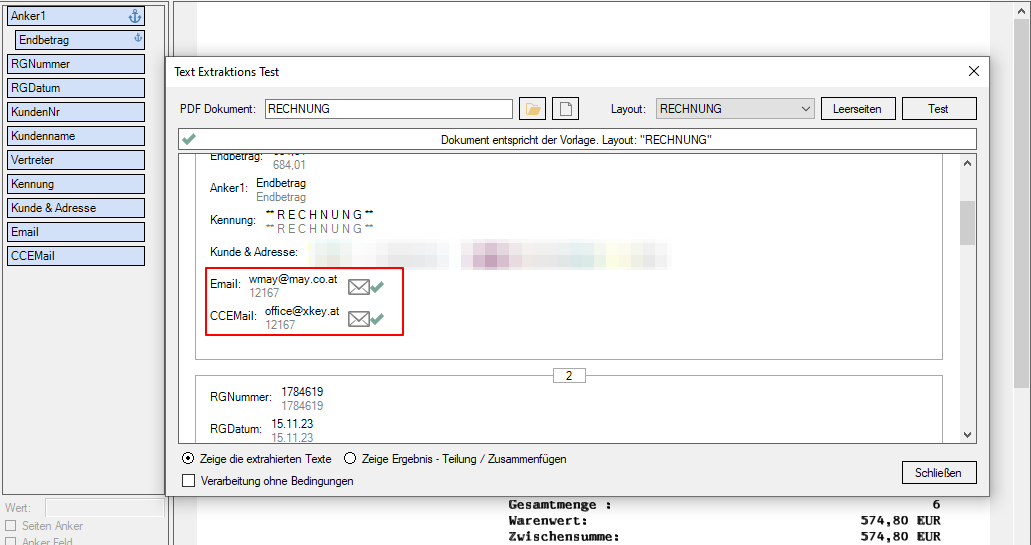
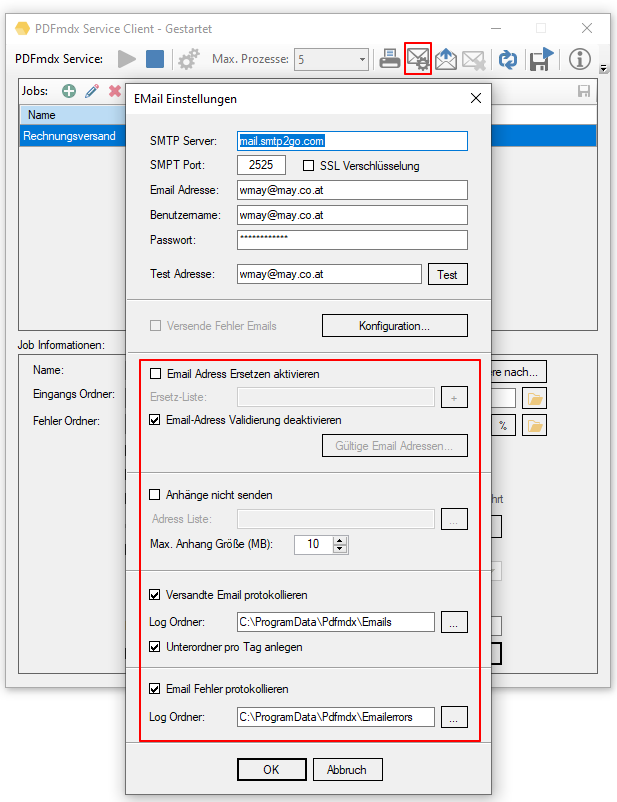
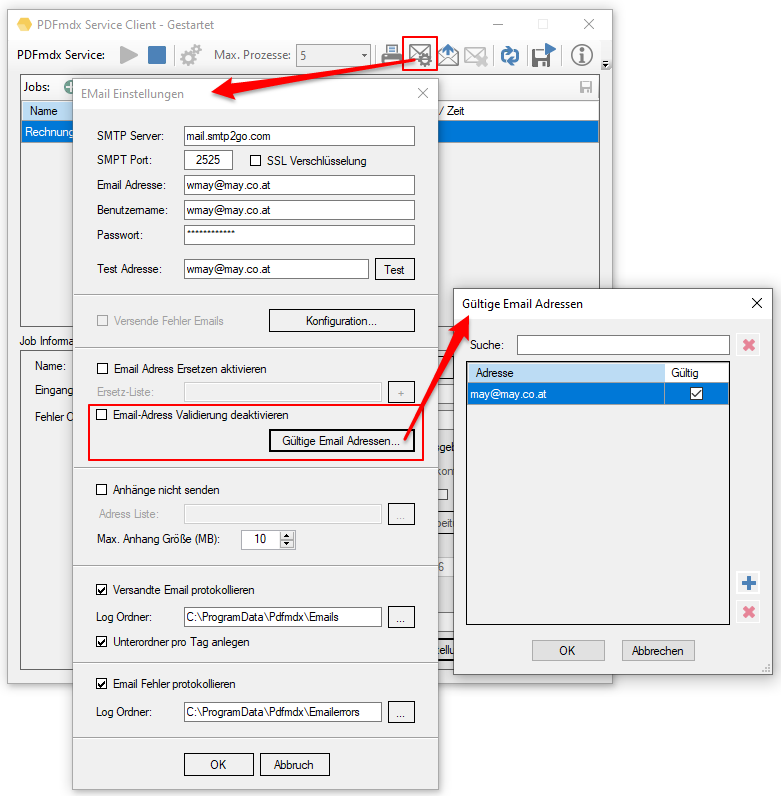
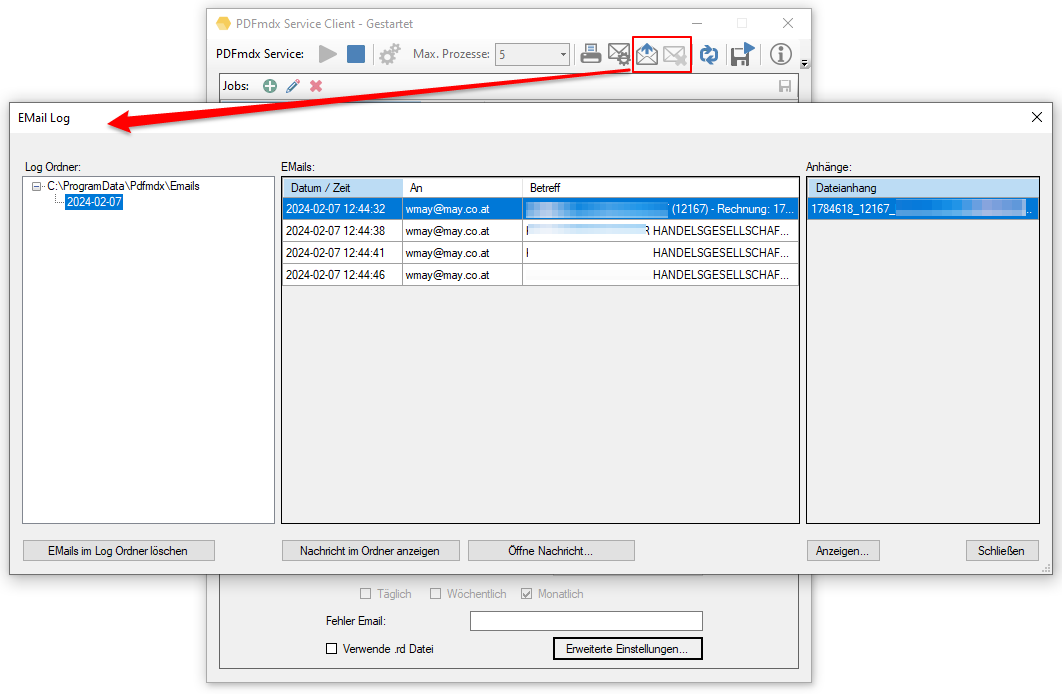
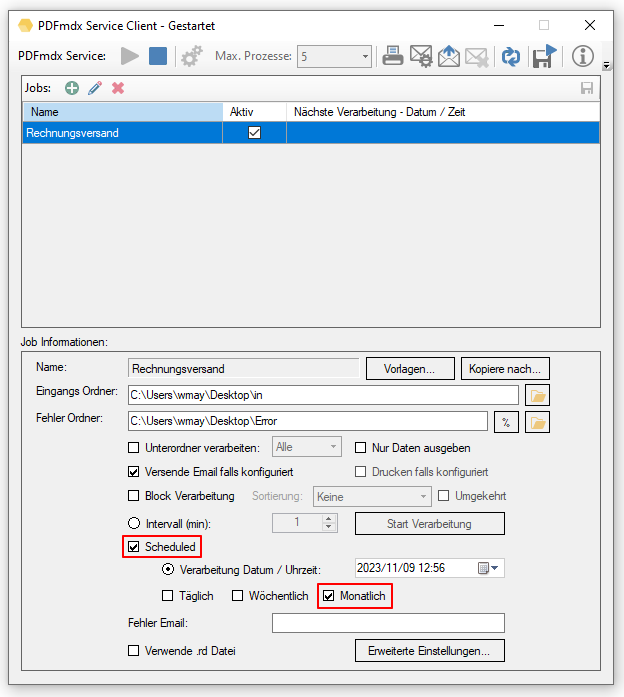
FileConverterPro (FCpro) 1.3.5 – OCR Performance wesentlich verbessert
Neuerungen der FCpro Version 1.3.5 :
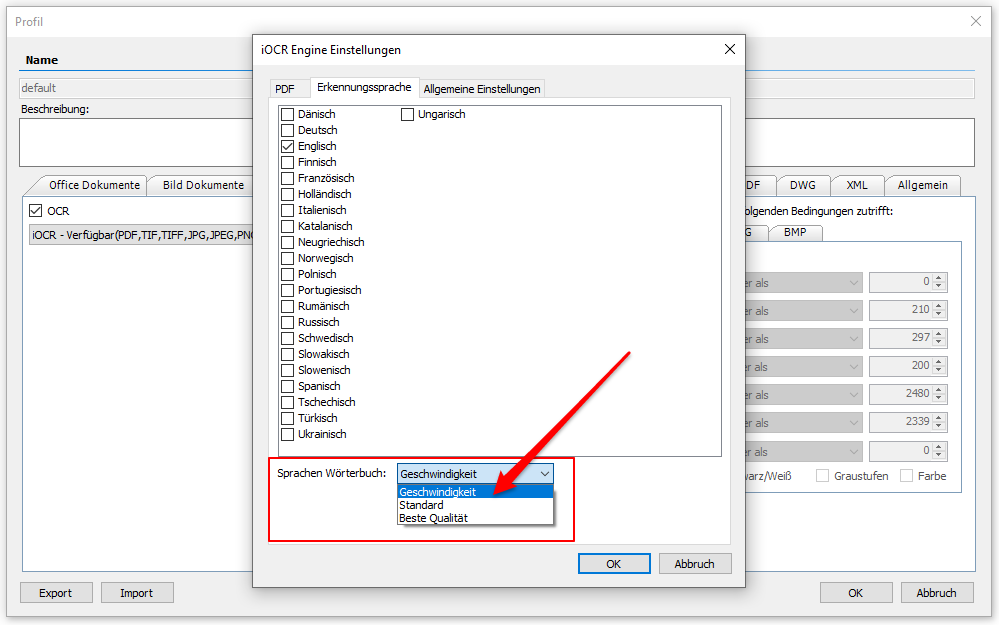
- Wesentliche Verbesserung der OCR Performance: Bisher wurde auf Grund eines Fehlers bei der OCR Verarbeitung, unabhängig von der getroffenen Auswahl, eine falsche Voreinstellung