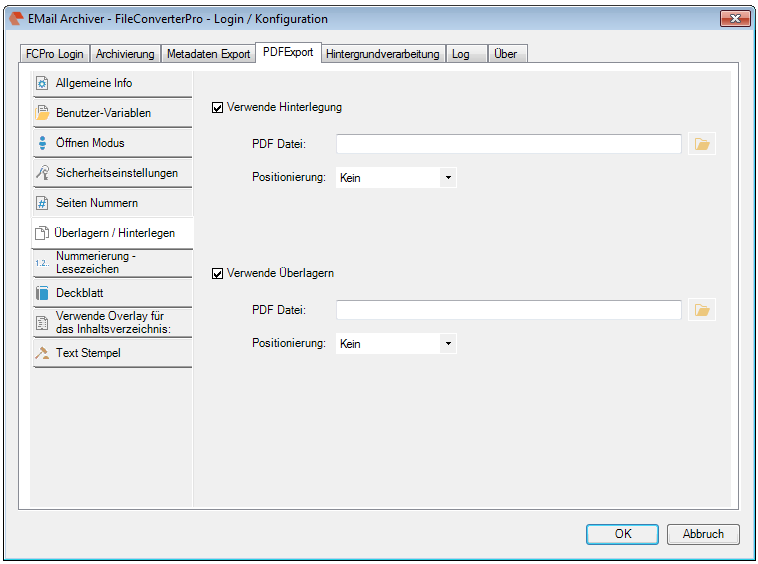
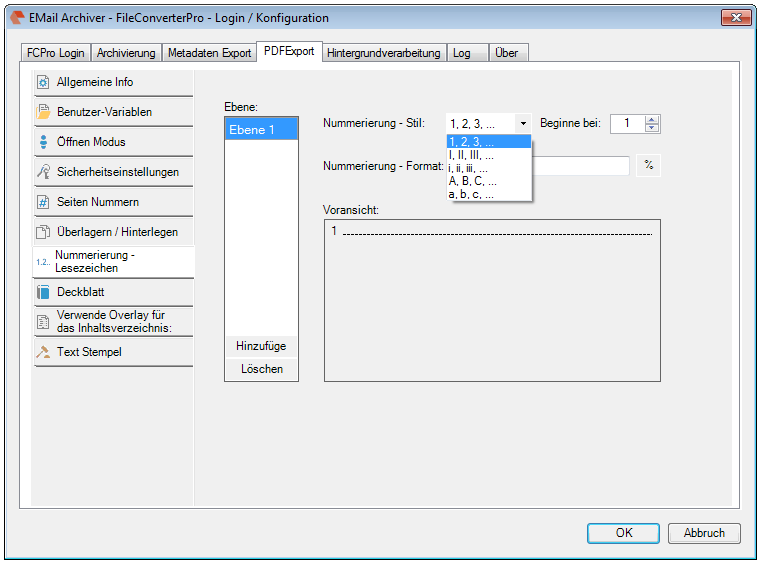
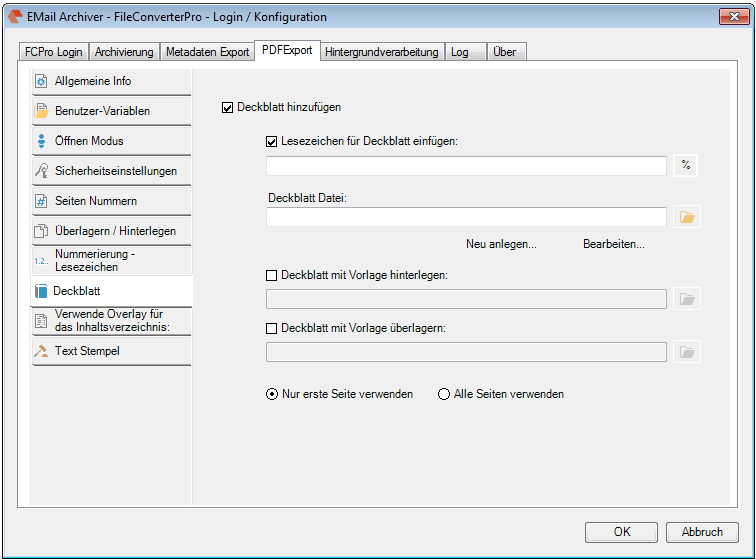
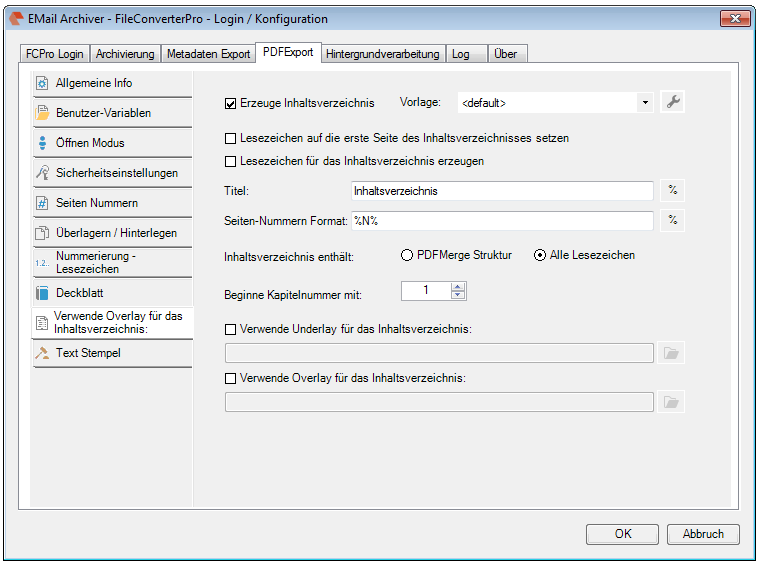
