New features PDFmdx template editor:
- Update of all PDFmdx basic components: Our general basic components PDF2PDFA, PDF2DOCX, PDFSign, PDFCompressor – were brought up to date.
- Templates / template groups: An additional “group” level has been implemented to enable clarity and management of a large number of templates. This allows templates to be grouped together. In the PDFmdx Editor, the groups form the top level in the tree view. Groups can – be created, the name changed, deleted or moved up and down. Templates of a selected group can be exported or imported as a whole or individually. Templates in a group can be moved to a different or a new group.
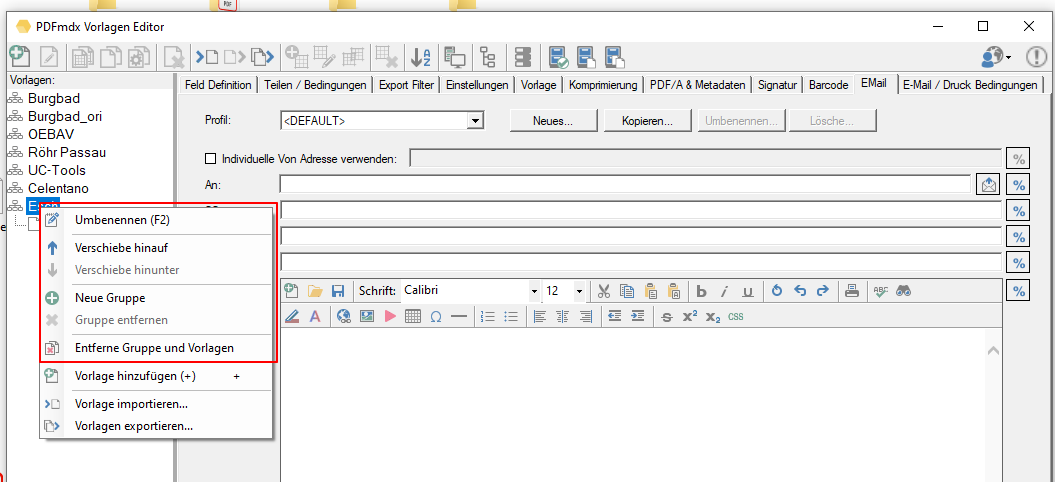
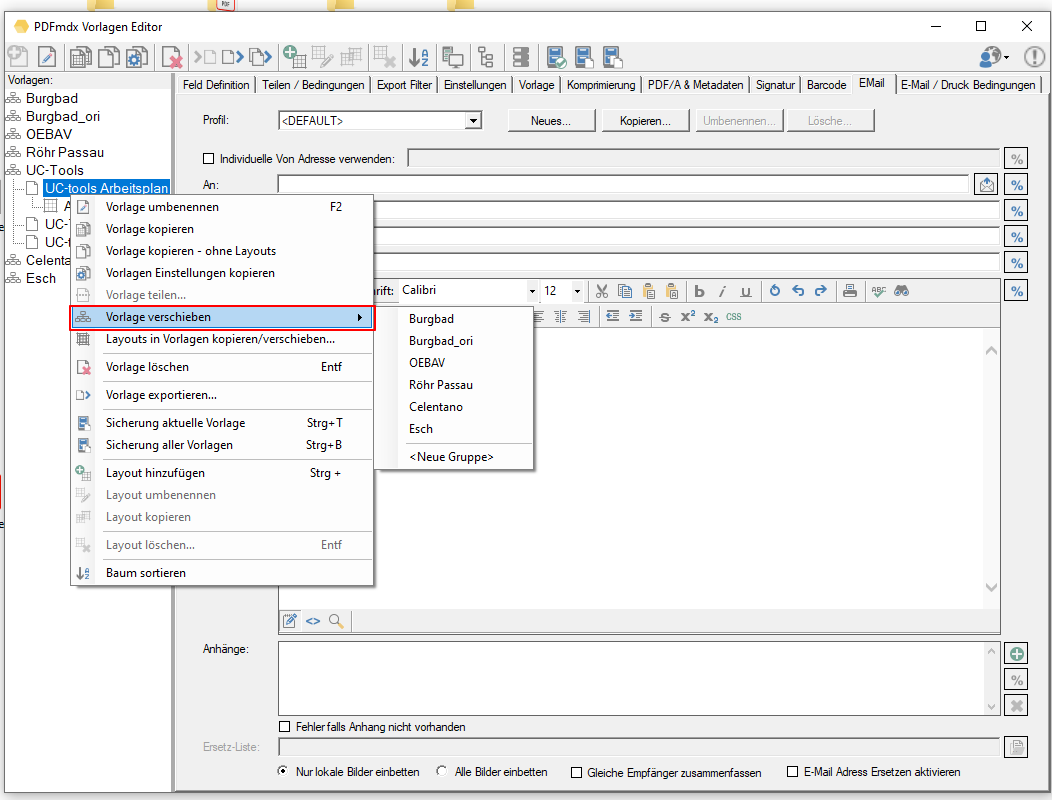
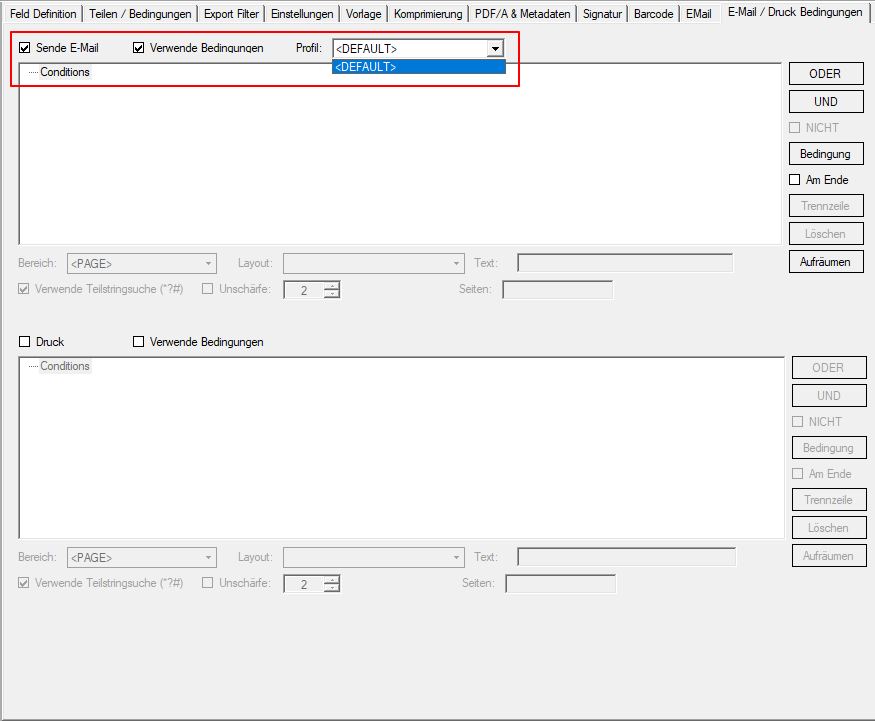
- E-Mail – Configuration via profiles: Several email configurations can now be created in one template. The e-mail configurations are managed using profiles with names. E-mail profiles can be created, copied, renamed and deleted. A specific email profile can be assigned to the email conditions. This means that not only the e-mail function itself, but also the e-mail profile to be used can be controlled via conditions.

- E-Mail – Use of variables for attachments: Up to now, only fix selectable and therefore predefined attachments could be sent with the PDFmdx main document by email. Now it is also possible to use variables for the path and file name of the additional attachments. An option can be used to determine whether, if an attachment does not exist or cannot be found, the email is sent anyway, or whether it should be treated as an error. During configuration, a file is first selected, inserted into the list, then edited and the variables added.

- E-Mail – Main document always as the first appendix: When sending an e-mail, additional attachments can be sent in addition to the main document generated via PDFmdx. Now the main document generated by PDFmdx is always inserted as the first attachment, the other additional attachments are always inserted after.
