ImageProcessing-FM – PDF, TIFF, JPEG – Bildverarbeitung über Ordnerüberwachung
Funktionen ImageProcessing-FM:
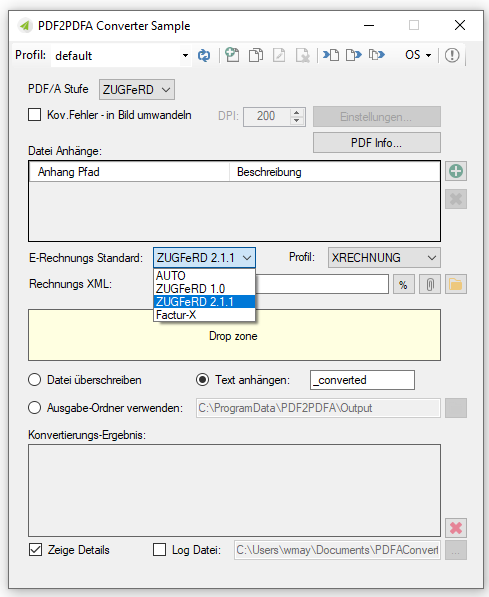
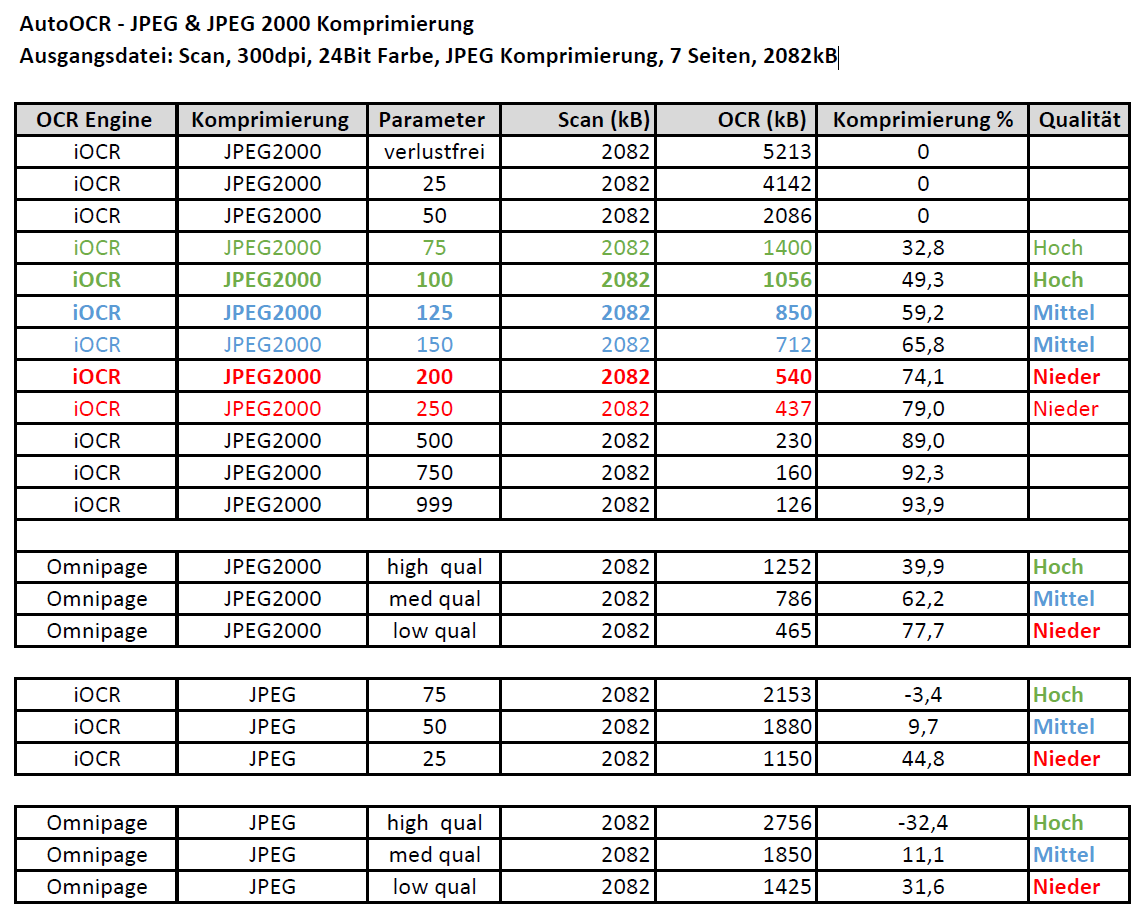
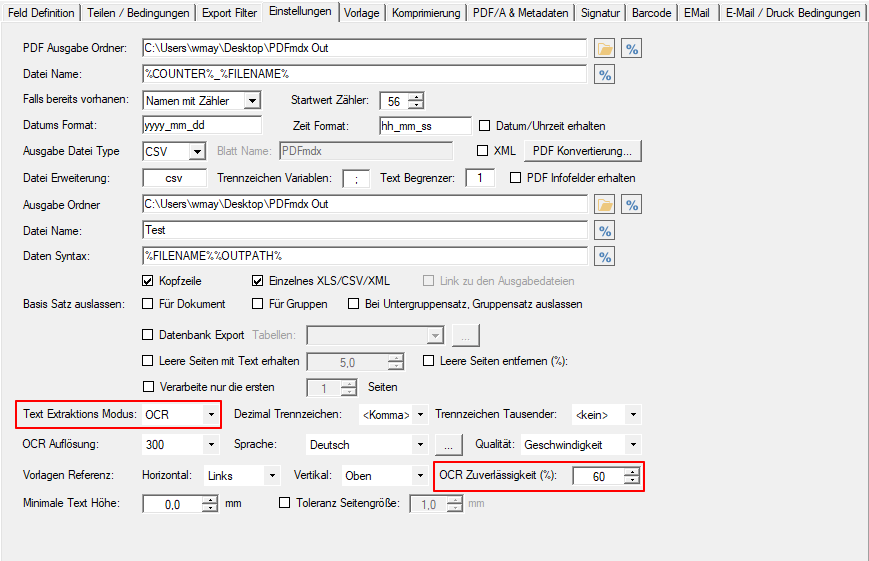
Eine Bildverarbeitung (ImageProcessing) dient dazu die Qualität gescannter Dokumente (PDF, TIFF, JPEG) zu verbessern und zu optimieren bzw. auch um als Vorbereitung für eine nachfolgende OCR Erkennung die Bildqualität für die maschinelle Lesbarkeit zu verbessern, Damit können leere Seiten, schwarze Ränder, Lochungen, Linien und Verunreinigungen entfernt werden. Die FM Version wird als Windows Dienst installiert und kann einen oder mehrere Eingangsordner überwachen.
