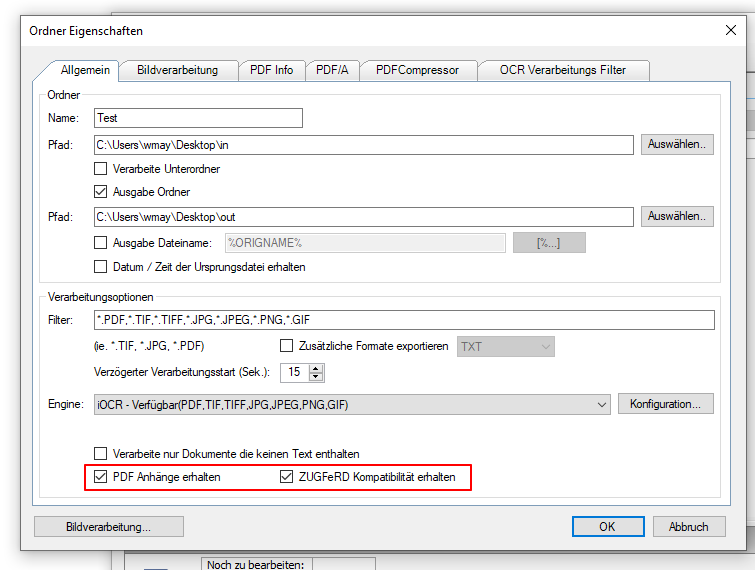
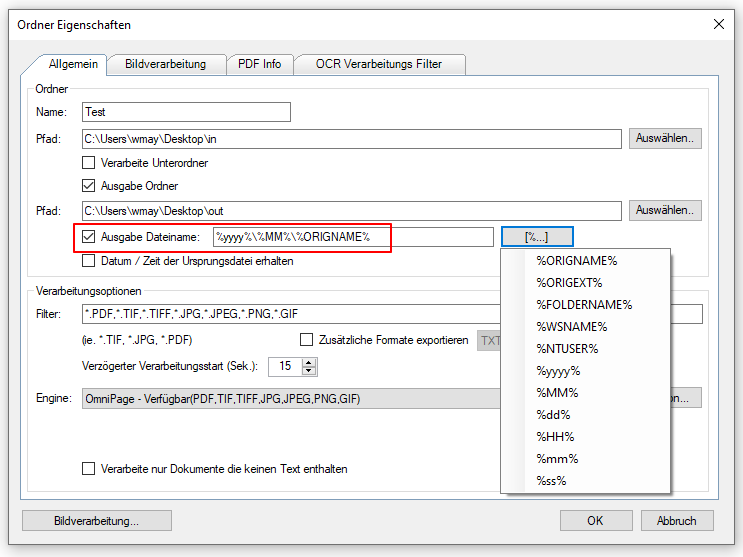
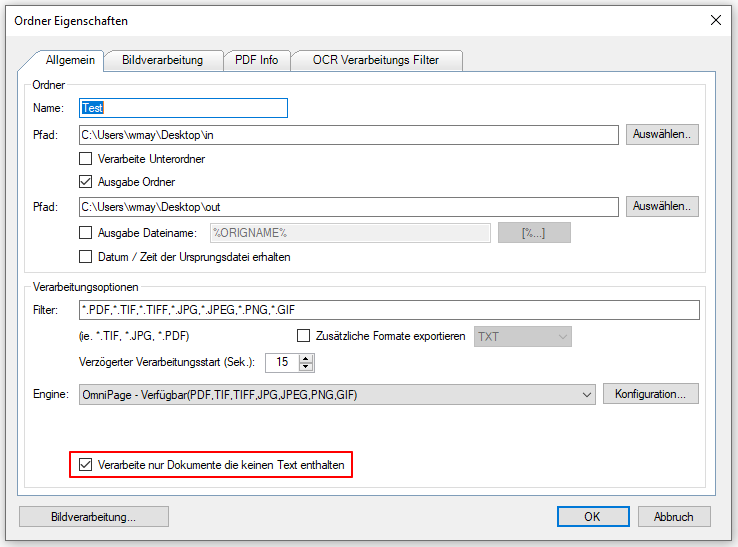
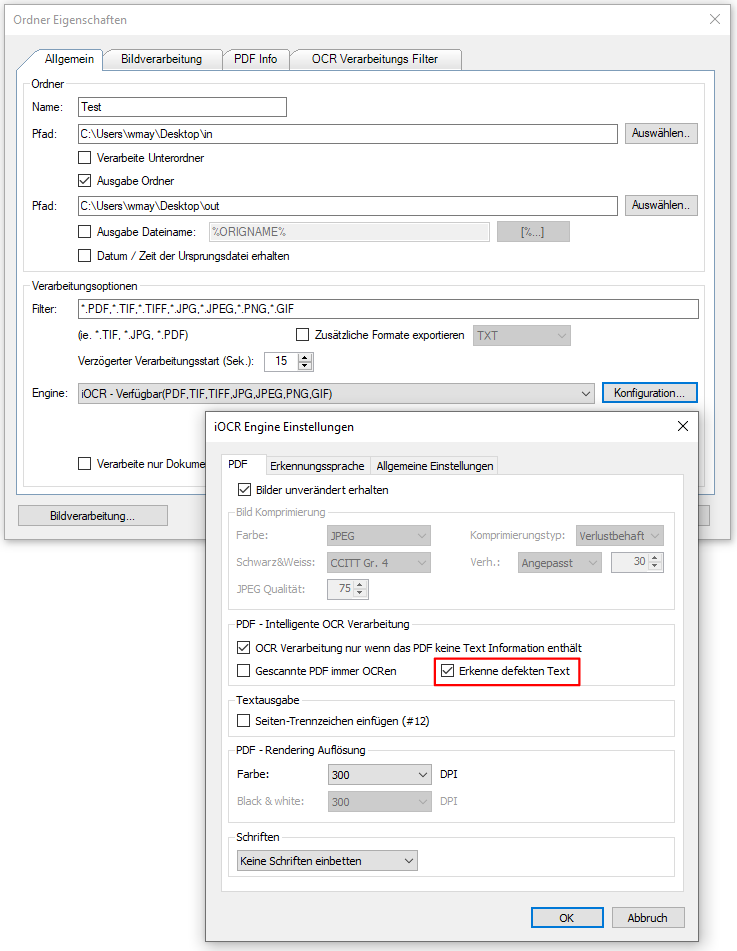
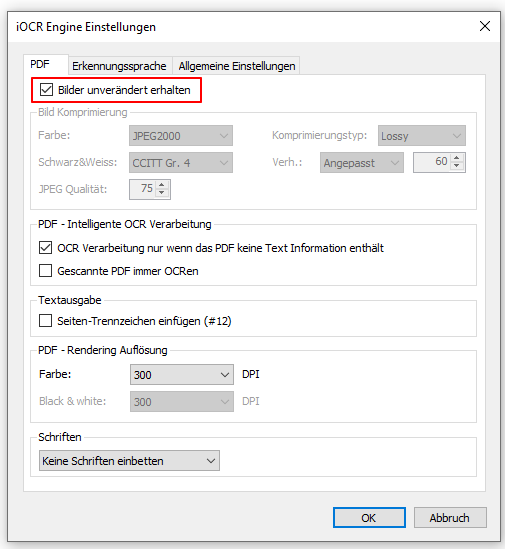
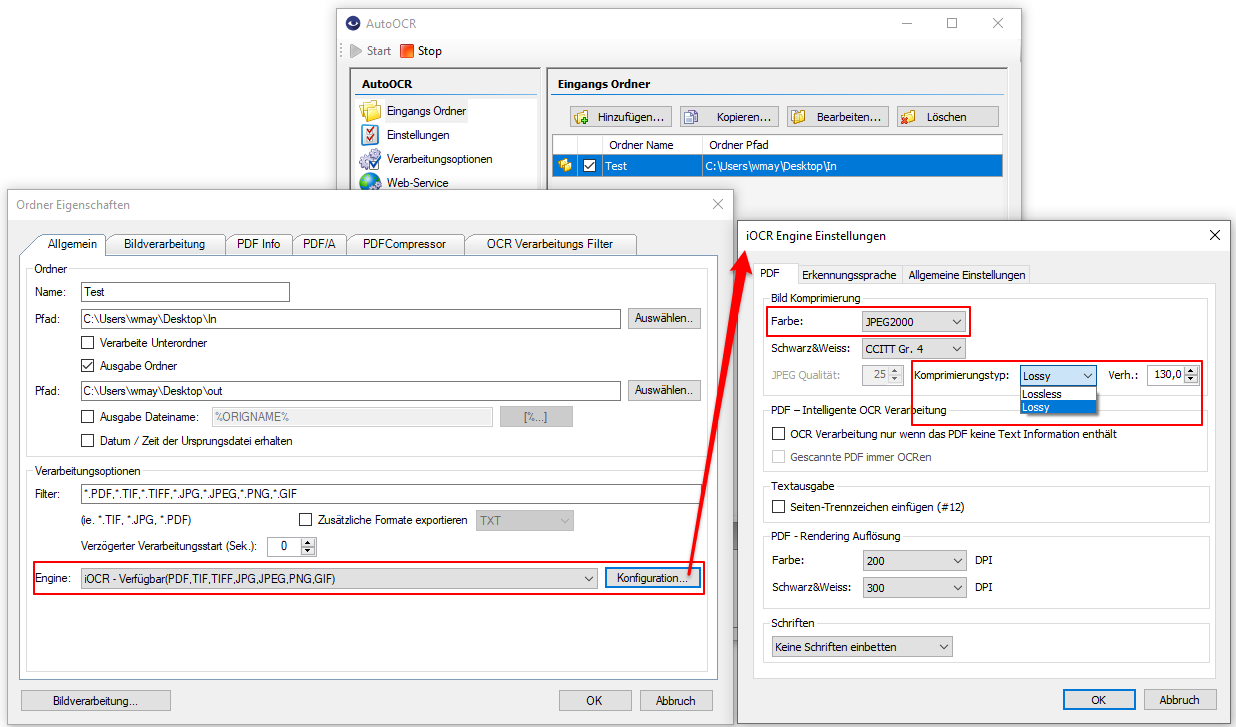
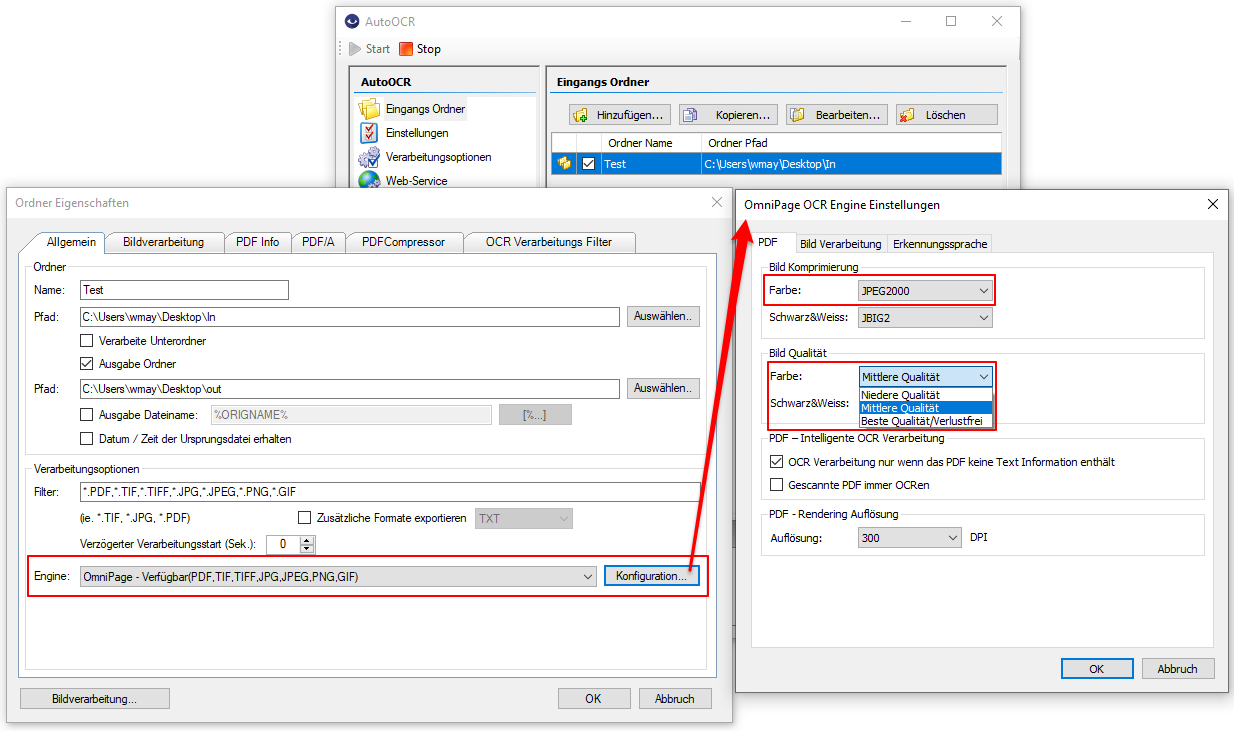
AutoOCR 2.1.1 letzte Version vor der Änderung der PAM AppID
Ab AutoOCR / AutoOCR-light Version 2.1.5 gibt es eine neue PAM AppID: AutoOCR = 4AO / AutoOCR-light = 4AL. Kunden mit aktiver Wartung können jederzeit die aktuelle Verison 2.1.5 einsetzen. Sie erhalten von uns für diese PAM AppID die Lizenz eingetragen. Kunden ohne aktiver Wartung können nur jene Version einsetzen welche beim Kauf der Software aktuell verfügbar war.
Aus diesem Grund kann es erfoderlich sein wieder auf eine vorhergende Version z.b.: Version 2.1.1 zurück gehen zu müssen – wie geht das:
- AutoOCR / AutoOCR-light Dienst stoppen und AutoOCR Userinterface beenden
- AutoOCR / AutoOCR-light deinstallieren
- vsOCR deinstallieren – Das ist wichtig ansonsten funktioniert die Version 2.1.1 nicht falls die neue vsOCR noch auf dem Rechner vorhanden ist.
- AutoOCR / AutoOCR-light Version 2.1.1 herunterladen und installieren
Einstellungen und Lizenz bleiben erhalten. Falls ein User Account für den AutoOCR / AutoOCR-light Dienst (User/Domain/Passwort) verwendet wurde muss dieser neu konfiguriert werden.
Download – AutoOCR Version 2.1.1 >>>
Download – AutoOCR-light Version 2.1.1 >>>