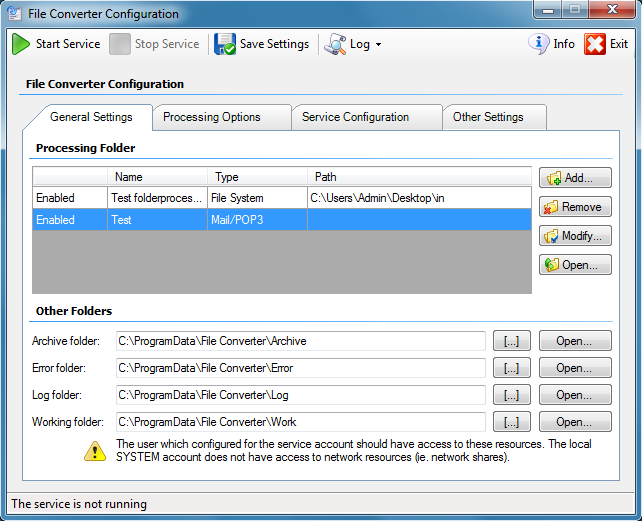
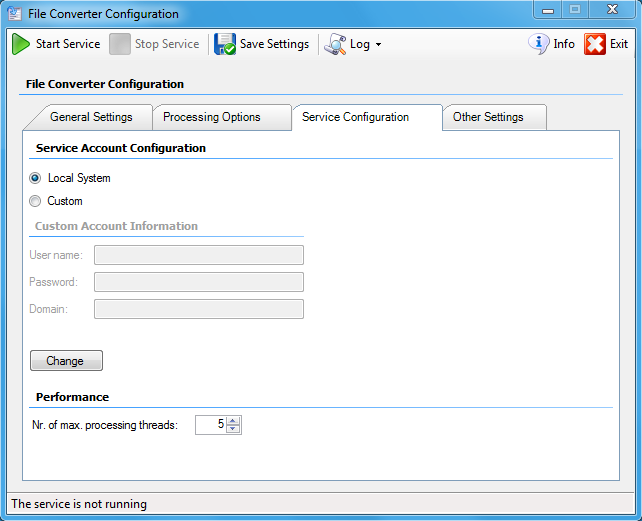
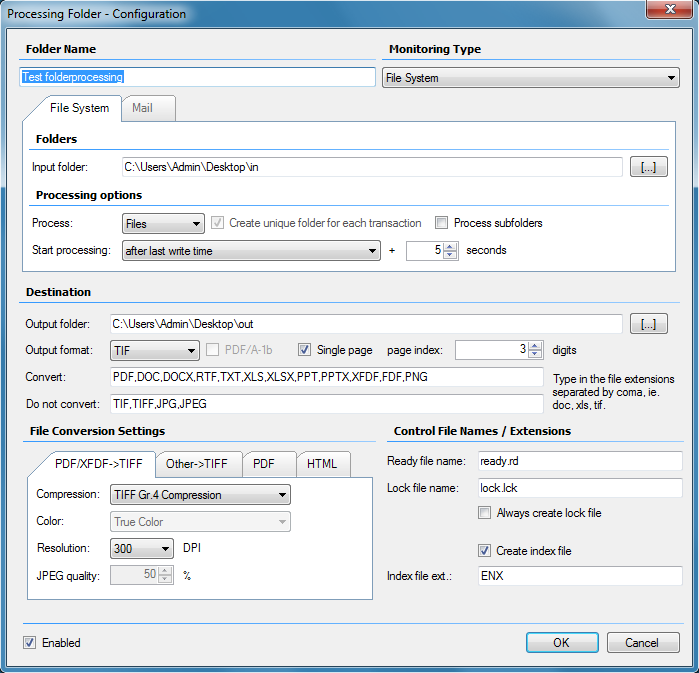
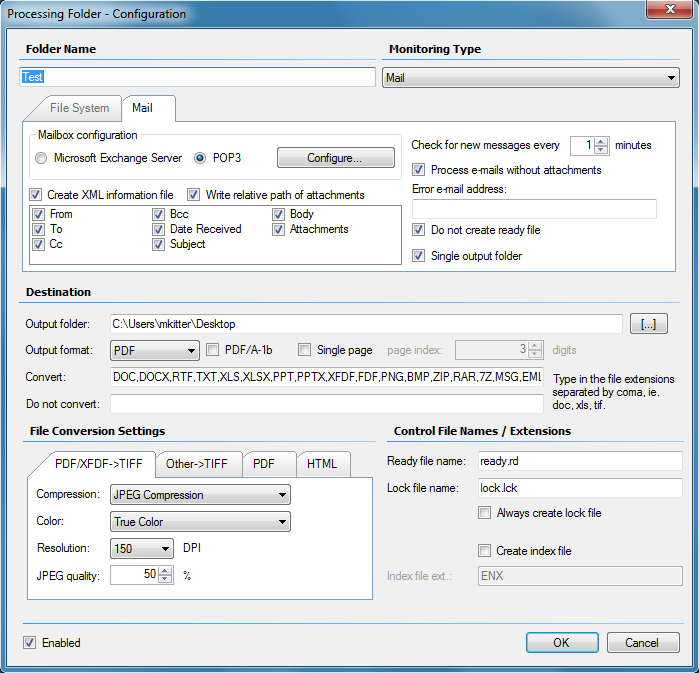
Overview of the PDF/A standards
The document format PDF got developed by the company Adobe in the early 90’s, on the base of the page description language “Postscript”. At first it was a proprietary but disclosed file format and in in 2008 submitted to the ISO and since them builds, in version 1.7, the ISO standard 32000.
