ZUGFeRD – eDocPrintPro PDF/A-3 printer driver for electronic invoices available
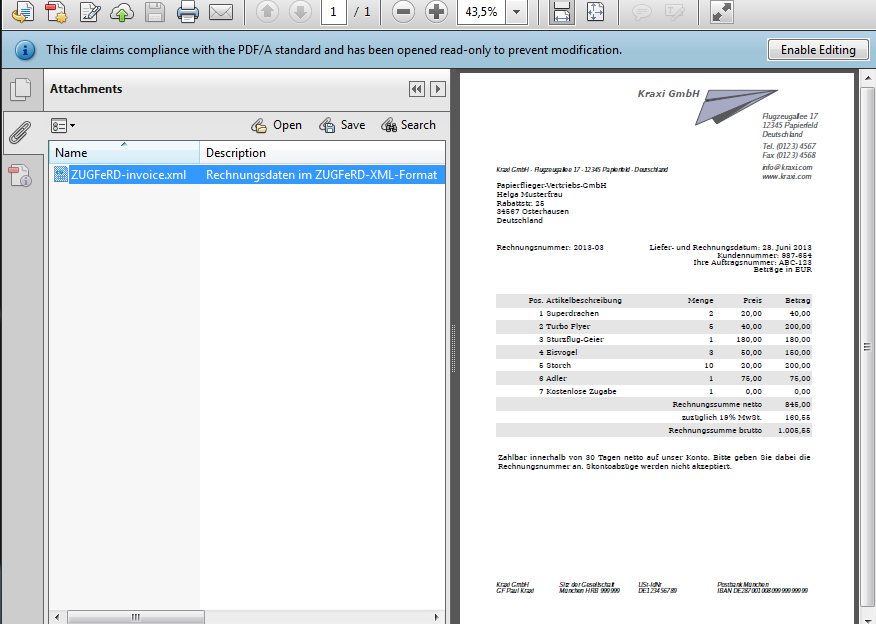
The ZUGFeRD data format is a, based on the PDF/A level 3, format for electronic invoices in germany. Thereby the PDF document is used for archiving, print and visual representation and the data gets additionally embedded as XML. The XML contains sector-neutral information and metadata for the invoice.
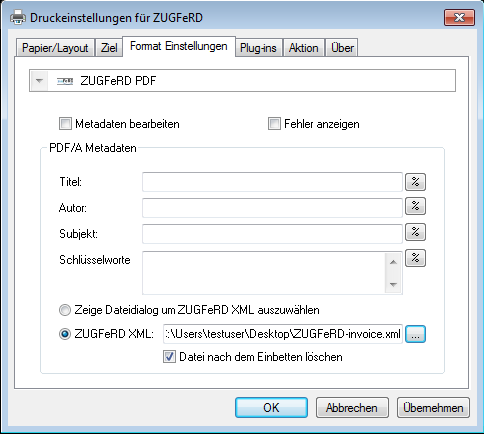
For a ZUGFeRD invoice also a PDF/A-3 has to be created as well as a XML file has to be available. The XML usually gets created from the ERP. The ZUGFeRD eDoc printer driver allows with a simple print process to create such invoices out of any application.
Possible courses: the XML is available in any cases, the print process is done via the ZUGFeRD eDoc driver:
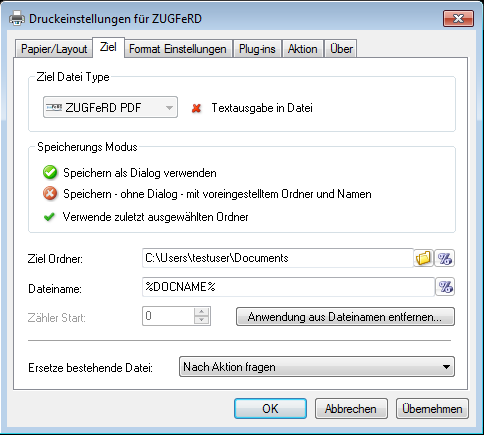
- interactive choice of the XML file via file dialog
- “silent” processing of the XML with pre defined path and file name.
- XML can also be deleted after embedding automatically to create a defined state.
- Starting of the print process via the eDoc SDK, the destinaion path and names of the PDF’s is adjusted through the SDK, the document printed, the XML gets embedded automatically and afterwards an event about the finishing of the process is passed back to the application.
ZUGFeRD – customized – specifically interesting for software-developer:
The ZUGFeRD eDocPrintPro PDF/A-3 printer driver is specifically also for developers of software solutions because with it the creation of ZUGFeRD conform electronic invoices can be implemented fast and easily. The software only has to create the ZUGFeRD conform XML file, the rest is done by the ZUGFeRD eDoc printer driver. Software provider can implement the solution with their name and use it without any additional license costs (royalty-free).
Function range ZUGFeRD – customized:
- ZUGFeRD – eDocPrintPro PDF/A-3 printer driver + setup with own name / logo / links for the lizensefree (royalty-free) usage together with the own software solution
- 32 and 64bit version – for MS-Windows XP / 7 / 8 / MS-Windows Server 2008 / CITRIX and MS-Terminalserver
- eDocPrintPro SDK – to be able to automate the print process and to integrate it in the own application.
- ZUGFeRD – XML extractor – to be able to extract the XML file from the PDF (C# .NET or Commandline Tool)

Download – eDocPrintPro ZUGFeRD – PDF/A-3 printer driver >>>
Download – ZUGFeRD – sample invoice >>>
Download – ZUGFeRD – sample XML >>>
ZUGFeRD – information package >>>