- MS-Windows Dienst
- Mehrere Jobs können angelegt werden um mehrere Eingangsordner zu überwachen.
- Multithreading / Parallele Verarbeitung gewährleistet einen hohen Verarbeitungs-Durchsatz
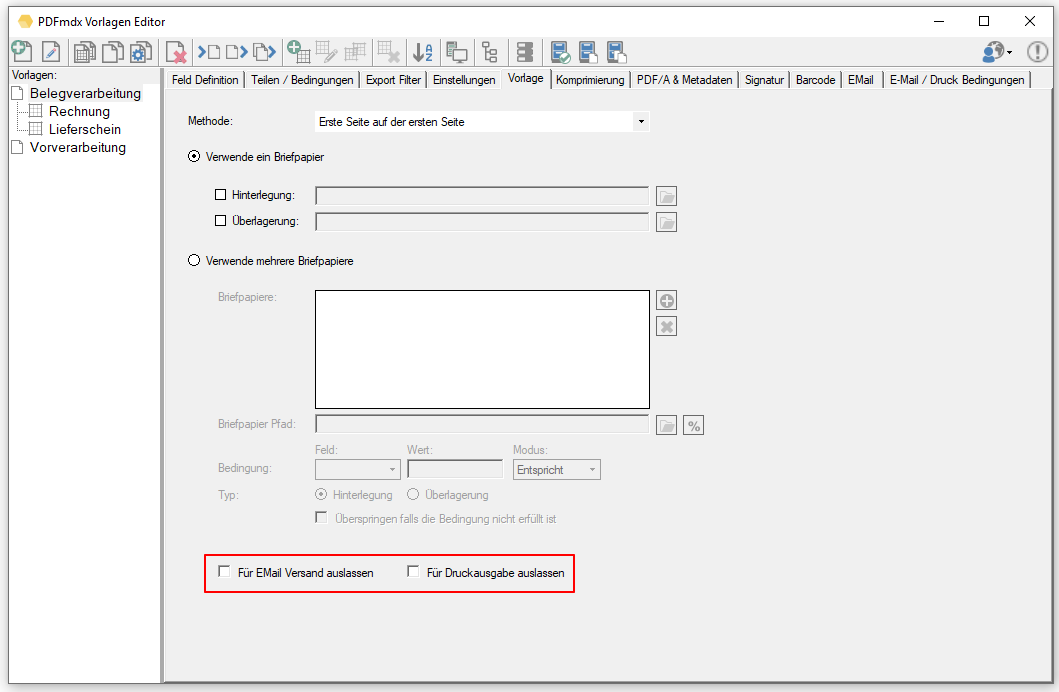
- Konfiguration der Verarbeitungsschritte über Profile (Neu, Kopieren, Bearbeiten, Löschen, Export, Import)
- Nur der Start Ordner oder auch die ganze Unterordnerstruktur können abgearbeitet werden.
- Ordnerinhalte können nach der Verarbeitung gelöscht oder die Ordnerstruktur kann erhalten bleiben.
- Ordnerstruktur aus dem Eingangs-Ordner kann auch in den Zielordner übernommen werden.
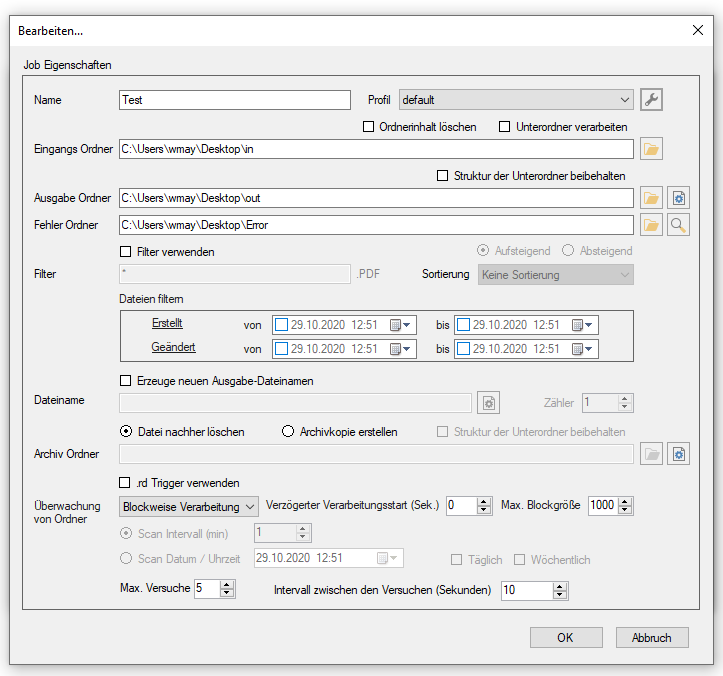
- Dateiverarbeitung über Filter – Name, Erweiterung, Erstellt von/bis, Geändert von/bis.
