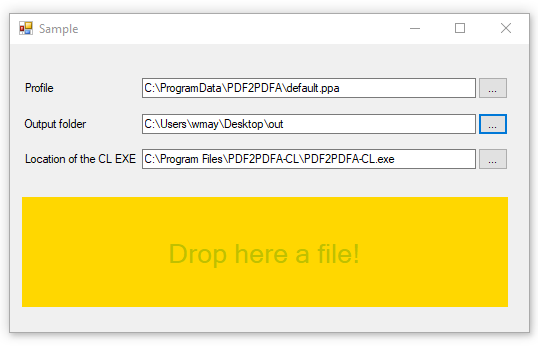
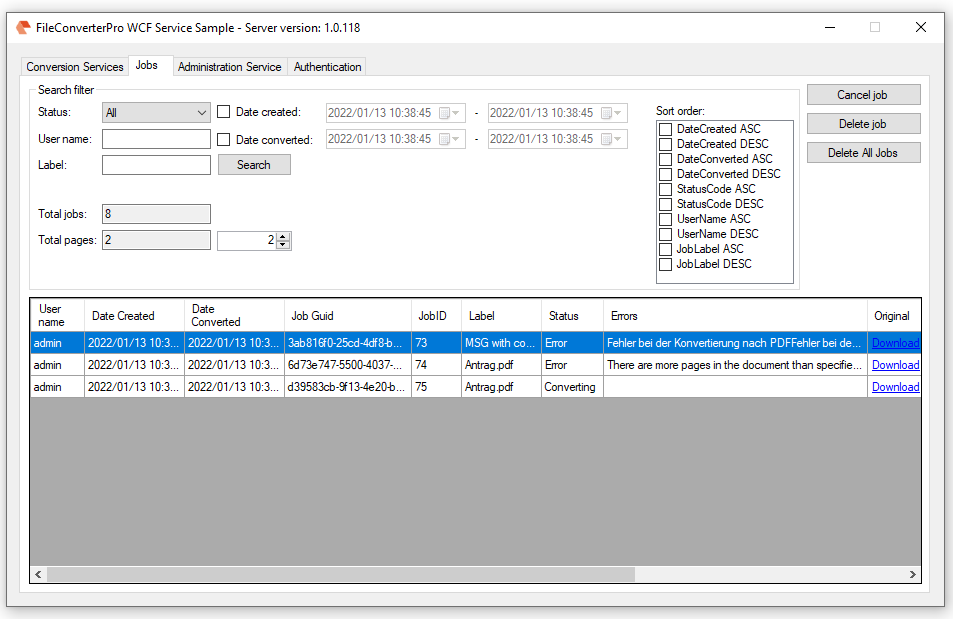
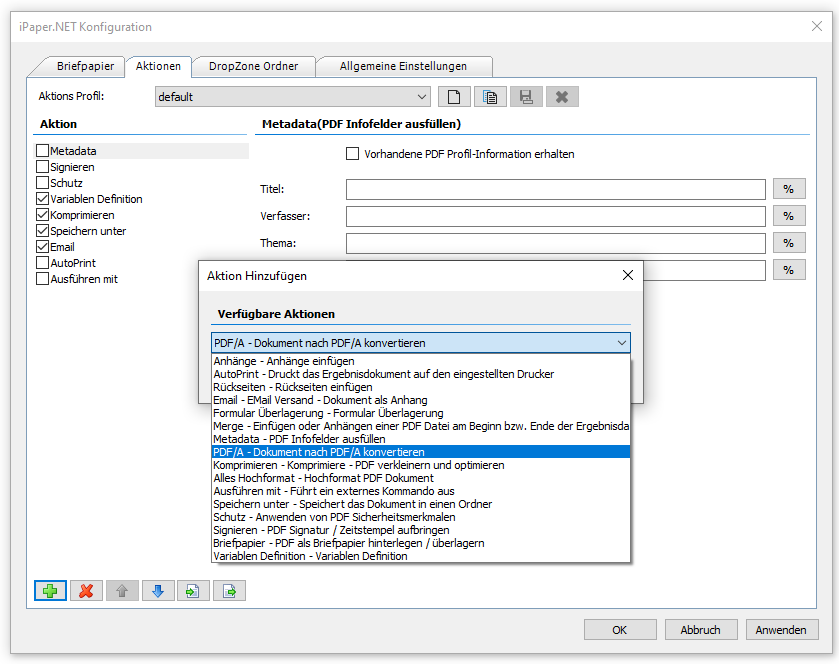
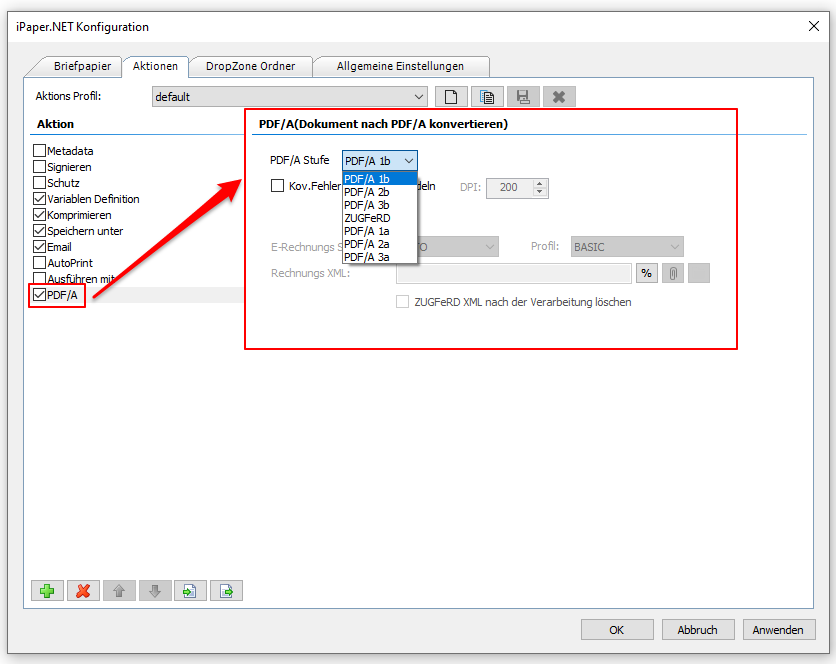
