Merge.NET – .NET Komponente – Zusammenfügen – „Mergen“ von Einzel-PDF(/A) zu Gesamt-PDF(/A)
Merge.NET ist eine DLL die in eigene .NET / C# Anwendungen eingebunden werden kann um aus einzelnen PDF bzw. PDF/A Dateien eine Gesamt PDF bzw. PDF/A Datei zu erzeugen. Die Funktionen entsprechen unsere EasyMerge Anwendung.
Funktionsumfang:
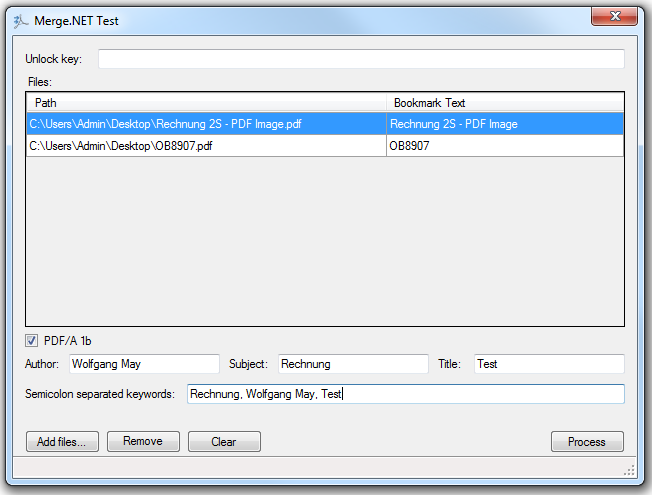
- Zusammenfügen von Einzel PDF bzw. PDF/A-1b zu einer einzigen Gesamt Datei
- Die Reihenfolge in der die Einzeldateien eingefügt werden legt auch die Sortierordnung in der Gesamtdatei fest.
- Pro Einzeldatei kann ein Bookmark Text festgelegt werden – In der Gesamtdatei werden die Bookmarks automatisch generiert.
- Option ob PDF oder PDF/A-1b erzeugt werden soll.
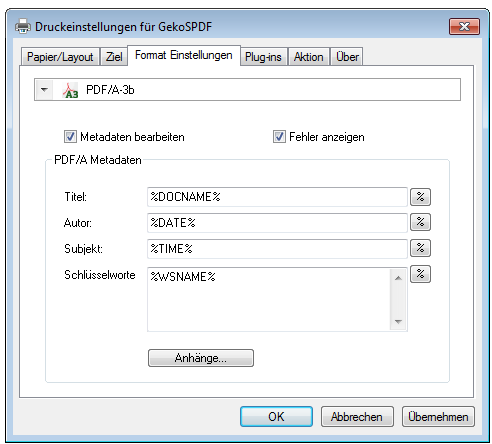
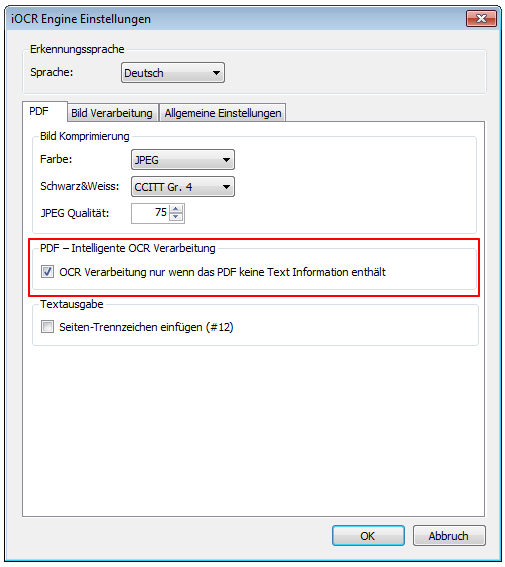
- Bei PDF/A können die PDF Infofelder festgelegt werden – Autor, Betreff, Titel, Schlüsselworte
- Programmschutz über Freischaltcode – so kann die erzeugte Anwendung kundenspezifisch geschützt werden – Ohne Freischaltcode wird ein Demostempel auf das PDF aufgebracht.
- Royalty-free Lizenzierung d.h. die Merge.NET Komponente wird einmal lizenziert und kann dann in beliebigen Anwendungen bei beliebig vielen Kunden zum Einsatz kommen.
Lieferumfang:
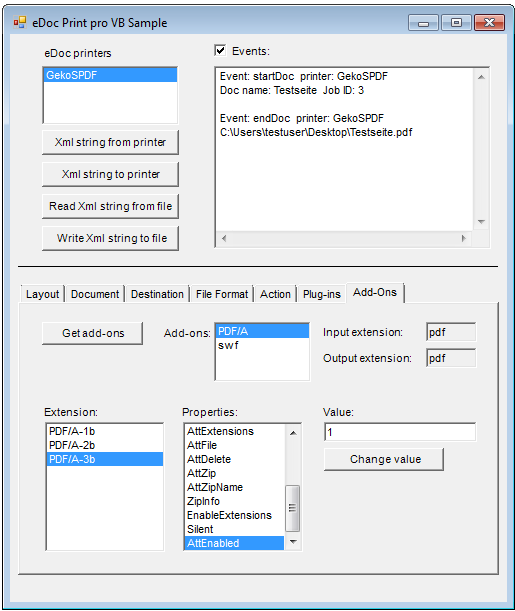
- Beispielanwendung als .NET / C# / VS Projekt – im Sourcecode sowie als EXE
- CHM Help Datei
- Merge.NET.dll
- Programm um Freischaltcodes zu erzeugen.