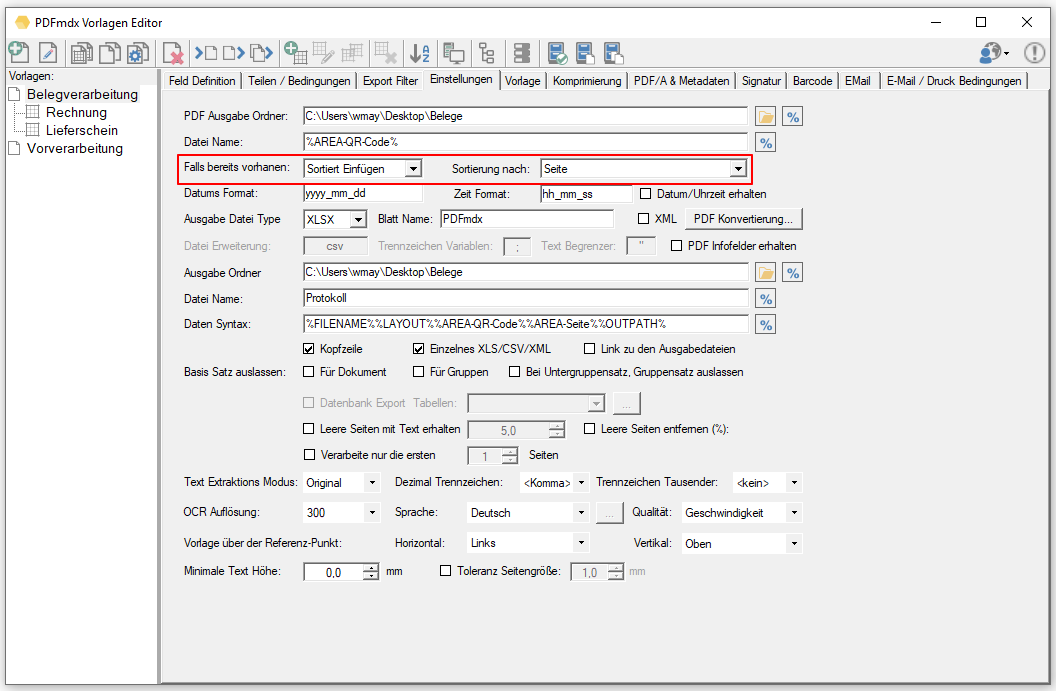
- Sortierte Abarbeitung nach Name / Datum sowie auf-/absteigend möglich.
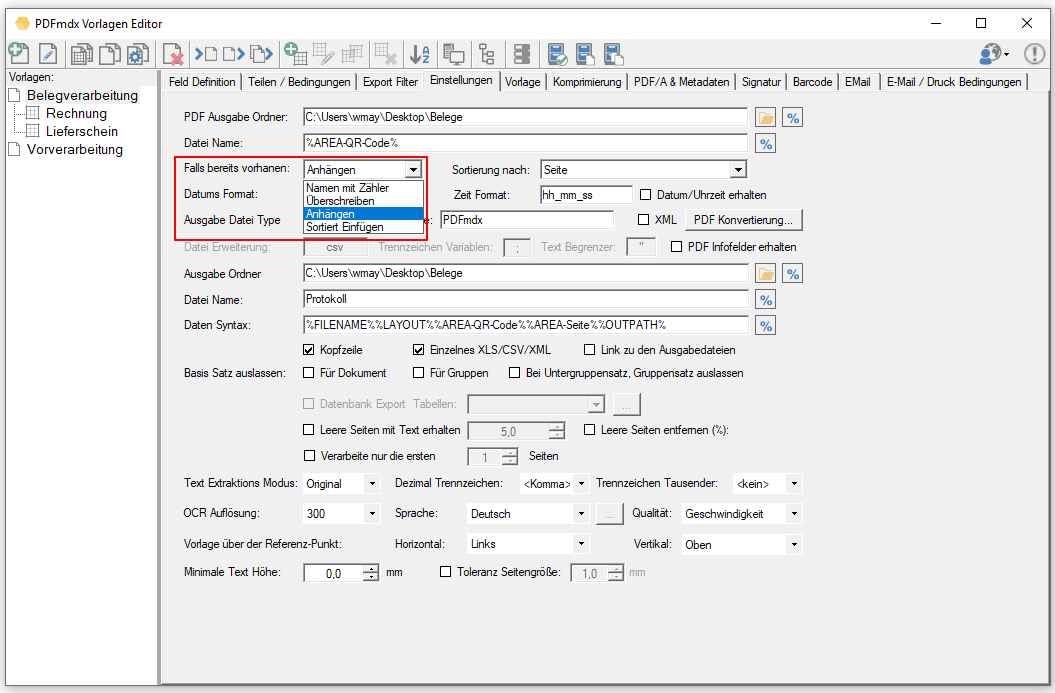
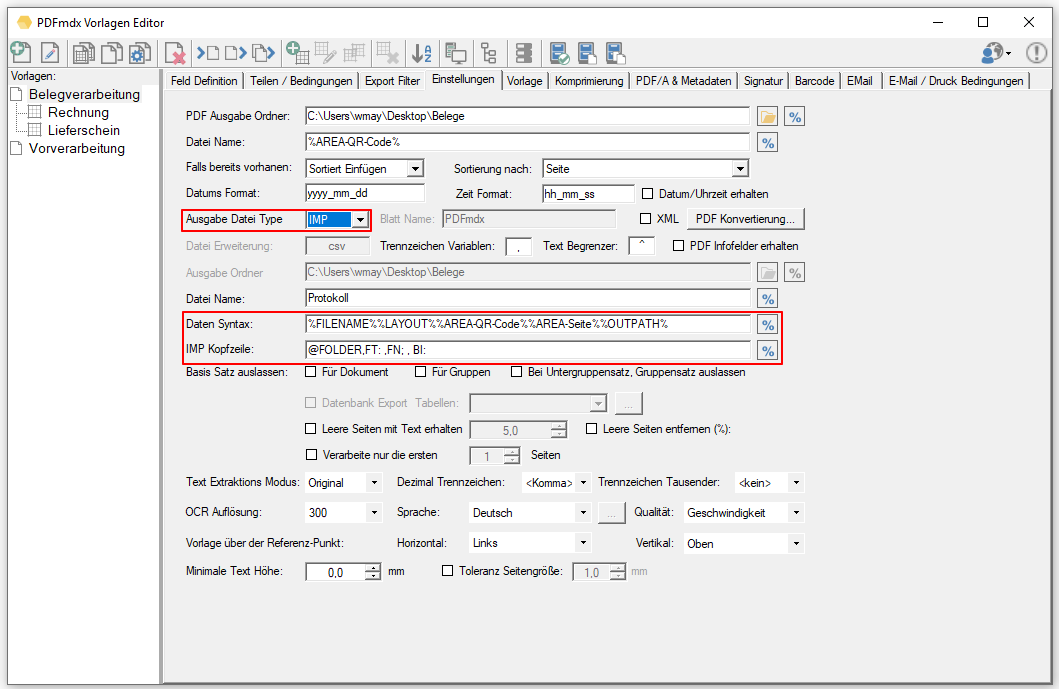
- Erzeugung eines neuen Dateinamens über Variable (Datum, Zeit, Zähler, Ursprungs-Name/Erweiterung)
- Löschen der Ursprungsdatei (Verschieben), Kopieren bzw. Erzeugen einer Archivkopie
