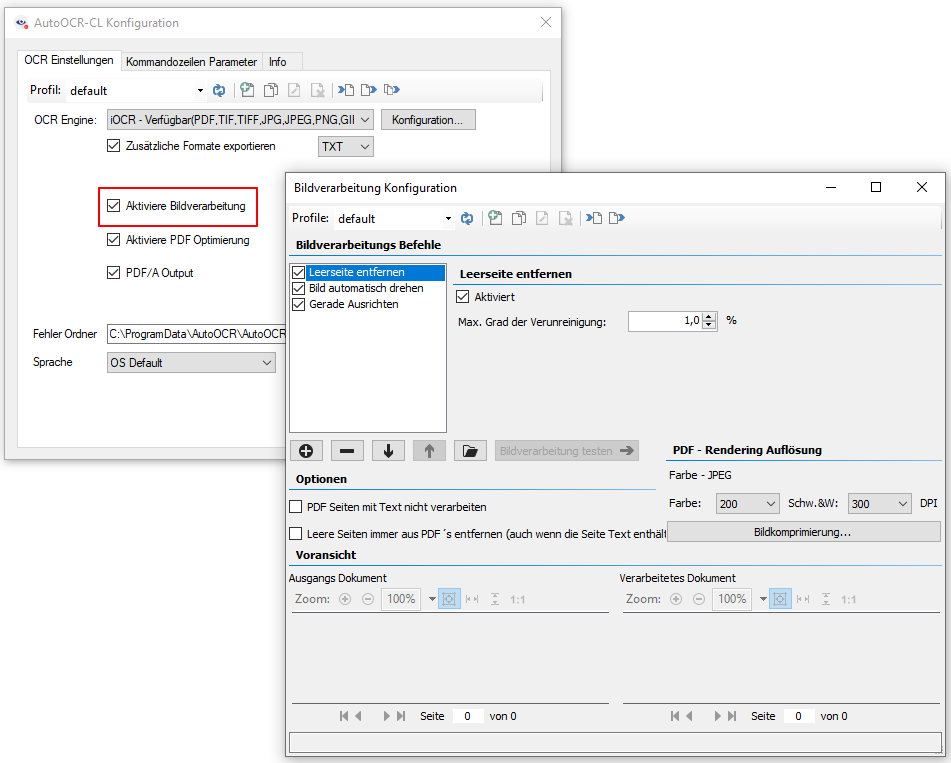
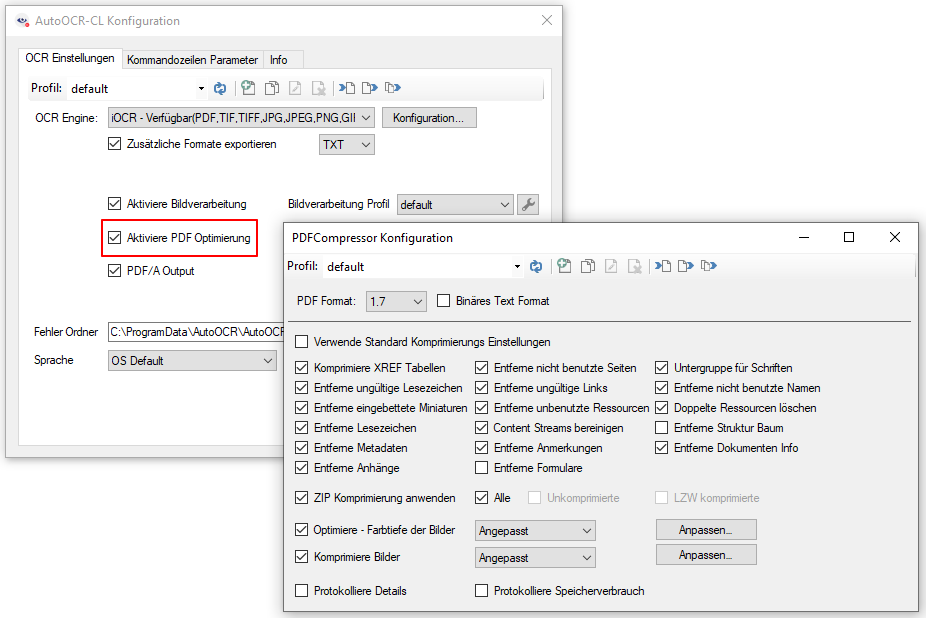
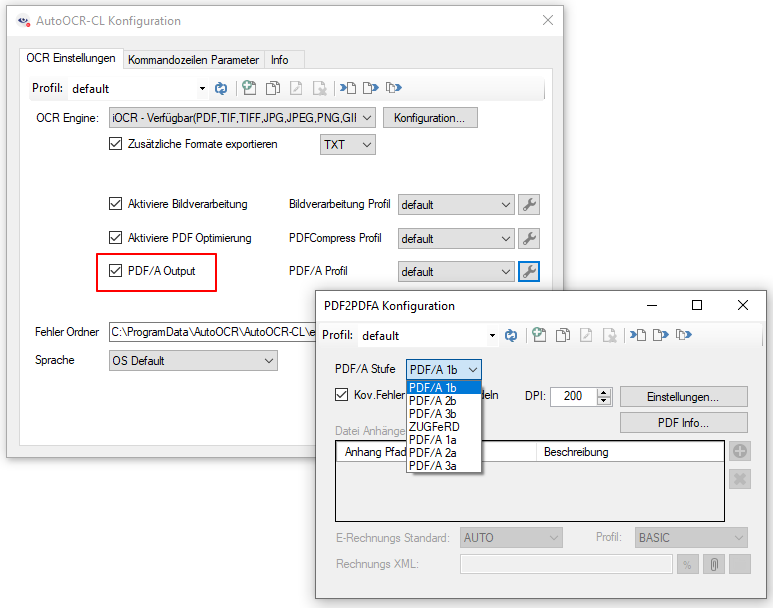
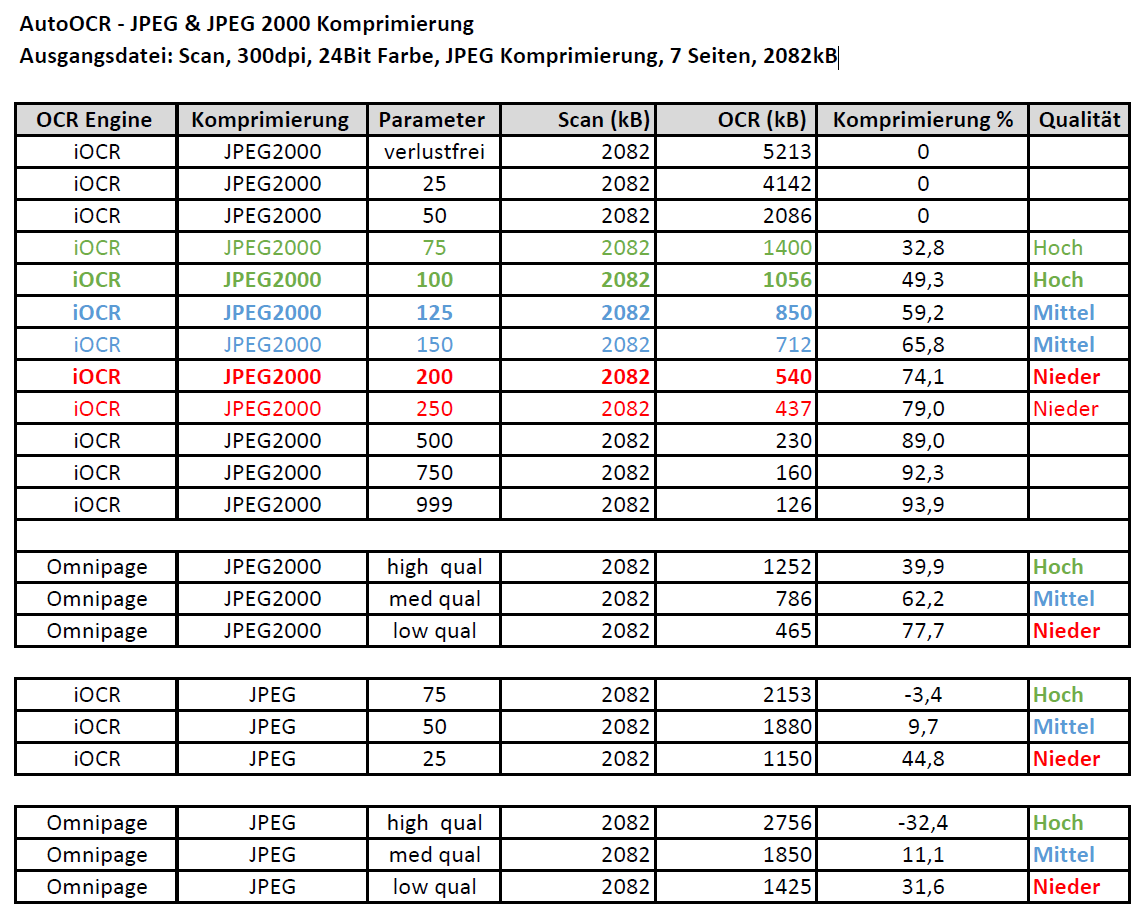
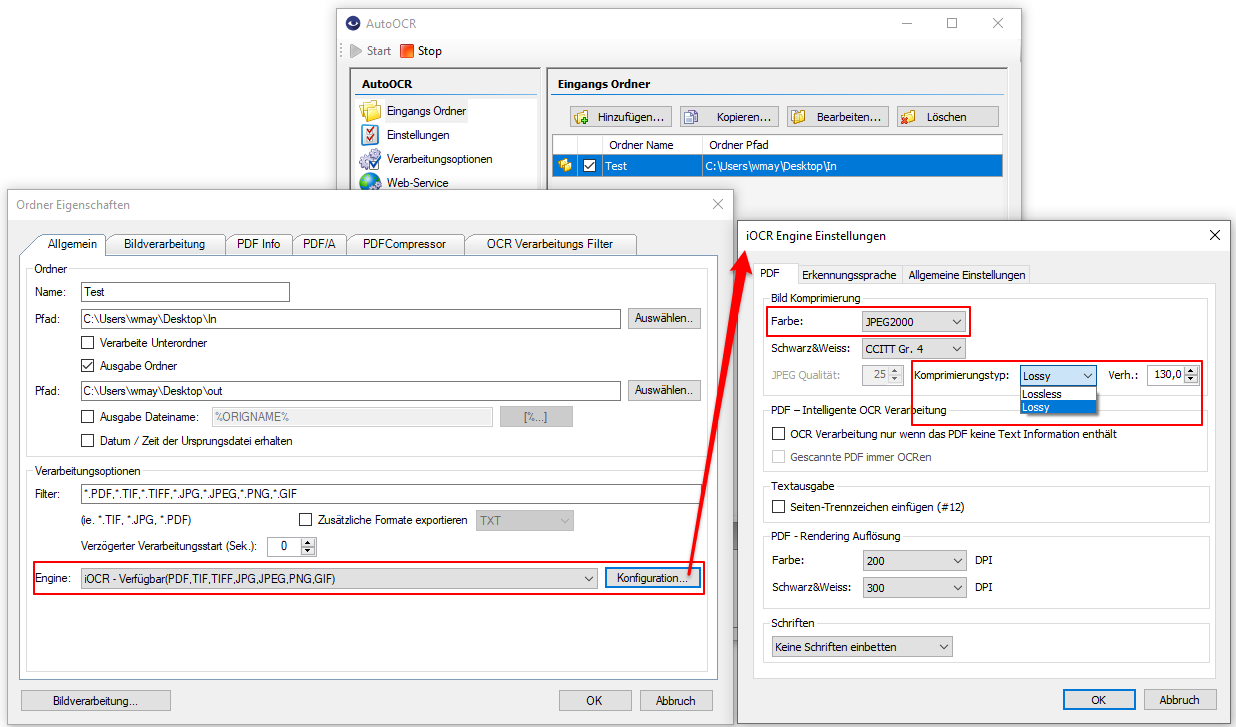
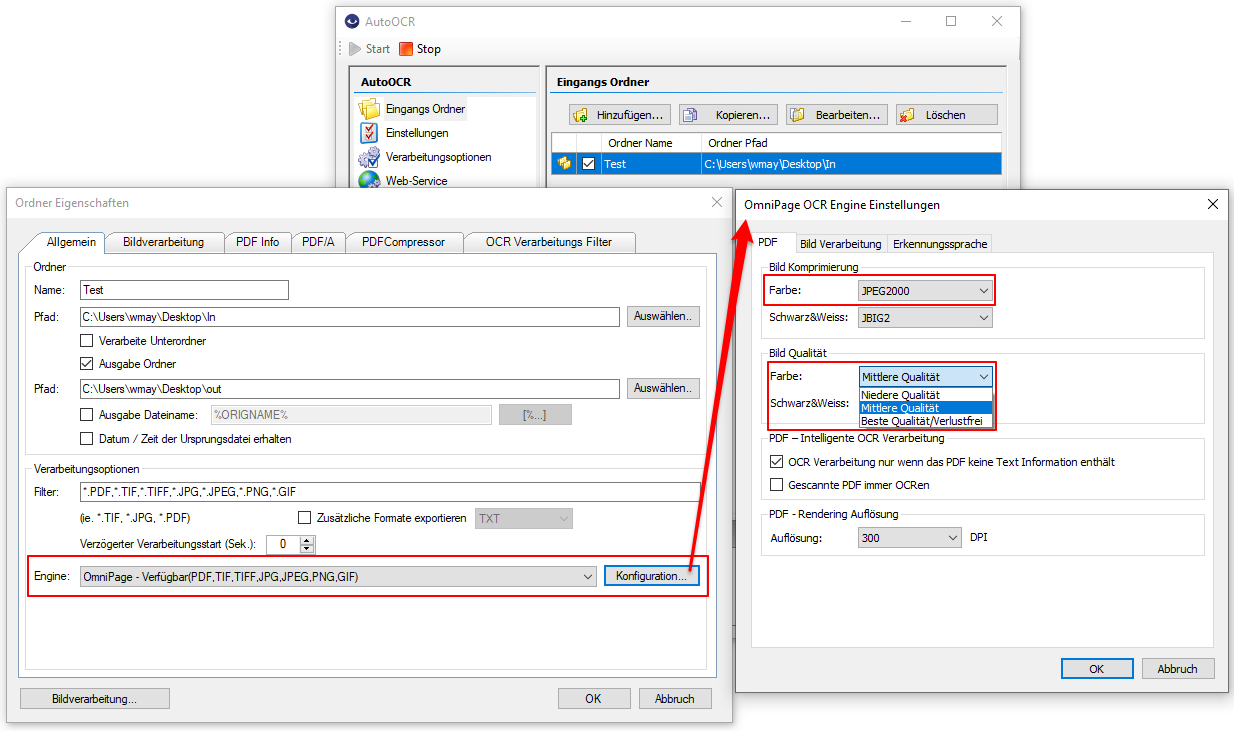
