ZFMerge – ZUGFeRD PDF und weitere PDF´s zu einer ZUGFeRD Gesamtdatei zusammenfügen
ZUGFeRD ist ein anerkannter und immer öfter verwendeter Standard für elektronische Rechnungen.
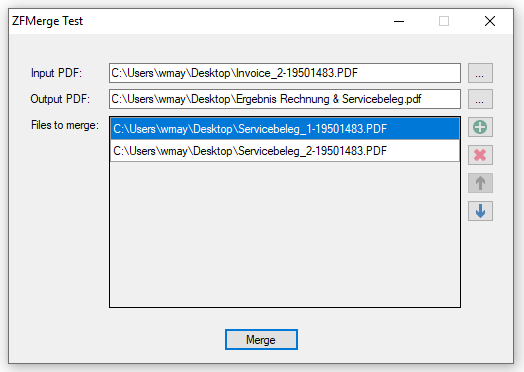
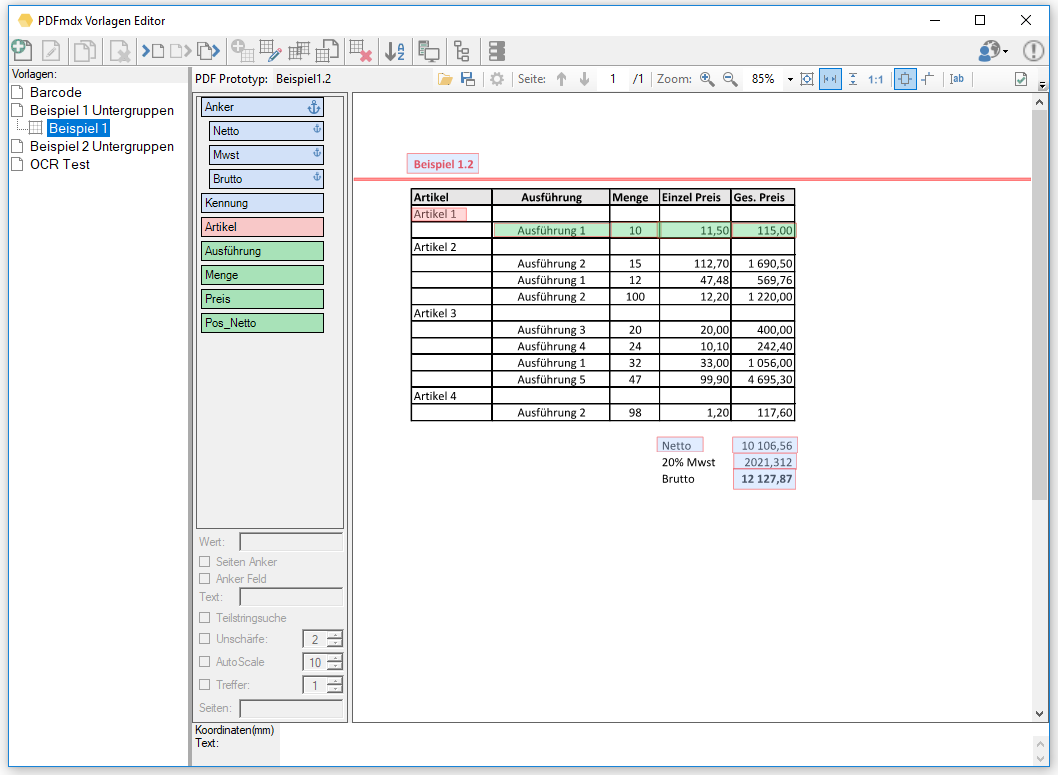
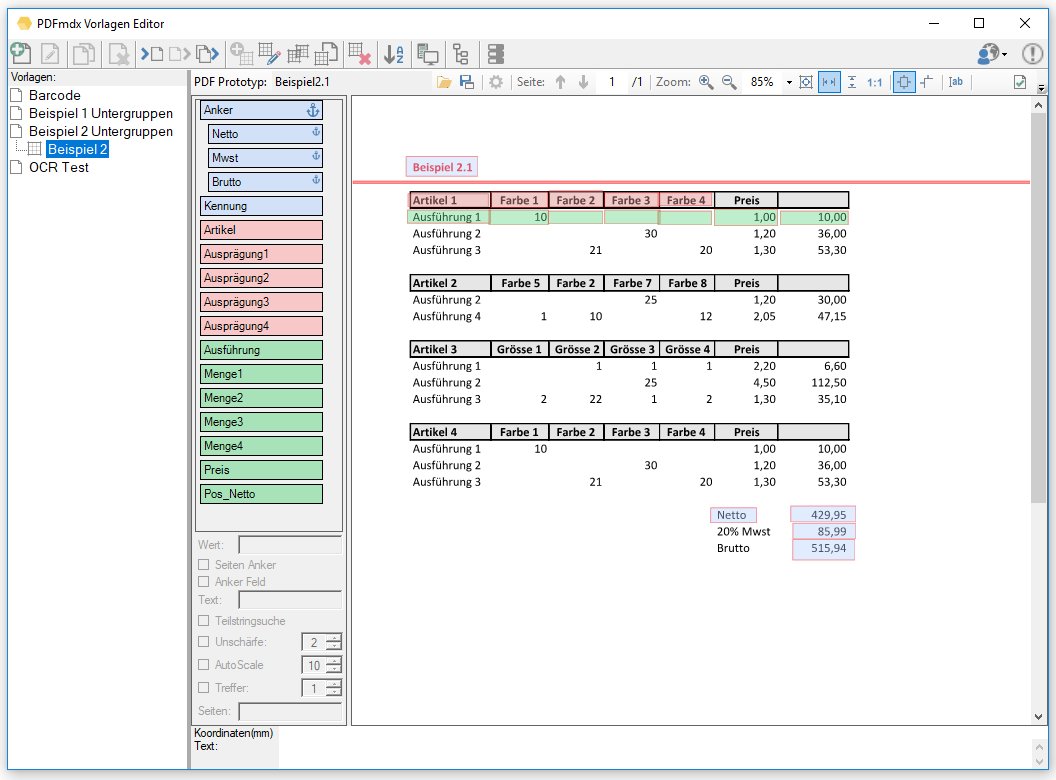
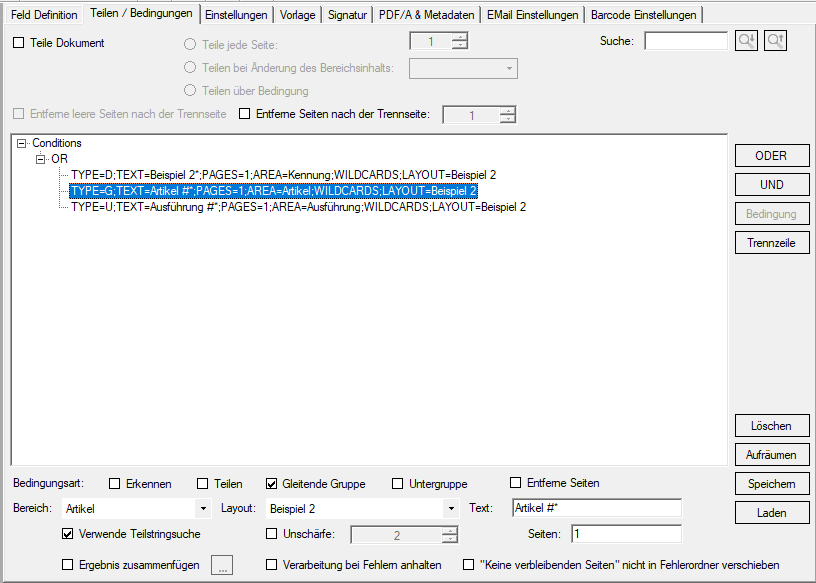
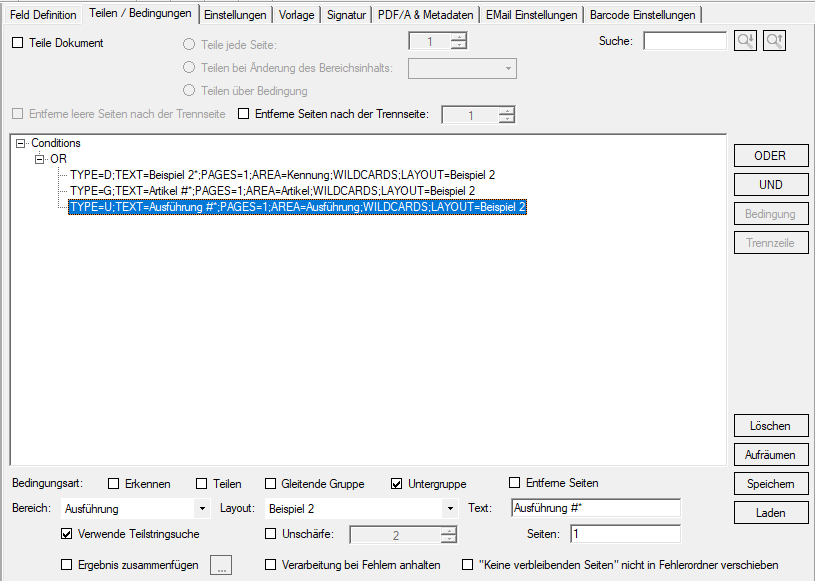
Wird z.B. aus einem ERP System eine ZUGFeRD konforme Rechnung mit eingebettetem XML erzeugt so kann es je nach Kunde erforderlich sein weitere Belege (z.B: eine Leistungsaufstellung) die nicht über das ERP System erstellt wurden, mit anzuhängen. Es muss also ein neues ZUGFeRD konformes Gesamt-PDF erzeugt (zusammengefügt) werden das die XML der Ursprungs-Rechnung und alle anderen Dokumente enthält.
