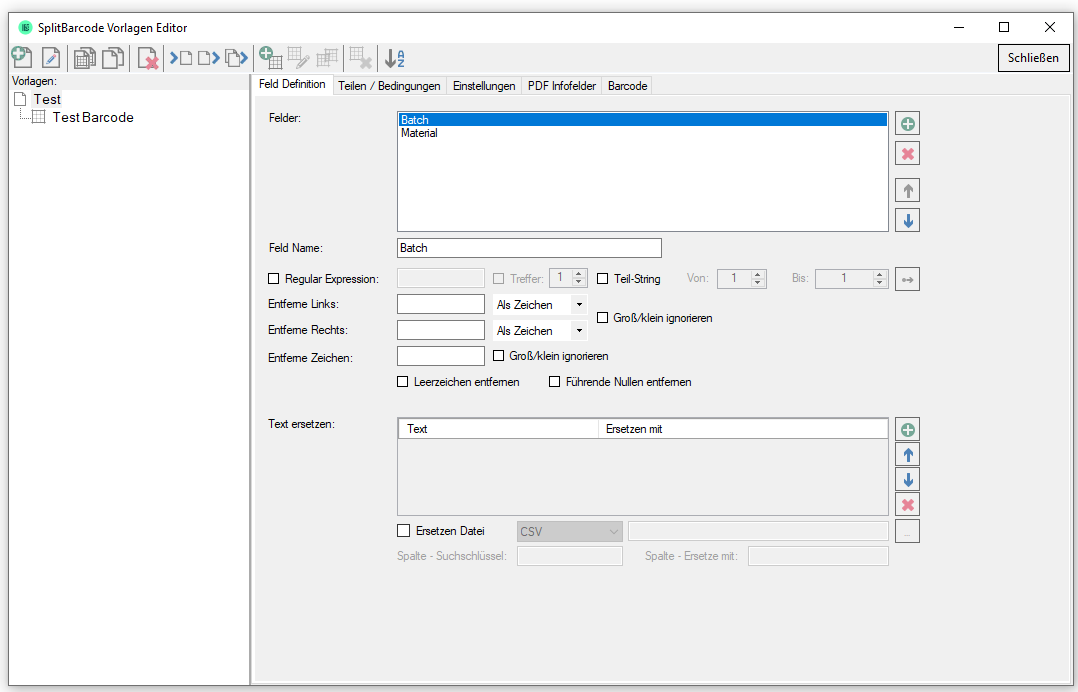
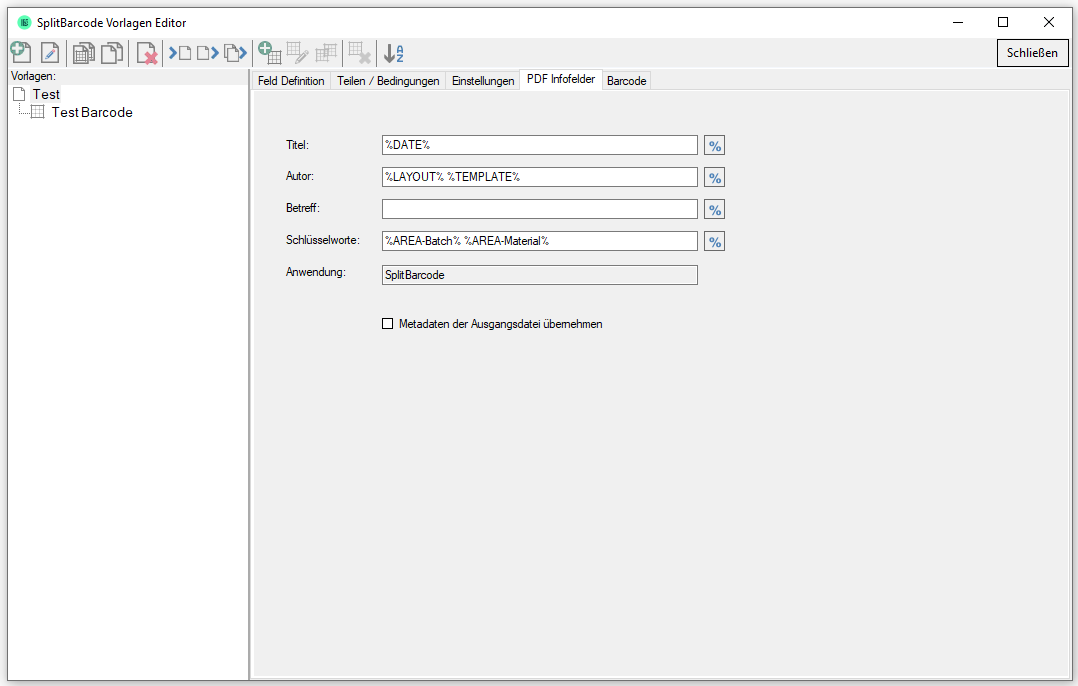
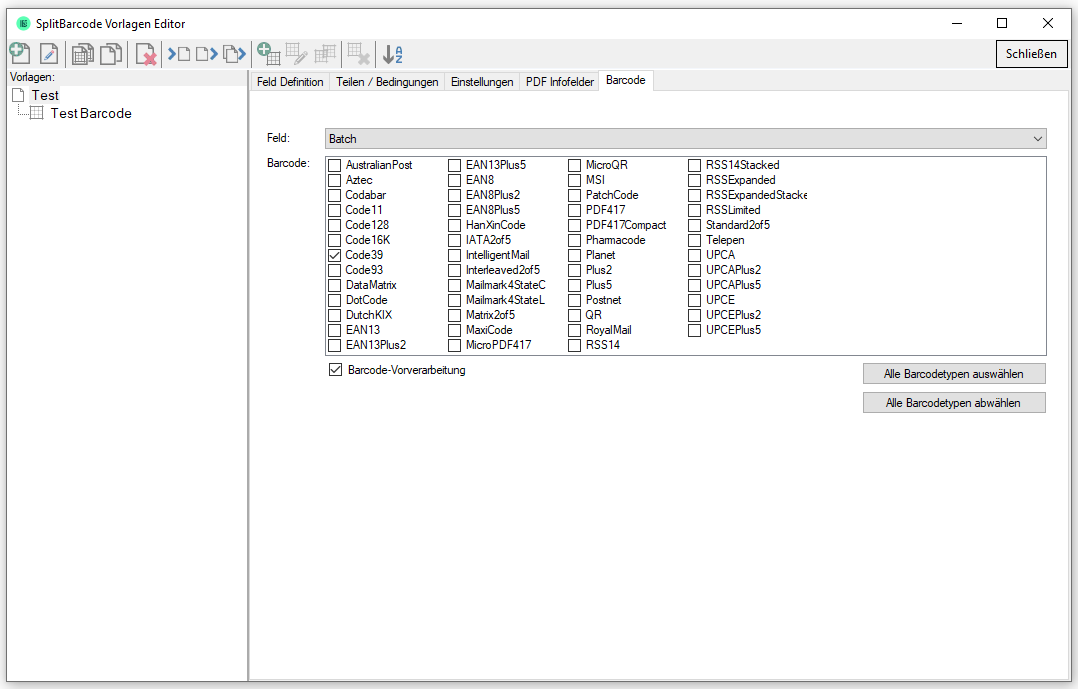
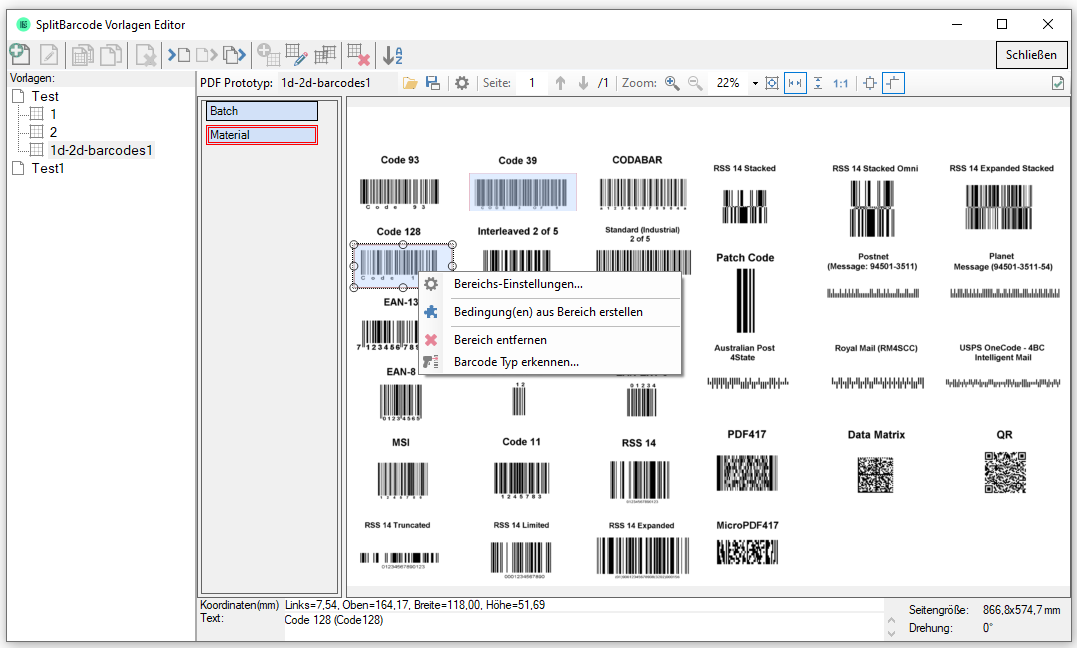