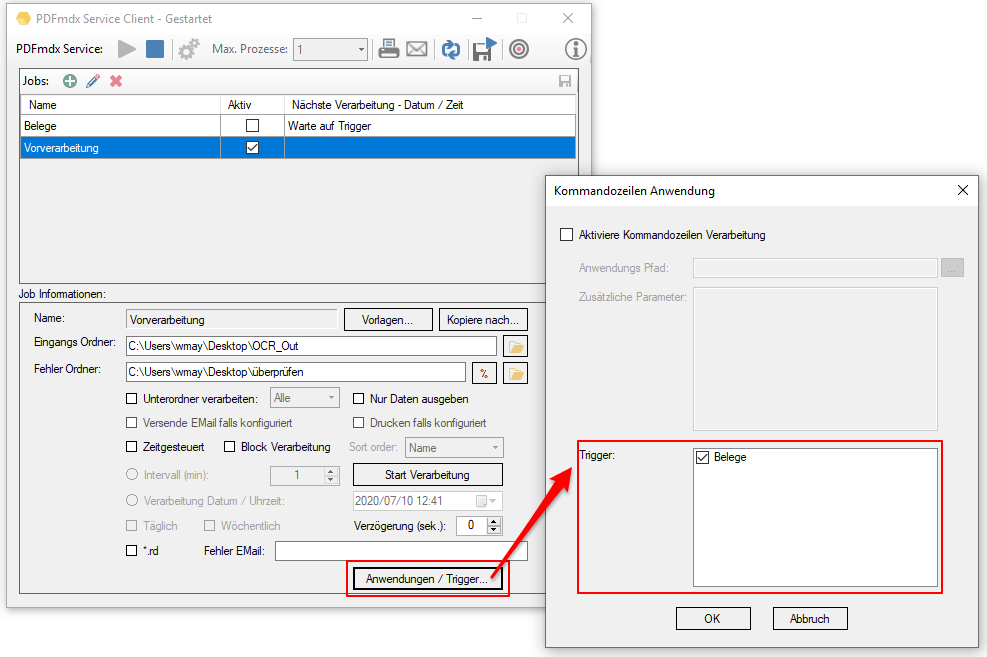
- Ordner-Überwachung und Verarbeitungsstart über Datei-System Events – sofort, bzw. mit einer einstellbaren Verzögerung (0-999sek.), bzw. über Zeit-Intervall (in min.)
- Start der Verarbeitung zu einem eingestellten Datum / Uhrzeit mit optional täglicher / wöchentlicher Wiederholung.
- Einstellbarer Anzahl an Wiederholungs-Versuchen / Zeit-Intervall falls eine Datei blockiert sein sollte.