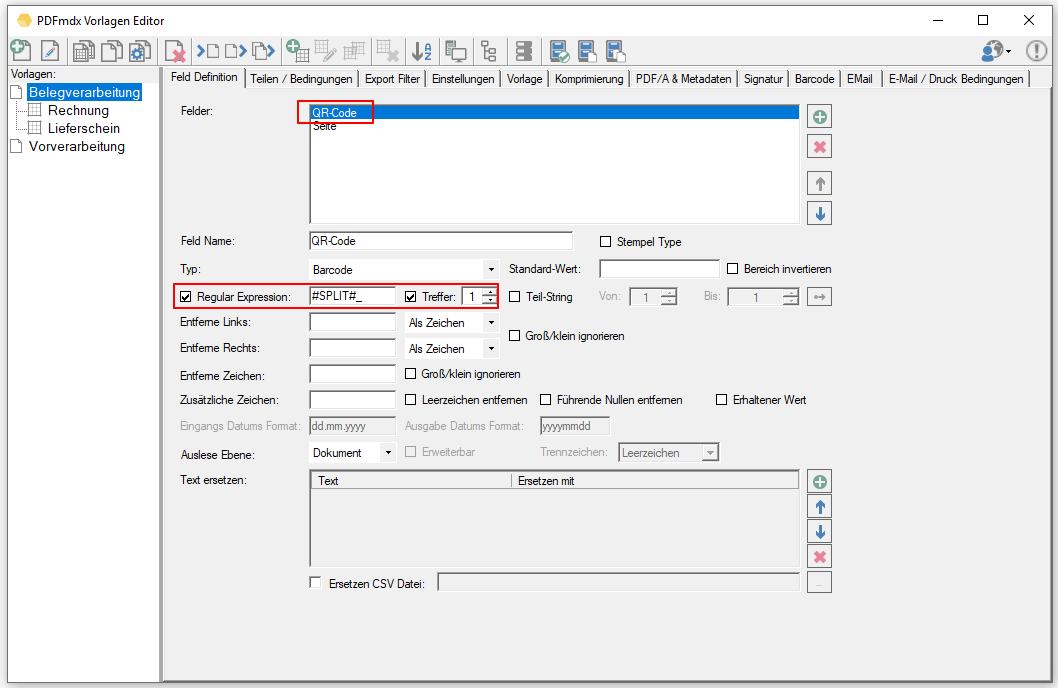
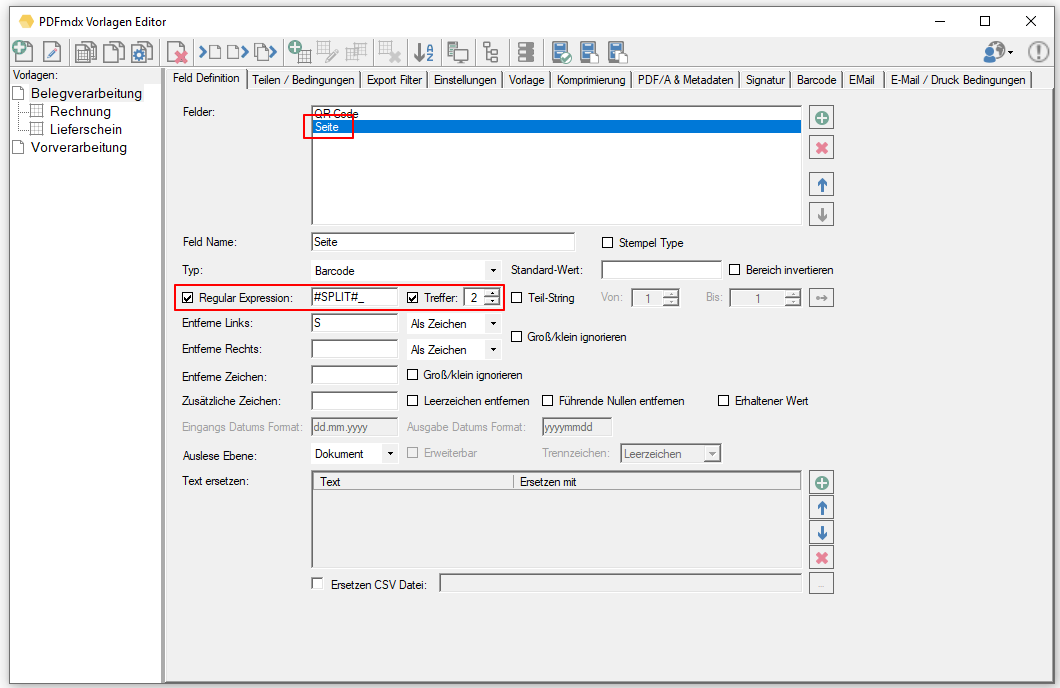
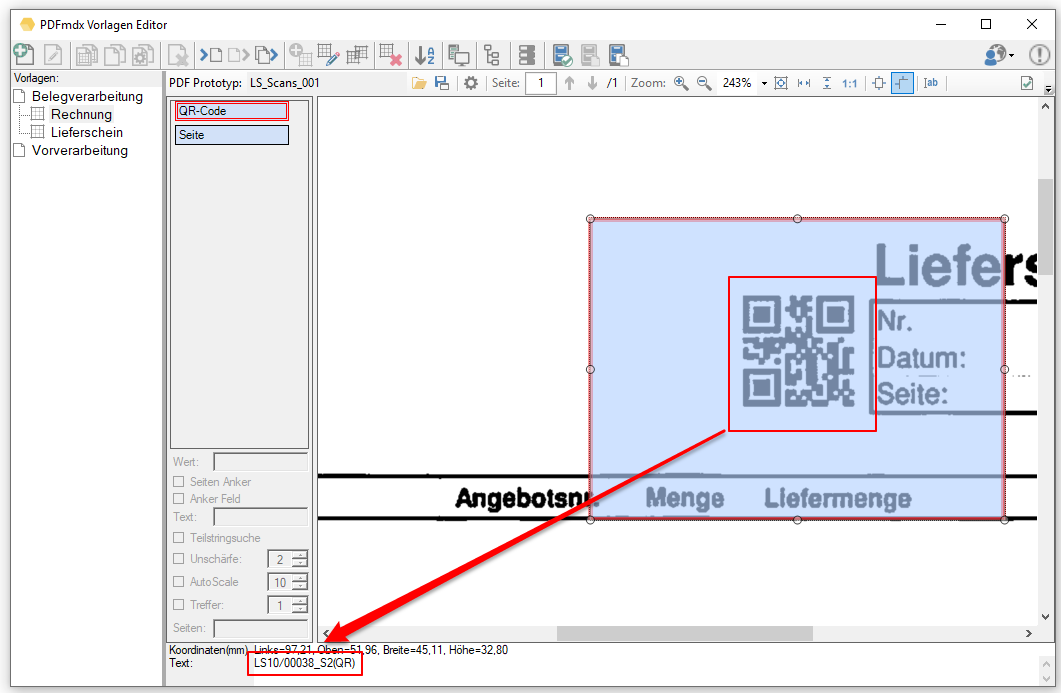
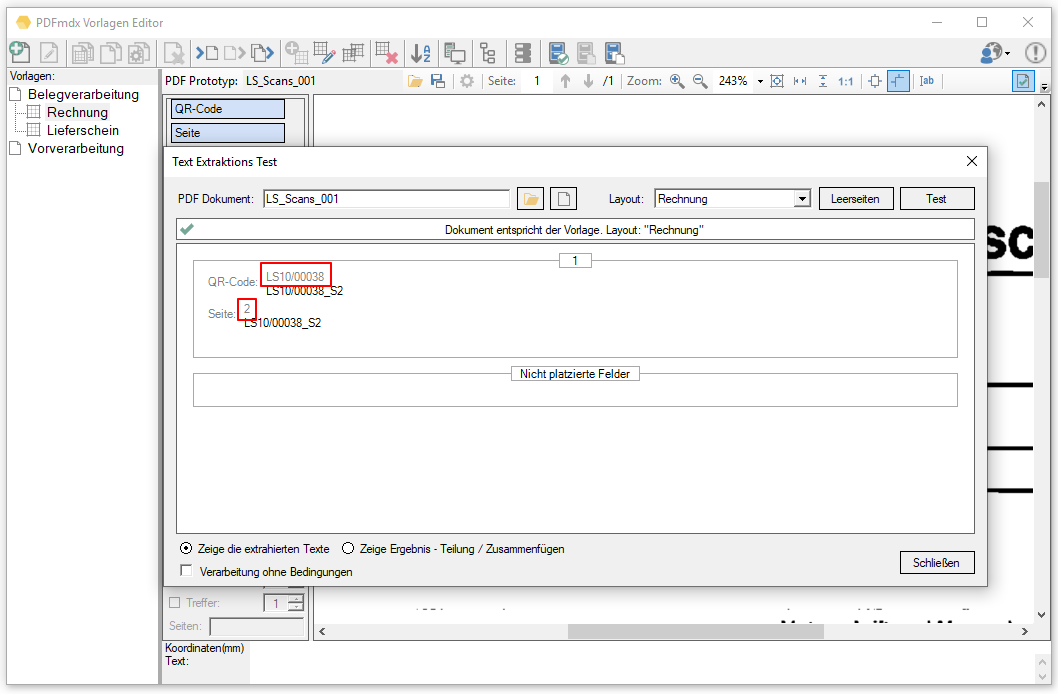
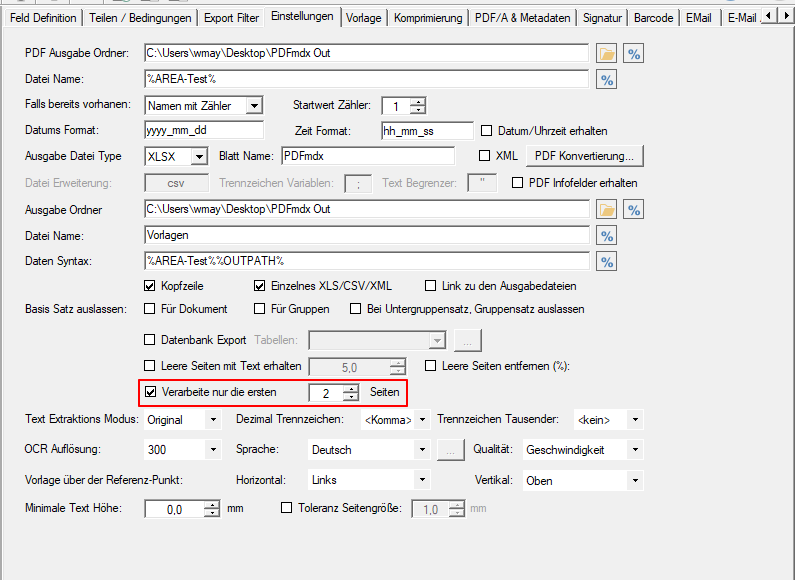