Sample project Calling the PDF2PDFA-CL command line application from .NET / C#
We have created a C# / .NET example project to show how the PDF2PDFA-CL command line application can be called from a .NET / C# program.
Functions:
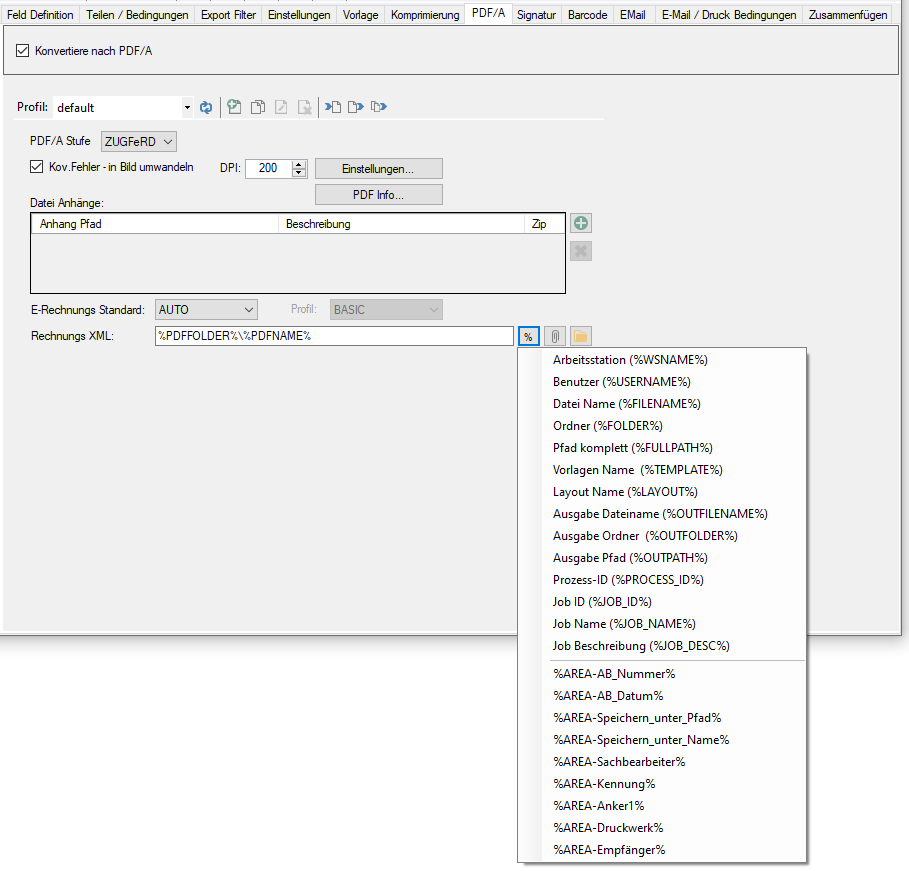
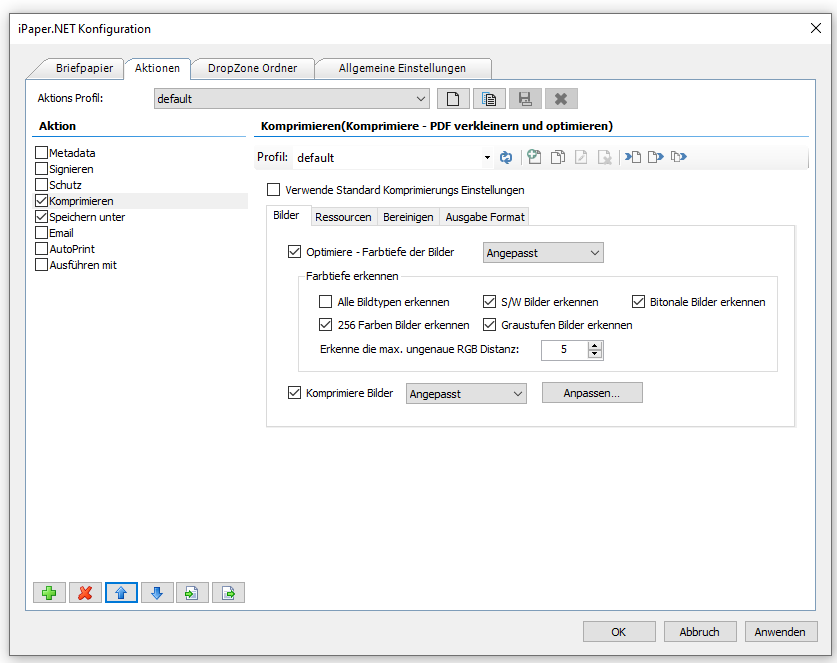
- PDF to PDF/A conversion using our PDF2PDFA-CL application< /a>