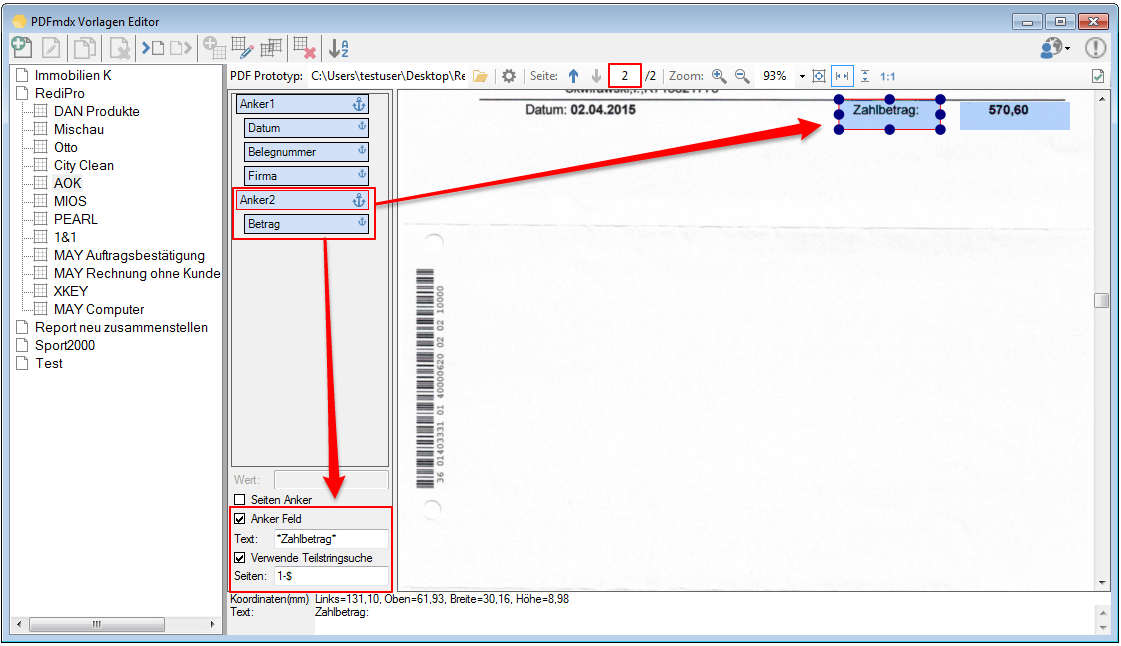
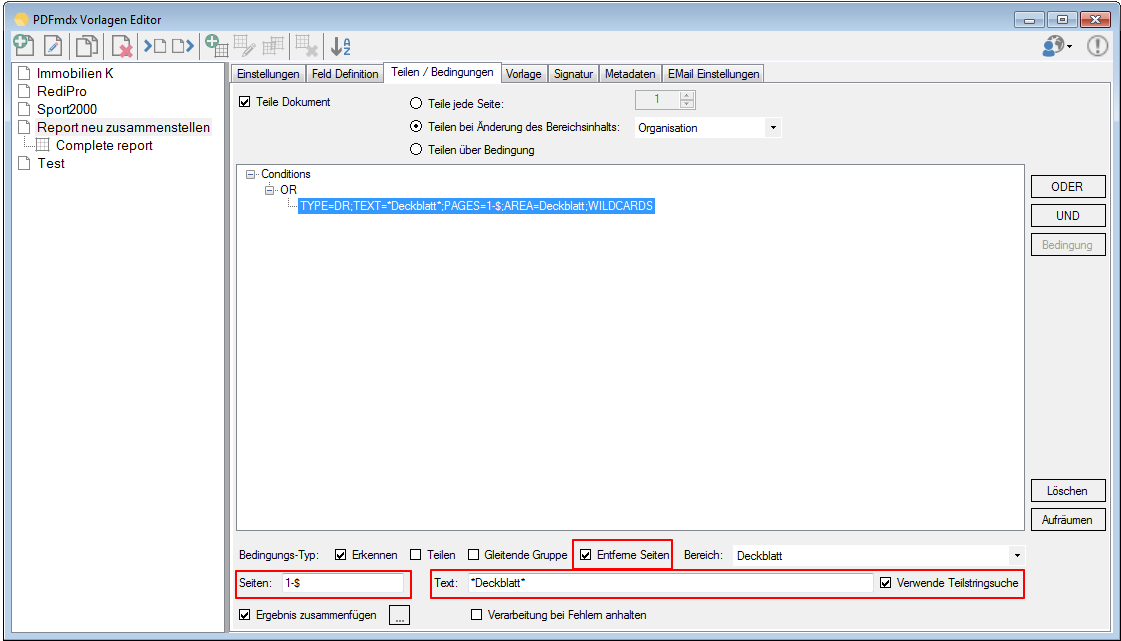
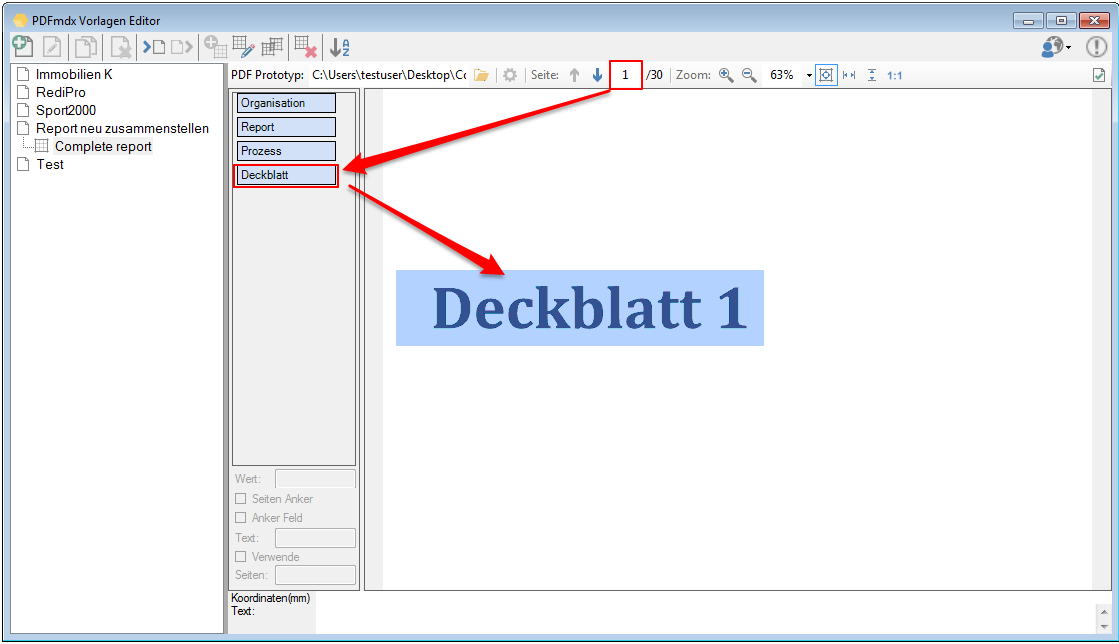
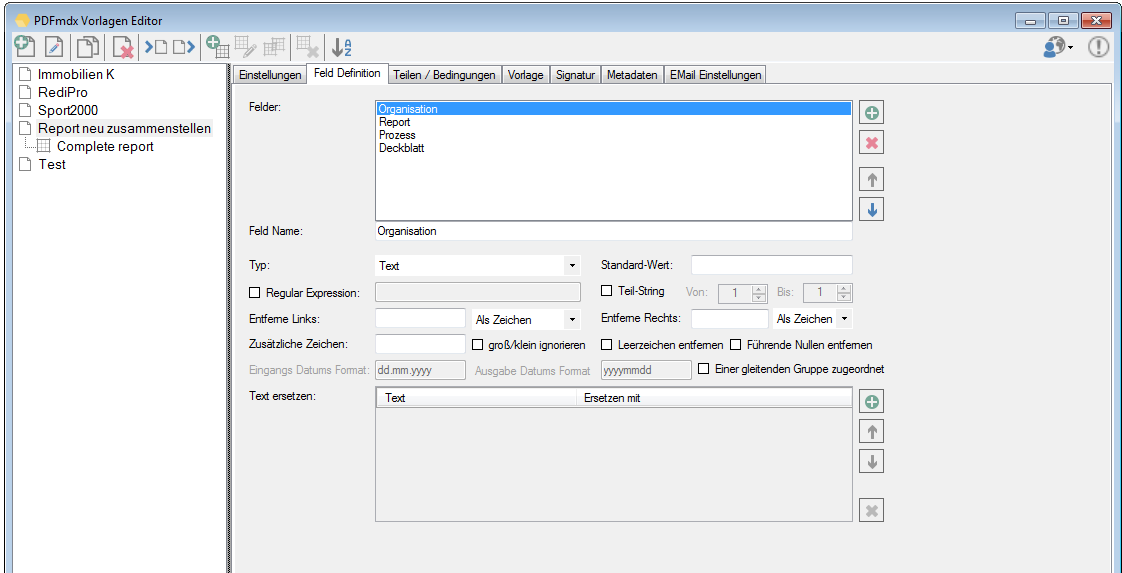
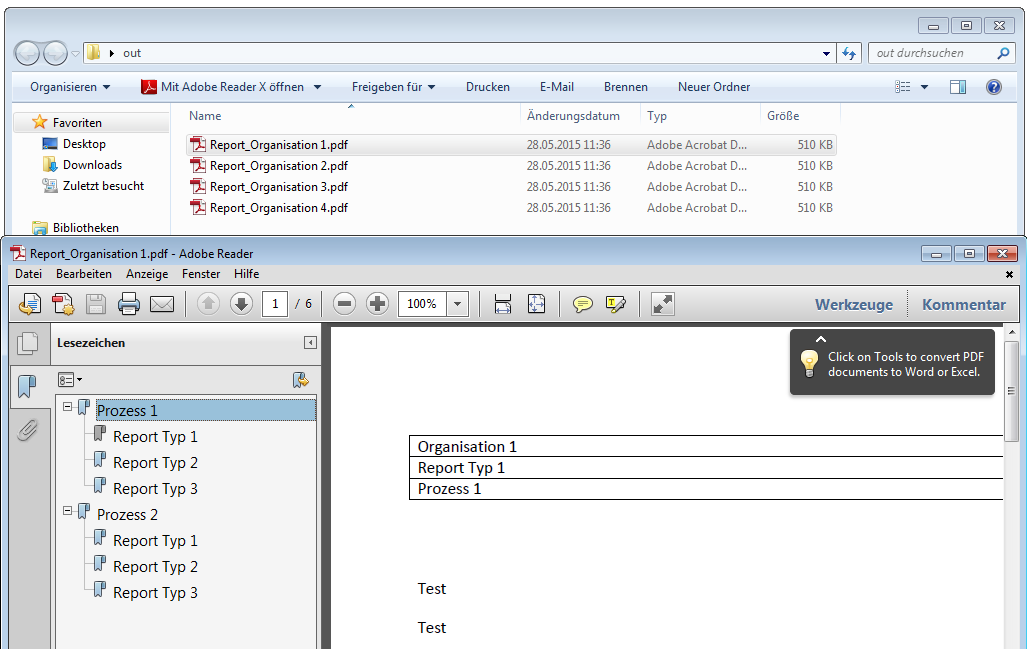
