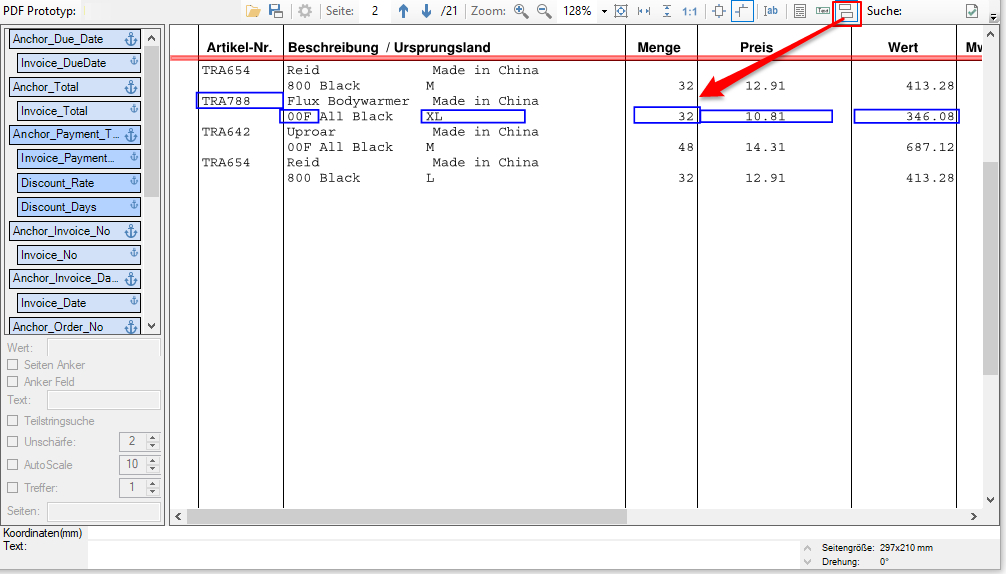
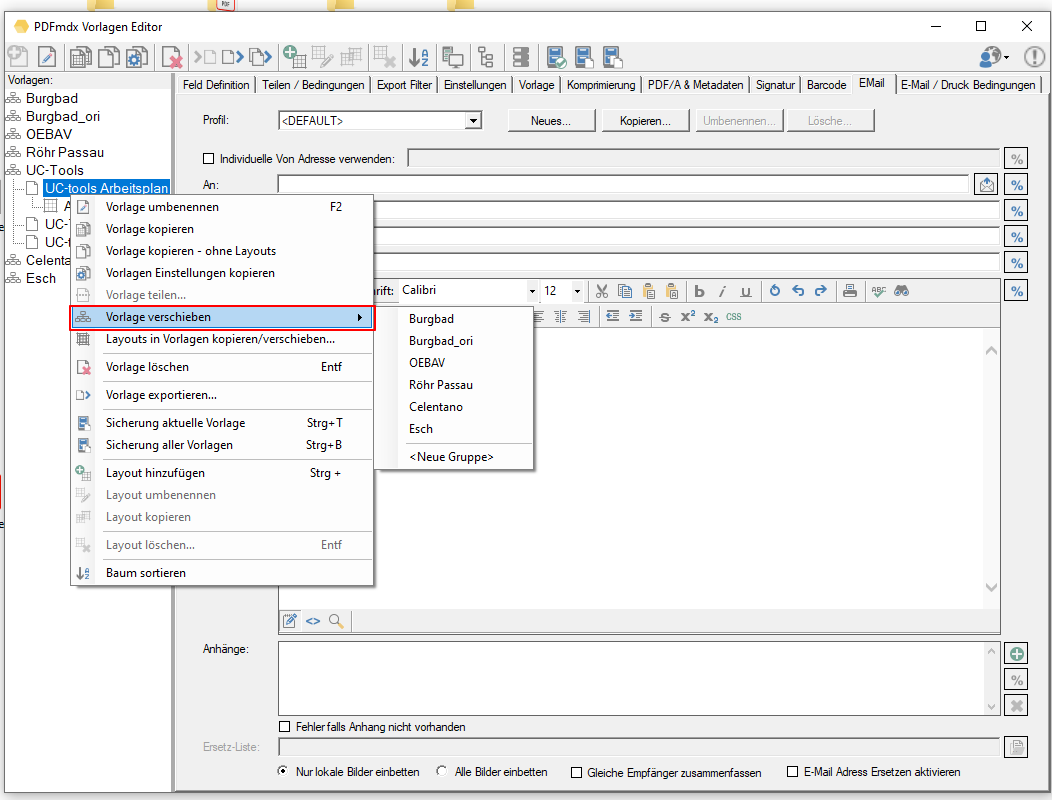
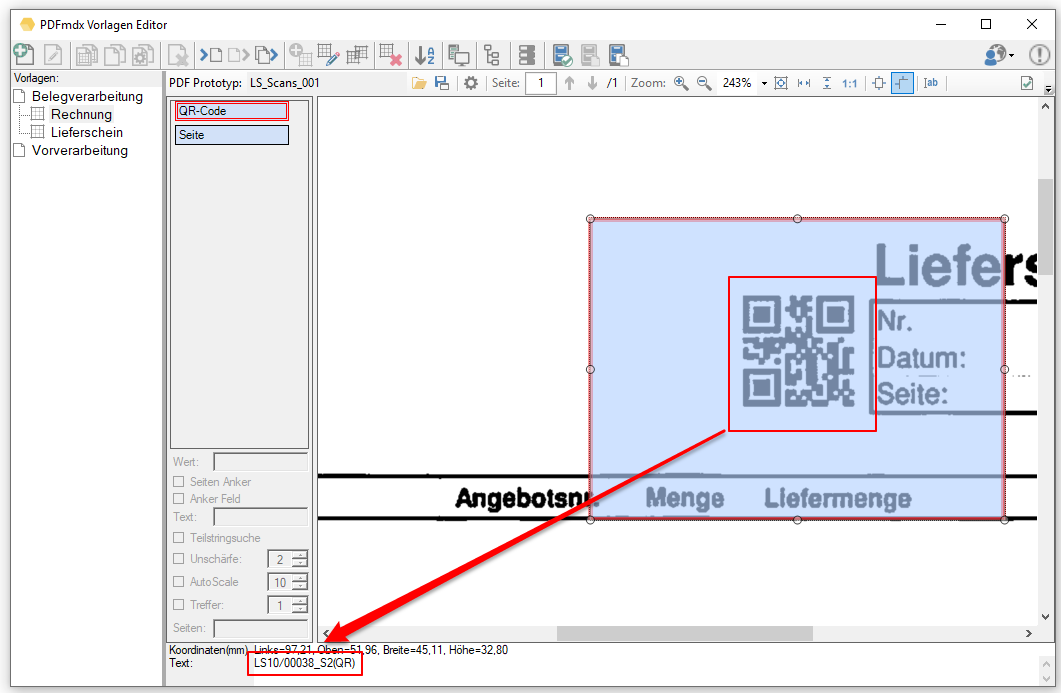
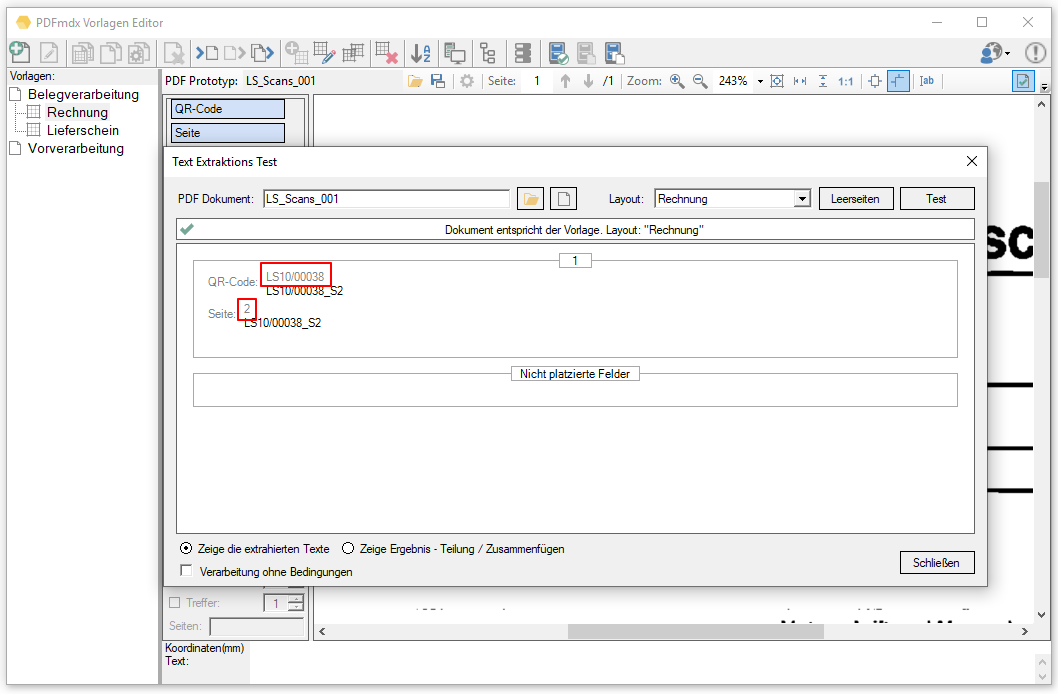
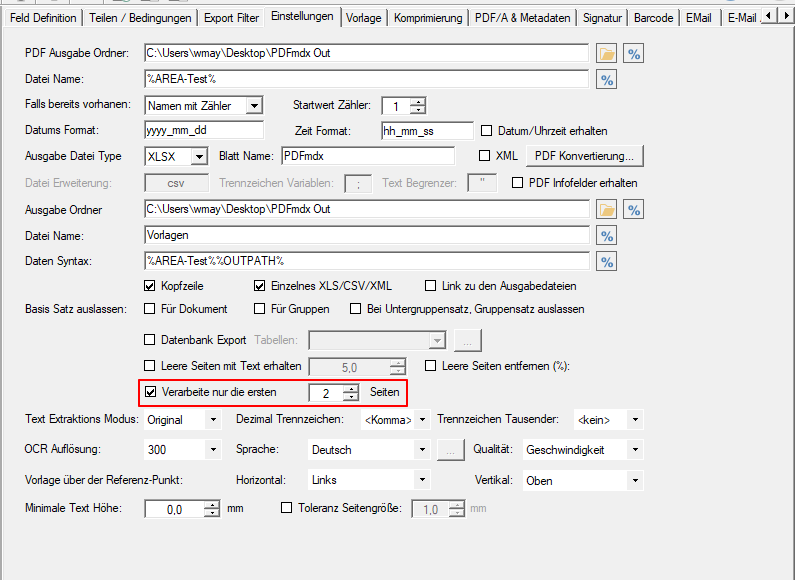
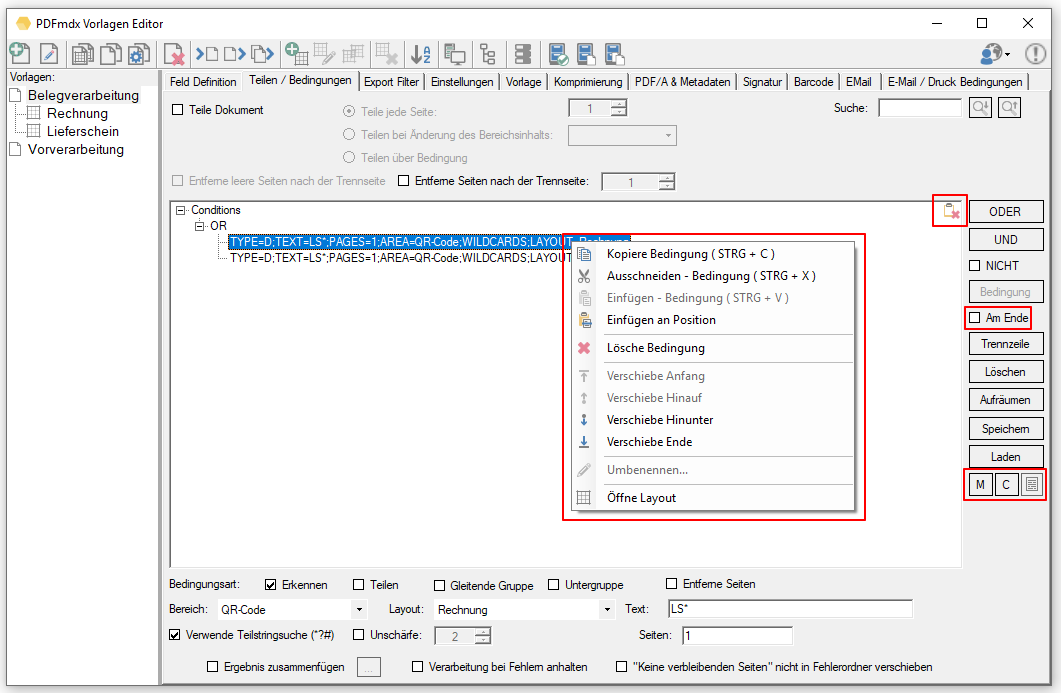
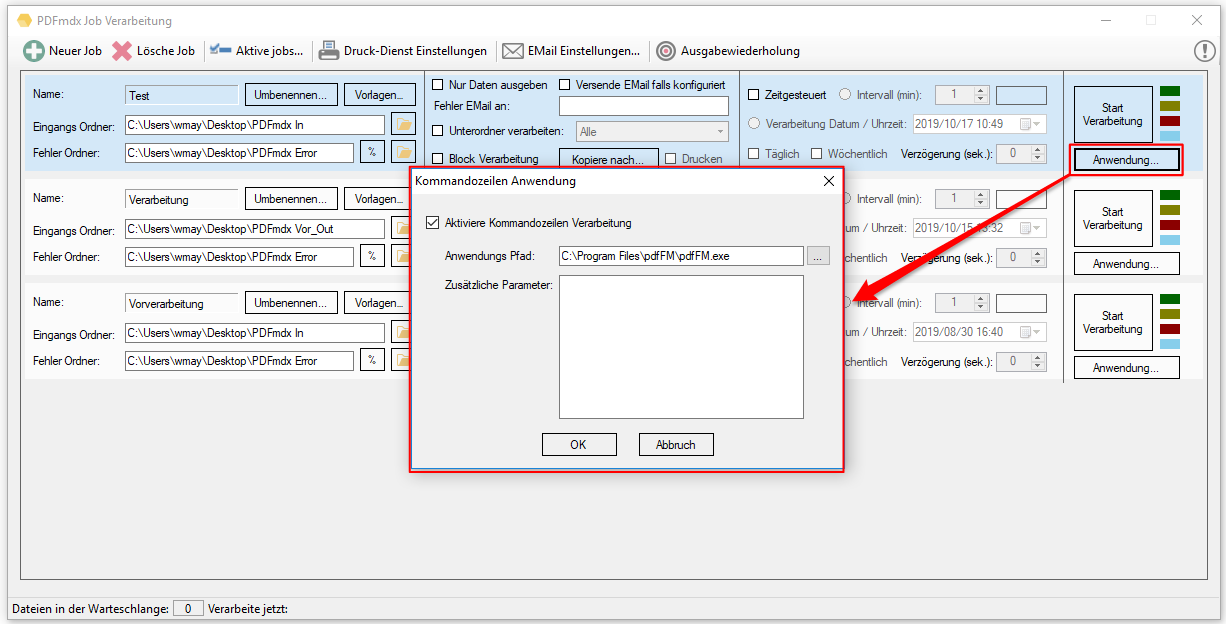
PDFmdx Version 3.20.0
