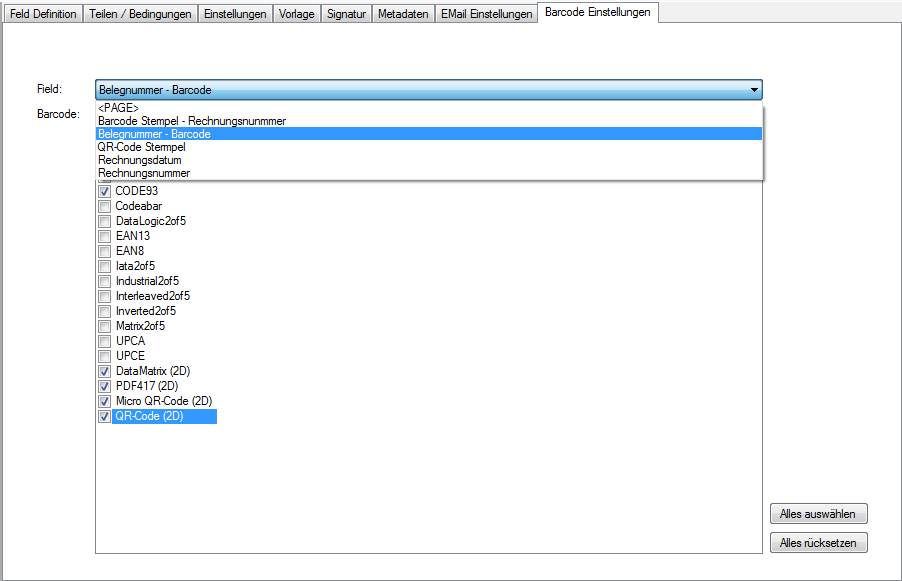
7. Get the PDF information fields, obtaining date / time – The PDF information fields as well as the creation and modification date of the source file can be copied to the output file. Without this option, this information will be rewritten.