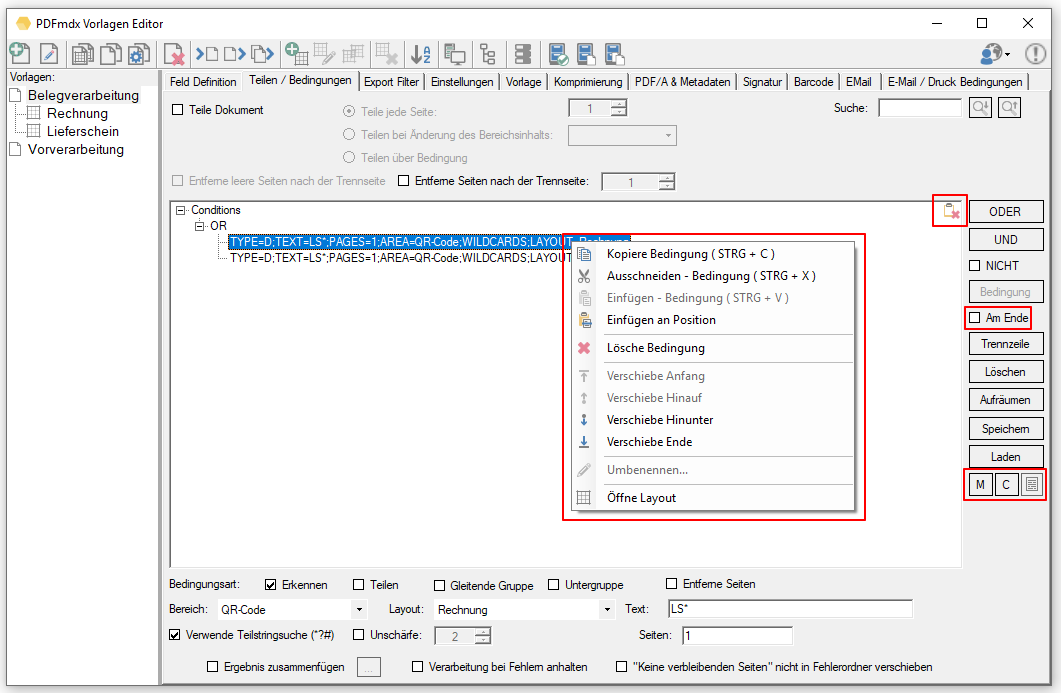
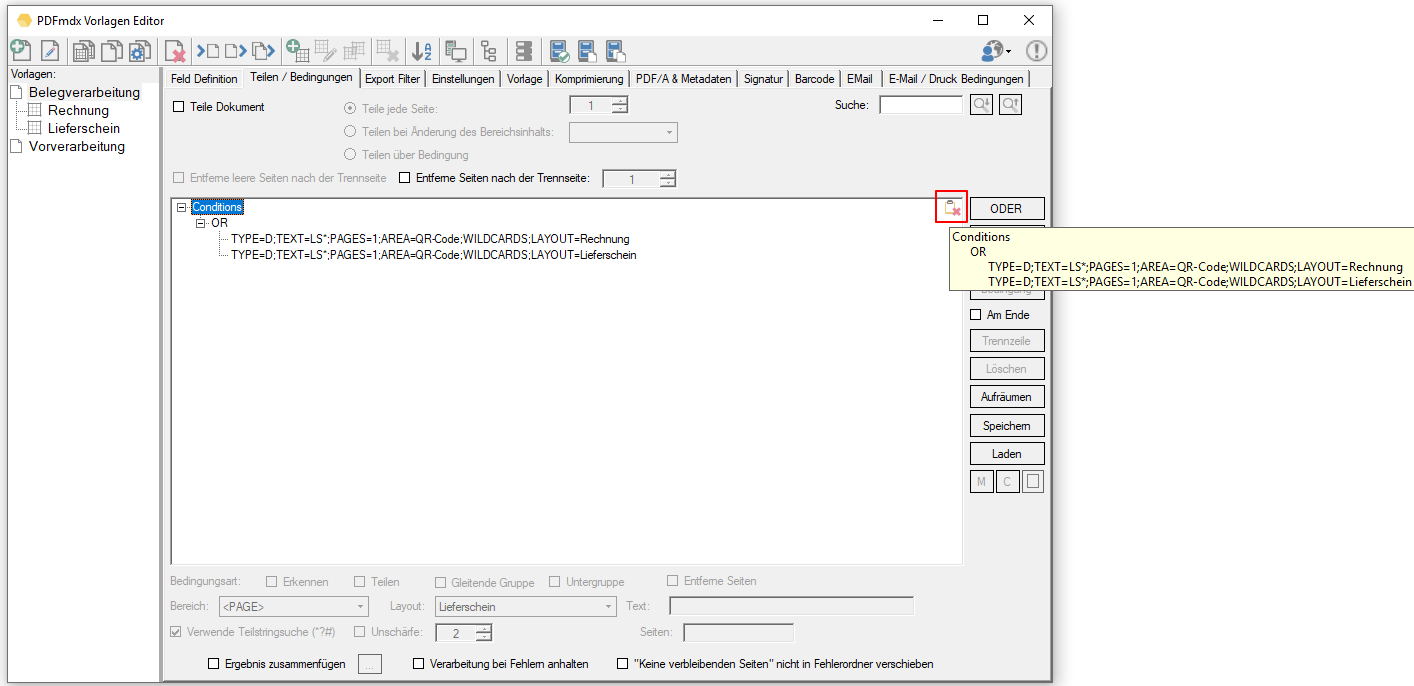
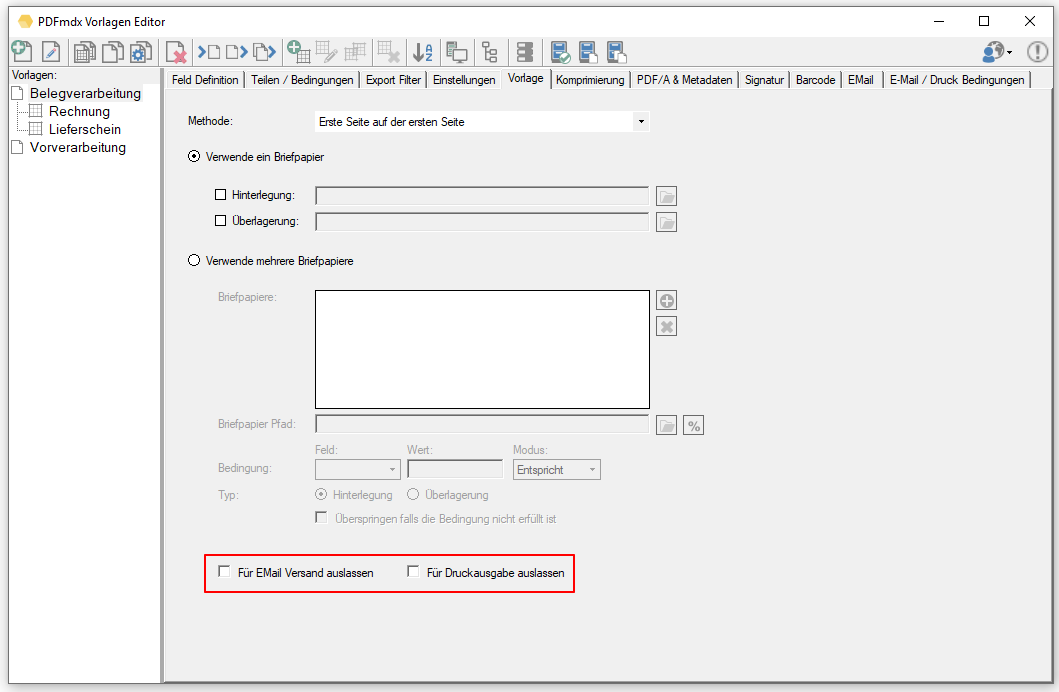
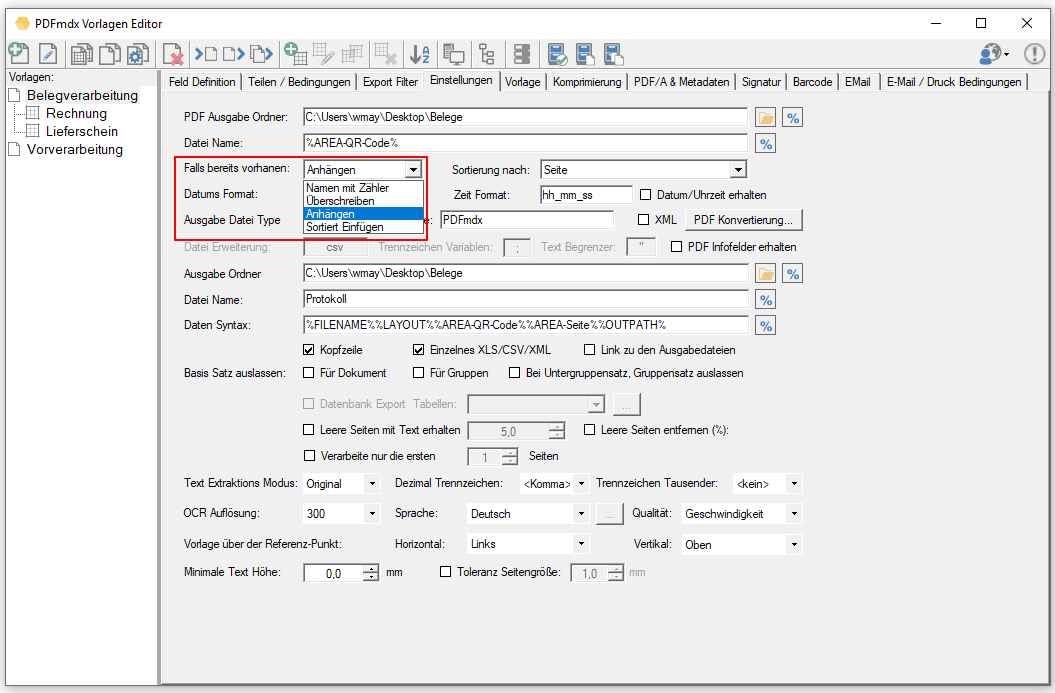
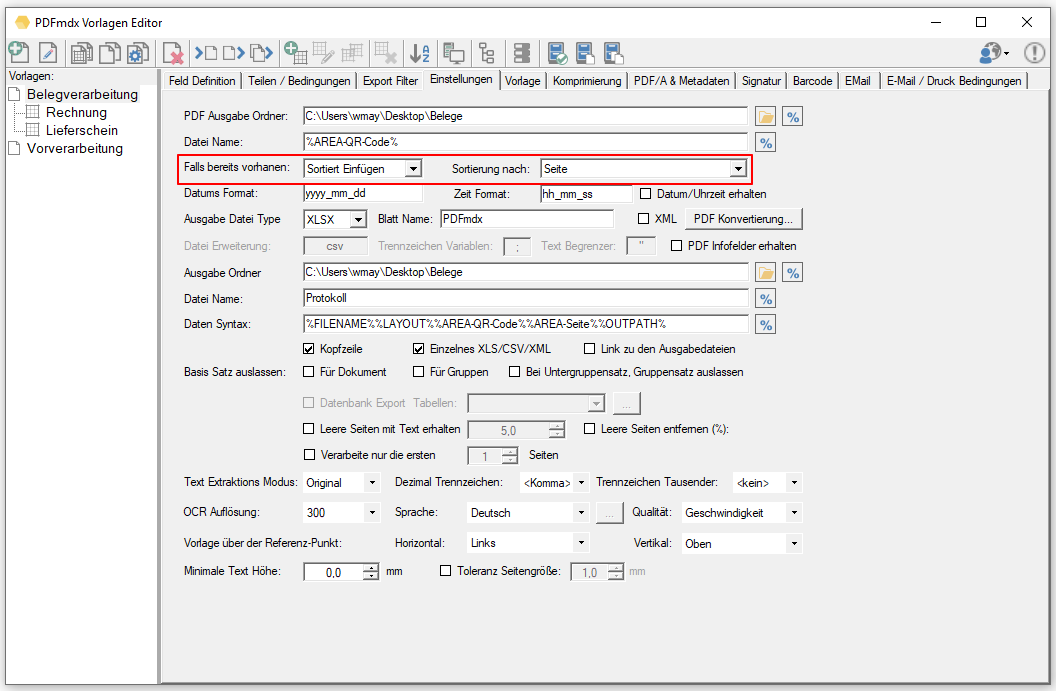
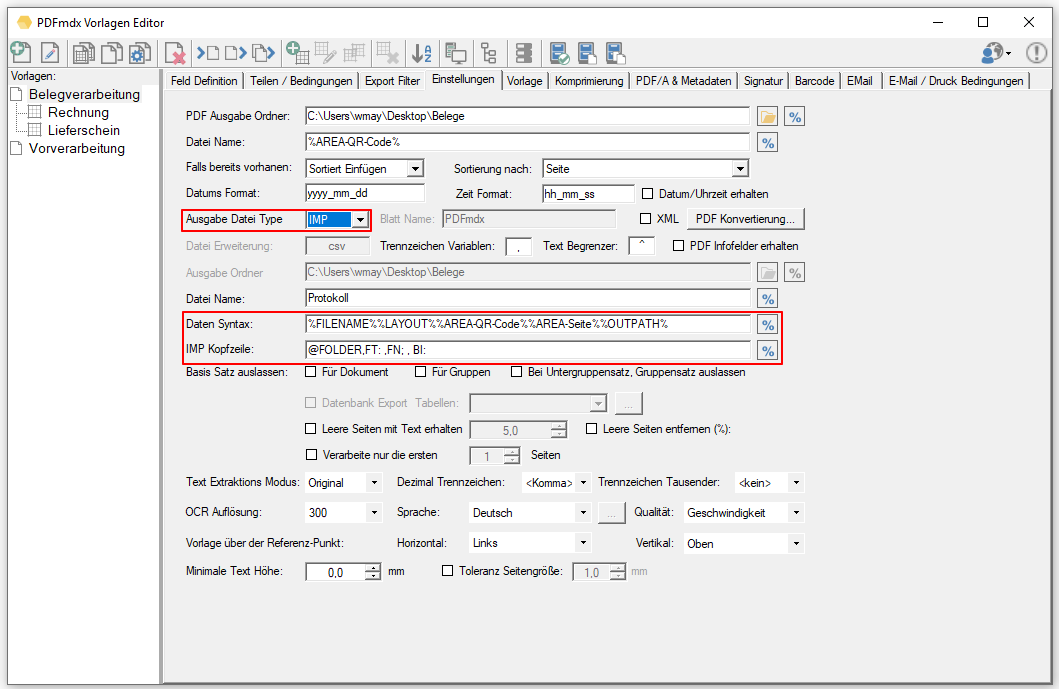
