New features PDFmdx template editor:
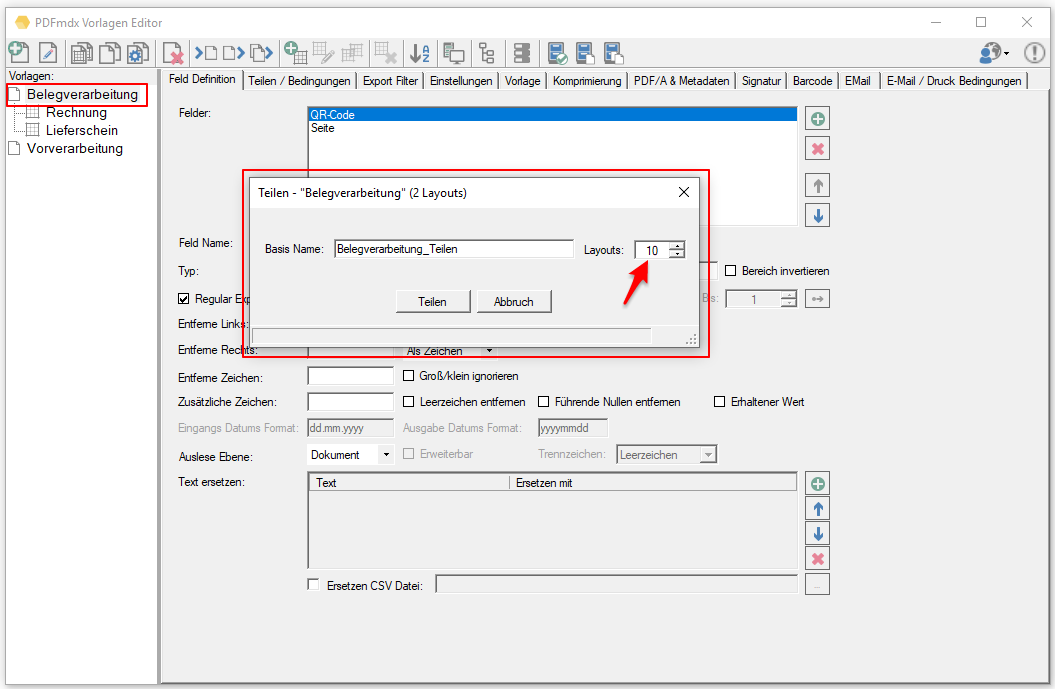
- Split templates: Templates can contain a large number of layouts and conditions over time. E.g. if a template contains several hundred layouts, the processing of these becomes slow and confusing. For this it is advisable to use several templates and to divide the layouts. It makes no difference in terms of processing. There is now a separate function for dividing up existing templates. The number of layouts per template is specified. The PDFmdx Editor then automatically generates copies of templates and divides the layouts and the associated conditions. After that, each template only contains the specified number of layouts.
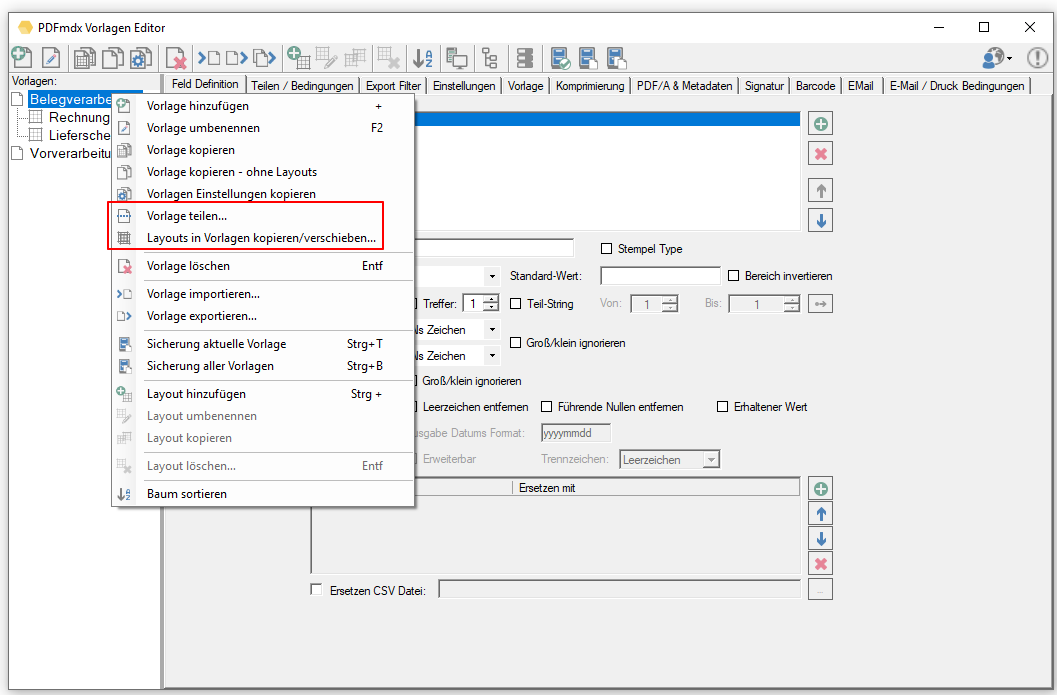
- Copy / move layouts: Together with the “Split templates” function, the function for copying or moving layouts to one or more other templates has been expanded and implemented. So far it was only possible to copy one layout into another template. The layouts (one or more) and the target templates (one or more) can now be selected in a template. It is also possible to move the selected layouts and not just copy them. The fields and their position in the layout are retained or added to the target template.

