DropOCR – version 1.2.5 available
Innovations DropOCR version 1.2.5:
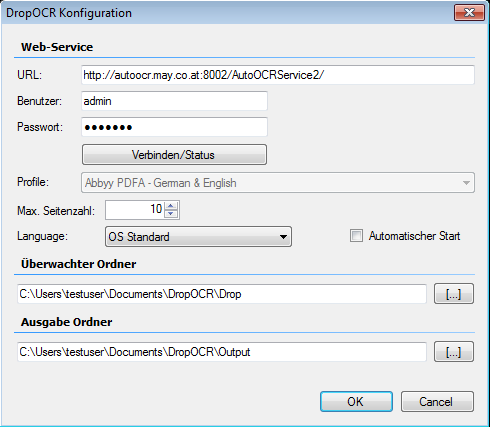
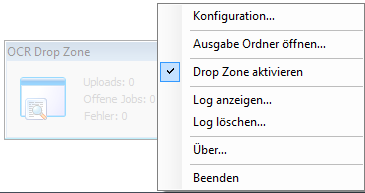
- Direct selection of the AutoOCR processing profile through the context menu of the icon tray application
- function “Cancel all jobs” – with that currently running transfers and processes can be canceled immediatly
- The “AutoStart” Option is now activated by default
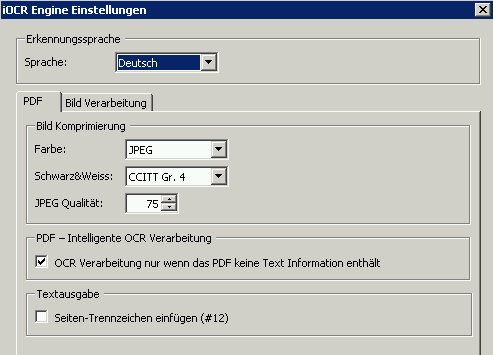
- The max. page amount is now preset to 1000 by default
- The connection data of the AutoOCR testserver are already preassigned with the installation
![]()