News / improvements PDFmdx version 3.20.0:
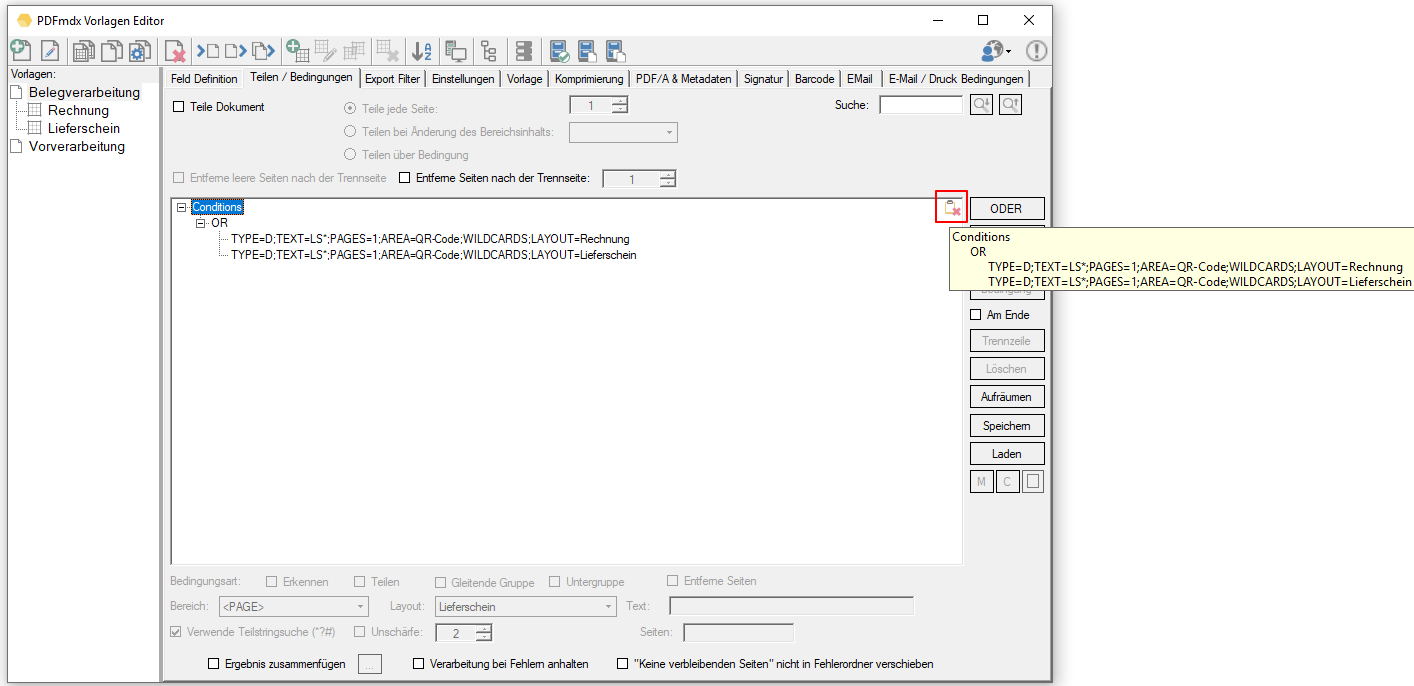
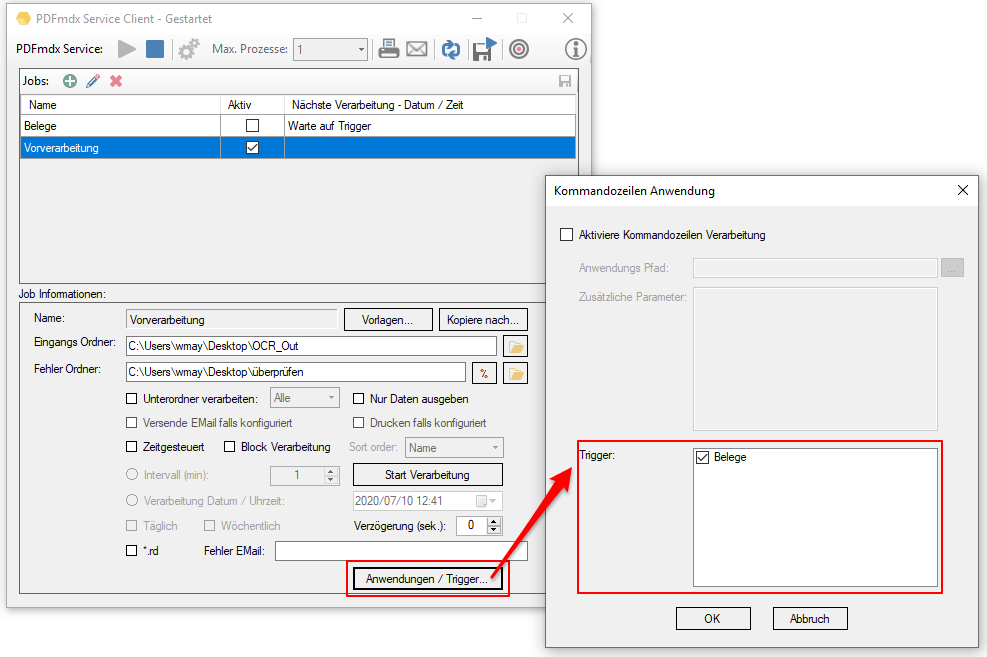
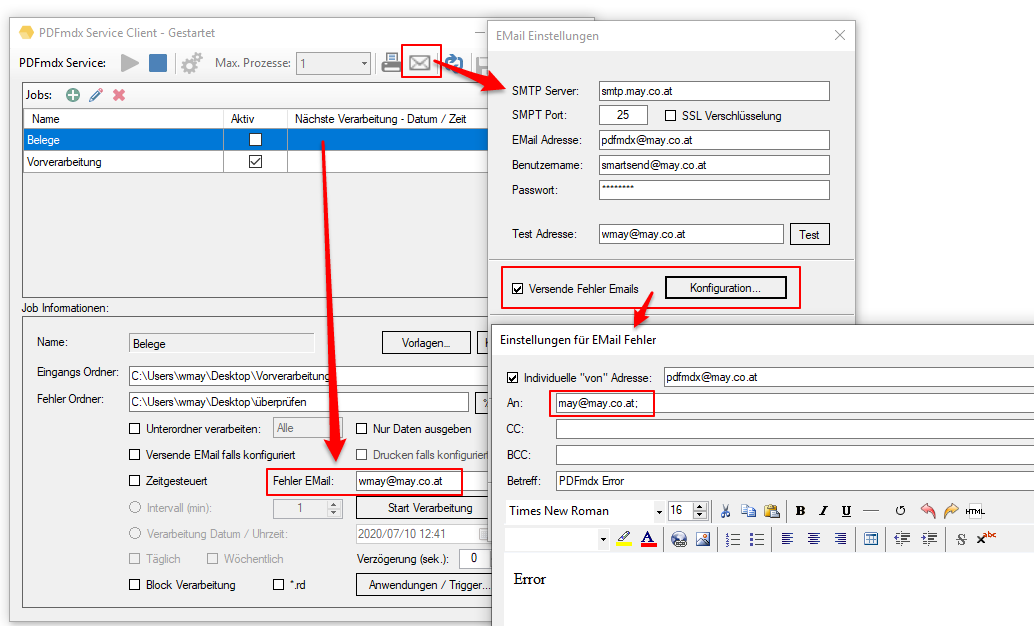
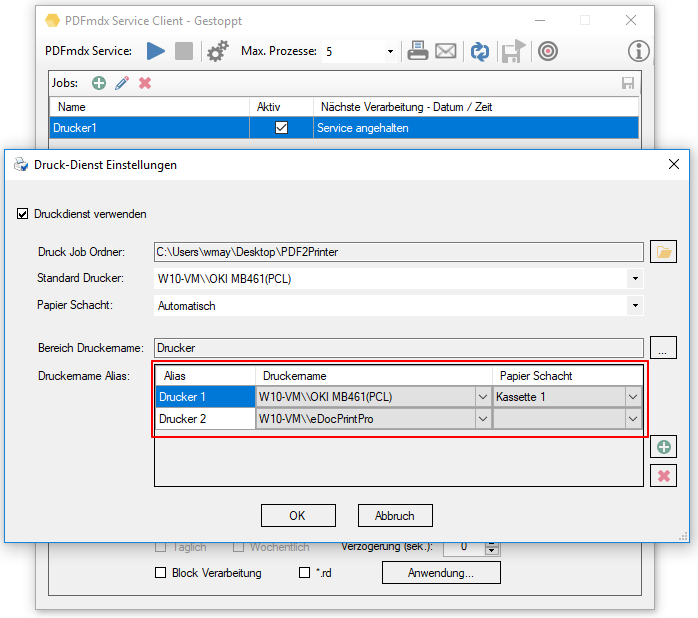
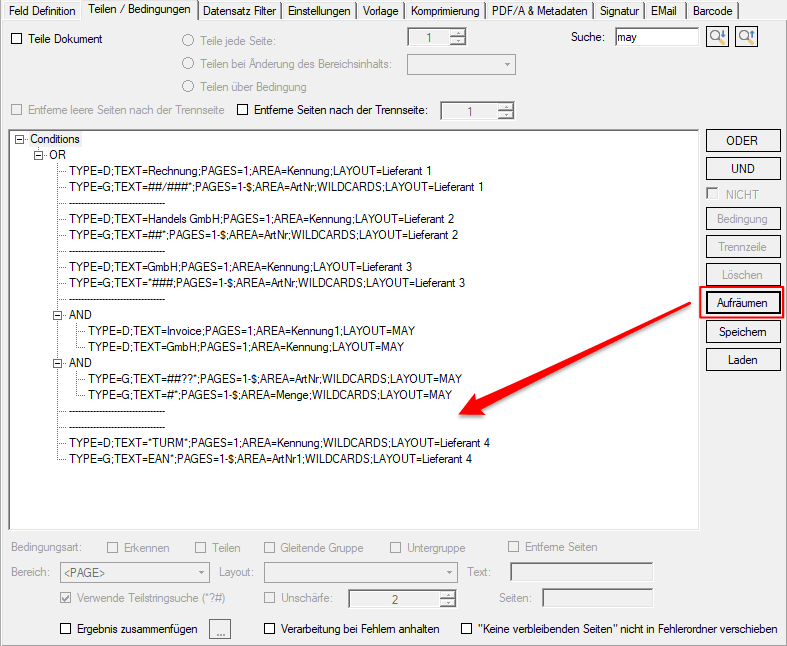
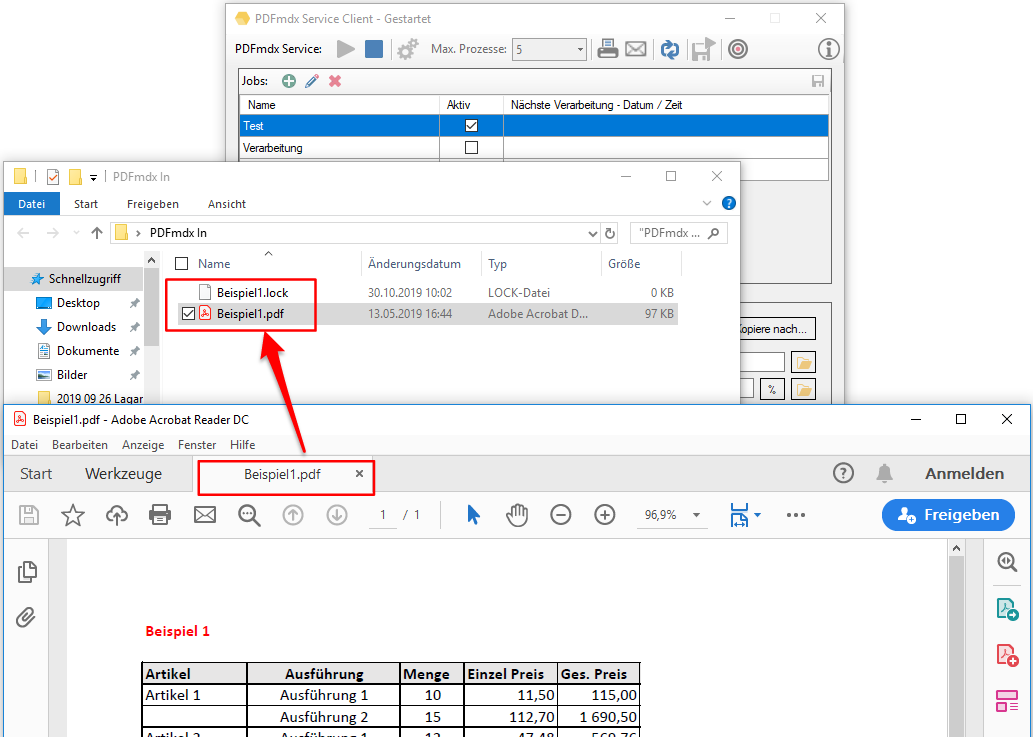
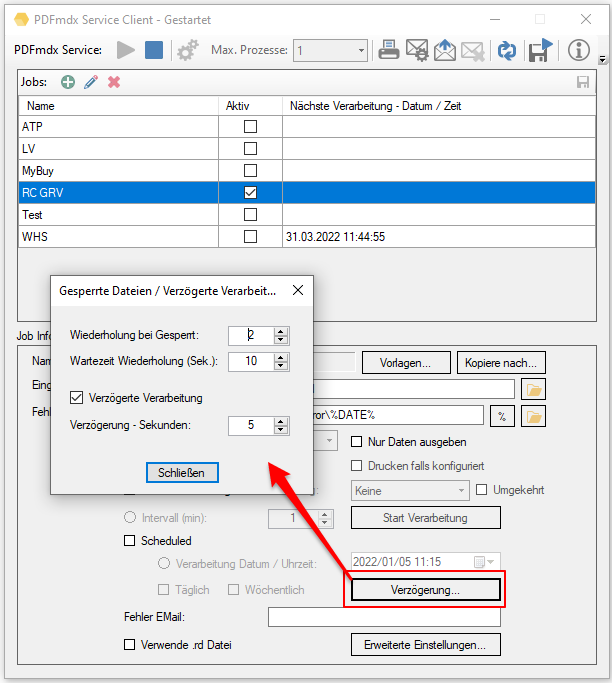
- Reps & Waiting time for locked files: If a file in one of the monitored input folders is still locked when another application starts processing, a *.lock file is automatically created for this file. This happens if e.g. a scanner stores the scans directly in a watched folder. Often the PDF file is created first, locked and then added page by page. Depending on the size of the batch of documents, it can take a few minutes to finish writing a file and unlocking it. In order to intercept such situations, 2 parameters were implemented to automatically remove *.lock files again. This allows initially locked files to be processed automatically after they have been released.
The “Number of repetitions” and the “Waiting time between repetitions” can be configured. It is therefore repeatedly checked whether the file is still locked and if it has been released, the *.lock file is deleted and the PDF is processed.