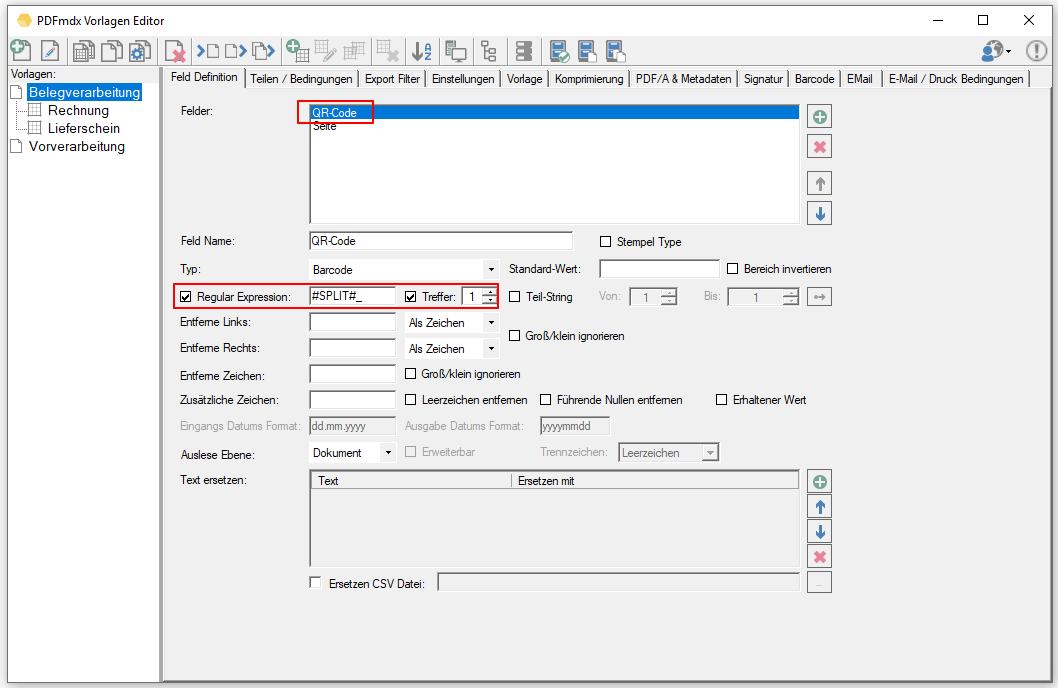
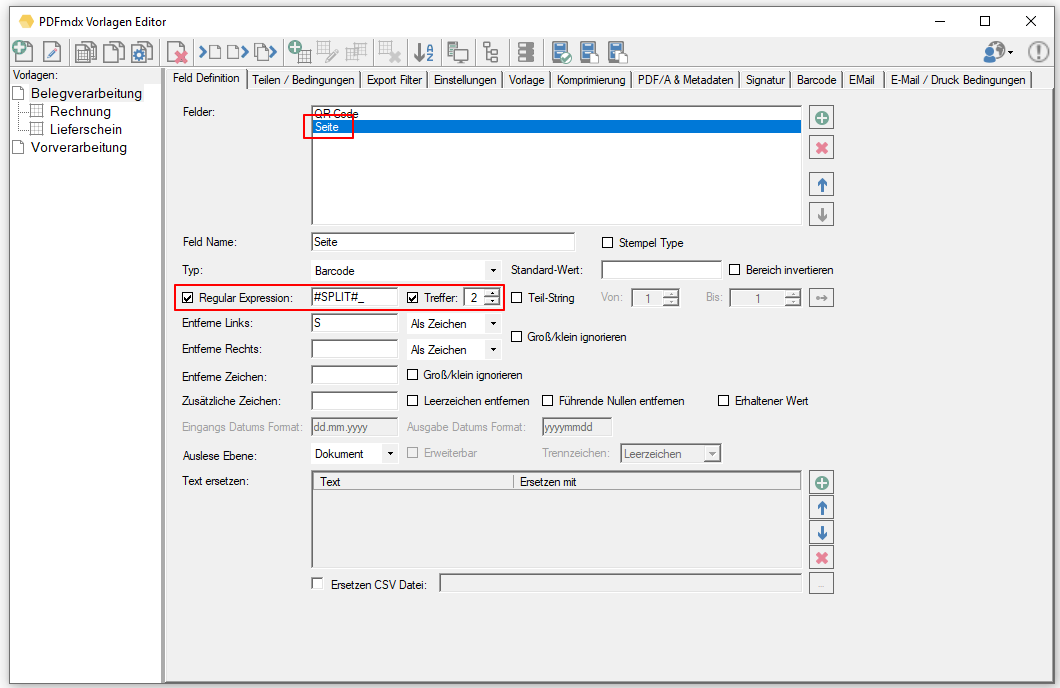
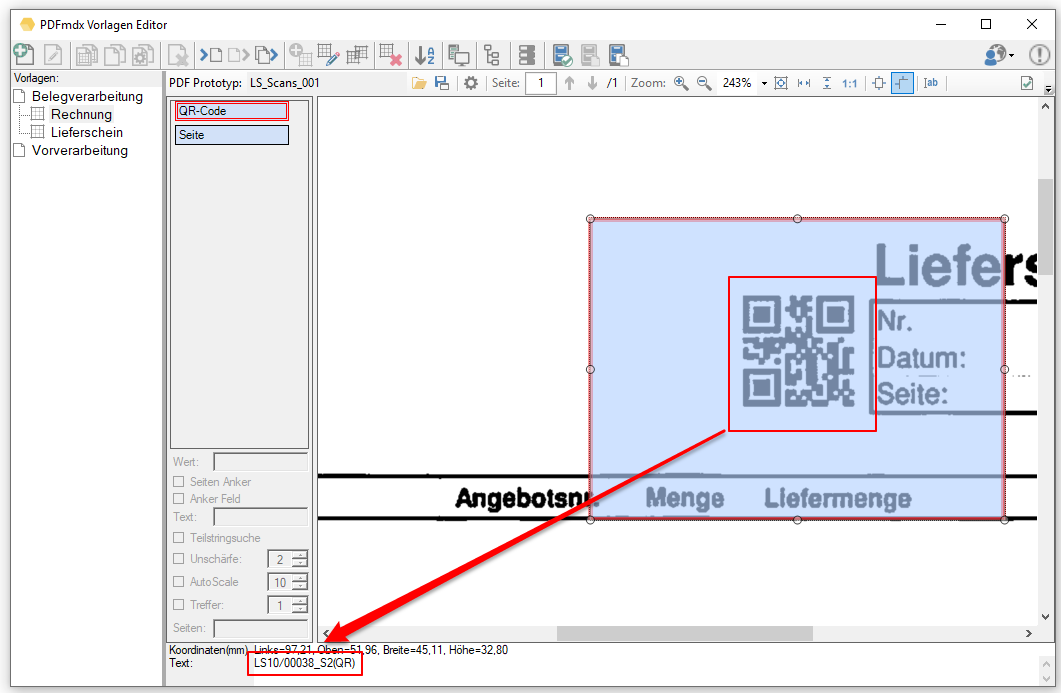
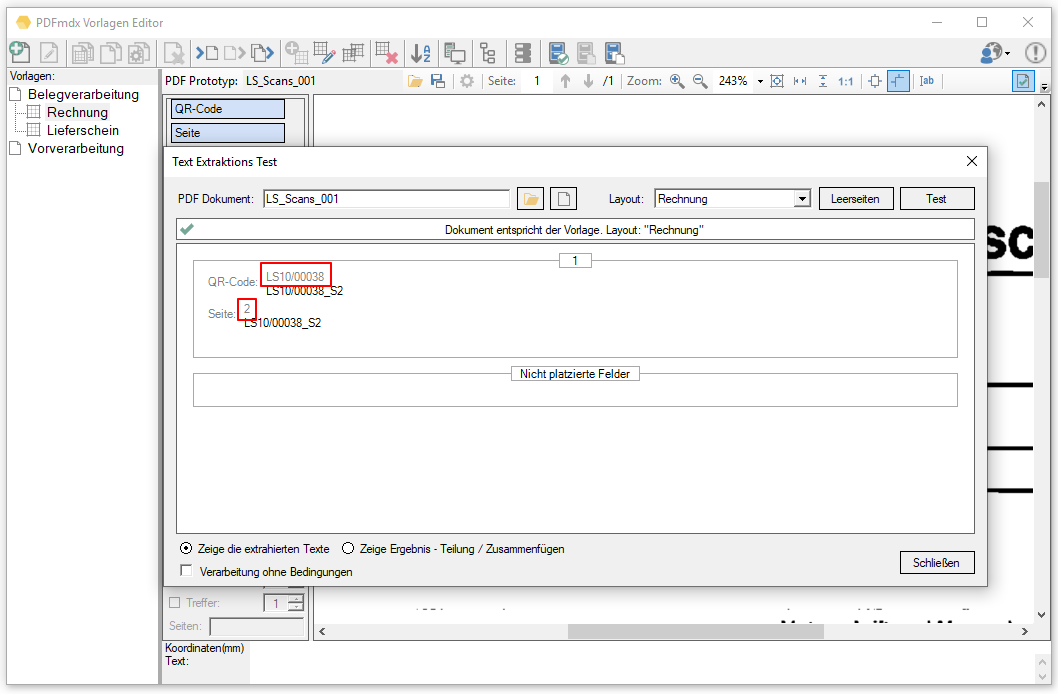
- Read out partial areas of fields: When reading out field contents, there is now a new function to get a specific part of a text in a targeted and simple manner. E.g. if a single field contains all information and is separated by a “/” separator. e.g. “XKEY GmbH \ Gerstlgasse30 \ 1210 \ Vienna”. With the help of the newly implemented Regex function, by specifying “# SPLIT # \” plus the position in the string, you can configure which part is to be read out and used for the assignment of the variables. For example the zip code = 1210 can be read out and determined by specifying “# SPLIT # \” + “3”.
