Im Zuge verschiedener Projekte erweitern wir laufend die Funktionen unserer .NET Basis Komponenten. Nachfolgende einige Beispiel daraus.
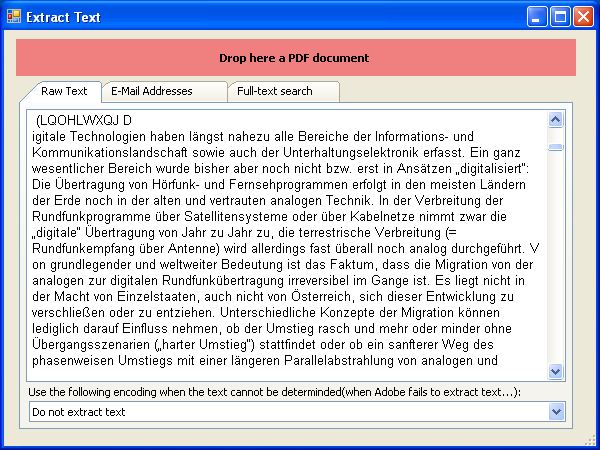
Extrahieren der Textinformation aus PDF
verwenden wir zum Beispiel in unserem eDocPrintPro Druckertreiber um neben der PDF auch eine ASCII Datei mit der aus dem Dokument gewonnen Textinformation abzulegen. Der Text kann analyisiert, durchsucht und weiterverarbeitet werden – oder die Information wird in eine SQL/Volltext-Datenbank geschrieben um in weitere Folge die Volltextsuche zu ermöglichen.
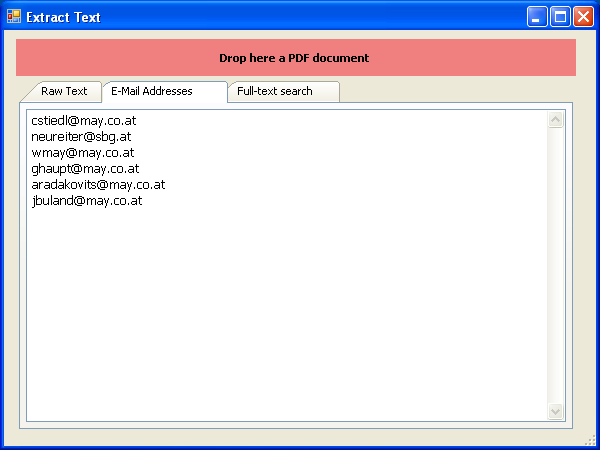
Extrahieren von E-Mail Adressen aus PDF
Unsere Komponenten erlauben es uns auch nach bestimmten Textstrings auf PDF Seiten zu suchen und das Gesamtdokumente an diesen Seiten in Einzeldokumente teilen – z.b. im eDocPrintPro PDFSplit Plugin. Ebenso gibt es eine Funktion um z.b. E-Mail Adressen aus einem PDF zu extrahieren – das verwenden wir bei iPaper oder aber auch in unserer PDFMail Software. Die PDF Dokumente können an Hand der damit gewonnen Information gleich per E-Mail verschickt werden.
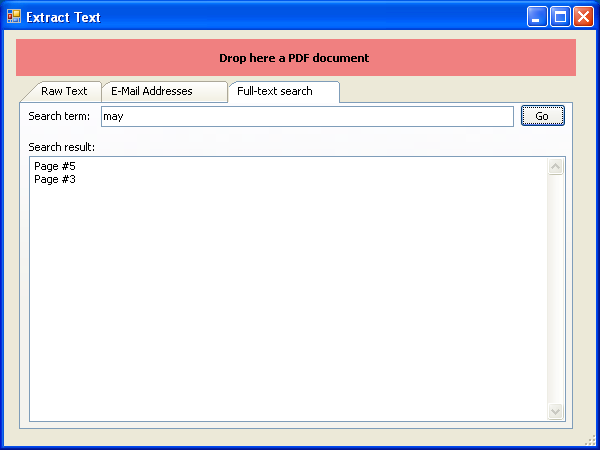
Lucene .NET – OpenSource Volltext Datenbank
Eine weitere zur Verfügung stehende Funktion erlaubt es große Datenmengen mit der Lucene .NET OpenSource Volltextdatenbank zu indizieren. Damit können auch sehr großen Dokumentenbestände blitzschnell durchsucht und Informationen zielgenau gefunden werden.
Download – Demo – Extrahieren von Text, E-Mail, Volltextsuche >>>