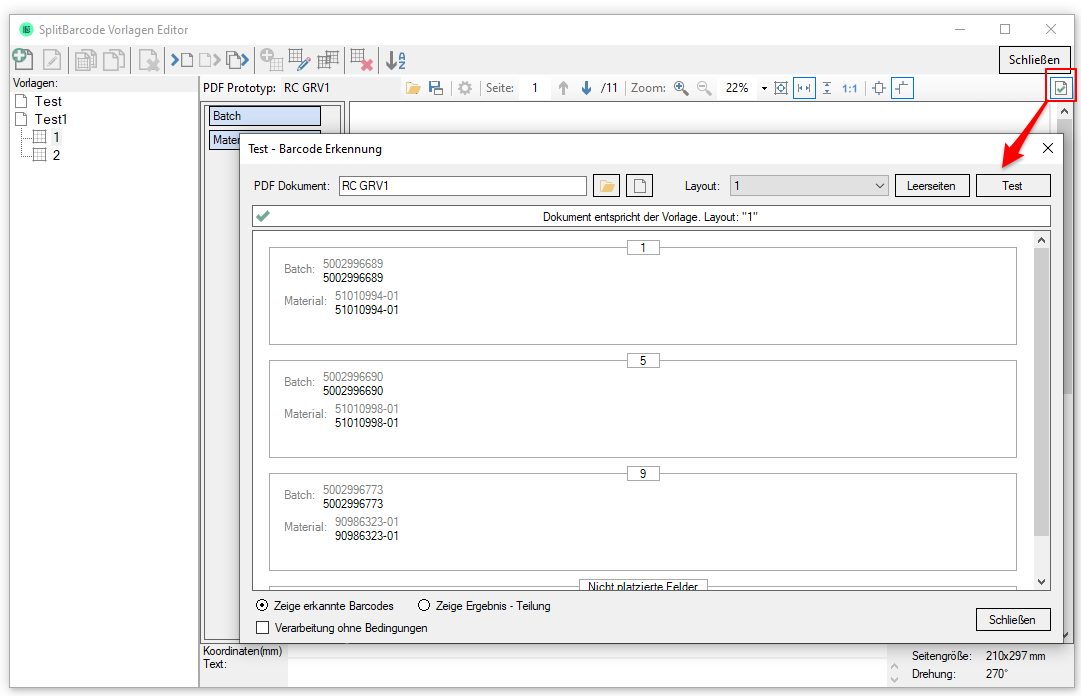
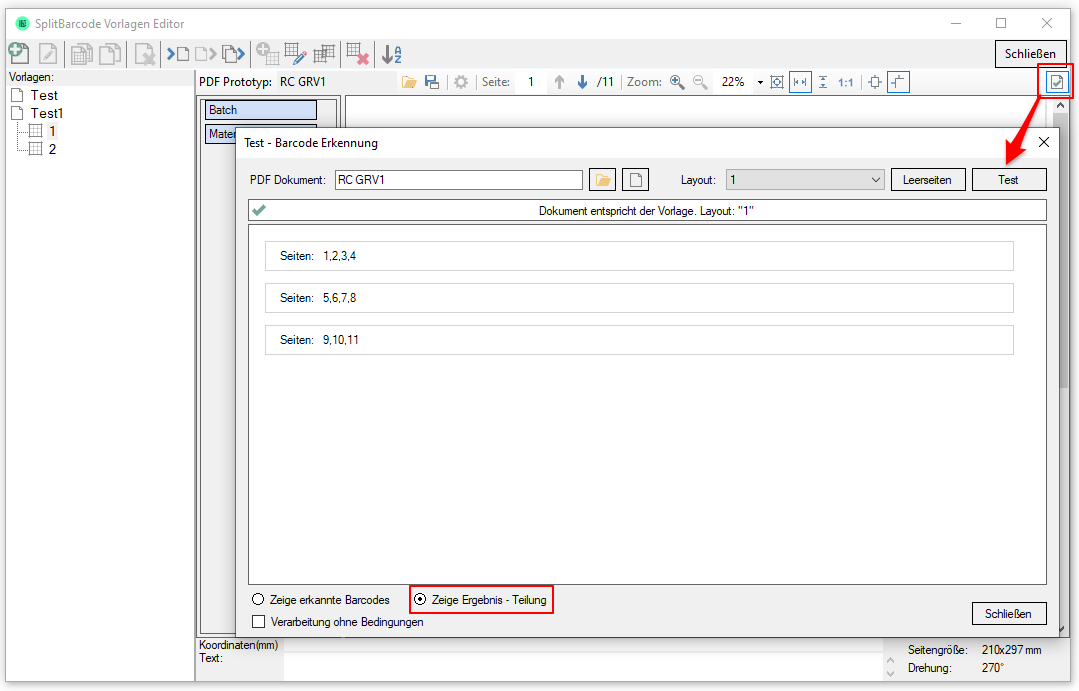
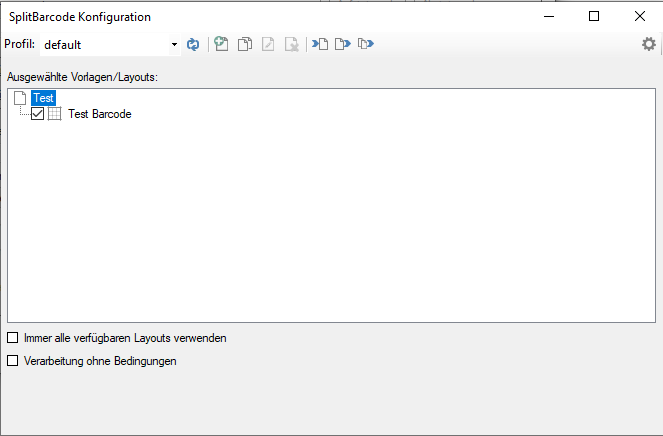
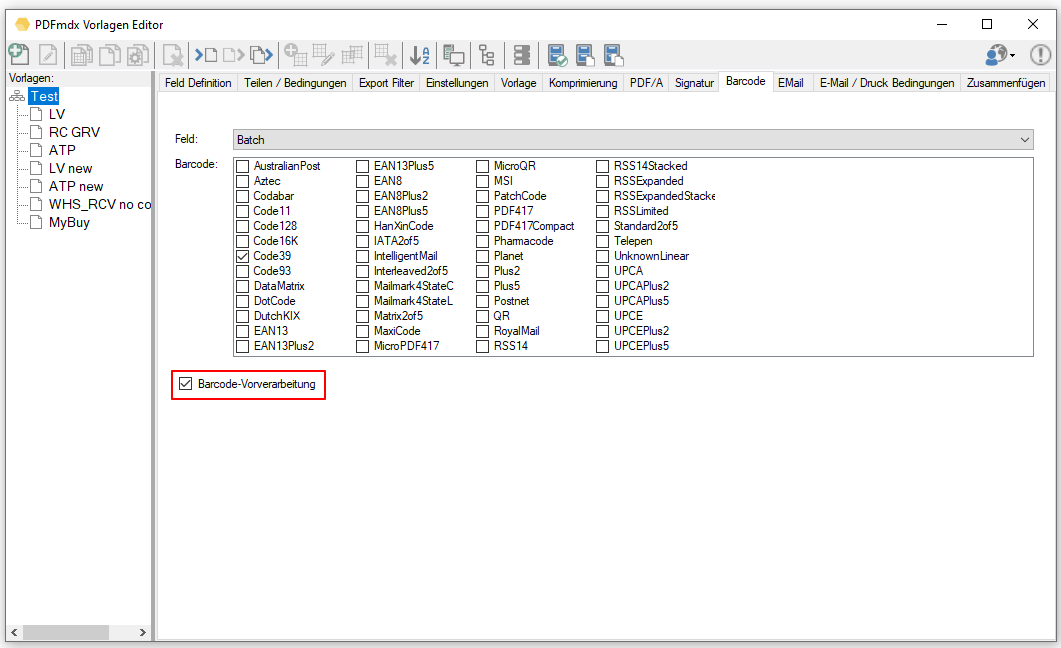