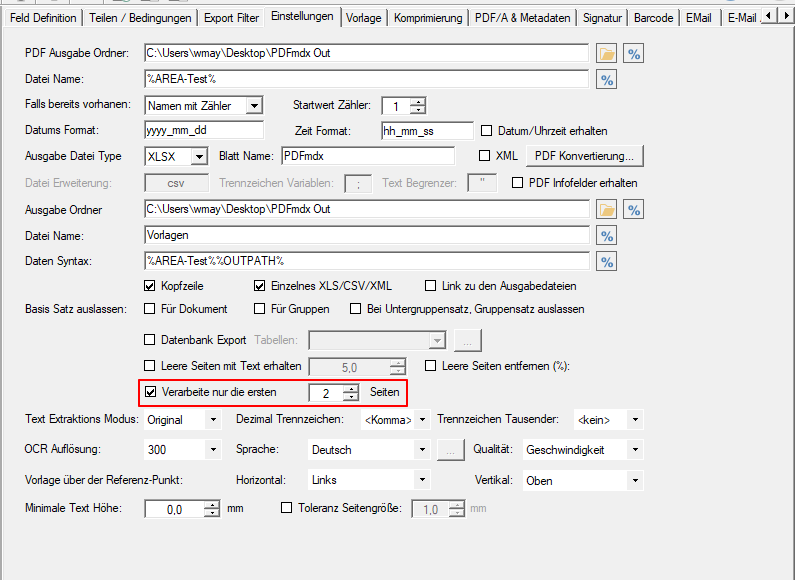
- Configurable page limit for processing: The information required for processing is often only found on the first or first page. In order to speed up the processing of very extensive PDF documents, which can also contain several hundred pages, a page limit (e.g. 2) can now be set for the template. This defines that only the specified pages and not always all pages of the document are read in and processed.
- Condition editor
-
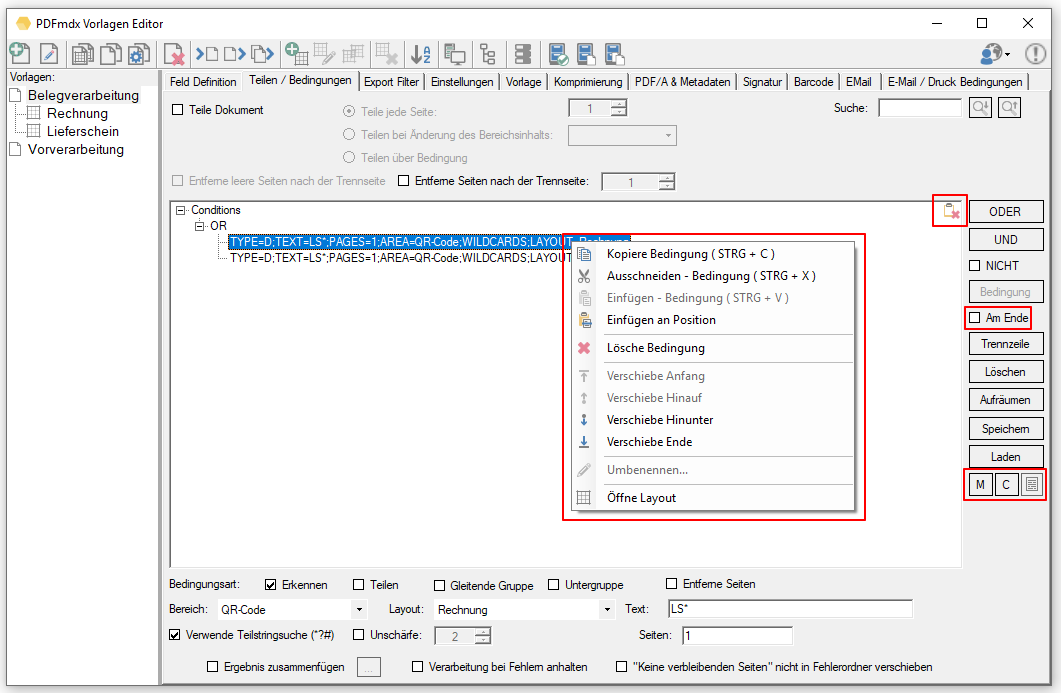
- Individual conditions, substructures but also the entire condition tree can be copied from one template to another using the clipboard.
- Separator lines can be copied / cut and pasted at any point in the structure.
- (M) emory function to use an existing condition as a preliminary consideration for all newly added conditions. M – sets the currently selected condition as default, C – deletes this default again. This preset is template-specific and is saved and restored with it.
- Checkbox to determine whether a new condition to be created is inserted at the beginning or at the end of the current level in the tree structure. Previously, a new condition was always inserted at the beginning of a node level, which meant that with large tree structures it was always necessary to move the condition downwards to get back to the starting point.