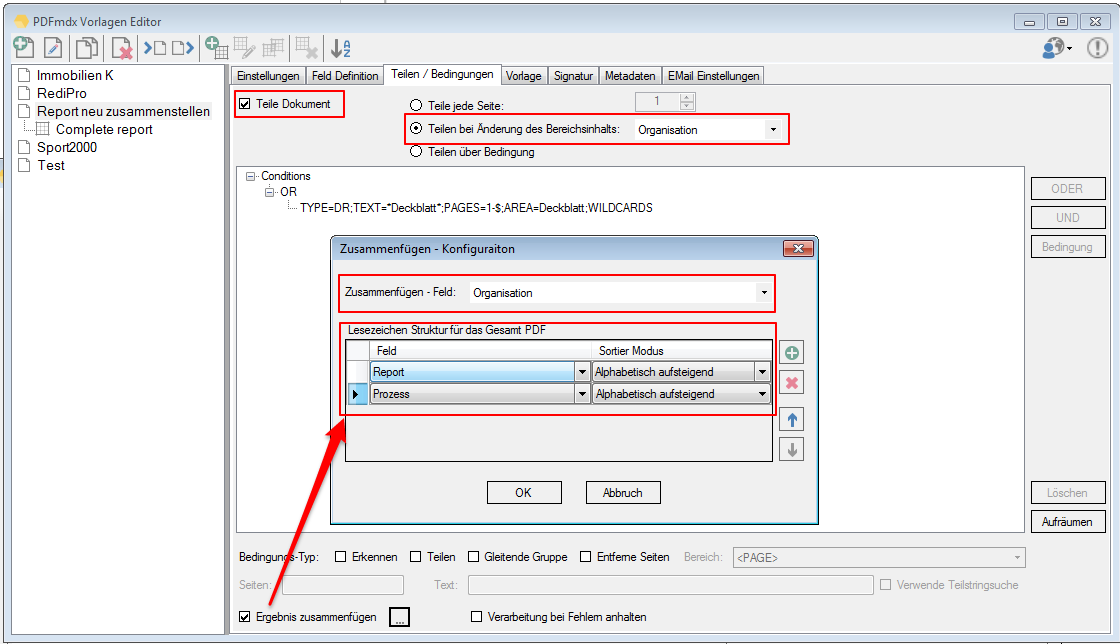
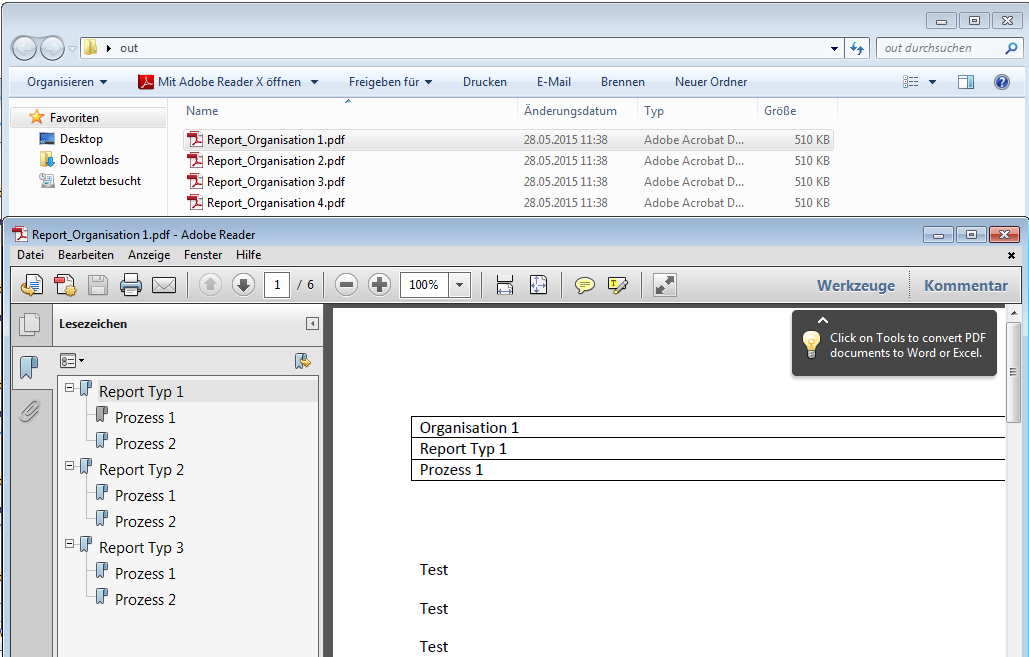
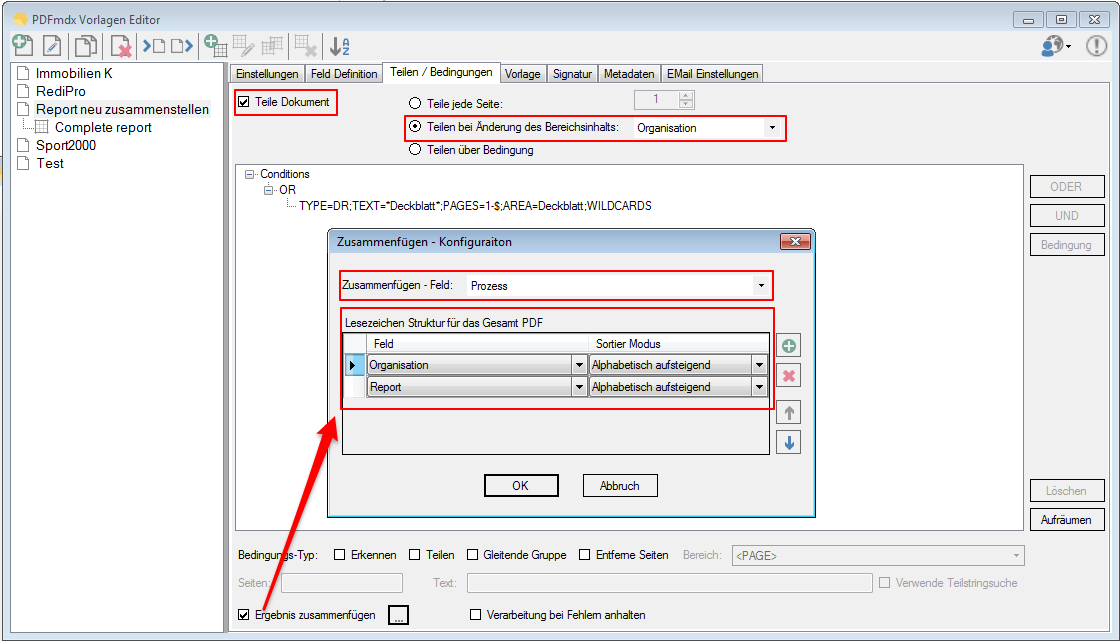
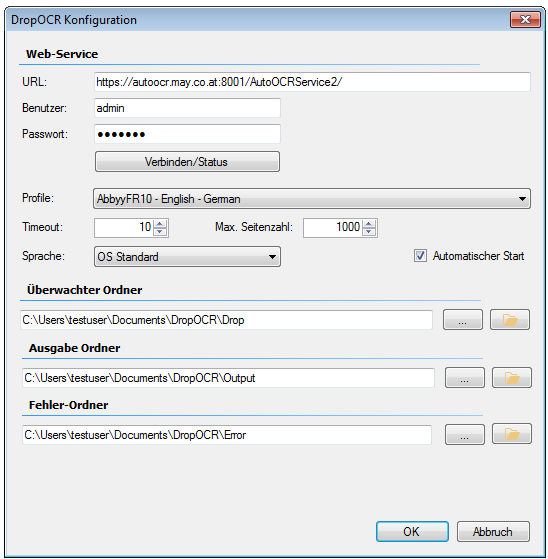