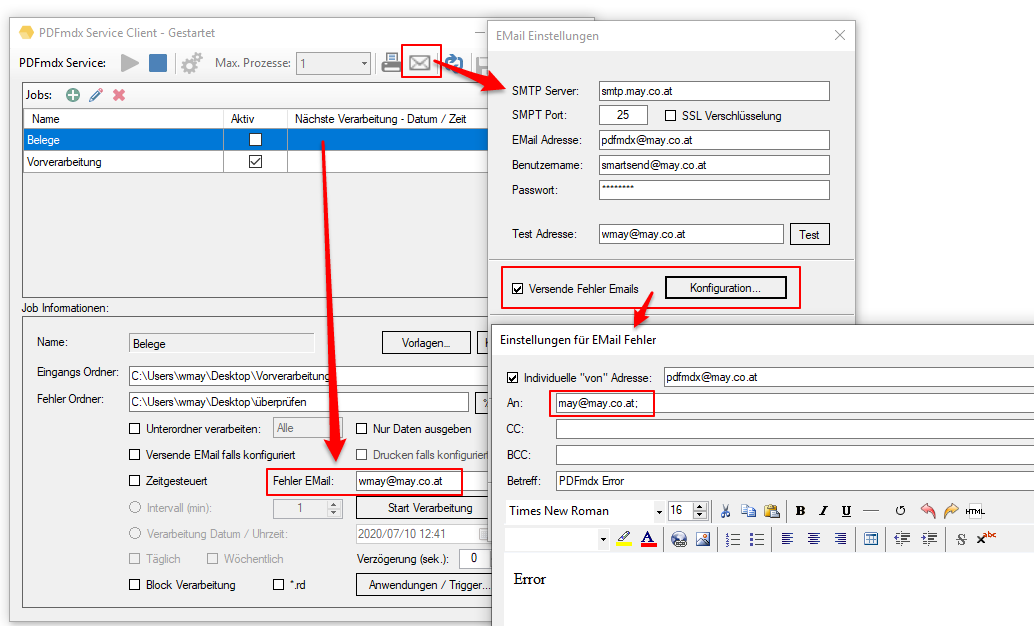
- Logging (Alle Events, nur die Fehler Events)
Bildverarbeitungs Funktionen:
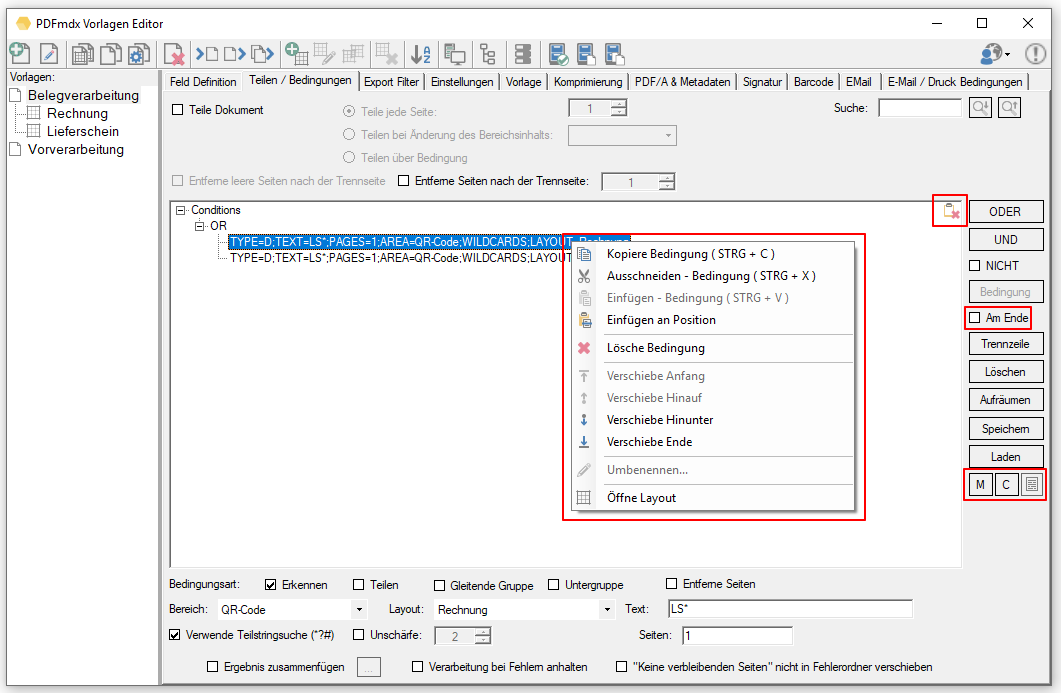
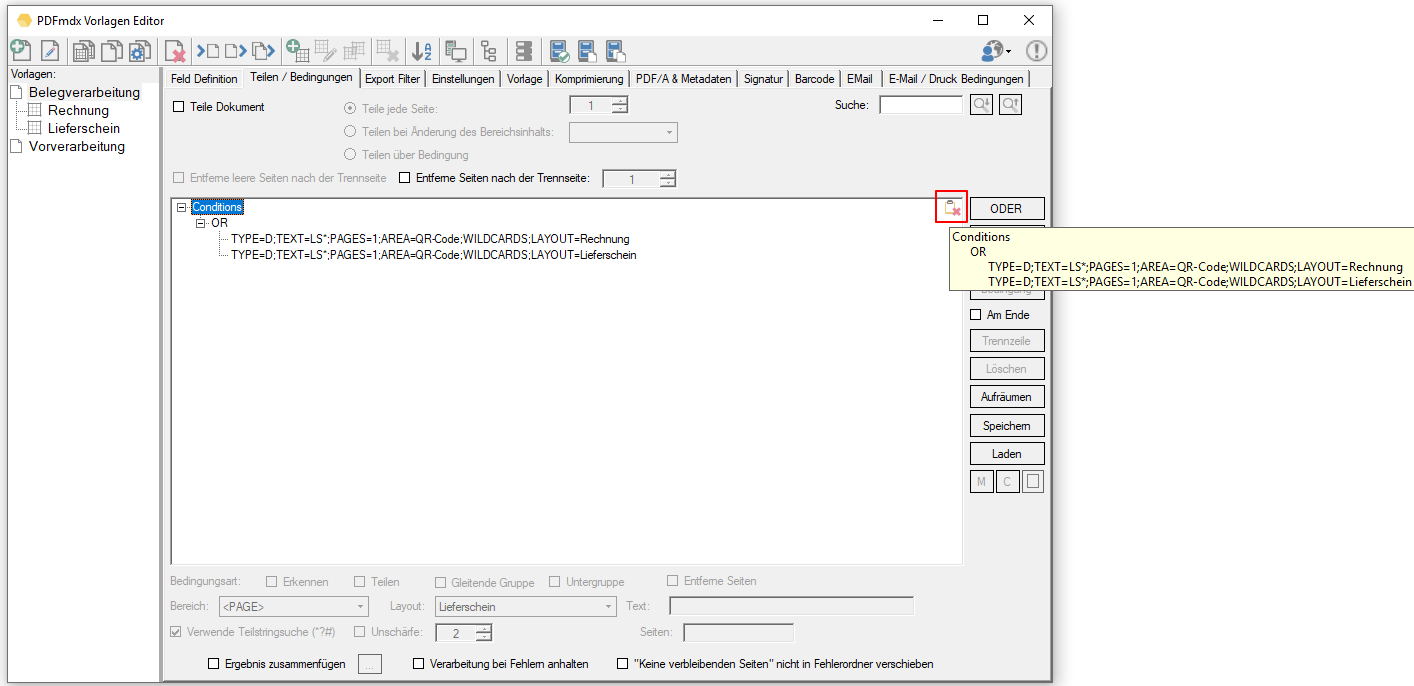
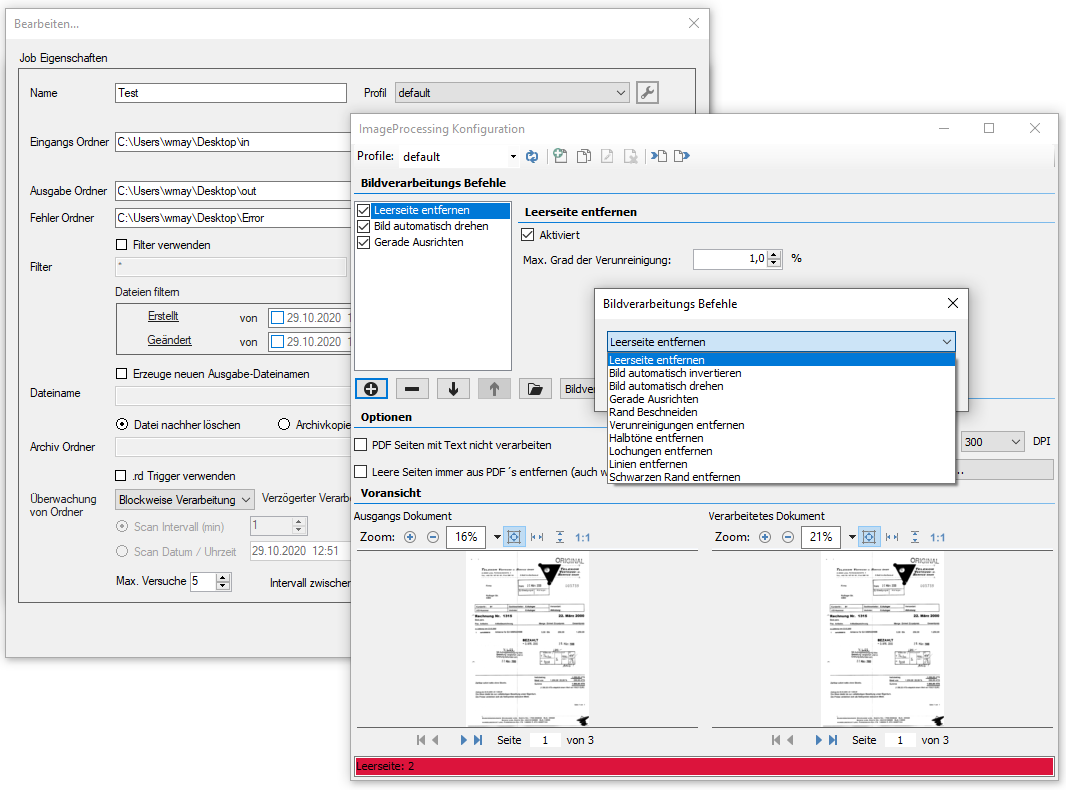
- Mehrere Funktionen können in einer vorgegebenen Reihenfolge hintereinander ausgeführt werden.