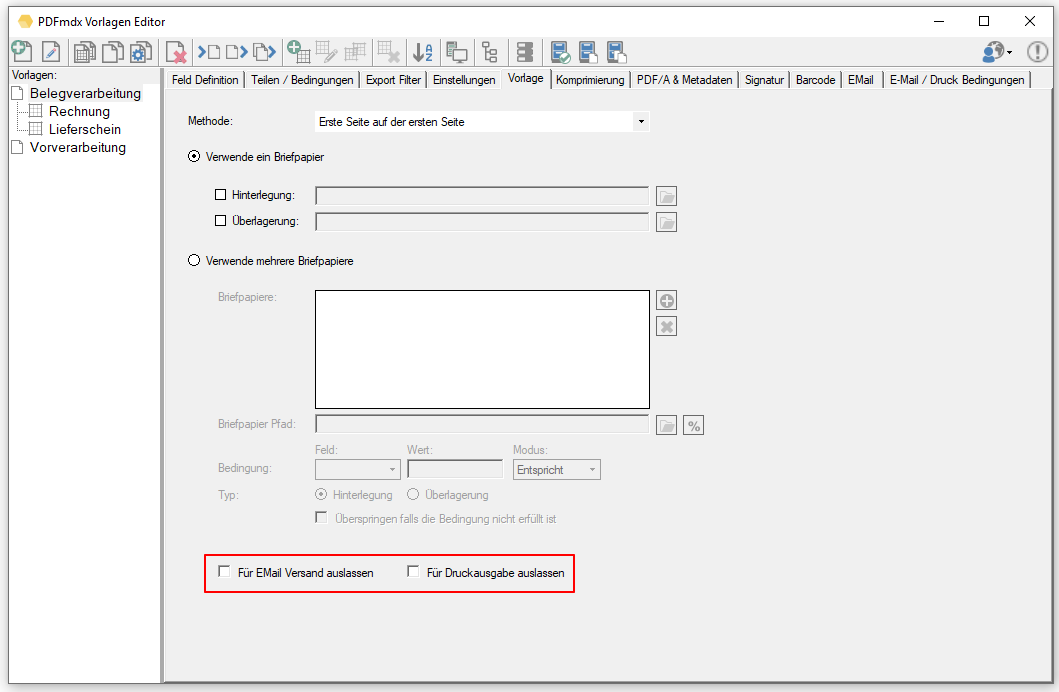
- Do not use letterhead when printing / sending emails: If documents are output on a printer or sent as email, it may be necessary not to use the letterhead for printing because the printer already contains letterhead, but the email should be sent with letterhead. This option can be specifically controlled.
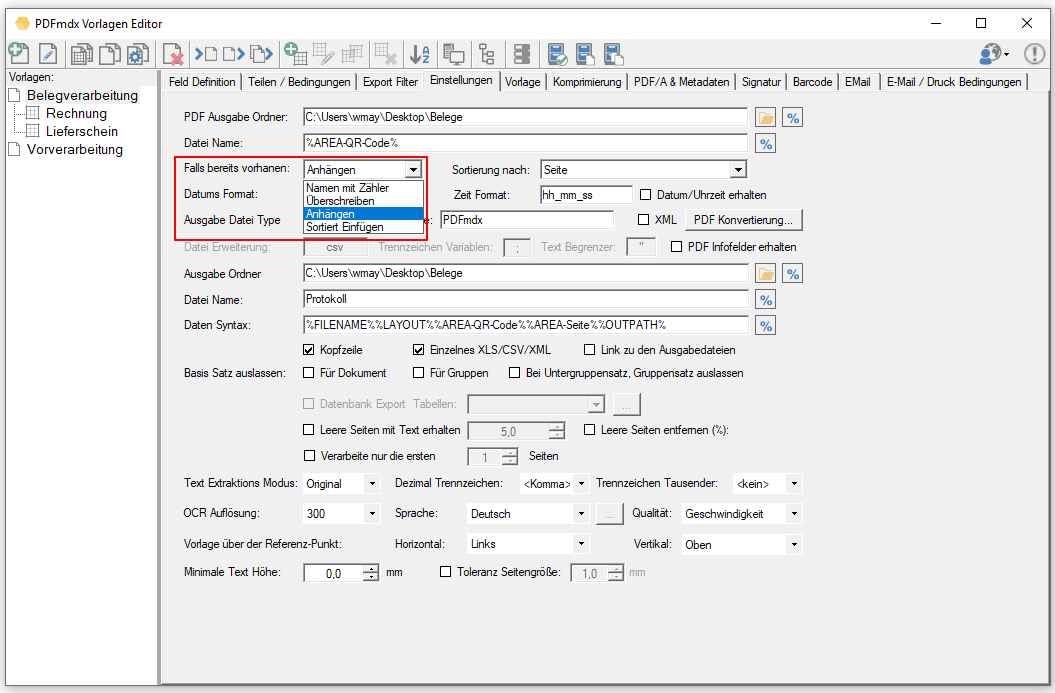
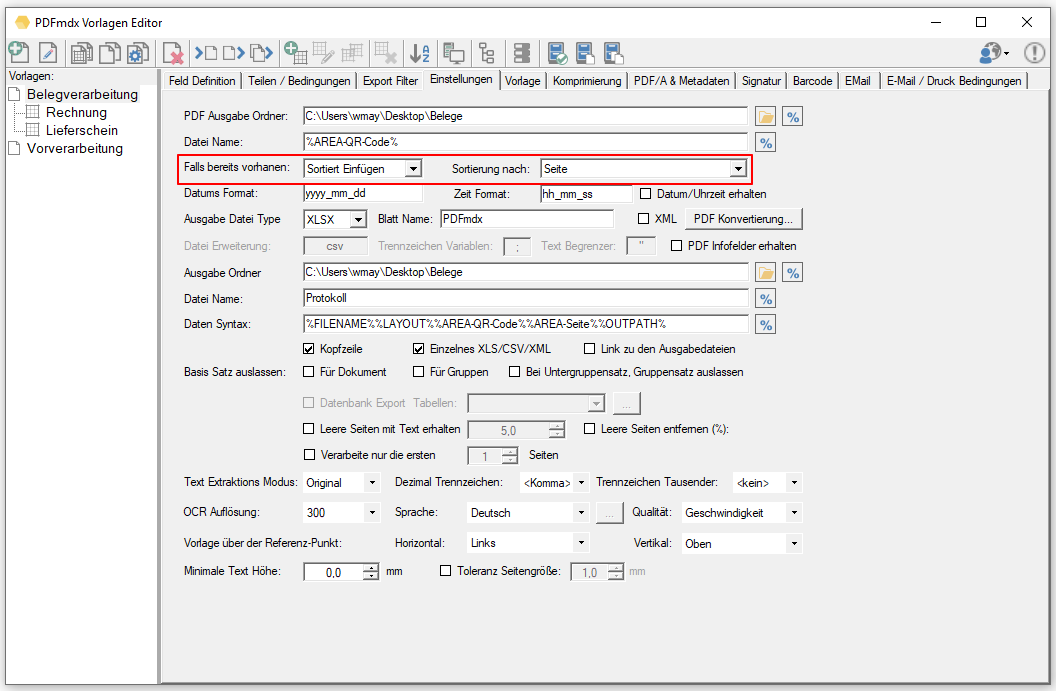
- Combine individual documents in a sorted manner: In order not to have to pay attention to a certain order / sorting when entering documents, or to combine individual documents sorted into an overall document using the field content that has been read out, 2 new functions – “Append” and “Insert sorted” have been added to the Output configuration implemented.