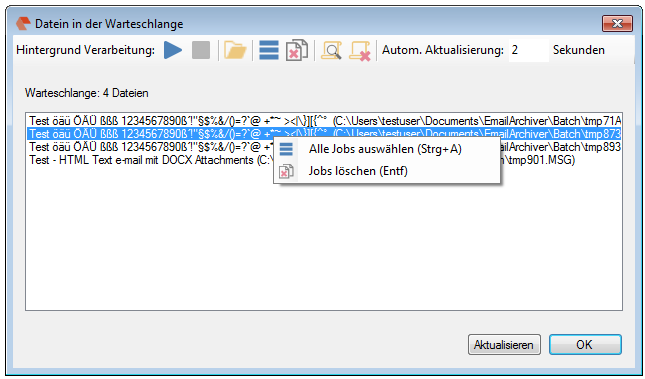
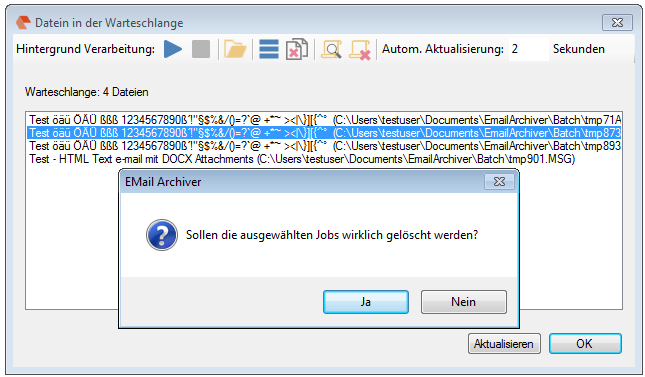
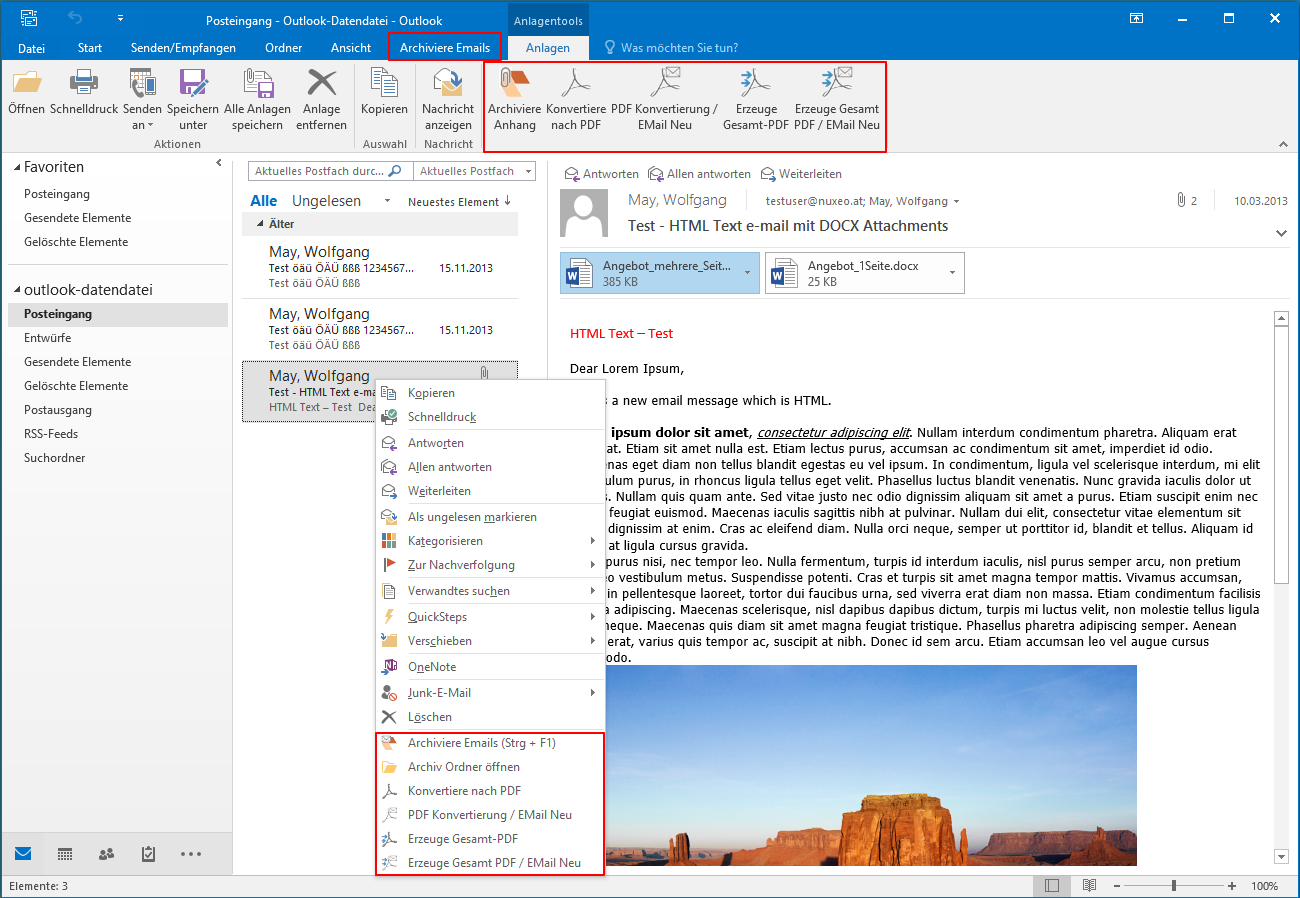
EMail Archiver for FileConverterPro – testet with MS-Outlook 2016 under Windows 10