ZFMerge – Funktionen:
- Erzeugt ZUGFeRD konforme PDF/A-3b Gesamtdateien.
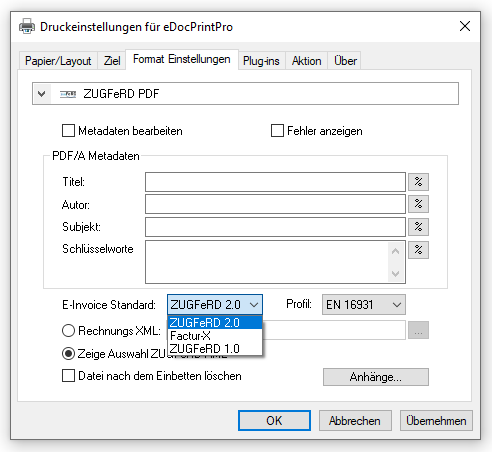
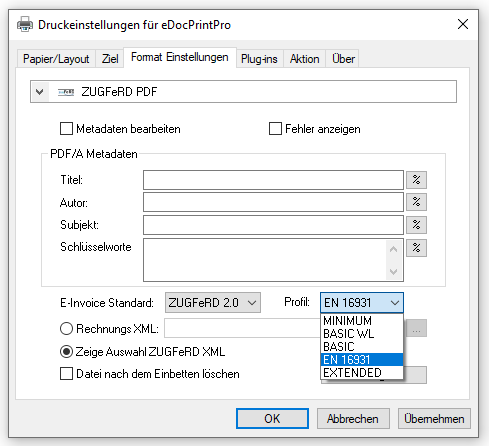
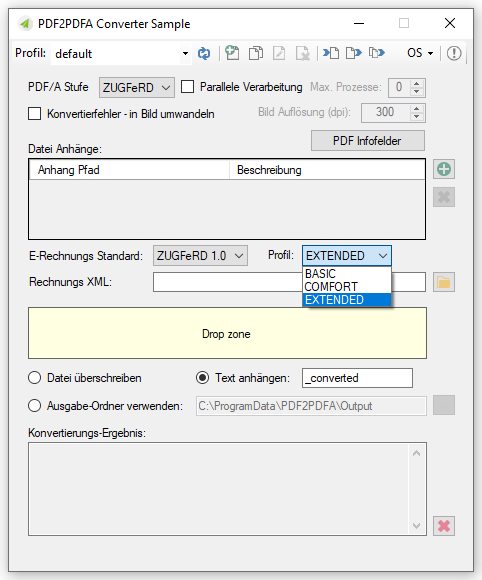
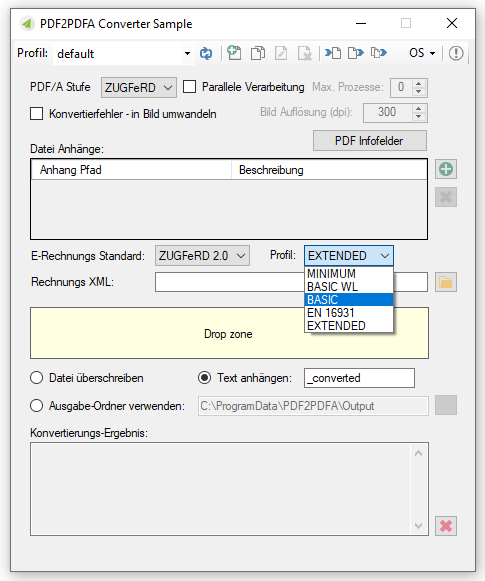
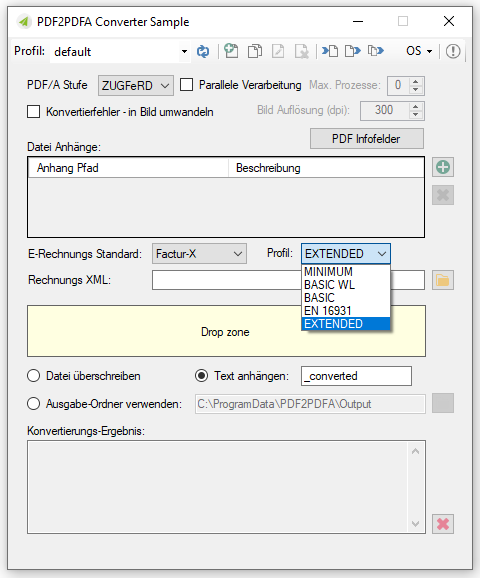
- Ausgangsdatei enthält bereits eine ZUGFeRD XML. Der ZUGFeRD Level und Profile werden übernommen.
- Weitere PDF Dateien können ausgewählt und hinzugefügt werden, die Reihenfolge ist änderbar.
- Pfad / Name der neuen ZUGFeRD Gesamtdatei wird ausgewählt.
- ZUGFeRD bzw. PDF/A-3b konforme PDF wird erzeugt auch wenn die Ausgangsdateien nicht dem PDF/A Standard entsprechen.