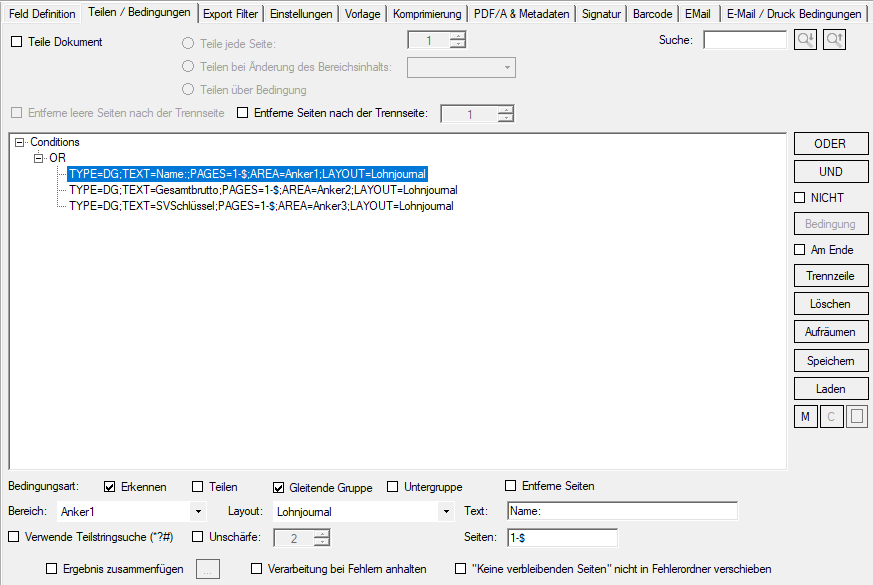
- Sliding group over 2 pages: With some documents it can happen that a data record of a sliding group begins on one page and continues on the next page. Up to now, sliding groups have only been identified via a condition (DG) for the start of the group. The data record is recognized, but cannot be read out completely, as part of it is on the following page. In order to include the information on the following page for such cases, at least two “DG” conditions with OR / OR link are required. One for the beginning and one for the rest of the record on the next page. This means that the entire data record is recognized and processed, even if it is on separate pages.
- Metadaten as XLS: Some downstream applications can only process the old XLS and not the current XLSX format. That is why the XLS format for the metadata output has now been implemented again.
- New PDF preview functions – display text layer / display text blocks: A scanned PDF that has been made searchable via OCR consists of both an image and a text layer. The image plane shows that only the scanned document. From this point of view it cannot be seen whether, where or which text is behind it. In the PDFmdx Editor preview there is now the option of showing only the text layer and hiding the image layer, as well as the option of showing the boundaries of the text blocks as green rectangles for each of these displays. This makes it easy and quick to see which text is available and where exactly the text blocks are located.

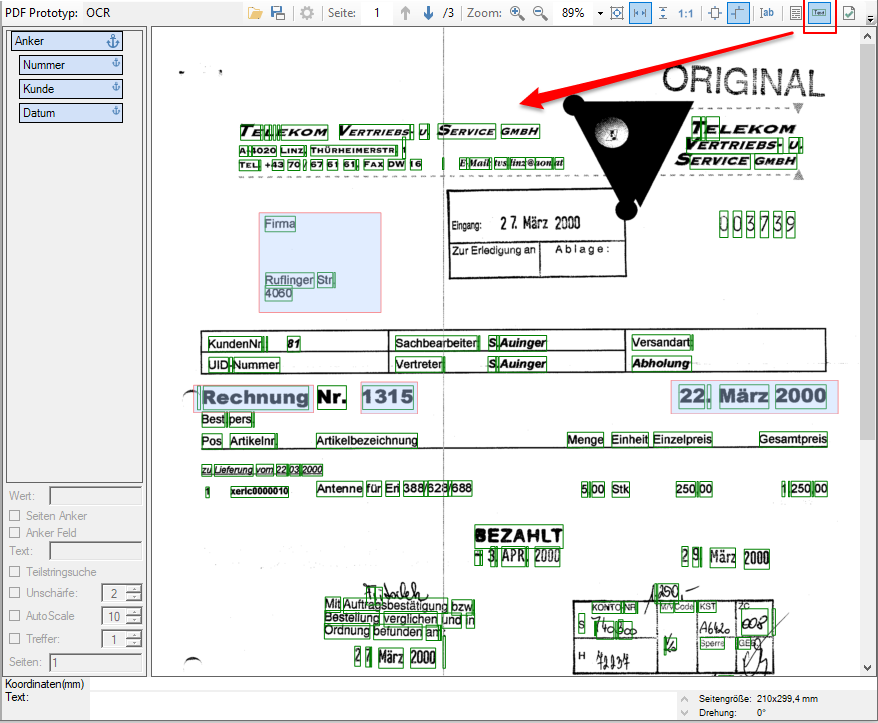
- Fields / Variables – Replacement of values via XLSX table: Bisher konnte nur eine CSV Datei verwendet werden um die Werte von Feldern/Variablen zu ersetzen. Jetzt ist es auch möglich eine XLSX Datei zu verwenden. Konfiguriert wird der Name der Spalte für den Suchschlüssel sowie die Spalte für den Ersatzwert.
