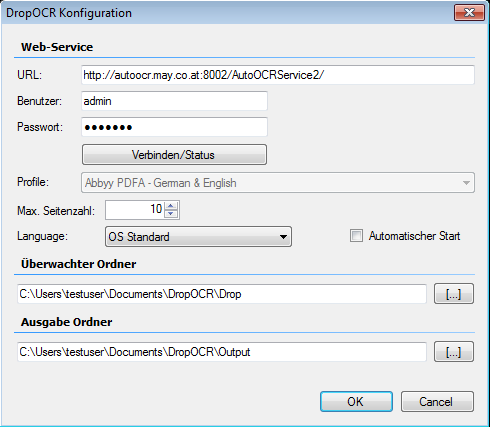
DropOCR – Version 1.2.5 verfügbar
Neuerungen DropOCR Version 1.2.5:
- Direkt Auswahl des AutoOCR Verarbeitungsprofils über das Context Menü der Icon Tray Anwendung
- Funktion „Alle Jobs abbrechen“ – damit können laufende Übertragungen und Verarbeitungen umgehend beendet werden.
- Die „AutoStart“ Option ist jetzt standardmäßig aktiviert.
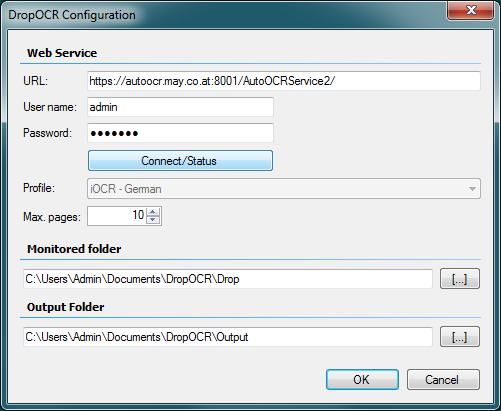
- Max. Seitenzahl ist per Default auf 1000 voreingestellt
- Die Verbindungsdaten des AutoOCR Testservers sind durch die Installation bereits vorbelegt.
![]()