PDFmdx – Version 2.5.0 available
Innovations PDFmdx Version 2.5.0:
- pmdx – template Export / Import – The PDF prototype files of all layouts are now included in the file PMDX. Was previously a template from the PDFmdx Editor exported and imported on another computer again, so the PDF prototype file had copied separately and be available on the target computer in the correct path before calling. Was it not present, the position was lost and the fields had to be re-inserted. The PDF prototypes are now included in the PMDX file and will no longer be stored externally. This simplifies the exchange, as well as run the PDFmdx Editor and PDFmdx processor on different computers.

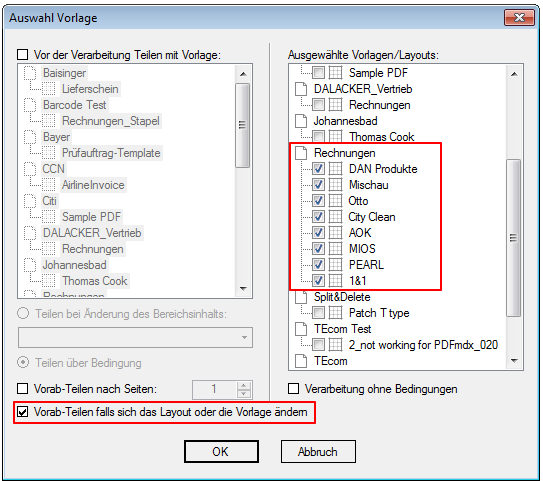
- Sites and Dividers (advance) delete – Via conditions pages and Dividers can be detected and be deleted before or during processing. If the deleted page will not be used for the detection of the layout or to split, there is a separate function to delete the recognized side “before processing”. In this case, first all pages to be deleted are searched and the further detections and divisions for the “remaining document“ carried out only in a second