- “Attach” – If a PDF with the same name is found during the output, the new file is appended to the end of the existing file.
- “Insert sorted” – During the configuration, a field must be selected according to which the sorting should take place. A PDF bookmark is created with the text of the selected sort field. If a file with the same name is found in a subsequent output, the new document is inserted or appended in the correct place in the PDF using the sort field. “Empty” or the same content is added at the end.
- PDF display rotation is taken into account: PDF files can contain (0,90,180,270) parameters via a “display rotation”. E.g .: Can the display of documents that have been scanned rotated be corrected accordingly using the “Display Rotation” parameter in order to always display the pages in portrait format. However, the parameter is only used for display on the screen; internally, however, the PDF data structure is still rotated (e.g. upside down). The current version of PDFmdx recognizes the PDF “Display Rotation” and takes it into account so that the display corresponds to the processing and the fields are read from the correct positions.
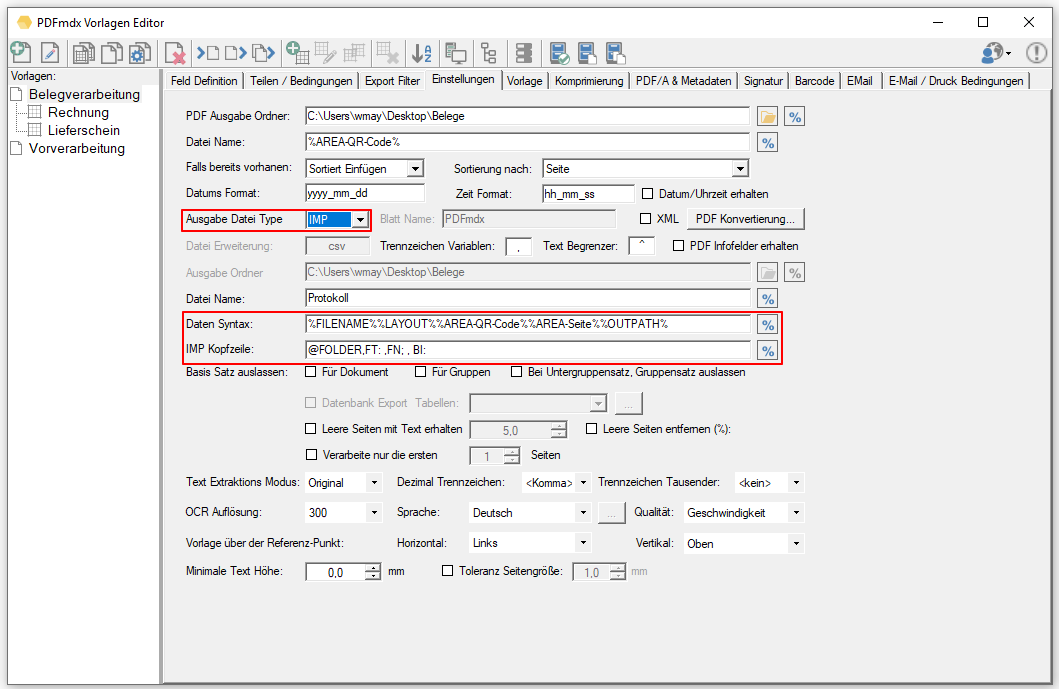
- EasyArchiv (IMP) Export Format: The EasyArchiv IMP metadata output format is a kind of CSV format. It contains an individually configurable header line as well as subsequent lines with the PDFmdx metadata. The field delimitation is the “^” and the field separator is the “,” (comma). As with all other formats, fields / variables are available for selection for the following lines.
Example of an IMP header: @ FOLDER, FT: B2B_Netz, FN: Partner, FN: B2BMessageID, FN: MailMessageID, FN: RefNr, FN: Sender, FN: B2BSystem, BI: 2001
FT: = document type, FN: = field names. This line must be configured individually according to the archive into which it is to be imported.
