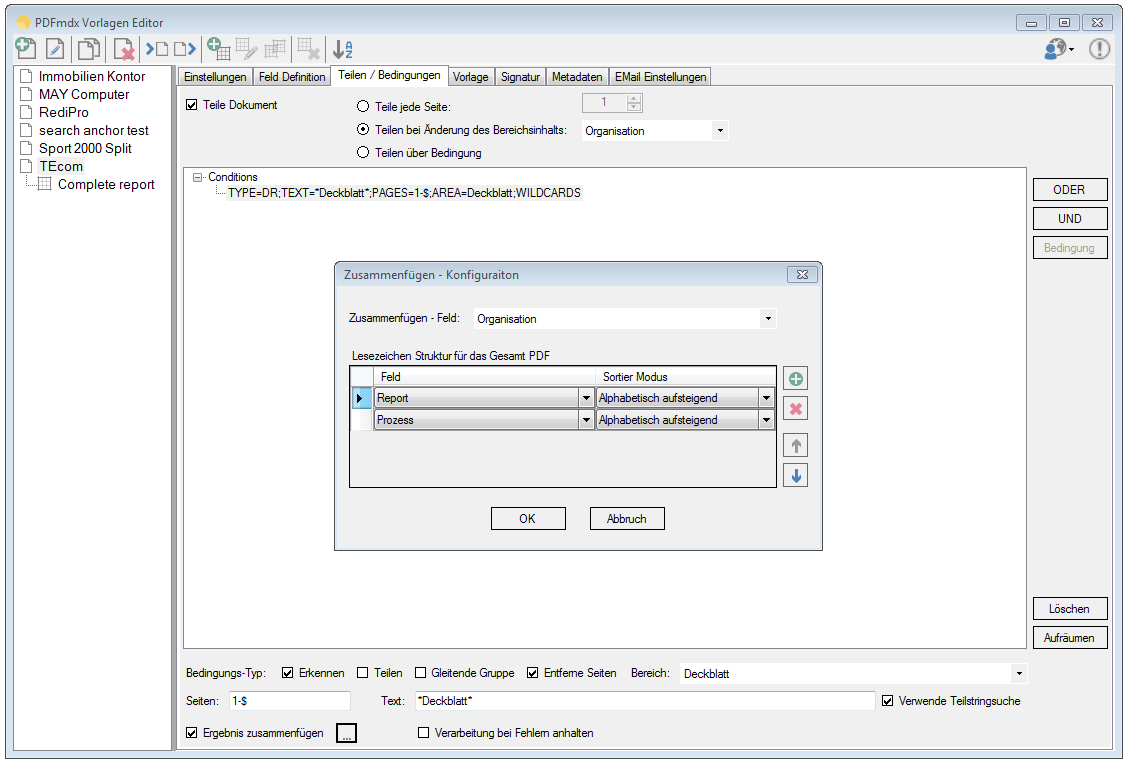
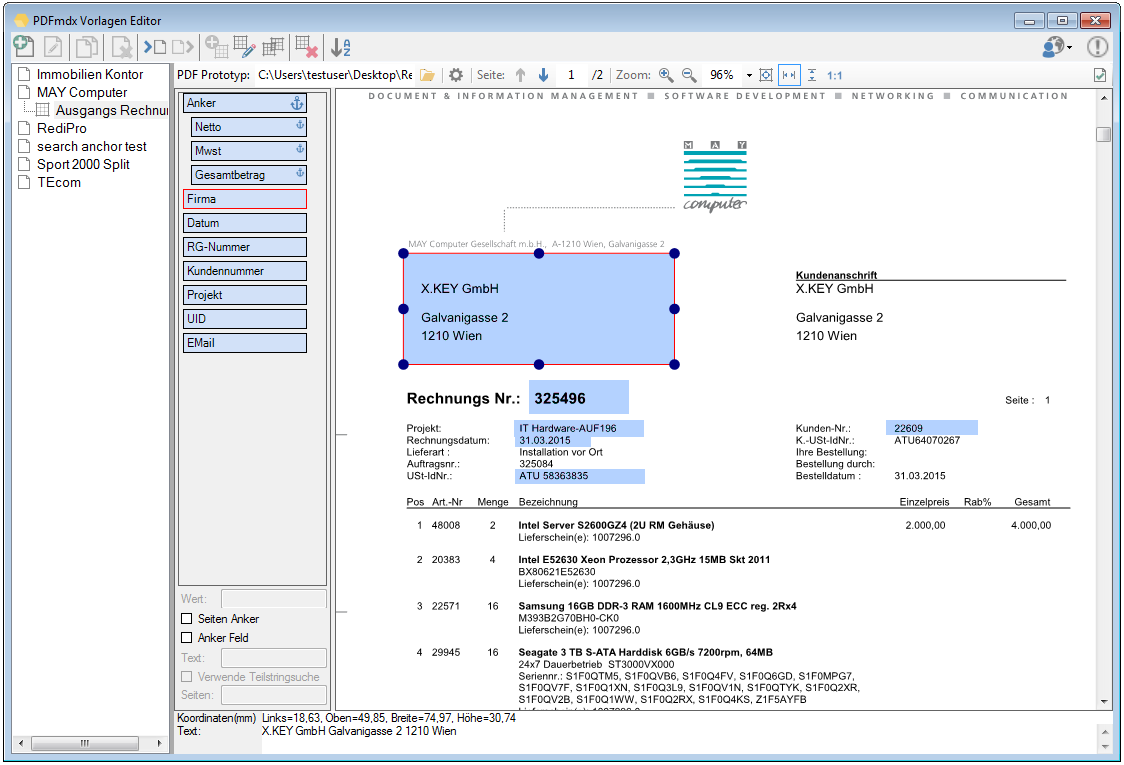
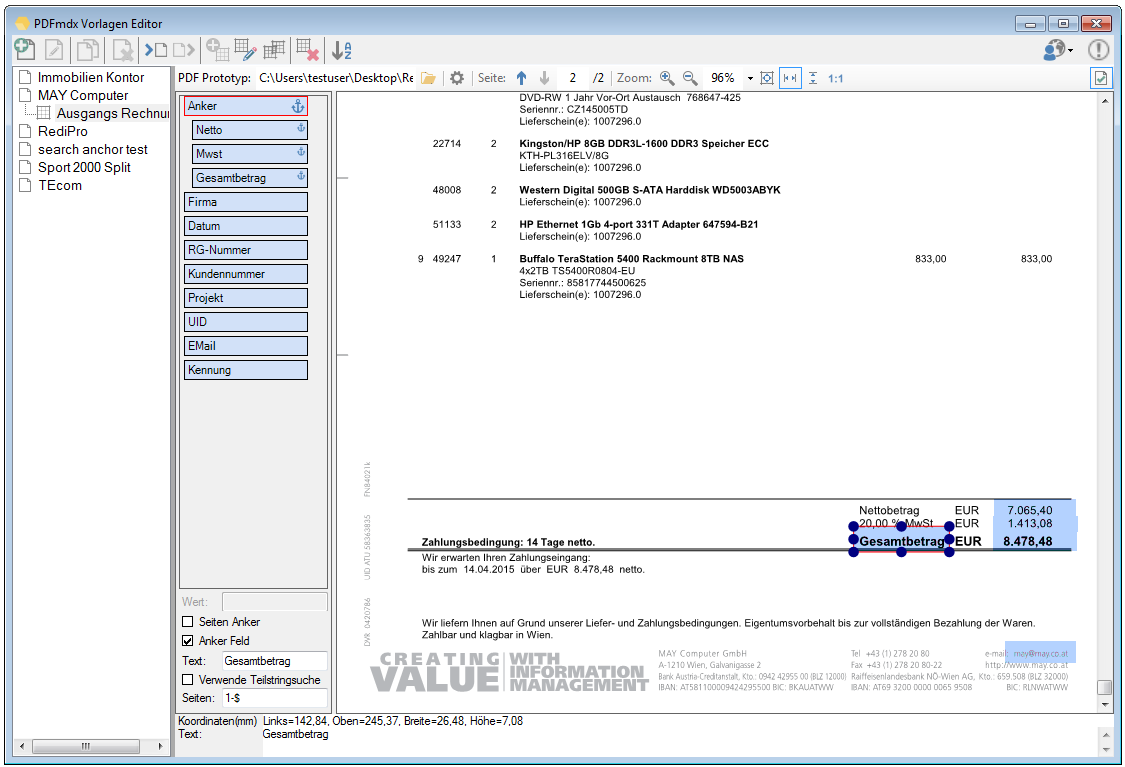
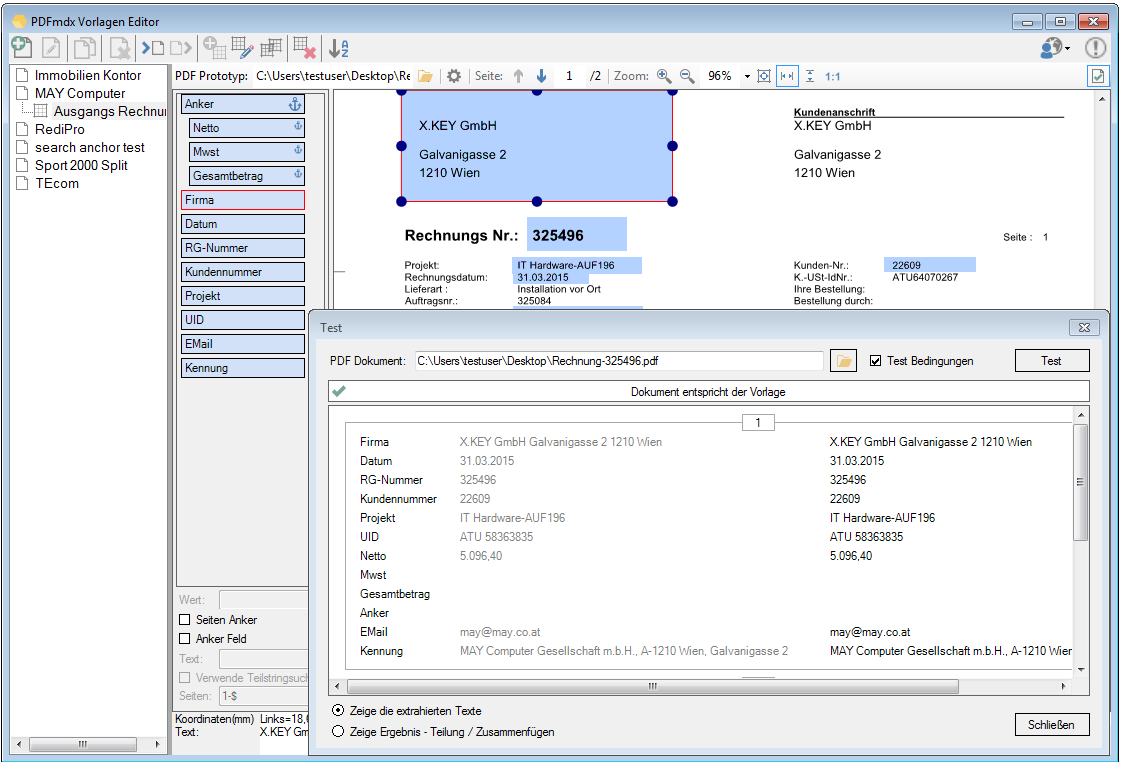
PDF2PDFA Anwendungen jetzt mit PDFCompressor und PDFSecureSign Option