Installationsvoraussetzungen:
- Windows 7 oder höher, 32 oder 64bit
- .NET 2.0 Runtime
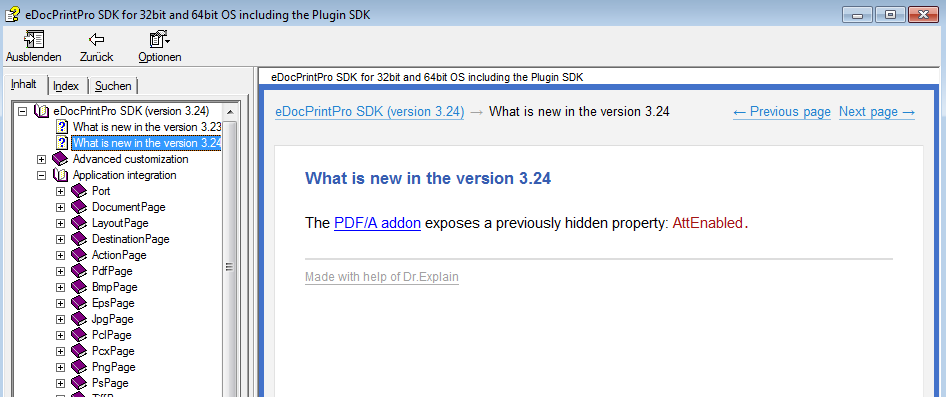
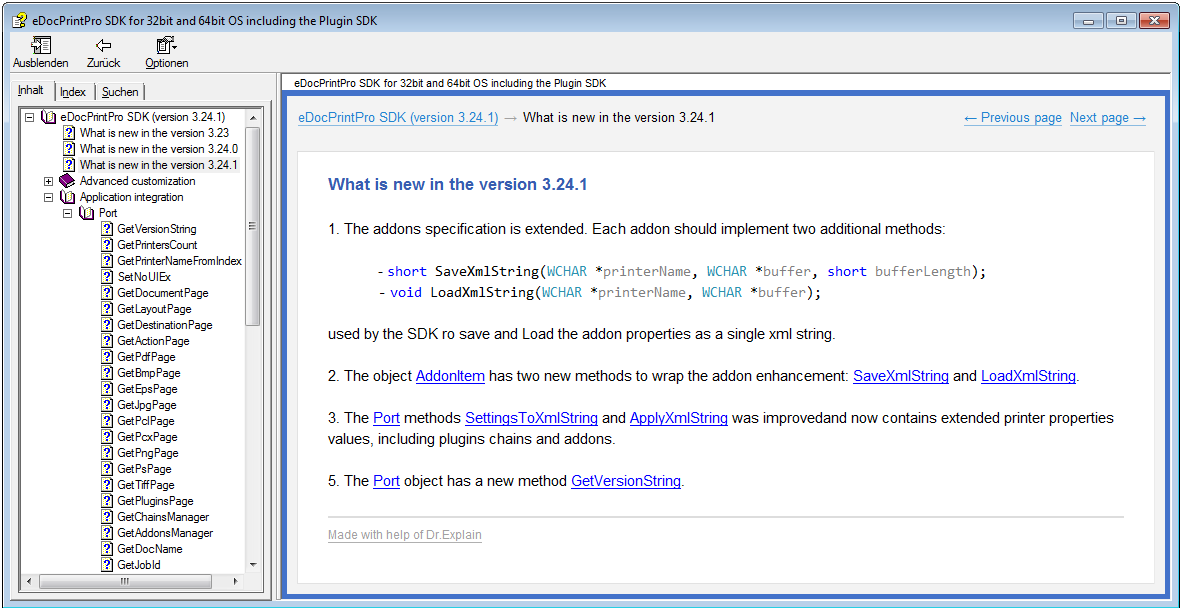
- GhostScript 9.18.1. oder eDocPrintPro ab Version 3.24 installiert
Download – Merge.NET – Beispielanwendung >>>
Download – eDocPrintPro
Download – eDocPrintPro 32 und 64bit (ca. 63 MB) >>>
Download – eDocPrintPro PDF/A 32 und 64bit (ca. 63 MB) >>>
GhostScript 9.18.1 Setup
Download – GhostScript 9.18.1 MSI Setup – 32bit (ca. 16MB) >>>
Download – GhostScript 9.18.1 MSI Setup – 64bit (ca.16MB) >>>