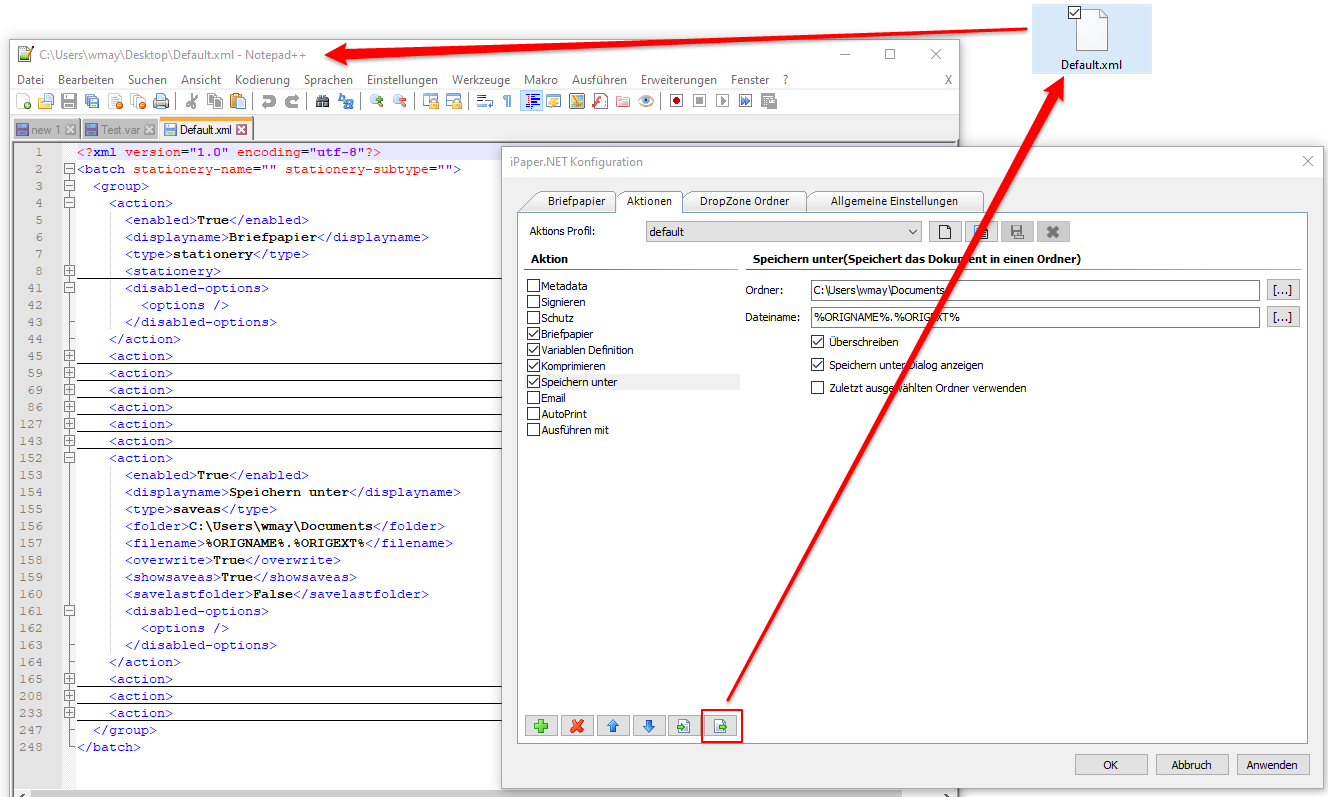
- .NET / C# sample project in source code including executable application
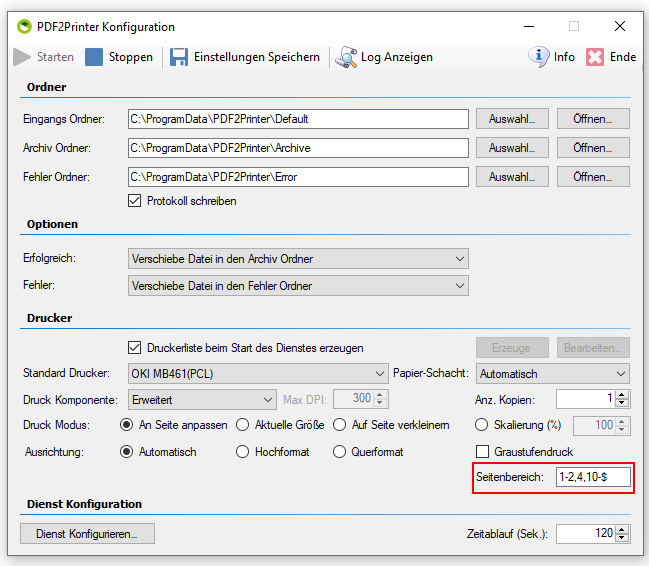