In die PDF2PDFA Anwendungen
- PDF2PDFA-CL
- PDF2PDFA-FM
- PDF2PDFA-CS
- DropPDFA
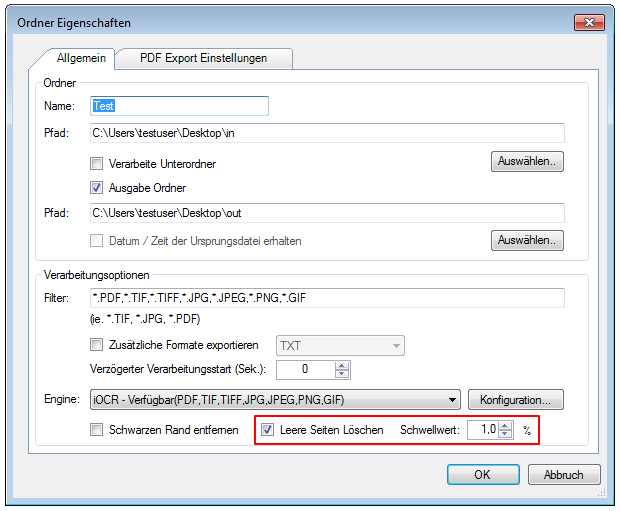
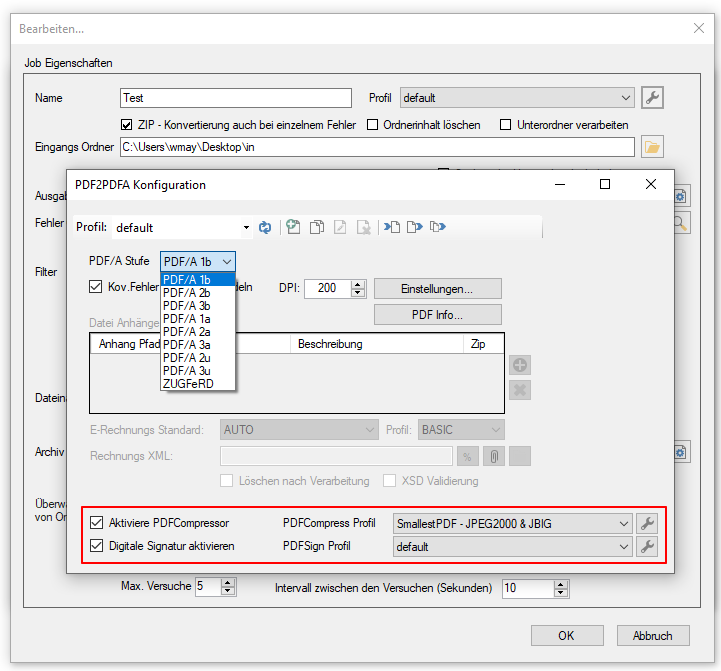
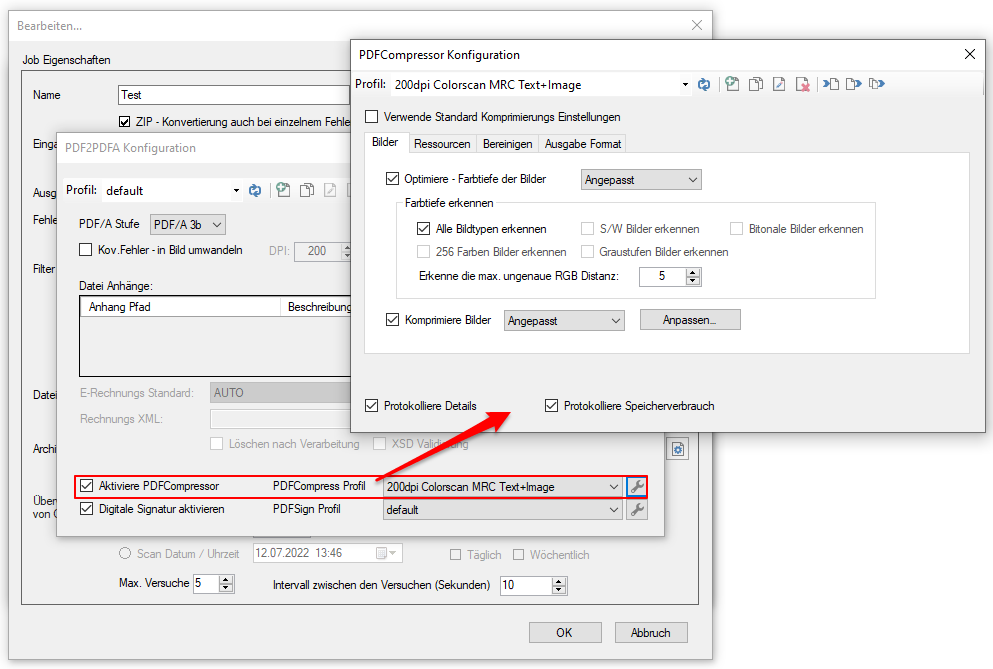