PDF/A – The PDF for archiving:
PDF/A is the appellation for the ISO norm 19005 and defines a standard document format for the long term archiving of electronical documents. The norm ensures which PDF function have to be contained or not to archive documents in the long term.
Important: The PDF/A standard is “constitutive” – if a document is PDF/A-1 conform it is automatically also covered in the PDF/A-2 and PDF/A-3 standard – the higher standards allow more PDF functions. But there is no “better” and “worse” PDF/A level but you take the required level and standards to assign the required functions.
PDF/A-1 (since 2006)
For PDF/A-1 there are 2 levels:
- PDF/A-1b: basic – this one is for the explicit visual peproducability of PDF/A documents.
- PDF/A-1a: accesible – like 1b – but has to also include the content structuring of the document (tagged PDF) – this level can’t be created automated through direct conversion, scan, OCR or printer drivers – technically yes but the content structuring usually has to be created and completed manually already in the source application.
PDF/A-2 (since Juni 2011)
For PDF/A-2 there are 3 levels:
- PDF/A-2b: basic – consistent with the 1b – with extensions of the level 2
- PDF/A-2a: accessible – consistent with the 1a – with extensions of the level 2
- PDF/A-2u: unicode – hierzu gibt es keine Entsprechung im Level 1 – entspricht dem Level 2b – jedoch muss der eingebettete Text im UniCode Standard abgebildet sein.
Extensions compared to PDF/A-1 :
- JPEG2000 compression
- Transparency
- Layers
- OpenType-font
- digital signatures as PAdes (PDF Advanced Electronic Signatures)
- Container: PDF/A-1 files can be implemented in PDF/A-2 files
- the page limit got extende to 381 x 381 km
PDF/A-3 (since October 2012)
The essential extensions of the PDF/A level 3 is, that it is possible to embed any files into the PDF/A. With that, for the archiving, a PDF file can be combined with the archiving of the source file, for searching, displaying and printing. Would you only archive the PDF file for a MS-EXCEL, eventually important additional informations like the formulas which it’s based on, would get lost. The embedded (source) files can be extracted from the PDF at any time.
More ISO normalized PDF standards are:
- PDF/E – PDF for Engineering: ISO 24517 – PDF/E-documents implement: Layers for installation- and construction plans as well as three-dimensional models inclusive predefined 3D-views.
- PDF/H (Healthcare) – PDF in the health system (best practice) for the diagnostics by imaging and for the storage of patients data and medical reports.
- PDF/X (Exchange) für Druckvorlagen: ISO 15929 / 15930 – The PDF/X-standard got developed for the exchange of announcement data for newspapers as well as for the transfering of print models and jobs. PDF/X is available in the following levels: 1a, 2, 3, 4, 5, 5g, 5gp, 5n
- PDF/UA (Universal Accessibility) – ISO 14289 – for universal accessible documents, z. B. as reading help for visually handicapped people.
- PDF/VT (Variable Transactional) – ISO 16612-2 – for the “printing of variables or transactional document contents”.
- PDF Level 1,7 – ISO 32000: The ISO has approved the Portable Document Format (PDF) 1.7 as international standard.