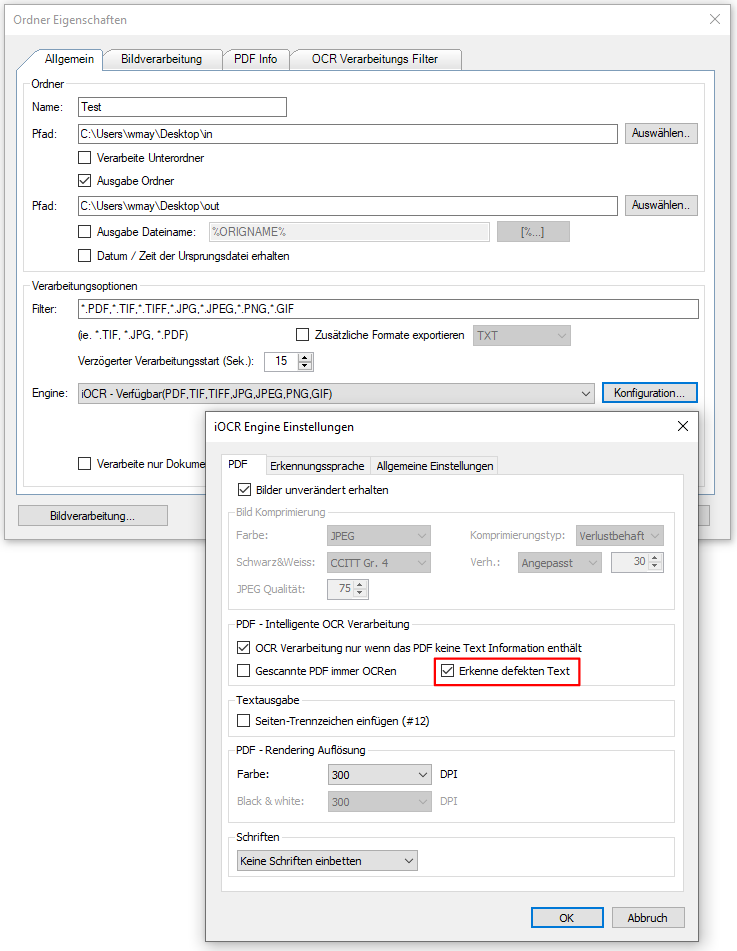
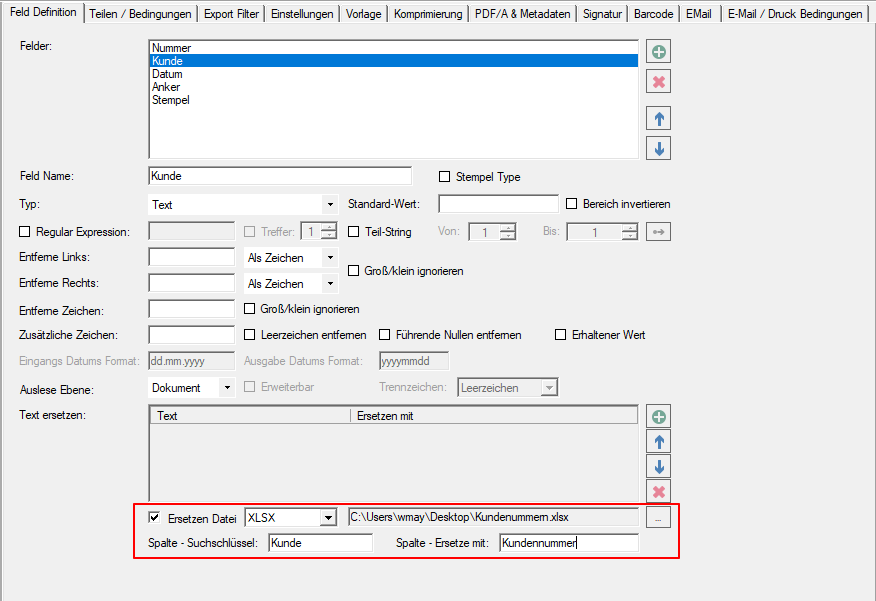
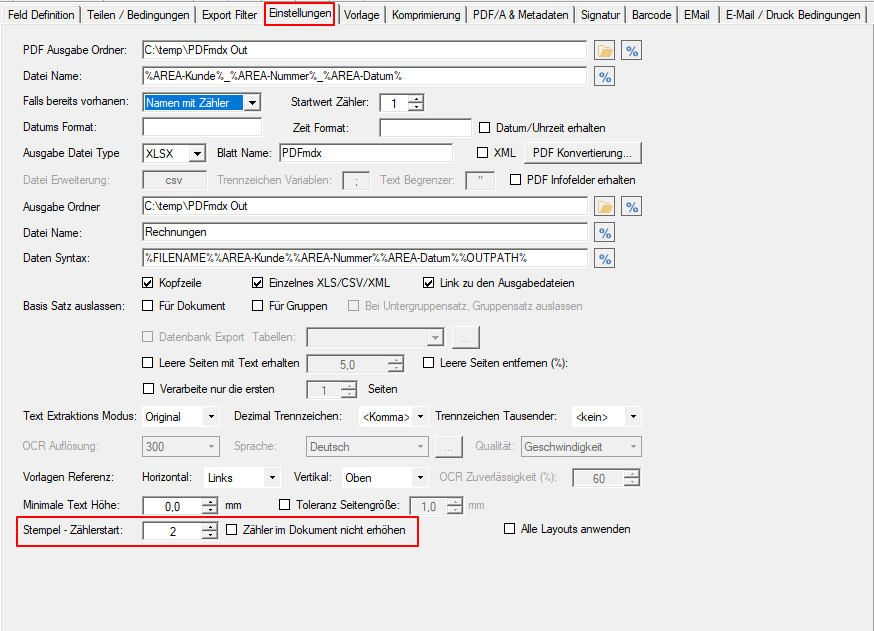
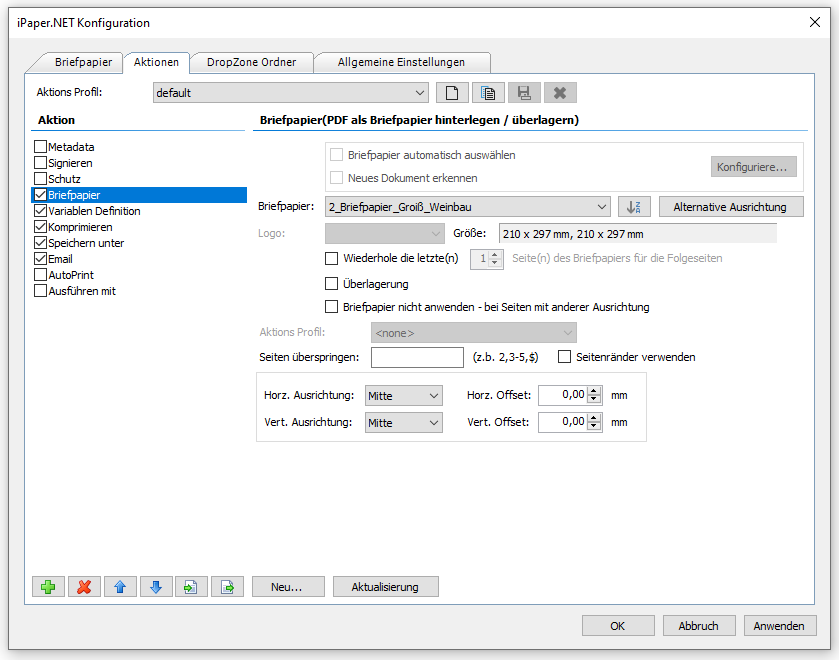