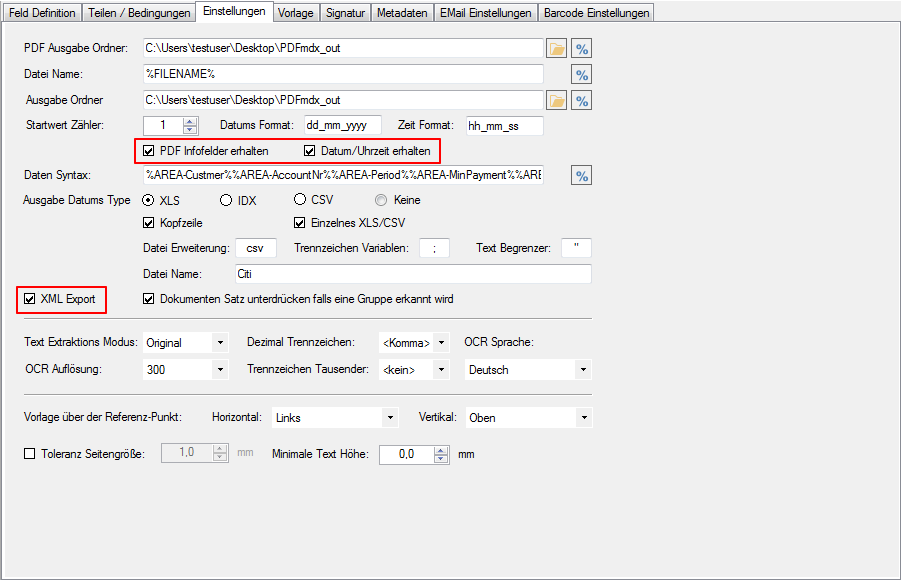
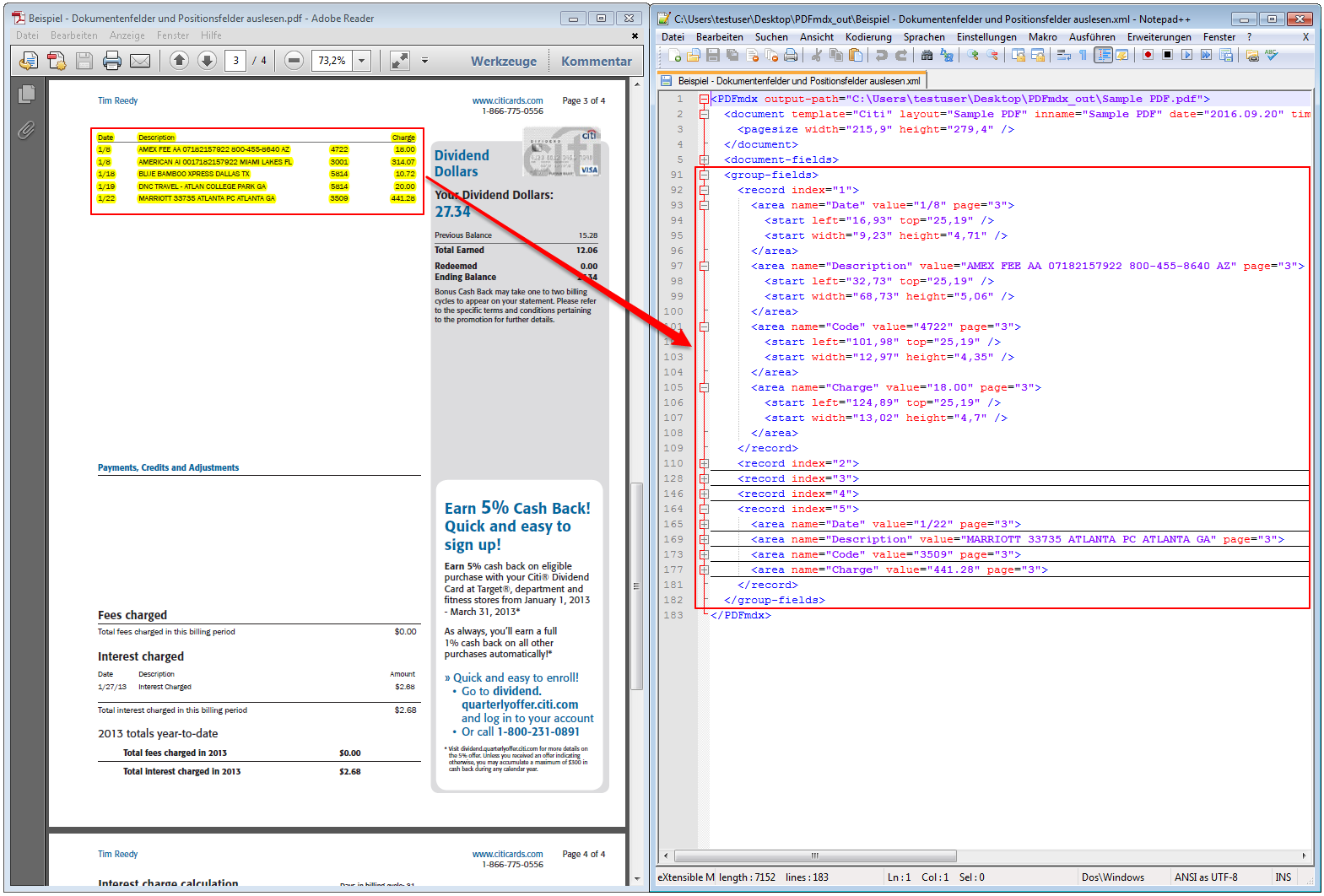
8. Suppressing the documents record in XLS / CSV output because with the gliding group (single position data sets) fields all document fields can be output as well.