- Die ausgewählten Funktionen, deren Parameter und Verarbeitungsfolge werden über Profile verwaltet.
- Profilfunktionen: Neu, Kopieren, Löschen, Umbenennen, In Datei exportieren, Aus Datei importieren.
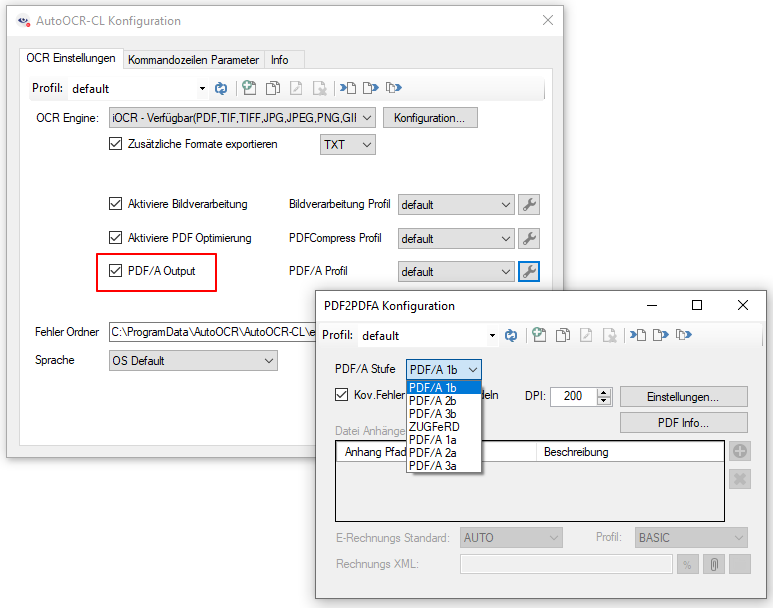
- Option um PDF-Scans / Seiten nur mit Bildinformation bzw. alle PDF Seiten zu verarbeiten.
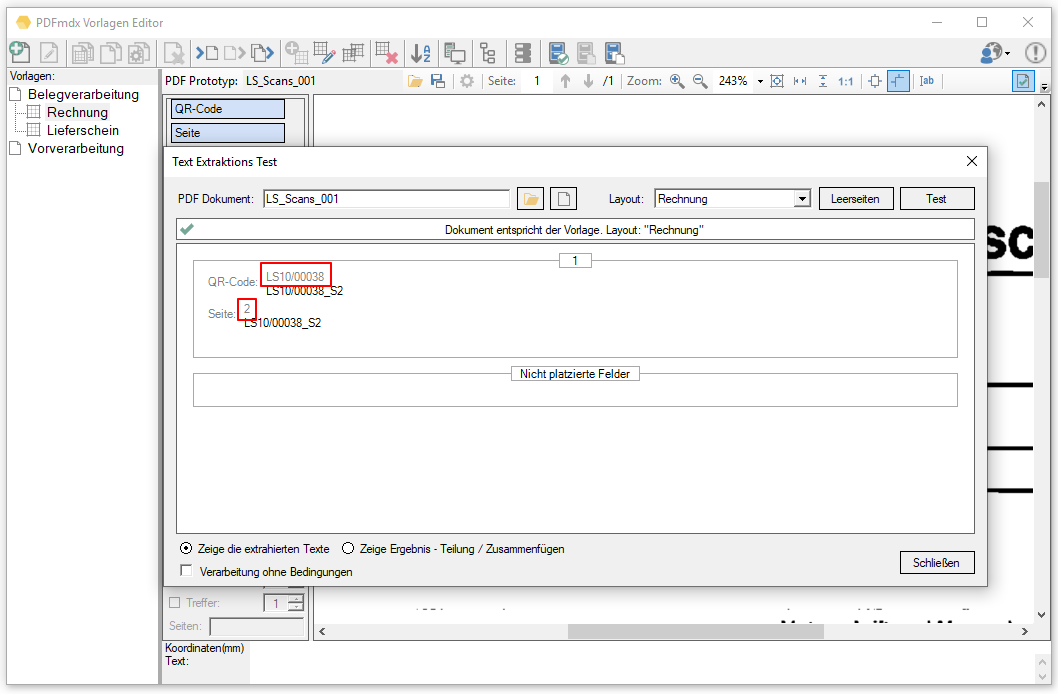
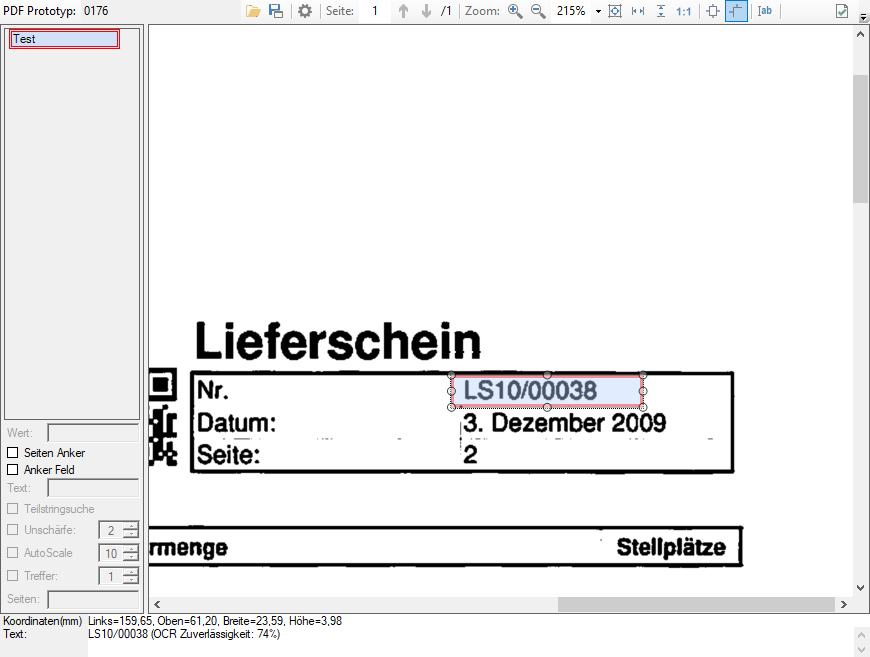
- Laden einer Musterseite und Test der Bildverarbeitungsbefehle mit Voransicht der Ausgangs- und Ergebnisdatei.