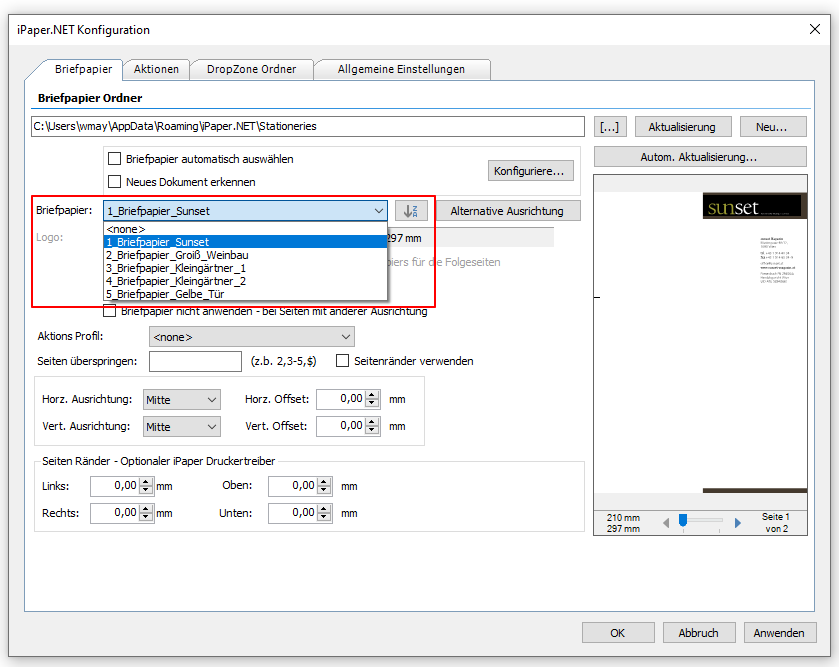
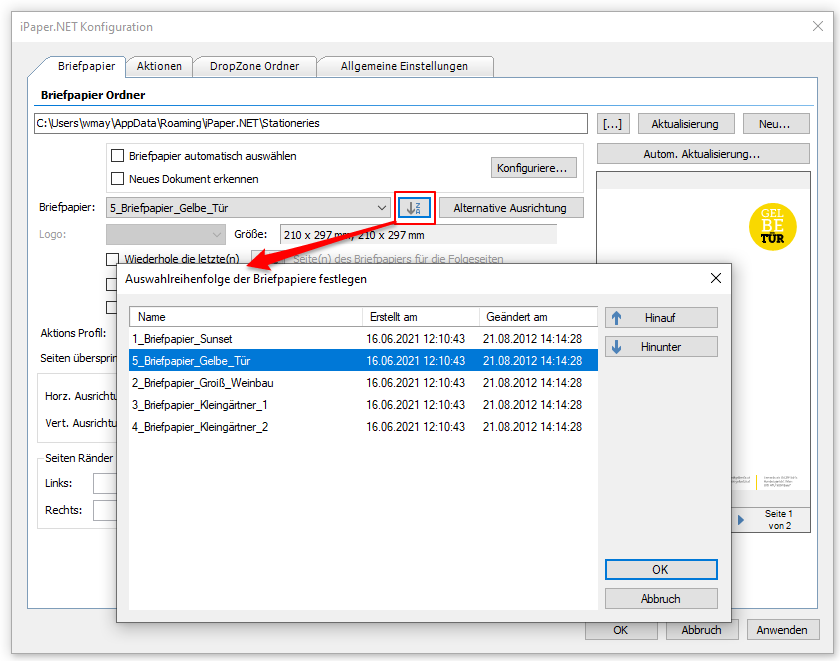
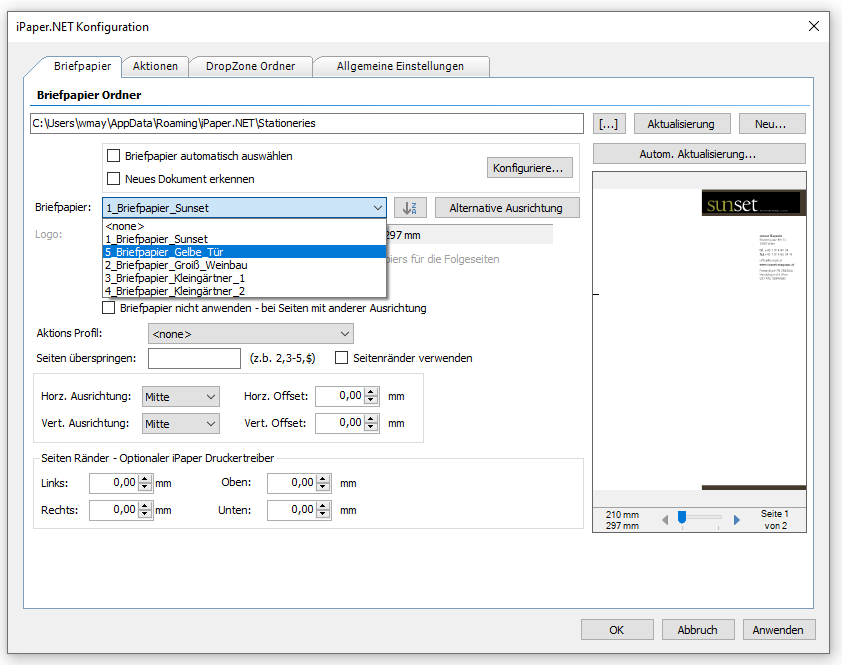
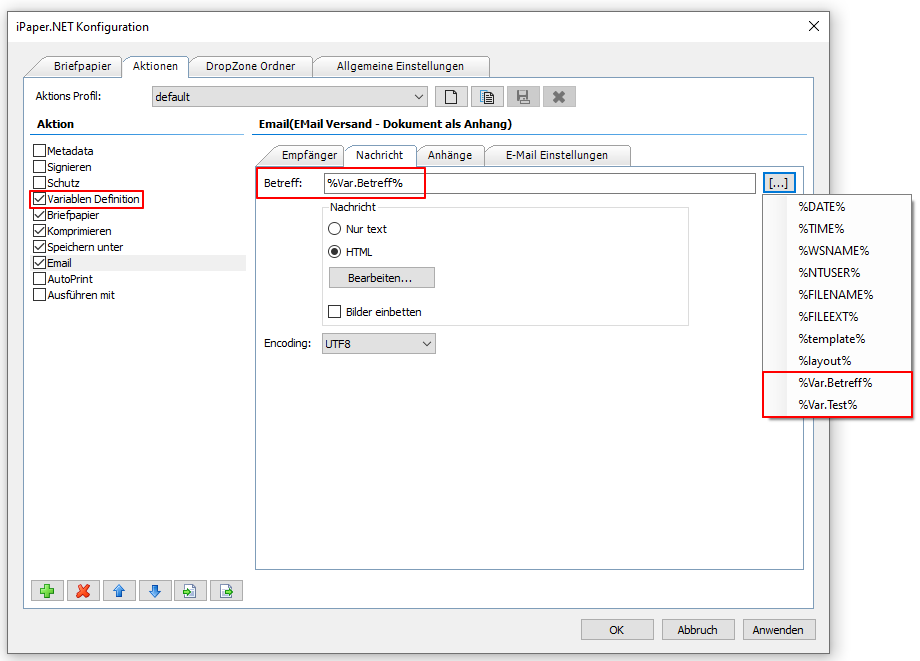
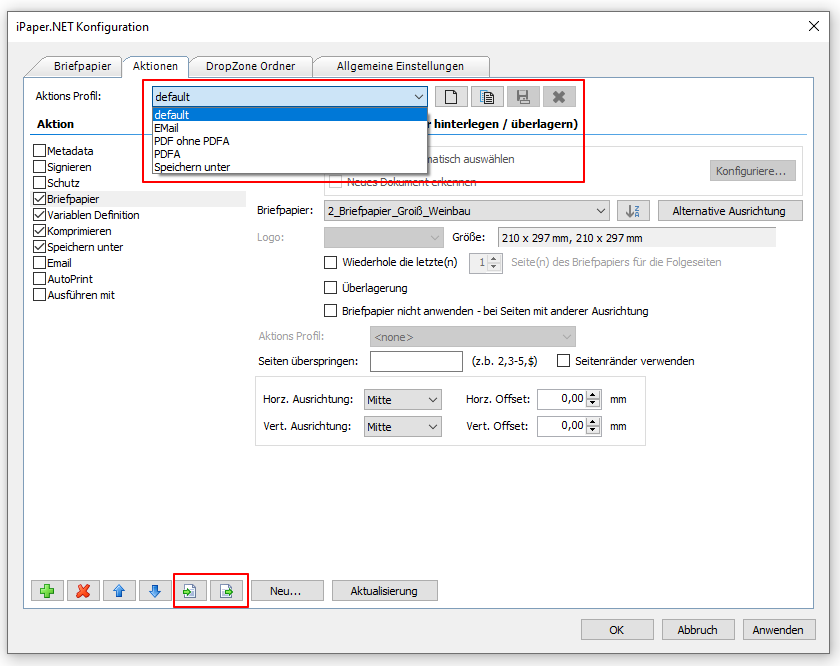