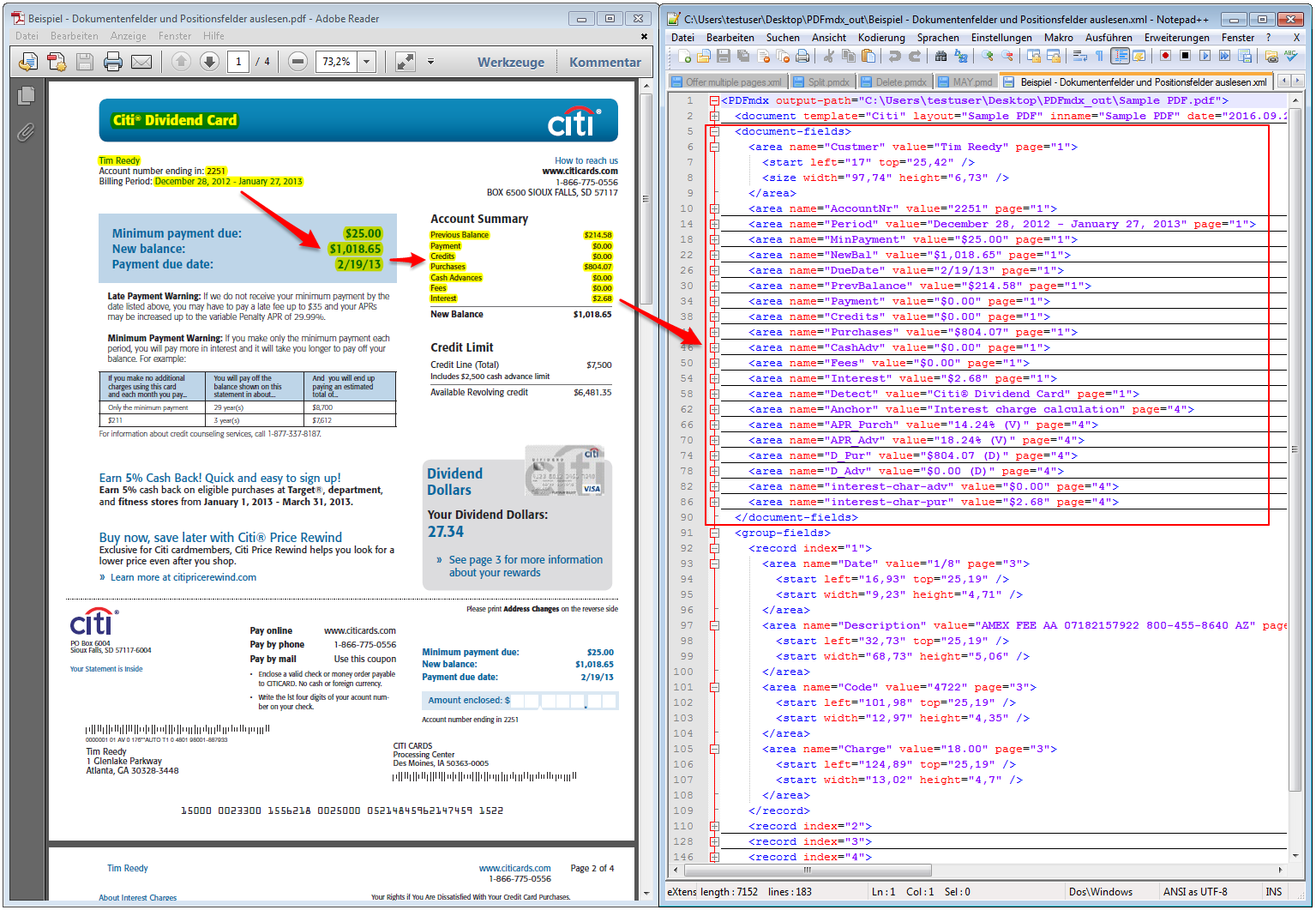
9. The XML output format has been improved and implemented correctly – The document fields and the records for the fields of “gliding group” (item fields) are output separately in the XML structure. The used unit “mm” is output as an XML element.
10. Search function in the PDF preview – therefore texts in PDF prototype currently displayed file can be searched and highlighed. The search can be carried forward / reverse and runs automatically as a substring search. This feature facilitates checking the conditions and the anchor Search function.

11. The default preview has been set to maximum width at the upper edge of documents – previously the default view was the vertical center of the document.