verwendet. Aus diesem Grund war die Performance der OCR Verarbeitung wesentlich vermindert. Diese Problem wurde behoben, damit ergibt sich eine wesentlich Steigerung der OCR Verarbeitungsgeschwindigkeit. Wichtig dabei ist, dass man die Option „Geschwindigkeit“ und nicht „Standard“ bzw. „Beste Qualität“ auswählt.
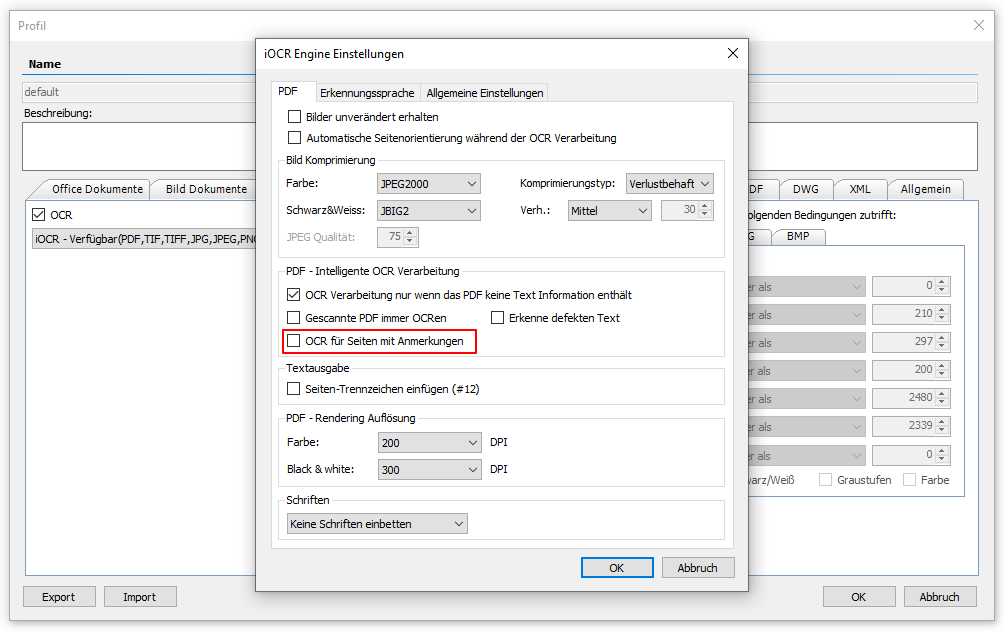
- Neue Option – Rendering von PDF Amerkungen (Annotations): Mit dieser Option kann gesteuert werden ob PDF Anmerkungen einer OCR Verarbeitung unterzogen werden sollen oder nicht. Bisher wurden immer alle Seiten mit PDF Anmerkungen neu gerendert. Damit wurden die Anmerkungen immer auch der OCR Verarbeitung unterzogen und waren in der Ergebnisdatei enthalten. Das nochmalige Rendering der betroffenen Seiten kostet jedoch Zeit und Ressourcen. Mit dieser Option kann nun gesteuert werden ob dieser zusätzliche Schritt erfolgen soll oder nicht. Ist die Option nicht aktiv so werden PDF Anmerkungen ignoriert und es erfolgt eine direkte OCR Verarbeitung bzw. werden PDF Seiten die bereits Text enthalten übersprungen.