- Selection – Conversion profile file (*.ppa) from PDF2PDFA-CL
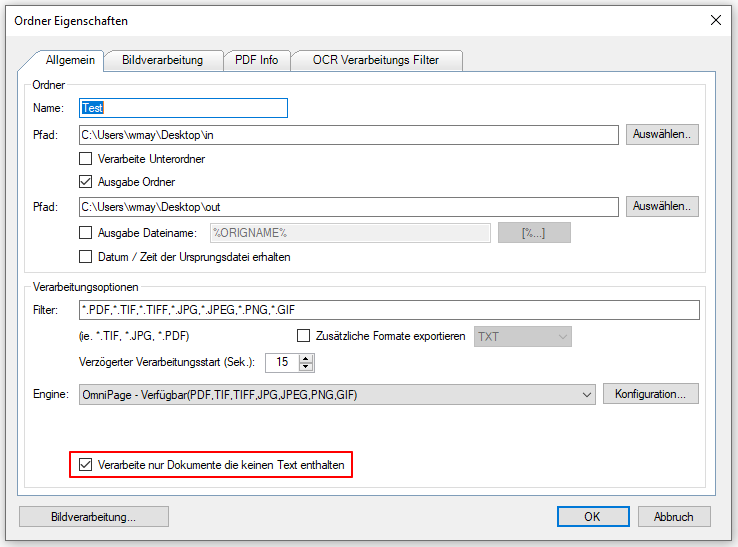
- Selection – Output Folder
- Selection – Path to PDF2PDFA-CL EXE