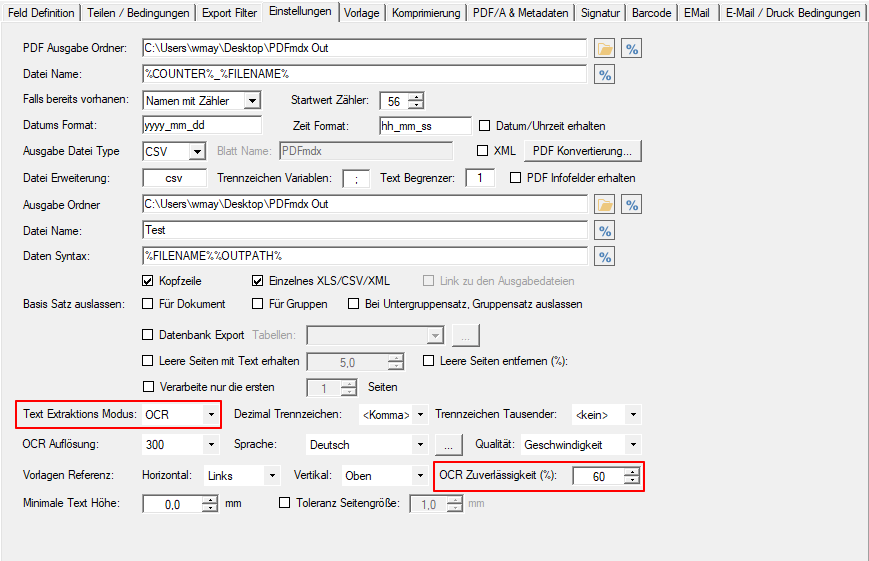
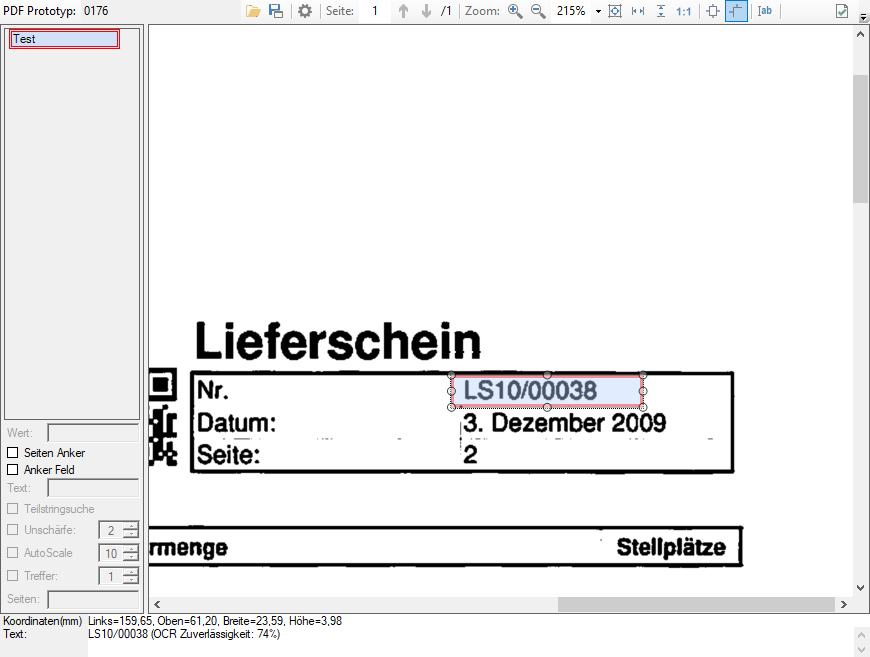
- OCR reliability in the OCR area: PDFmdx also offers the option of determining the text from the image using an OCR function for the positioned fields. Up to now, the OCR reliability was fixed internally at 60%. This threshold value can now be configured and is also output as information in the preview for the text output in the footer of the PDFmdx editor.
Innovations PDFmdx processing:
-
-
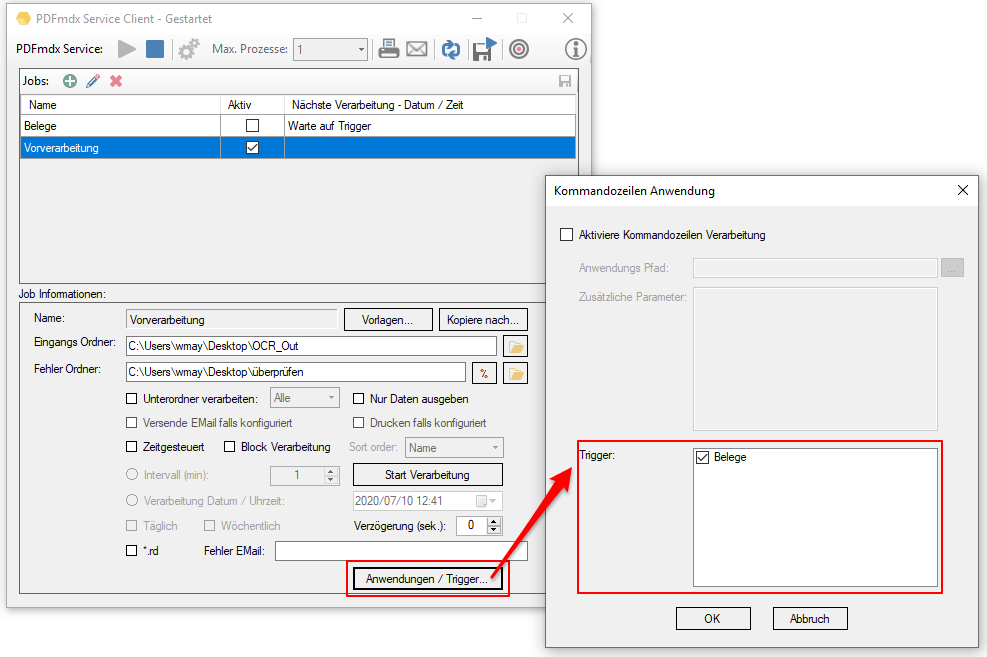
- Job Trigger Funktion: The start of processing of one or more jobs can be triggered by the end of processing of another job. All jobs that are started via a trigger must be deactivated in the job list, otherwise processing is triggered via the Monitoring folder and not via the trigger. With these jobs, the start of processing is only triggered by the trigger of another job. Sorted processing can also be ensured by a trigger. The next processing step is only started after all files of a previous job have been processed.