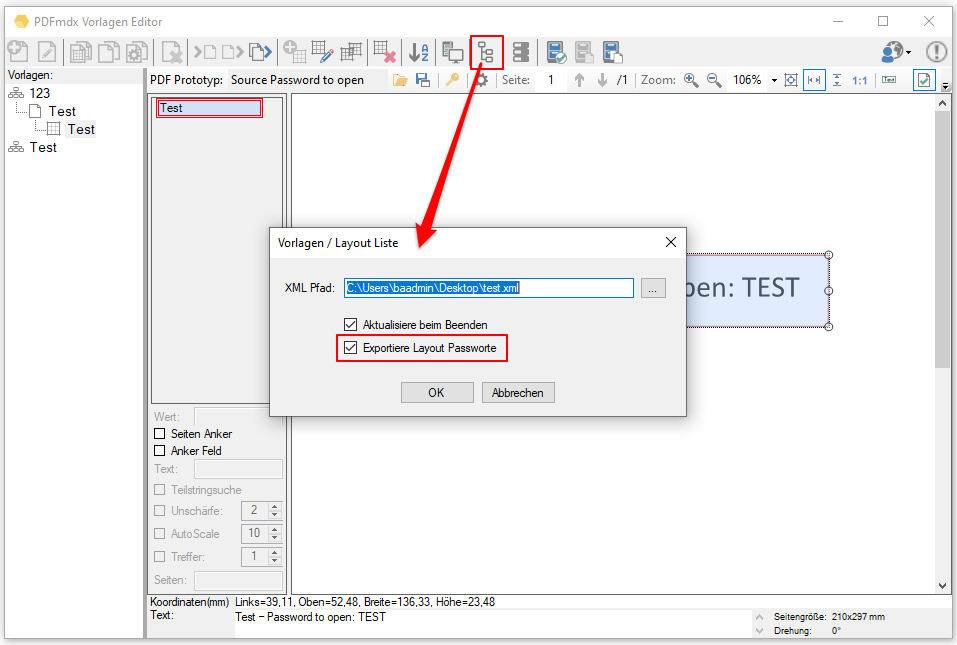
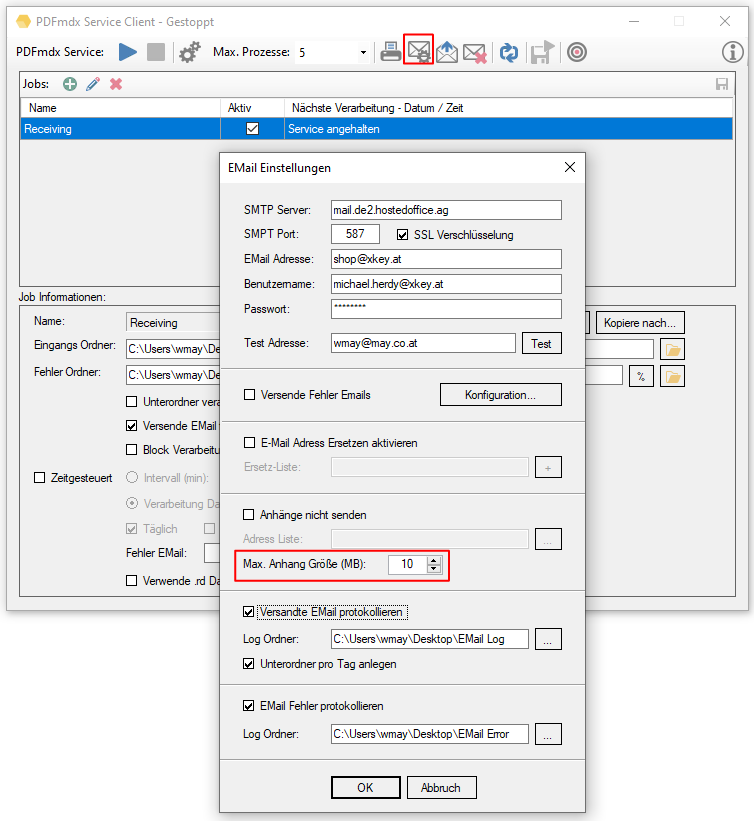
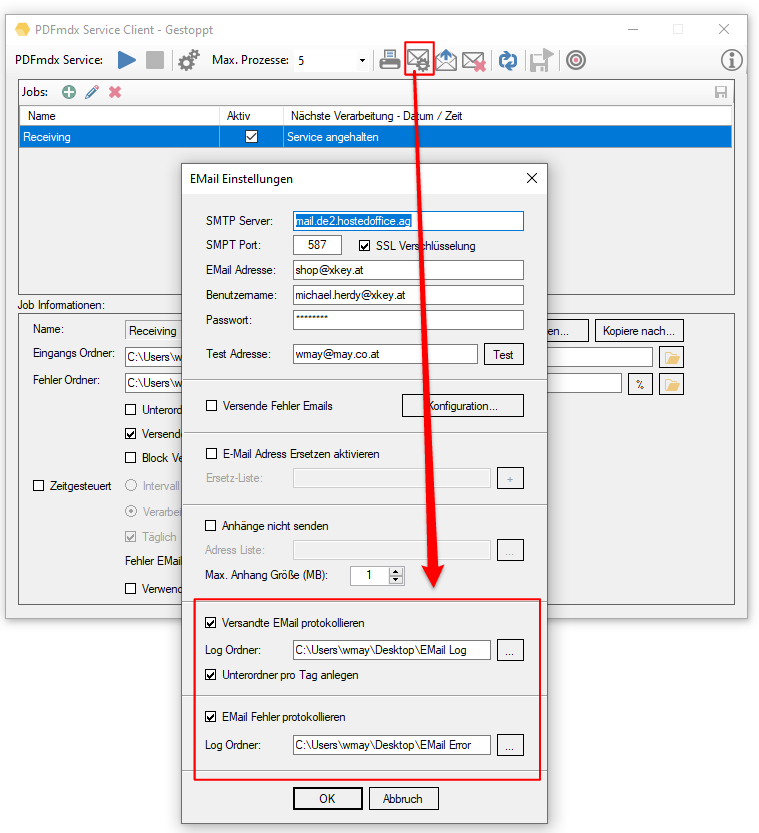
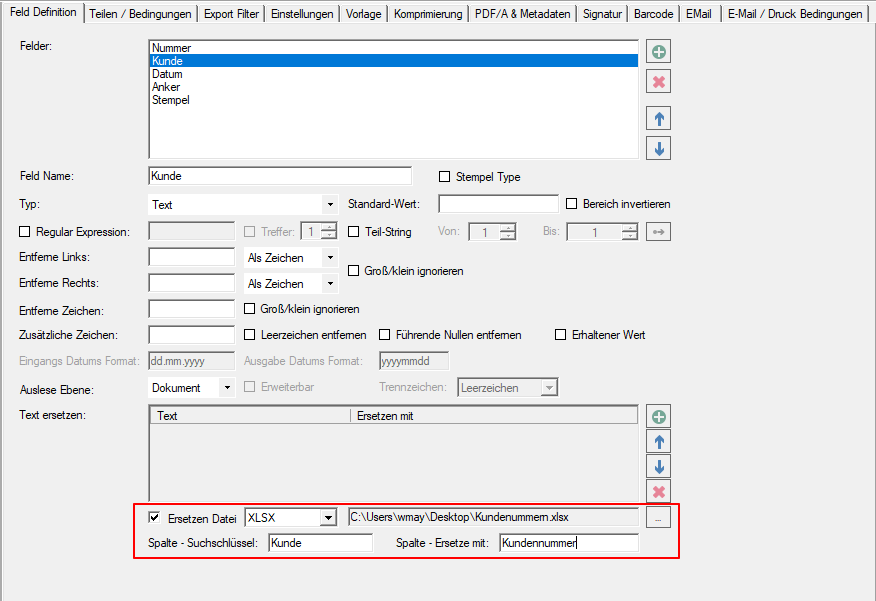
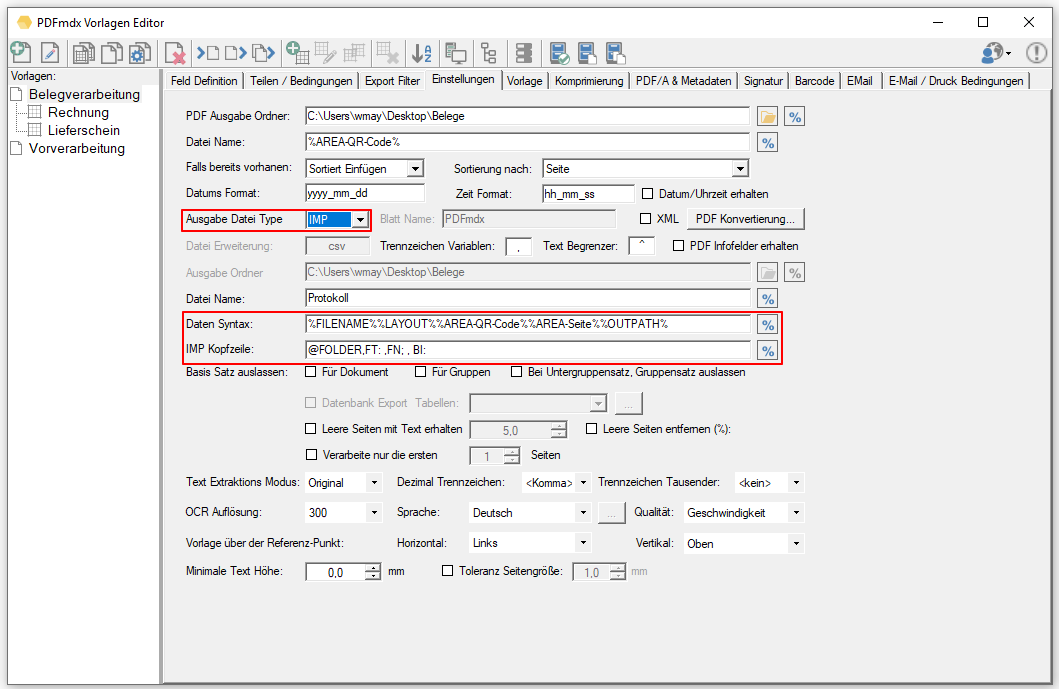