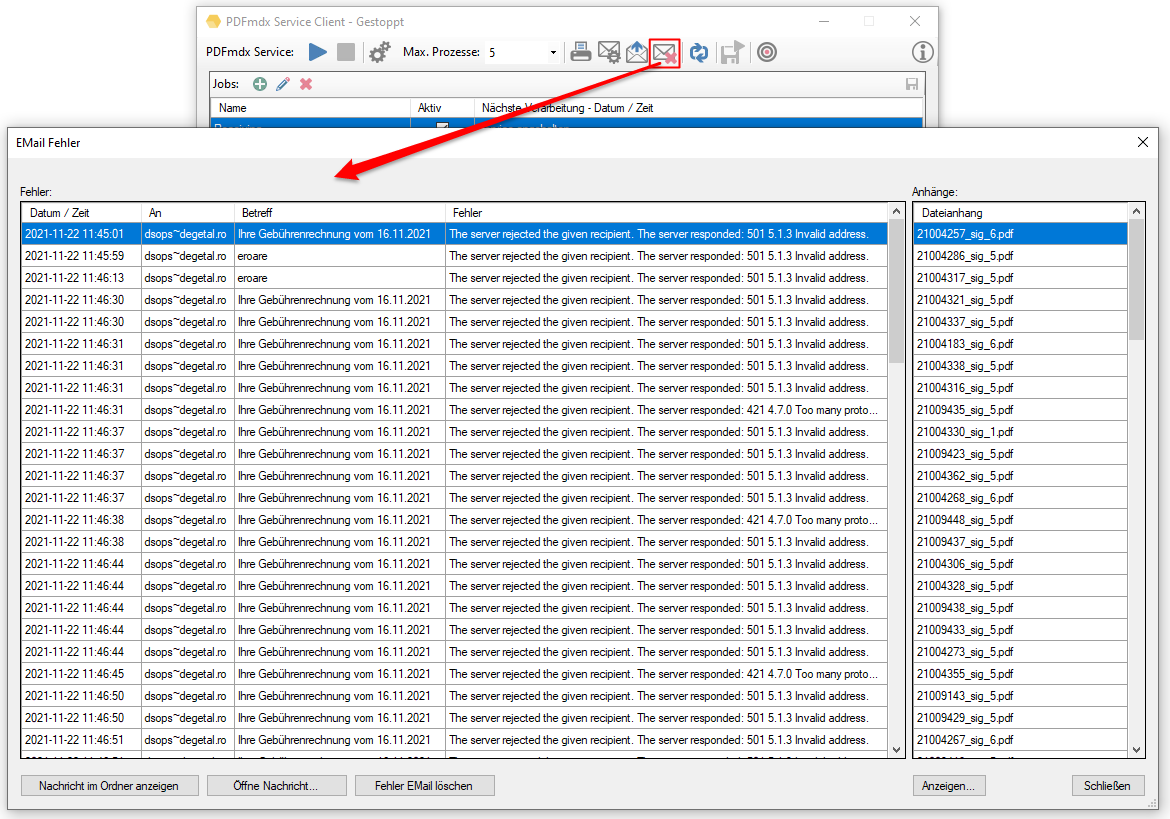
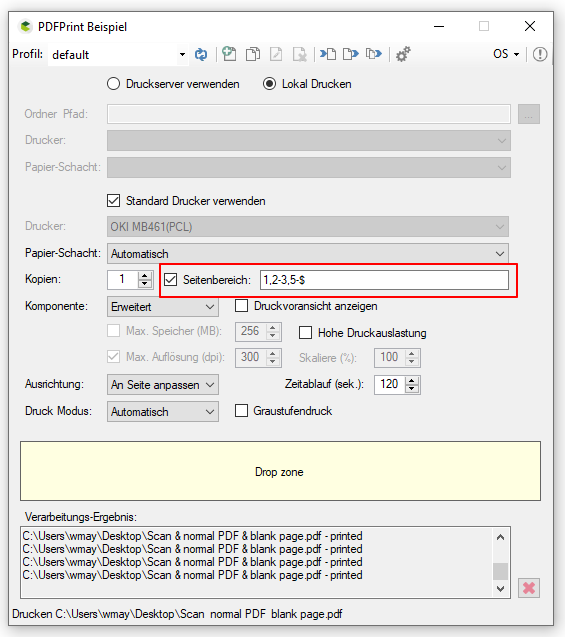
- Start processing by drag & Drop one or more PDF files into the selected drop area.