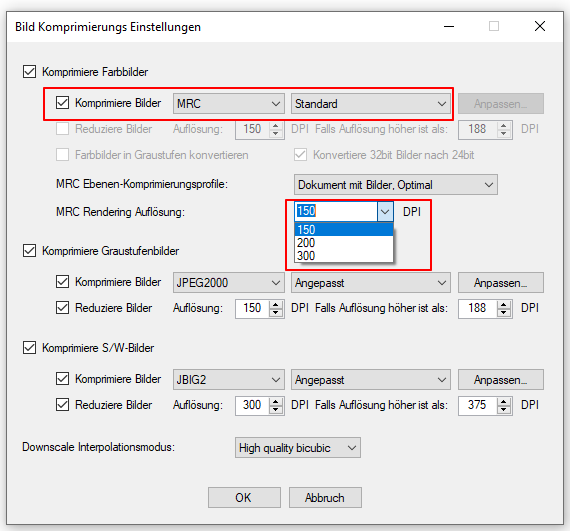
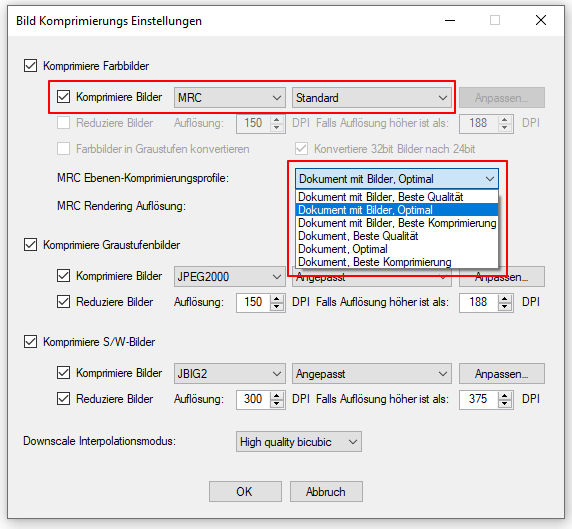
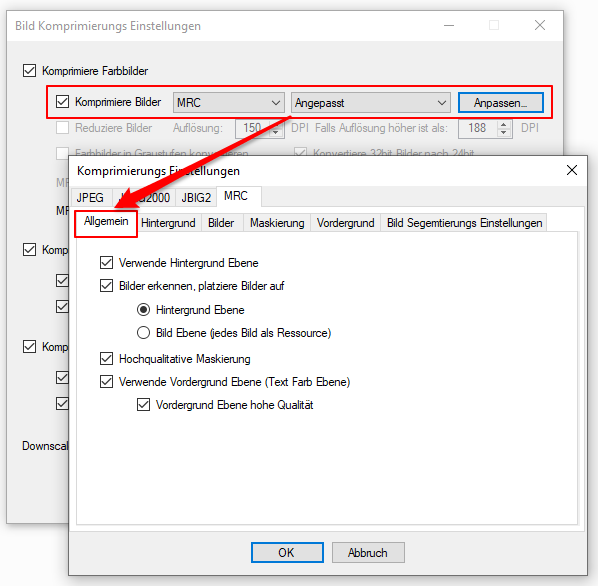
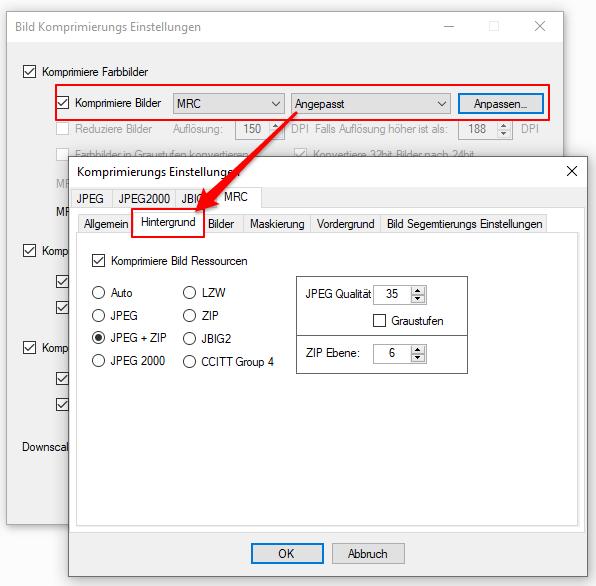
eDocPrintPro – Save as – no PDF file is created
If no PDF file is created at the selected storage location under the desired name after the “Save as” dialog, the cause is most likely that the Microsoft Visual C++ Runtime component is missing on the computer or has been uninstalled.
Info : >>>
Download: Microsoft Visual C++ 64bit Runtime