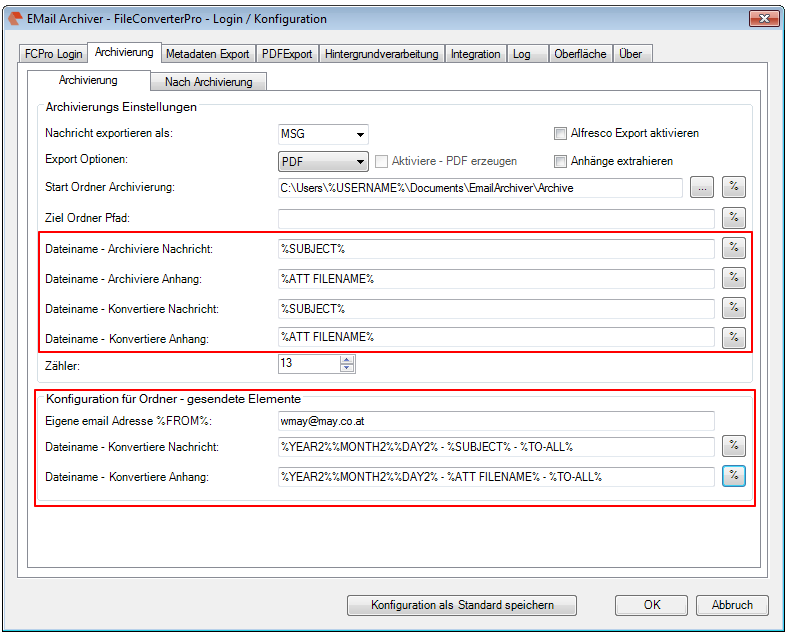
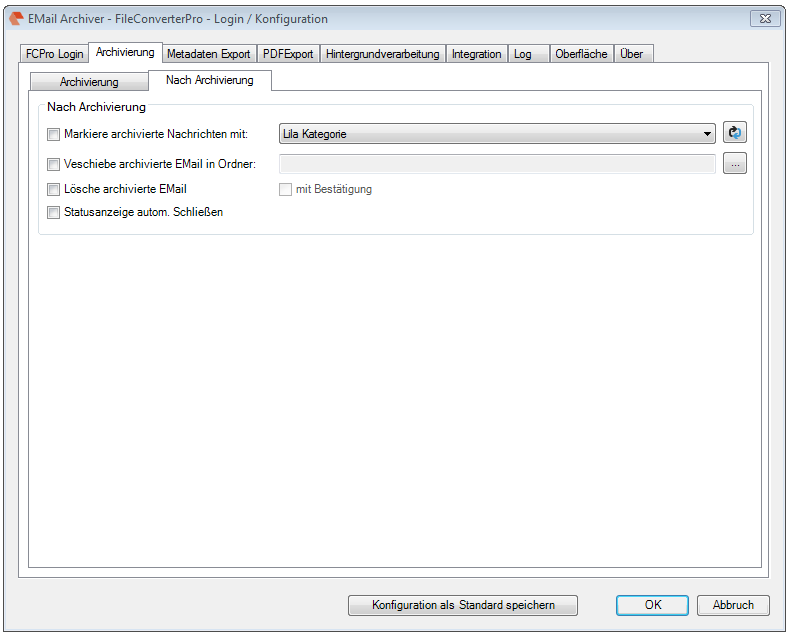
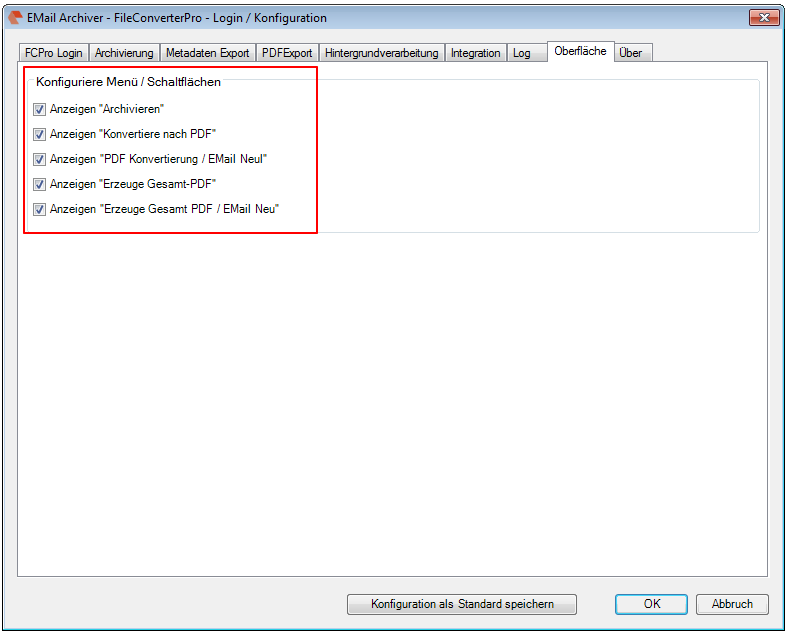
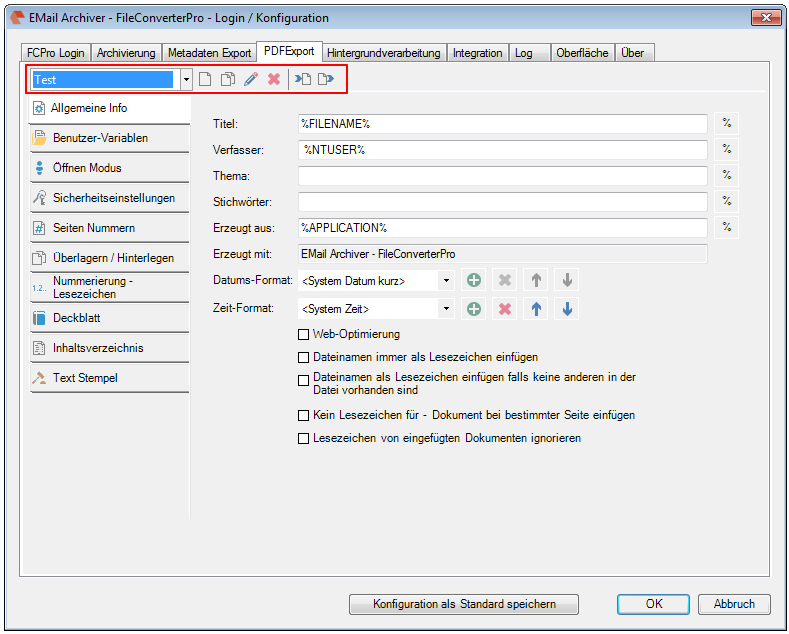