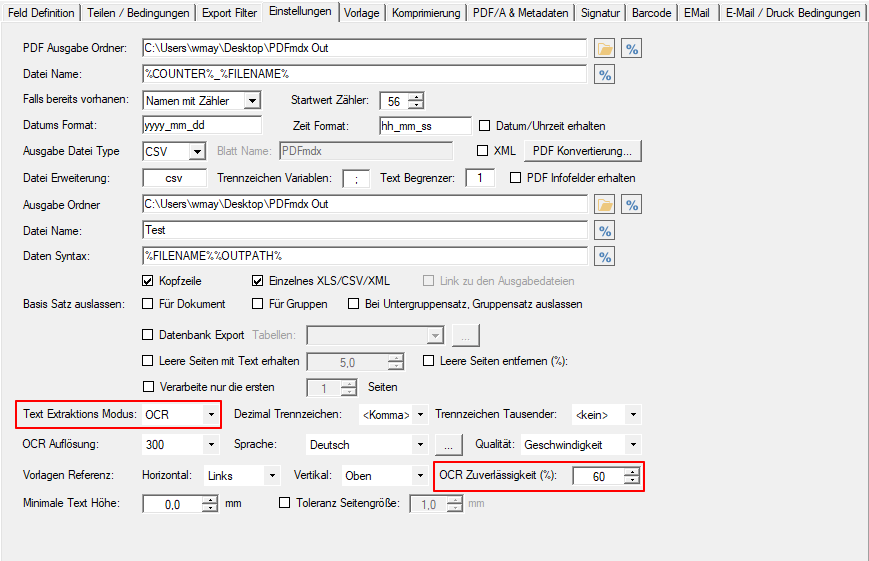
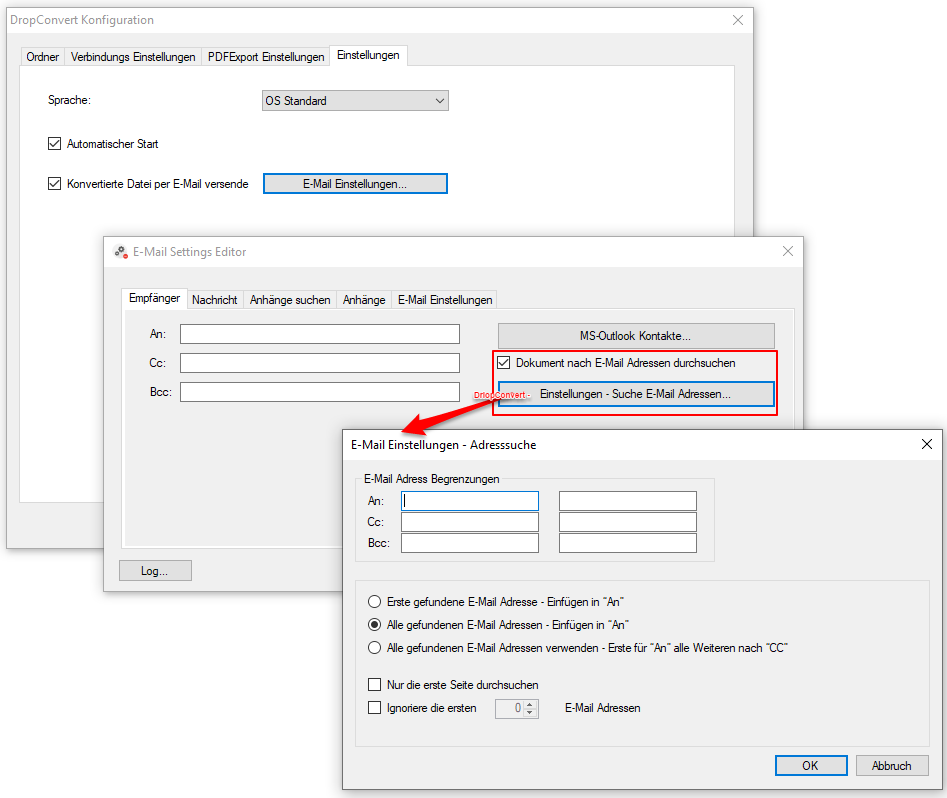
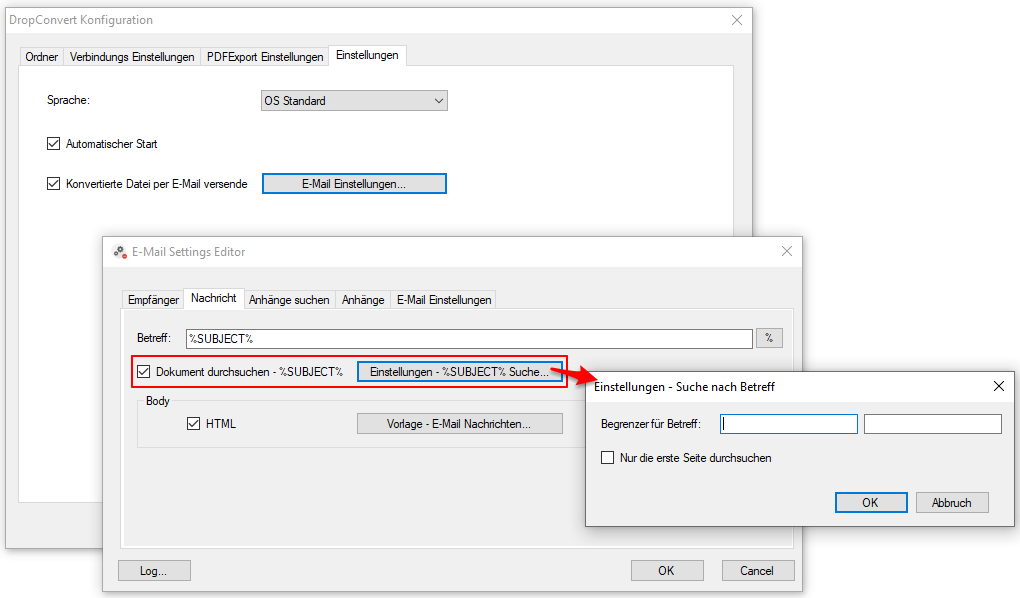
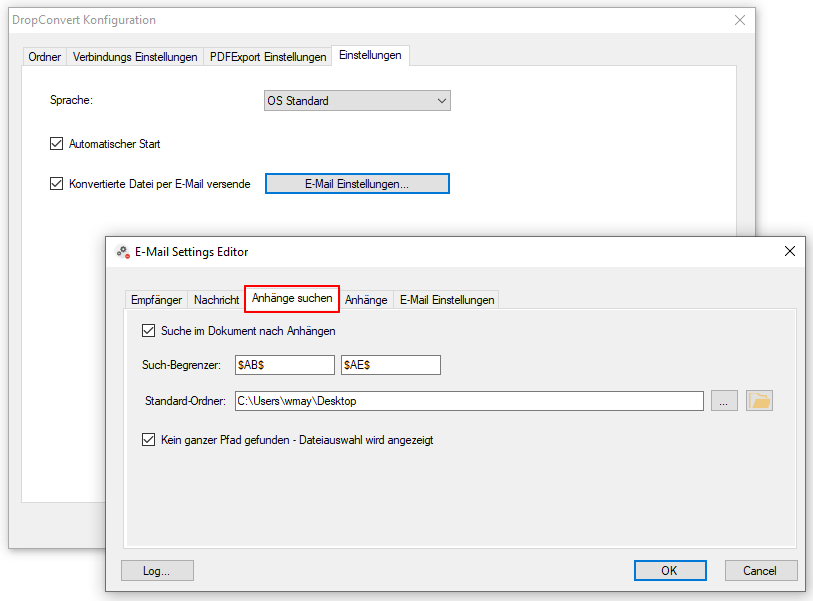
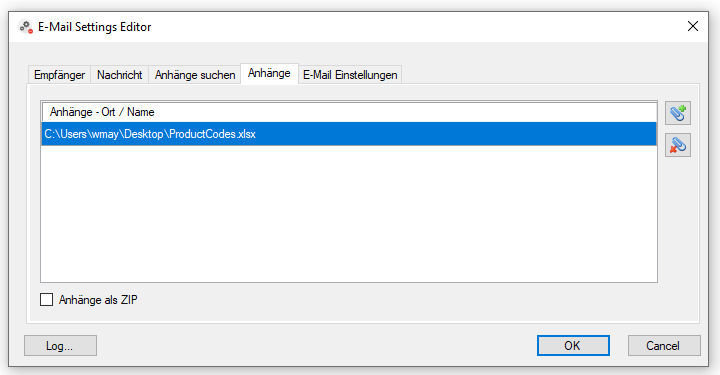
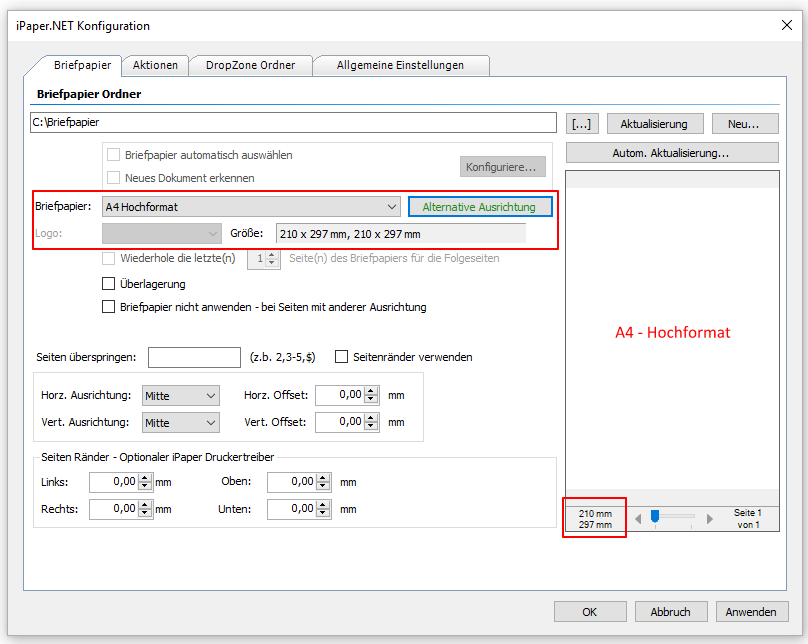