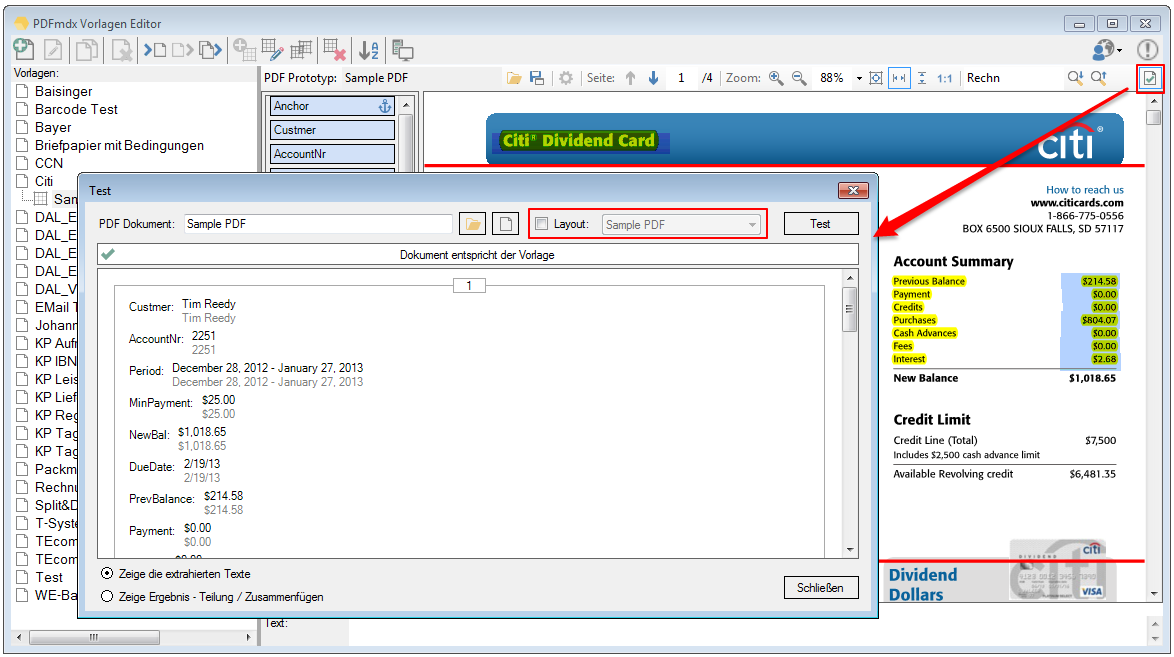
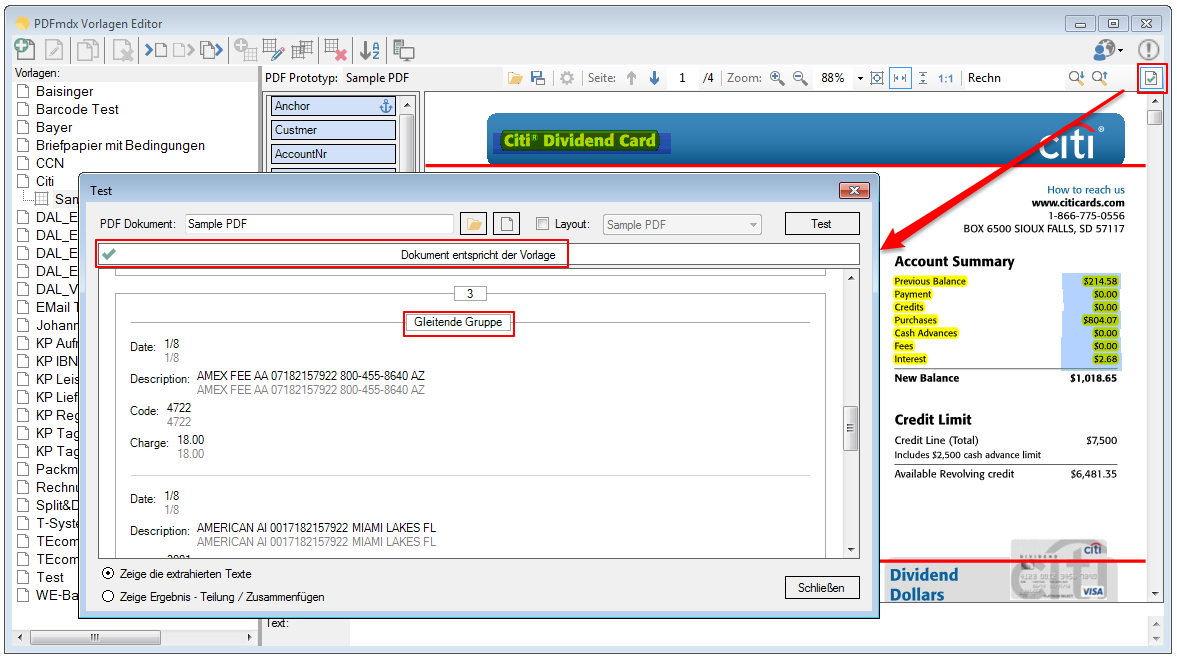
12. The test function been revised and extended. The defined condition can be switched off for the test. The layout to be used can be selected manually. So can be displayed regardless of the defined condition, the read-out fields. So the analysis and fine-tuning will be easier. The document fields and the fields of the gliding group are now properly evaluated during the test function and display correctly.
13. Set Default / default values for fields – they can be accessed and used via the% variables. So values can be assigned even if the field is not positioned or if the read-out area is empty.