-
-
-
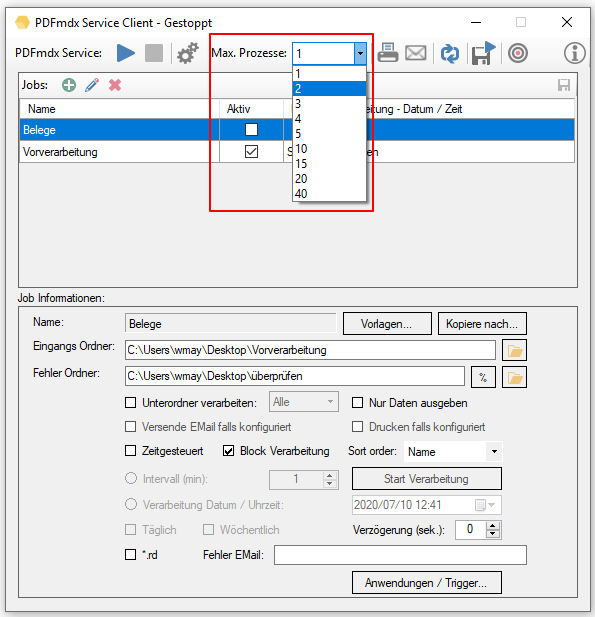
- Sorted processing of incoming files: Files in monitored folders can now also be processed in a sorted (ascending / descending) manner according to name, size, creation and modification date. To do this, the “Block processing” option must be activated. The start of sorted processing requires a defined point in time. It can be triggered by the interval timer, at a set time, by an * .rd file, by the trigger of another job or by pressing “Start processing”.
-

-
-
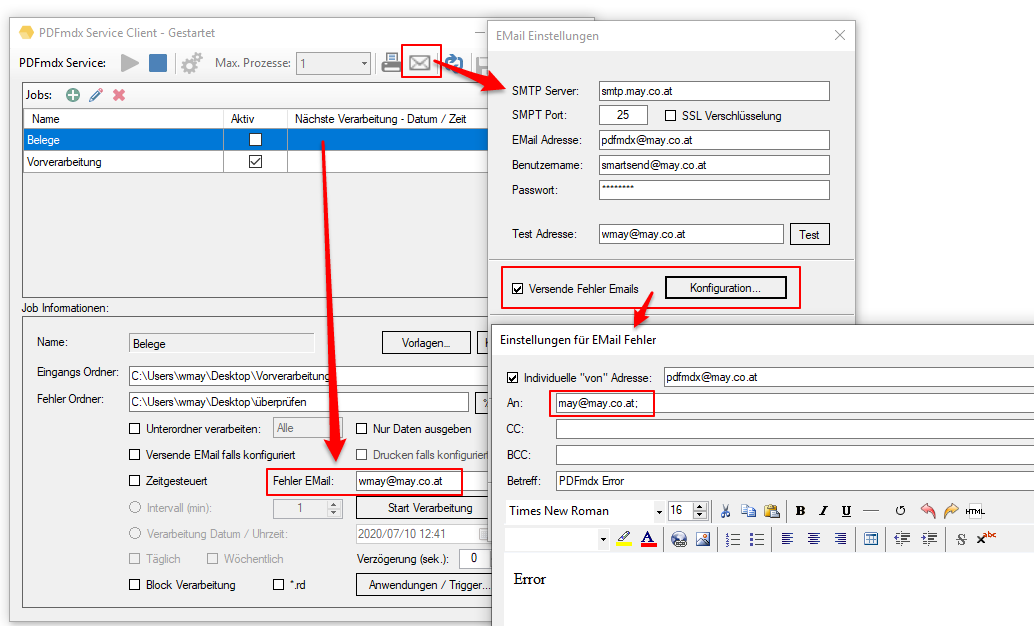
- Error email address per job: An individual error email address can be specified for each job. This overrides the error email address that is generally defined in the PDFmdx processor and applies to all jobs.
-
-
-
- Parallel processing: Is carried out on the basis of the jobs, but not in order to process several documents in parallel within one job.
-