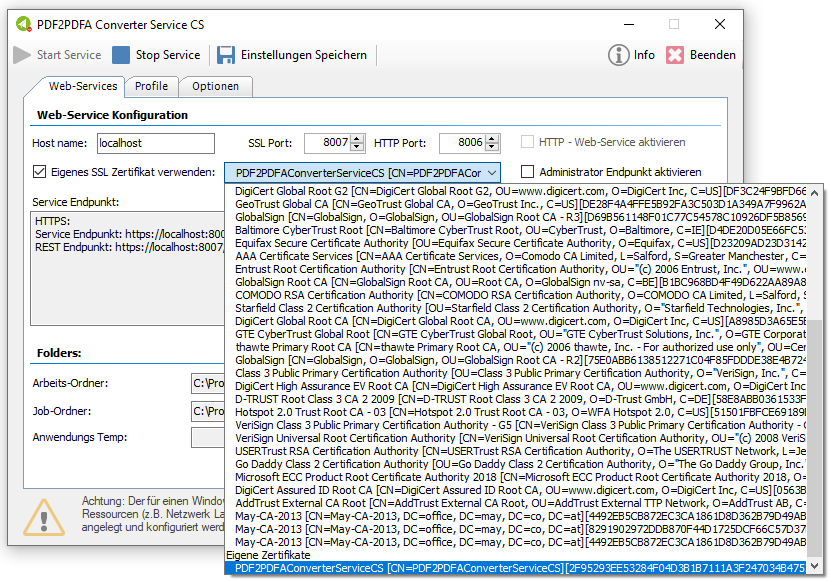
Web service applications – own SSL certificate can be selected
Web service applications require an SSL certificate for the encrypted REST / SOAP (https) communication between the service and the clients. The SSL certificate is stored on the computer and can either be a self-created certificate or a certificate from an official certification authority. So far, our applications, which have a web service interface, have automatically installed and used self-created certificates with the setup. It is now also possible to select and use other certificates installed on the computer.
Download – PDF2PDFA-CS – PDF to PDFA Converter Service >>>
Download – PDFCompressor Service incl. REST / SOAP Beispiele >>>
Download – HTML2PDF-CS – Converter Service via REST & SOAP >>>
Download – PDF2DOCX-CS – Converter Service – Windows service with REST / SOAP Interface >>>