passage. The criterion can be set on a selected field or “the whole page”. Also the search can be done on a particular page, a series of pages, or all pages. It is possible to work with an exact string, or by using wildcards as #,? and *.
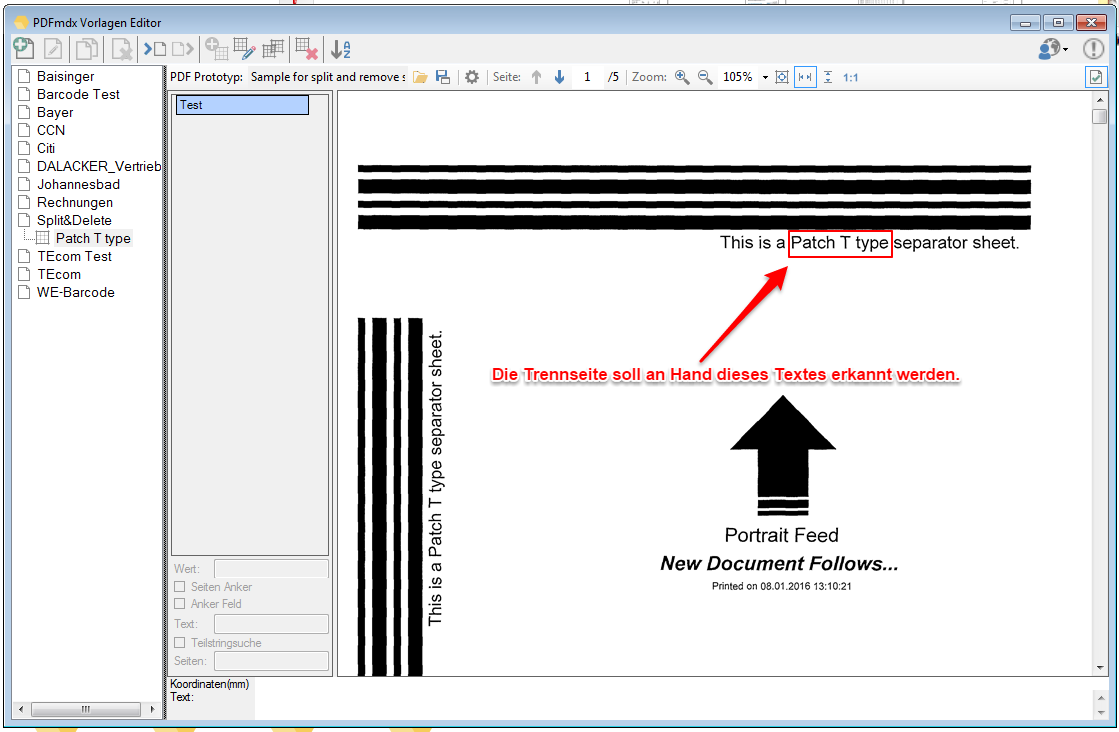

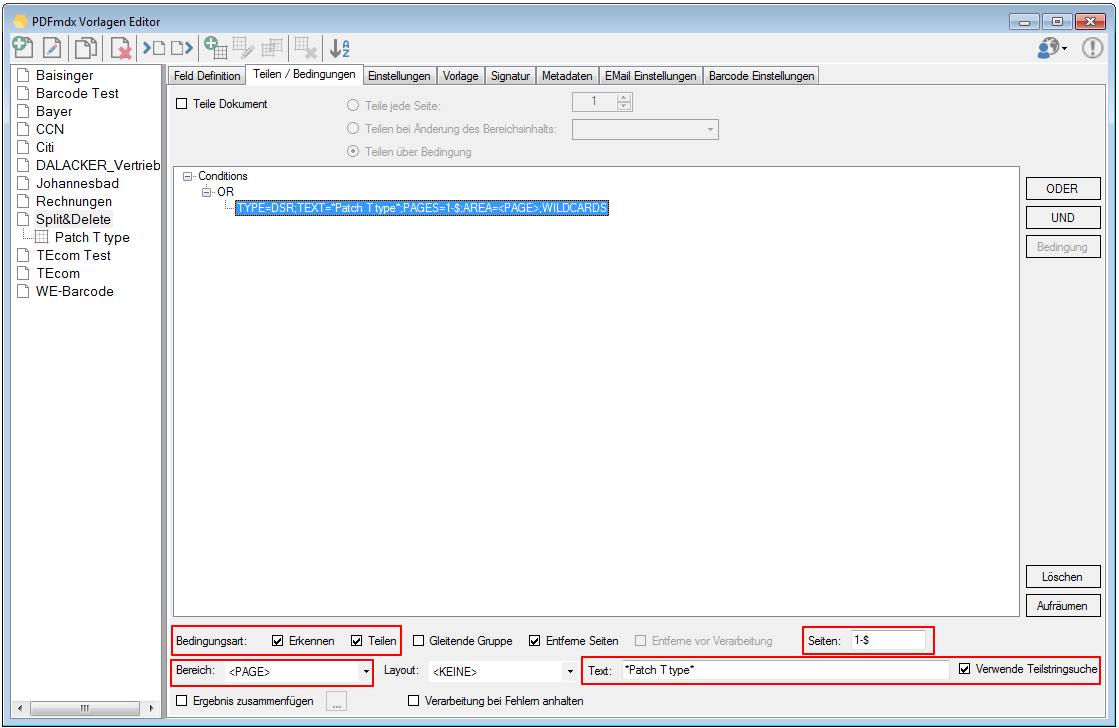
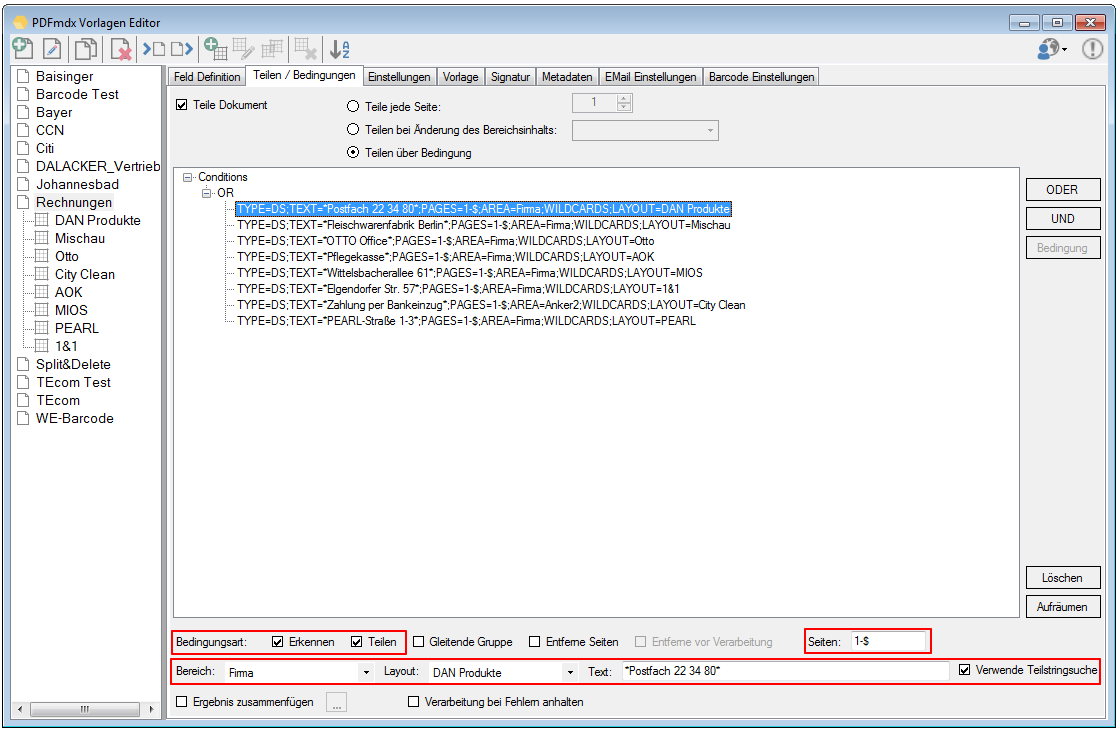
- Pre-split of document stack with reference to layout or template – Are different layouts or templates contained in a stack of documents, and the various documents to be recognized on the basis of criteria and divided into