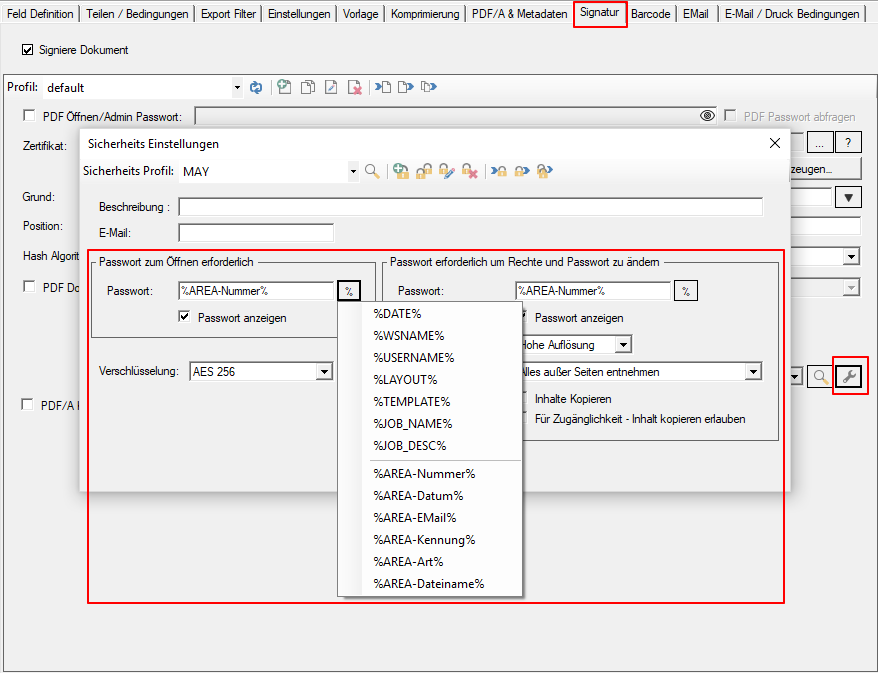
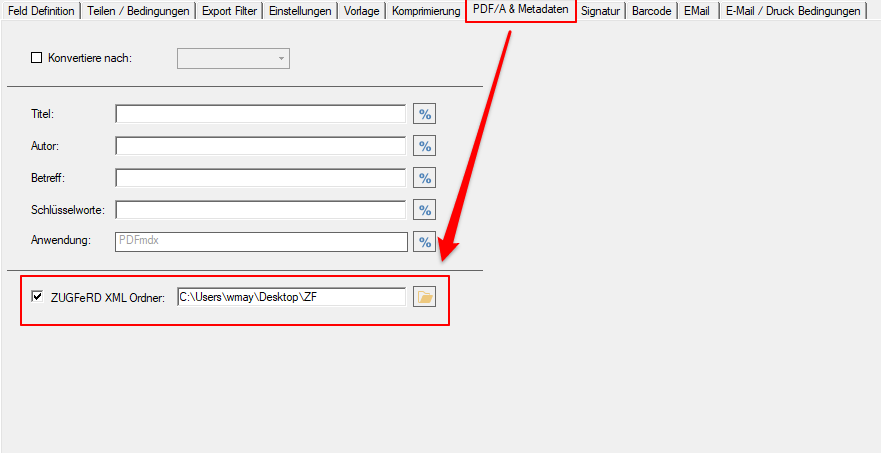
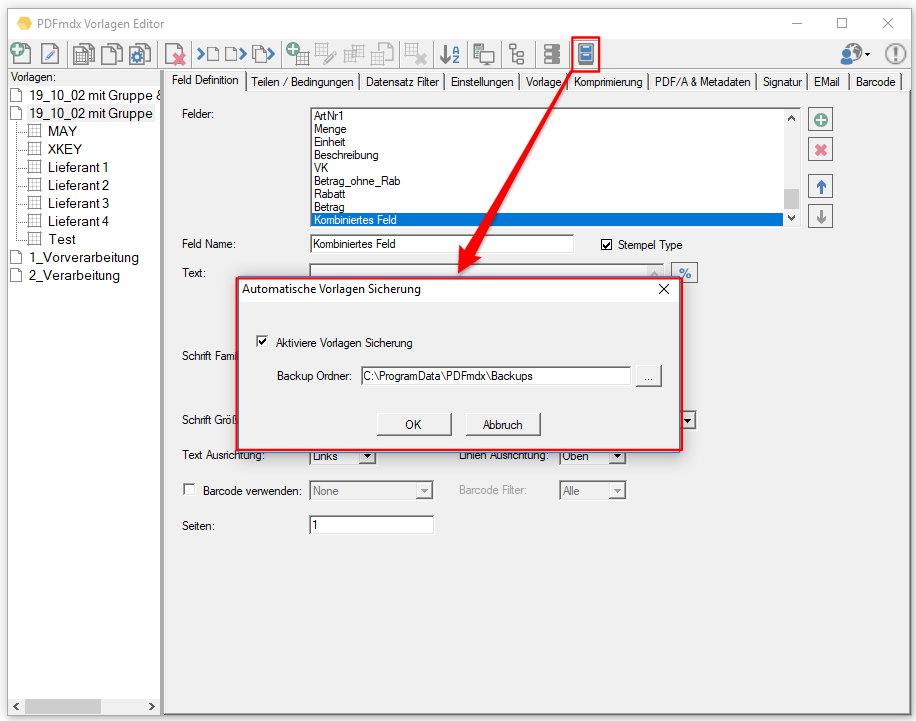
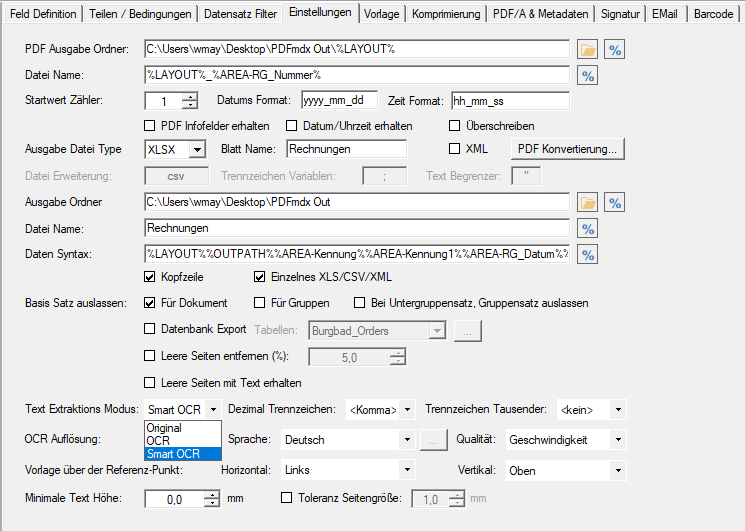
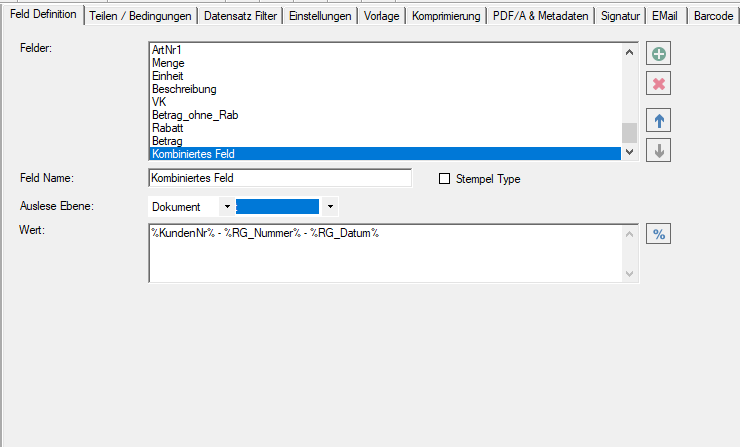
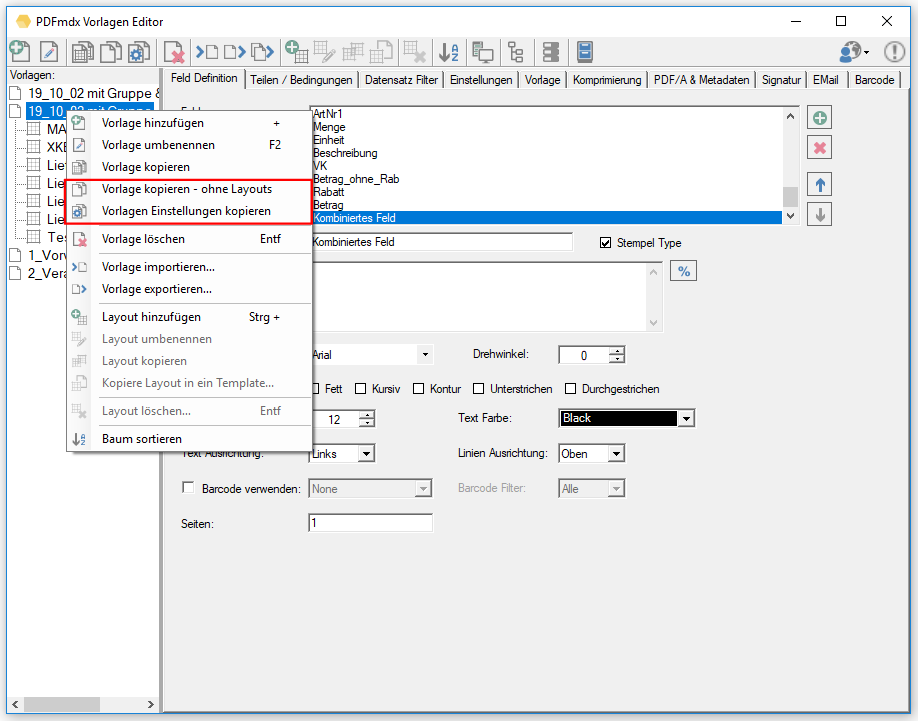
- Open PDF password – XML export of templates / layouts: During the XML export of templates / layouts, the passwords stored in the PDFmdx layout can now also be exported to open a protected PDF file.