14. Extensive corrections and bug fixes have been made in the range of page numbers in the conditions field–search anchors, and at page function of the search anchor definitions. It is now reliably the first search string found found on the specified page and used as an anchor reference for the fields. Likewise, improvements in the text extraction were made – especially with regard to the correct order of the extracted words. With these improvements PDFmdx has been optimized for the processing of scanned or OCR documents.
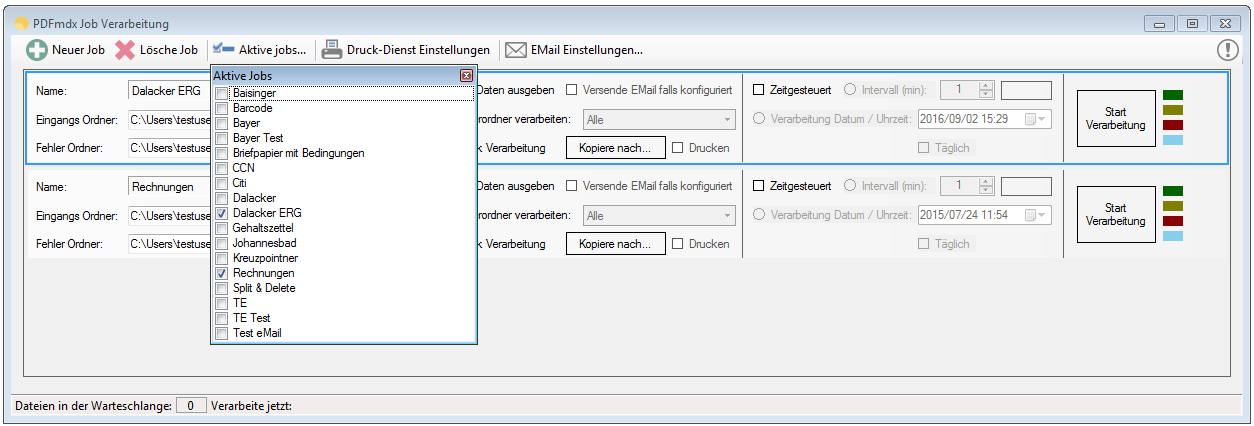
15. Show/Hide of jobs in the executable PDFmdx processing. In order to increase the clarity of a large number of configured jobs, job definitions can have a checkbox “hidden” and therefore hidden on the user interface.
Download – PDFmdx Template Editor & Processor >>>
Download – PDFmdx REST Interface >>>