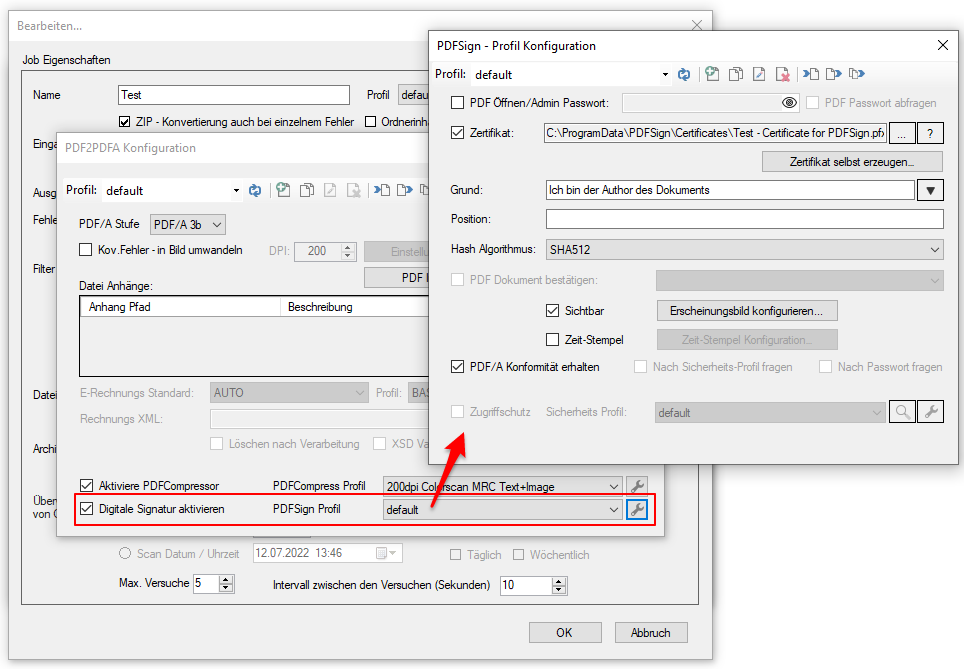
gibt es jetzt auch die Möglichkeit die PDF Dateien vor der PDF/A Konvertierung über die jetzt neu integrierte PDFCompressor Option zu komprimieren und zu verkleinern, bzw. nach der PDF/A Konvertierung die erzeugten PDF/A Dateien über die ebenfalls jetzt integrierte PDFSecureSign Option zu schützen, zu verschlüsseln bzw. digital zu signieren.
Diese beiden neuen Optionen können Einzeln lizenziert und freigeschaltet werden.
PDF2PDFA-CL – PDF/A – Kommandozeilen Konverter >>>
PDF2PDFA-FM – PDF nach PDF/A Konverter mit Ordnerüberwachung >>>
PDF2PDFA-CS – PDF to PDFA Converter Service >>>
DropPDFA – PDF per Drag&Drop nach PDF/A & ZUGFeRD konvertieren >>>