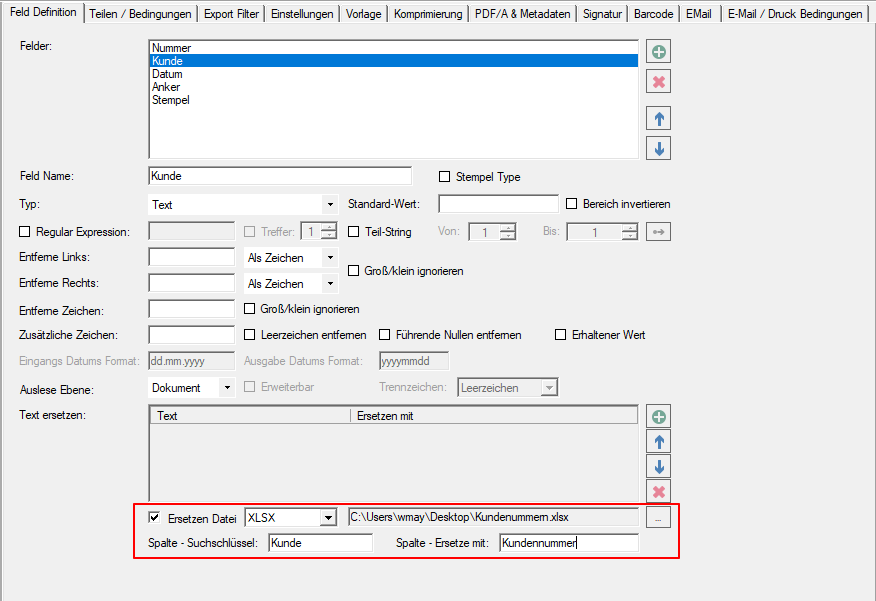
- Counter as a stamp variable: There is now also a counter variable for text or barcode stamps. An option can be used to configure whether the counter should be increased when it is used several times within the document or only with each new document. The start value can also be specified.

- Visual PDF signature – support for transparent image files: With the current version, transparent image files (PNG, TIFF) can also be used for the visual representation of the PDF signature.
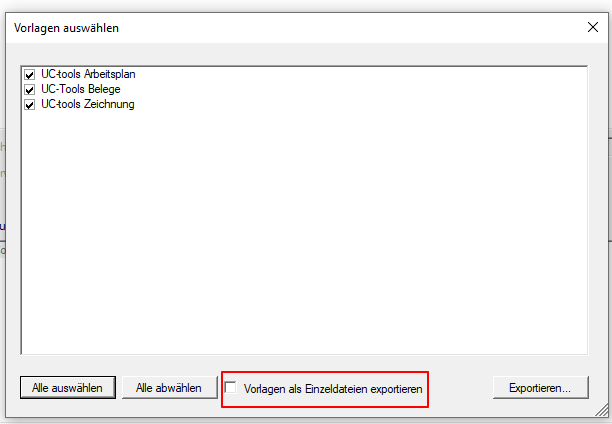
- Export templates as PMDX individual data: Previously, several or all templates could only be exported as a single PMDX file. or if you wanted to export several or specific templates as individual files, this had to be done individually for each template. Now, via an option from a template group, each template contained in the group can also be exported individually as a separate PMDX file. The template name is used as the file name.
Innovations PDFmdx processing:
- Recognition and export of a ZUGFeRD XML file contained in the PDF: This option can be activated for the PDFmdx job. Each PDF file to be processed is checked in advance to determine whether it contains a ZUGFeRD XML file. If such an XML is contained in the PDF as an attachment, the XML is extracted from the PDF and saved in the configured folder under the PDF name with the extension * .XML. If the option “Move PDF” has been activated, the PDF will also be moved to this folder and will not be processed by PDFmdx.

- Activate all layouts automatically: If a new layout is added to a template, this layout must also be activated in the PDFmdx processor during the job. Up until now, this had to be done manually and was sometimes “forgotten” so that the newly created layout is not recognized. For a template as well as for the job configuration there is now an option to activate all layouts automatically. This means that all newly added layouts are always automatically activated and can no longer be “forgotten”.

- Error log with header: In order to be able to interpret the content of the individual columns of the error log (Error.csv) more easily, a header line with the names of the columns was inserted to get a conclusion about the information of the fields.
PDFmdx corrections:
- E-Mail HTML Body – File names for images can now contain spaces.
- Anchor field not found – Linked fields now remain empty and are not assigned any values.
- Fuzzy anchor search function has been improved.
- Error message – XLSX blocked: Over time, an XLSX metadata file can become very large. It has happened that opening and writing this XLSX took longer and several processes wanted to access this file. This led to error messages, access was not possible because the XLSX was still blocked by another process. This problem has been resolved. Nevertheless, care should be taken to ensure that such metadata files do not become unnecessarily large.
- Sliding group – Recognition was not possible with PDF with “Display Rotation”.