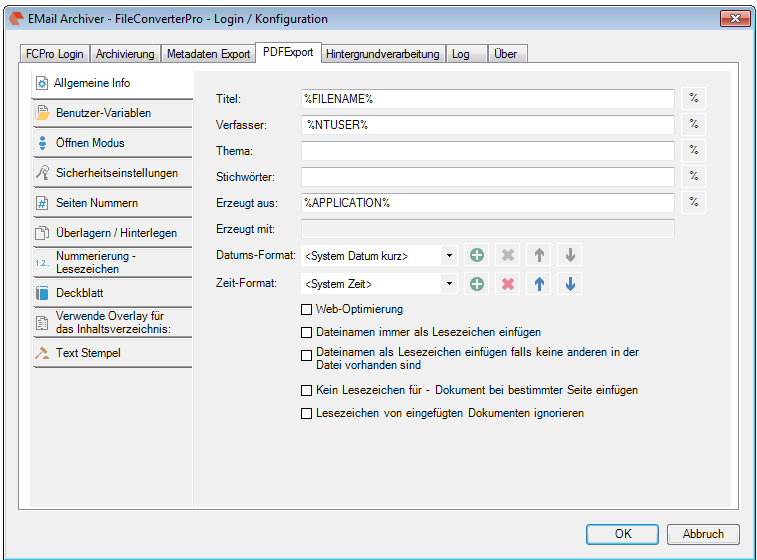
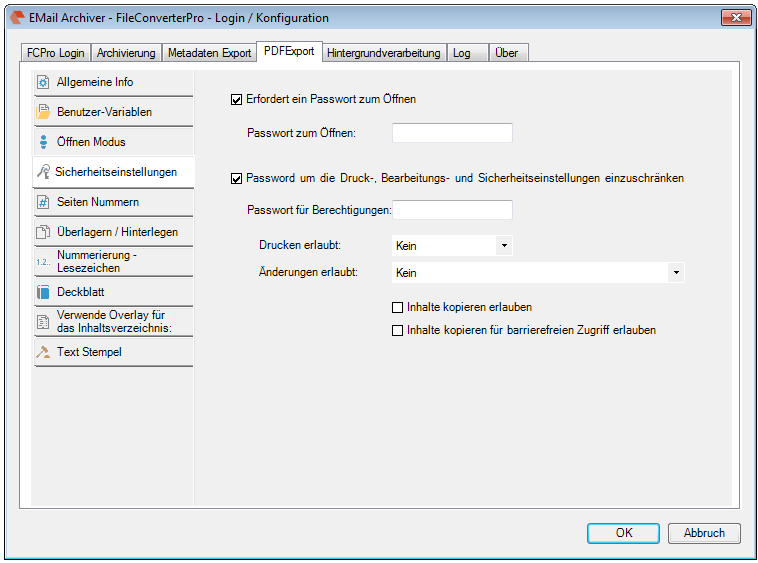
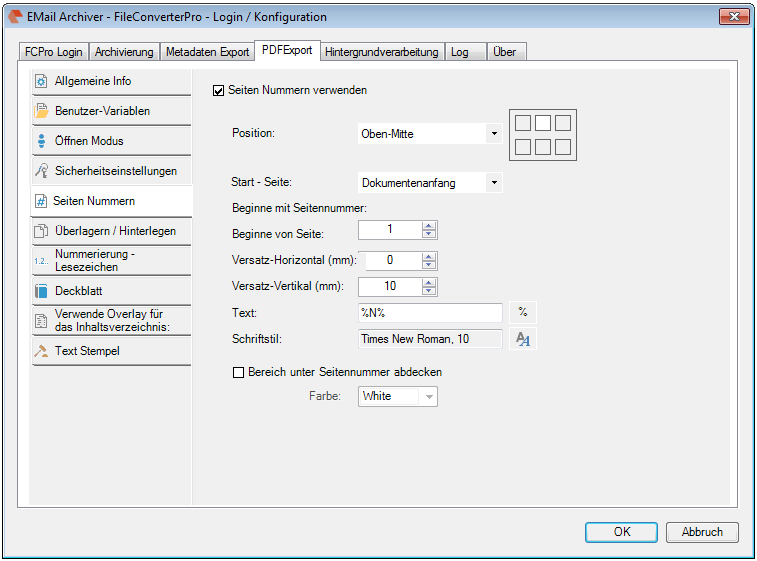
Recently, the new MS Office version 2016 is available. We have already successfully tested the latest version of our Email Archiver plugin for MS-Outlook of MS Office 2016 under Windows10. So the Email Archiver plugin can be used with MS Outlook versions 2007/2010/2013/2016.
Download – EMail Archiver Outlook Plugin für FileConverterPro >>>
Download – EMail Archiver Station Outlook Plugin inkl. FileConverterPro lokal >>>