individual documents, so this should be done in PDFmdx processor using the “up-front parts, if the layout or template changes “. A in a layout defined “S = Split” condition affects the stack of documents only with the same layout, not across different layouts and templates. Exist the documents to be processed already as separate individual documents, so this option is not needed.
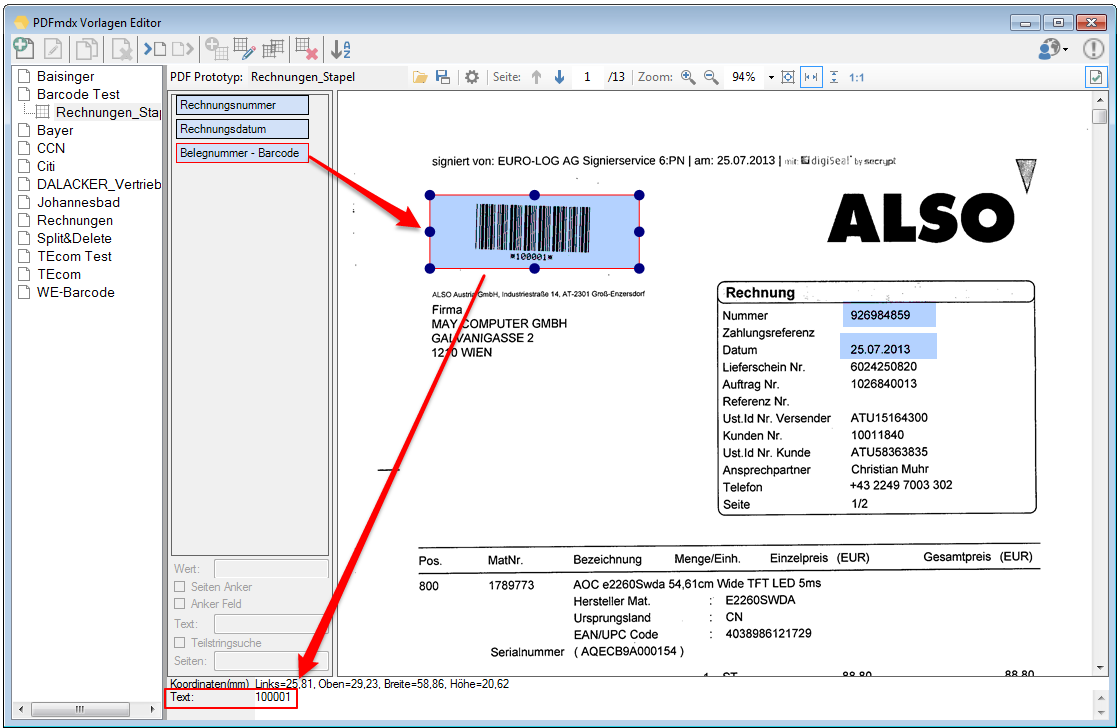
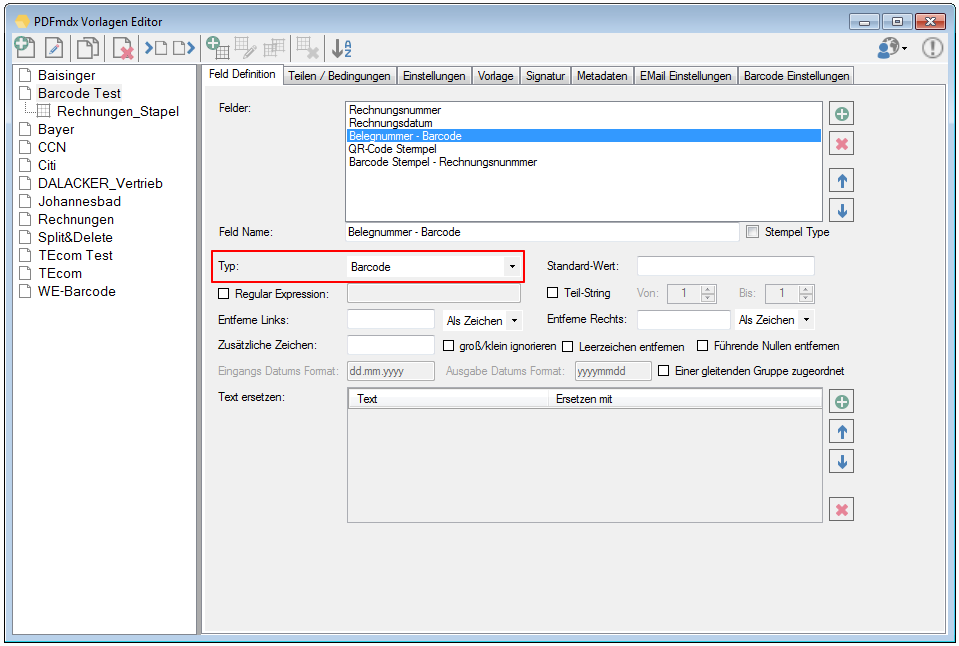
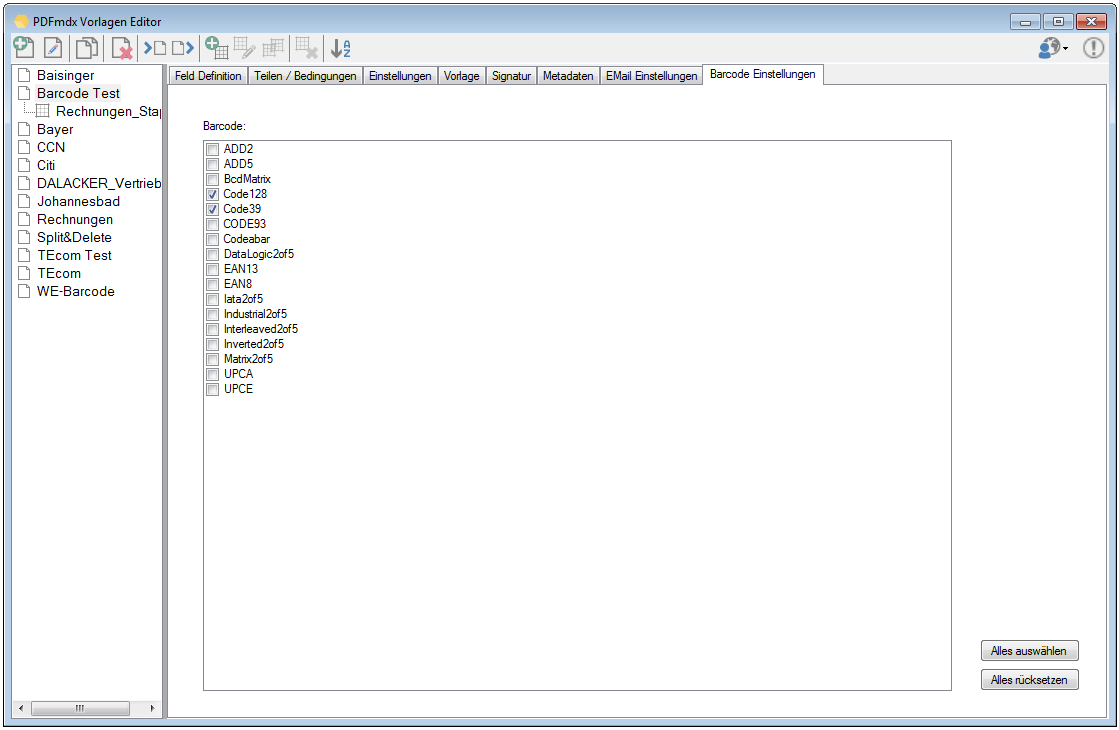
- Barcode – Recognition – The field types, there is now the option of selecting “barcode”. So 1D barcodes can be recognized within the marked field area. The bar code value is returned as a field content. On the bar code settings can be set which barcode types to be detected. The barcode recognition is performed directly at the field position and in test function. So is immediately visible whether the bar code is recognized and what is the value of the barcode.
- Date- and Time-Format of the Output-Variables configurable – The format for output variables% DATE% and% TIME% can now be specified individually on the variables “dd” “mm” “yyyy” and “hh”, “mm”, “ss”.