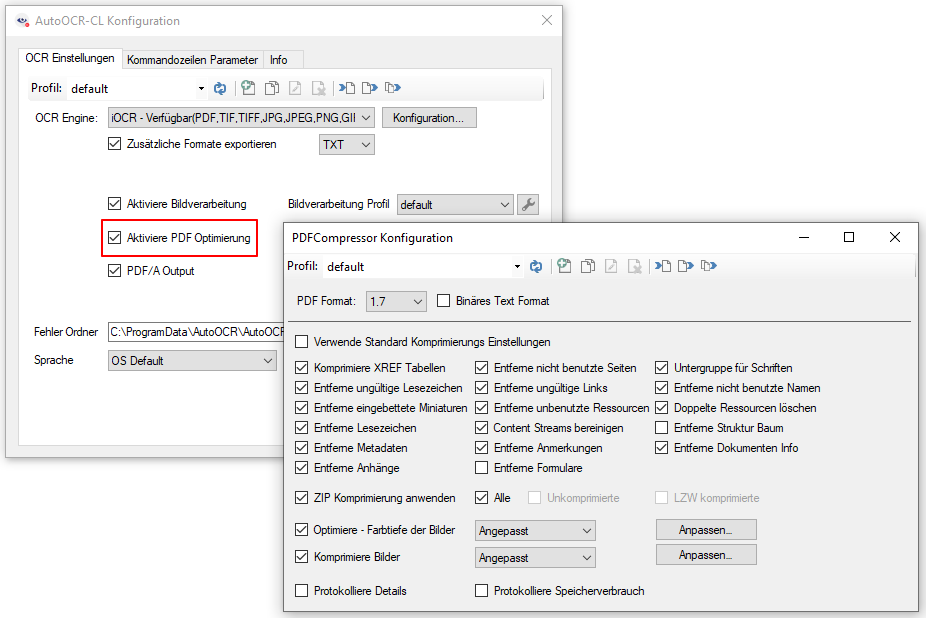
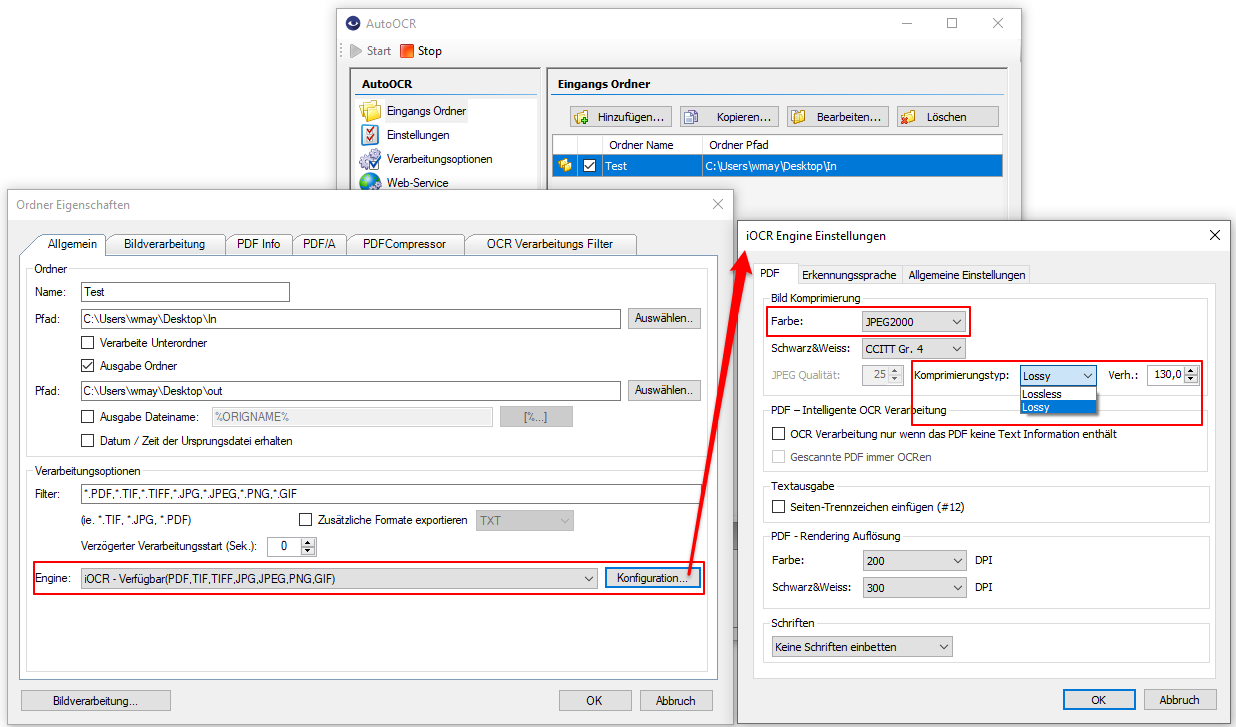
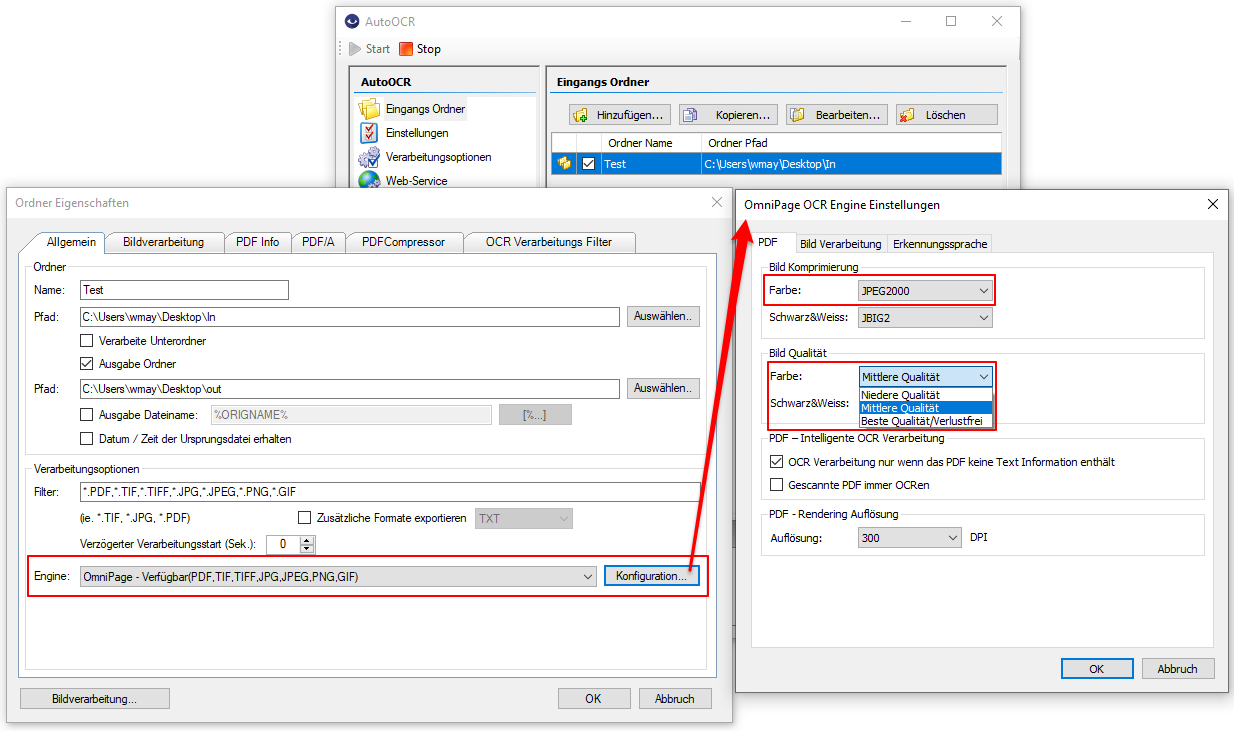
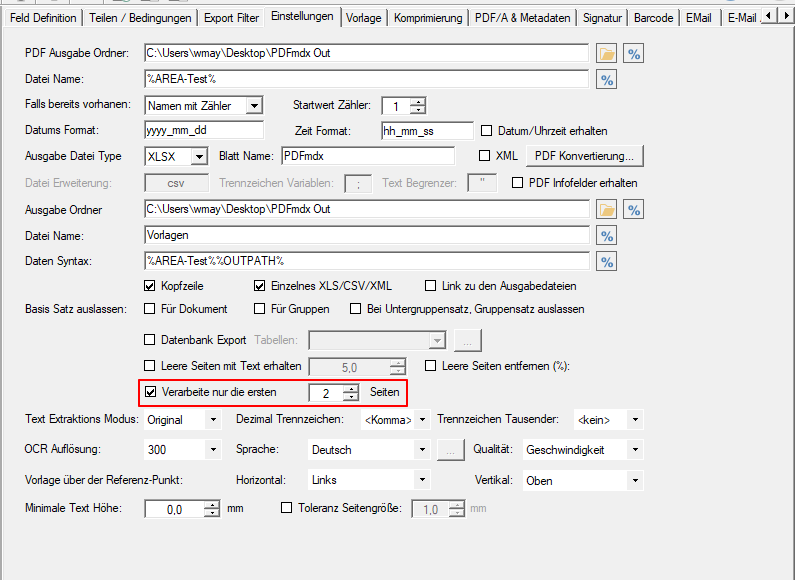
- Für das PDF Rendering kann die Auflösung, Komprimierung sowie Qualitätsparameter konfiguriert werden.
Einzelfunktionen der Bildverarbeitung:
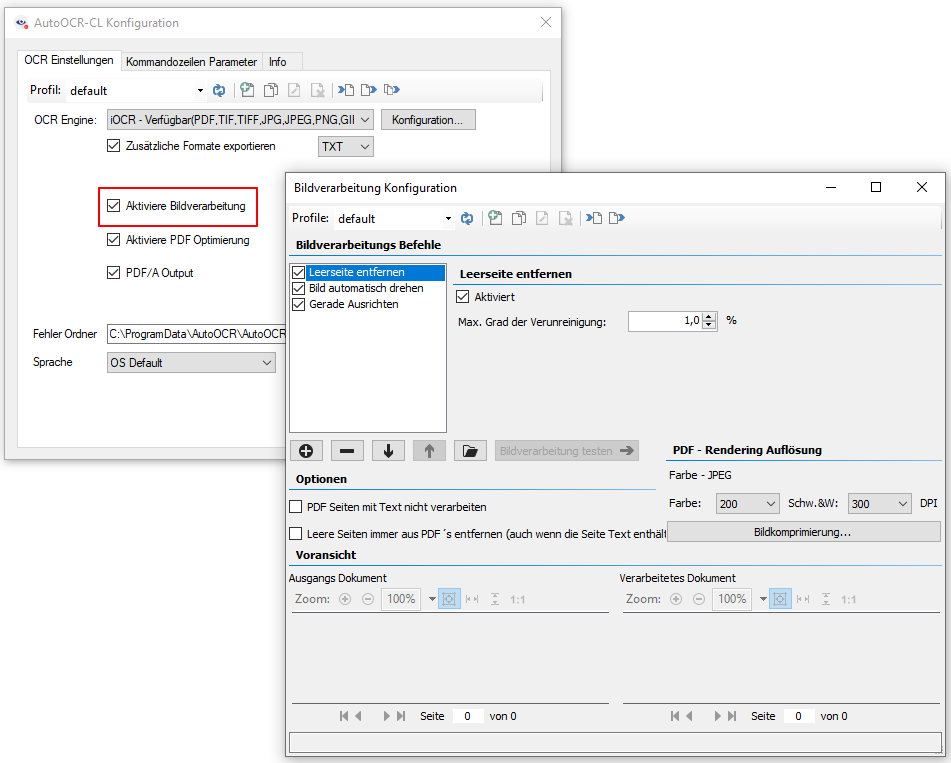
- Leerseiten erkennen und entfernen.
- Seiten automatisch drehen
- Seiten gerade ausrichten
- Bilder invertieren (schwarz nach weiß)
- Schwarzen Rand entfernen
- Rand beschneiden
- Verunreinigungen entfernen
- Lochungen entfernen
- Linien entfernen
- Farbe / Graustufen nach Schwarz/Weiß konvertieren

![]()