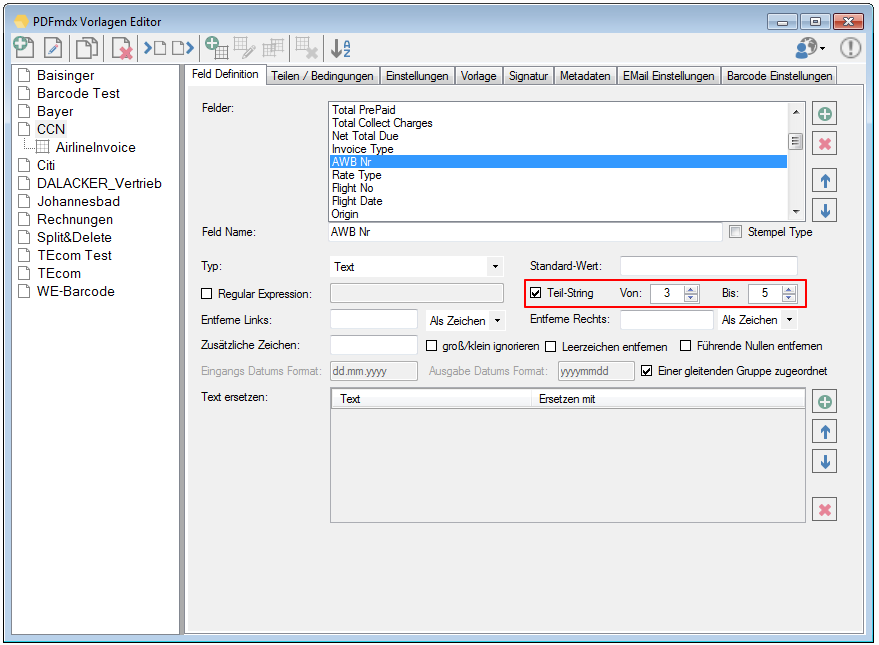
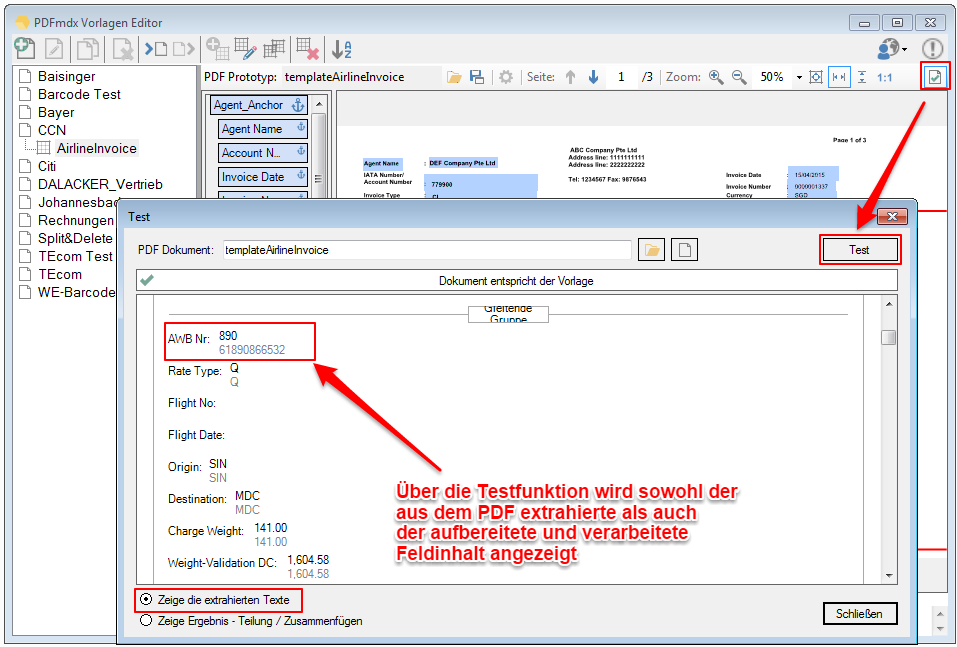
- Test function displays the extracted and conditioned field contents – For the test function the display of the PDF Extract, and also conditioned by the field definition Field contents, which are used by PDFmdx for further processing.
- Text bzw. 1D/2D Barcode Stempel aufbringen – PDFmdx can read texts from PDF documents and it may text or barcode stamp applied to the pages. In this case, fixed text, standard variables such as date, time, calculator, user, template name, layout page number, page number overall but also read out field values are used on configured variables. For text-stamp font style, font size, color, and formatting are – bold, italic, outline, underline, strikethrough as parameters available. The text alignment can be selected within the position box – Left / Center / Right, Top / Center / Bottom. A value can also be applied as a 1D / 2D barcode stamp. There are 36 types of bar codes to choose from. Another parameter determines whether the stamp to be applied to specific pages in a page area, on all pages or only on the last page.